动态网页也是字面意思:实时更新的那种
还有就是你在股票这个网站上,翻页。他的地址是不变的
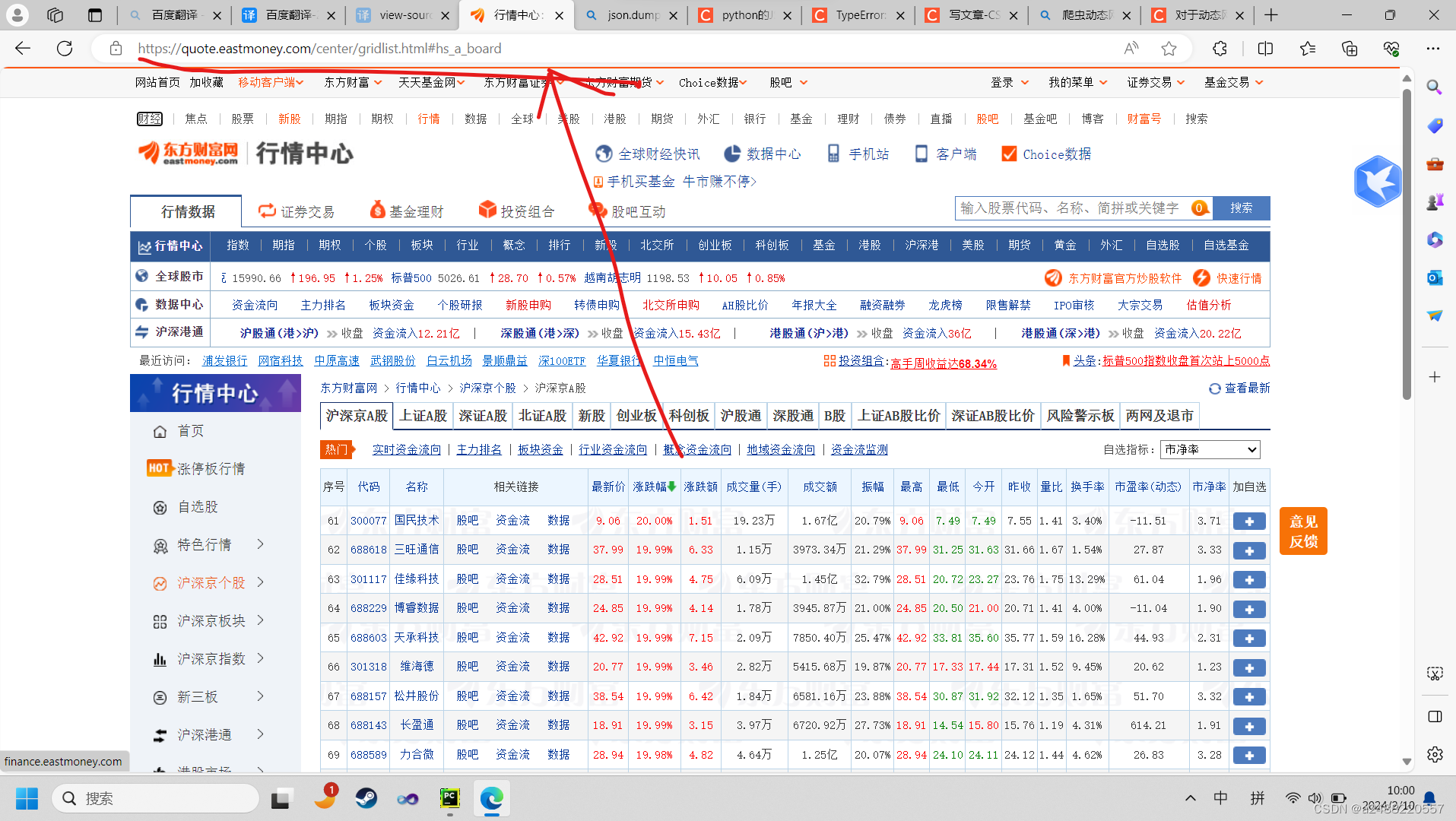
是动态的加载,真正我不太清楚,只知道他是不变的。如果用静态网页的方法就不可行了。
静态网页的翻页,是网址是有规律的。
还有就是:
在百度翻译中你总是在百度翻译一个网站上 ,并没有因此而改变。(意思就是不是查一个单词,换一个网址)
正文开始了哈:
先来看成品和代码;
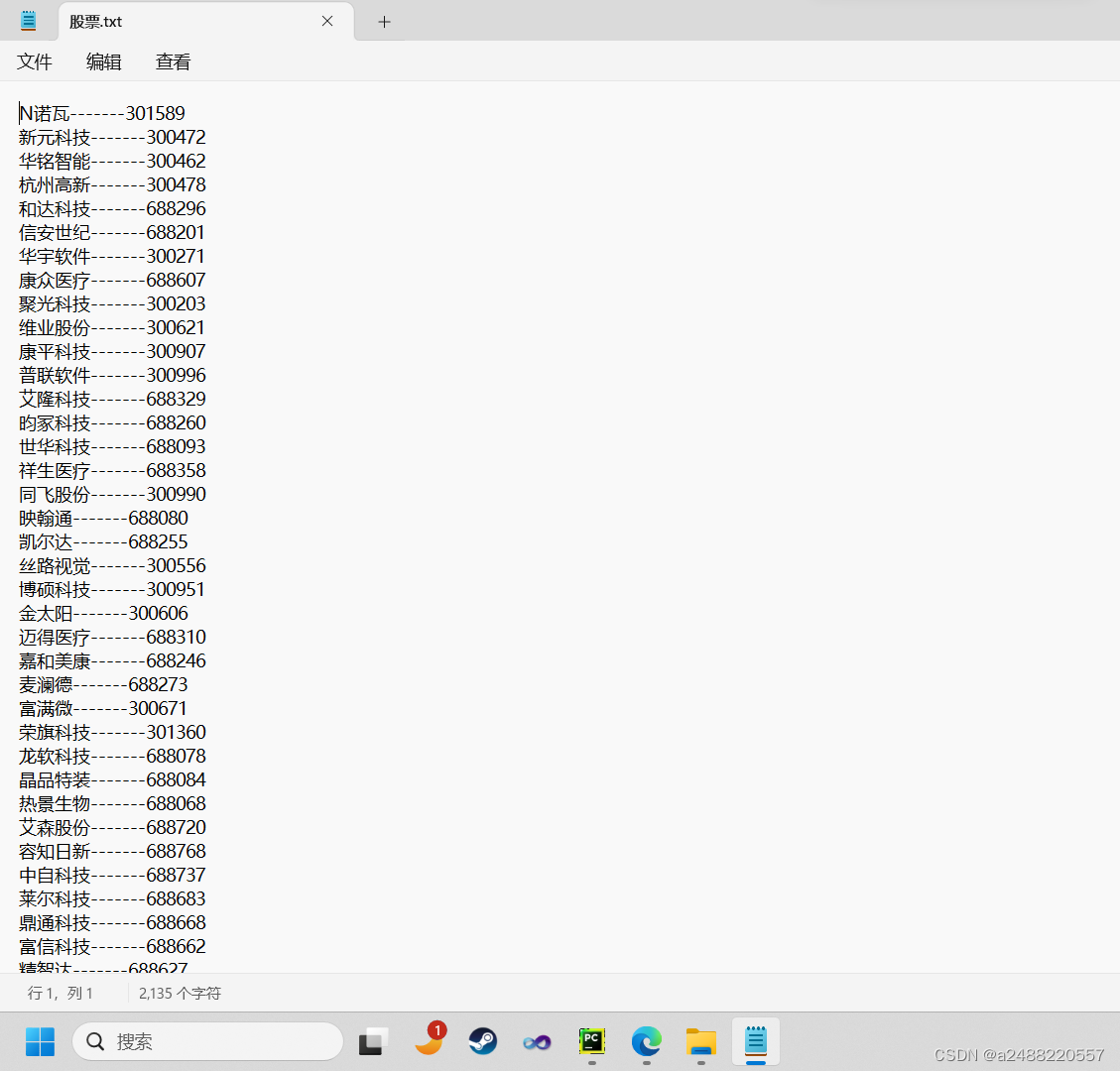
如果想要其他东西,只要改对应的地方。就可以拿到对于的数据。
import os
import requests
import re
import json
wenjian = input("您要保存的文件名:")
img_path = f"./{wenjian}/" # 指定保存地址
if not os.path.exists(img_path):
print("您没有这个文件为您新建一个文件:")
os.mkdir(img_path)
else:
print(f"您有这个文件夹,将为您保存在“{wenjian}”中")
count=0
url = "https://63.push2.eastmoney.com/api/qt/clist/get?"
hearders = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'
}
#for i in range(1,281,1):
for i in range(1,281,1):
count+=1
params = {
'cb': 'jQuery1124010908871949611432_1707493179217',
'pn': f'{i}',
'pz': '20',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'wbp2u': '|0|0|0|web',
'fid': 'f3',
'fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': '1707493179252'
}
resqonse = requests.get(url,headers=hearders,params=params).text
#print(resqonse)
obj = re.compile(r"jQuery1124010908871949611432_1707493179217\((?P<json>.*?)\);")#给正则表达式的匹配的东西起个名字,叫json(?P<name>.*?)
content = obj.search(resqonse).group('json')#在reqonse中搜索json的正则表达式
#print(content)
#print(f"第一次拿到的是content他的类型为{type(content)}")
#转换成字典
dic = json.loads(content)
#print(dic)
#print(f"改为字典为dic类型为{type(dic)}")
#拿数据
diff = dic['data']['diff'] #想要拿名字和股票编号。他们在data里的diff中
for i in diff:
name = i['f14']
num = i['f12']
#print(f"他的名字是: {name}——{num}")
end = name+'-------'+num+"\n"
f = open(f"{img_path}{wenjian}.txt", 'a')
f.write(end)
print(f"第{count}页打印完成")
一般在XHR和JS文件中找到想要的数据

要加入params和headers你会发现页数的改变是跟着 params中的'pn'在变,所以在页数改变的同时,'pn'也再改变。
上述代码中,加入新东西的是---Json
Json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
1.dumps和dump:
dump比Dumps多了一个操作,对于文件的写入。改为数据类型然后写入文件
# fp = open(f'{img_path}.txt', 'w',encoding='utf-8')
# json.dump(dic,fp=fp,ensure_ascii=False),中文的写入

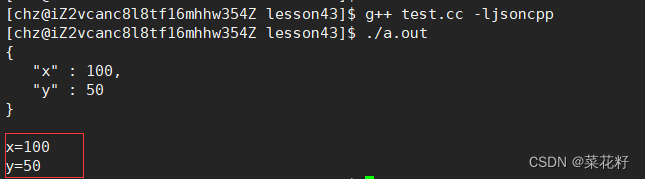
2.毕竟是学习,就截屏了做个笔记。
import json
a="[1,2,3,4]"
b='{"k1":1,"k2":2}'#当字符串为字典时{}外面必须是''单引号{}里面必须是""双引号
print (json.loads(a) )
[1, 2, 3, 4]
print (json.loads(b) )
{'k2': 2, 'k1': 1}

上面这个就很简单了到目前来说,简单指的是可以看懂!!!
上面还有一个关于给自己正则表达式找到的起名字的写法,代码后面我有注释,不再多说!!!
下面是百度翻译的读取,顺便做了个翻译系统:
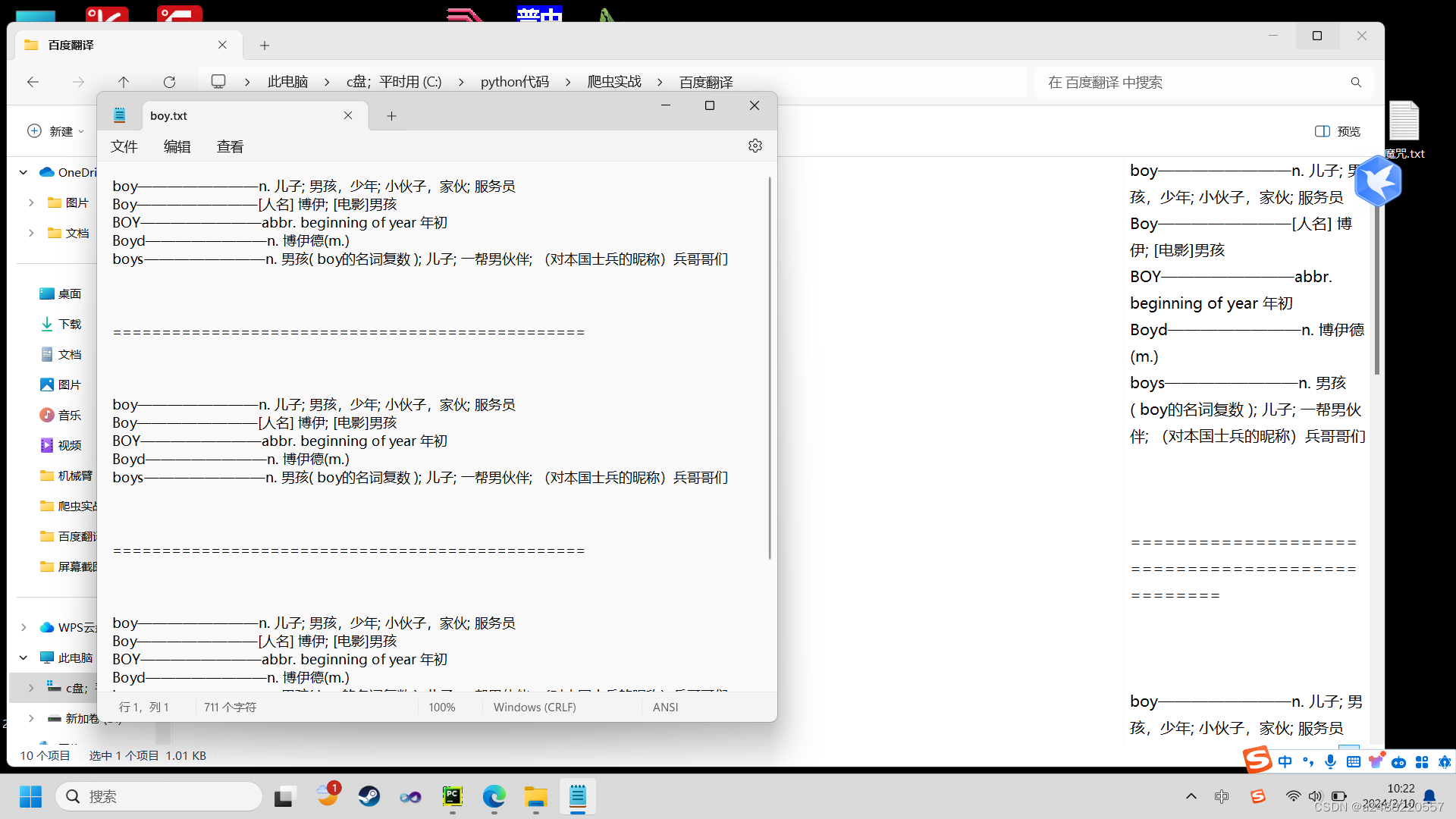
这个我就是多查了计次。
import json
import requests
import os
Myflag=1
img_path = '百度翻译'
img_path = f"./{img_path}/" # 指定保存地址
if not os.path.exists(img_path):
print("您没有这个文件为您新建一个文件---")
os.mkdir(img_path)
else:
print(f"百度翻译——结果为您保存在{img_path}文件夹中")
url = "https://fanyi.baidu.com/sug"
while Myflag!="0":
wenjian = input("您要查询的单词是:")
header = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'
}
data = {
'kw':f'{wenjian}'
}
response = requests.post(url = url,headers = header,data = data)
dic = response.json()
data = dic['data']
print(f"您所查询的{wenjian}的意思是:")
for i in data:
data = i['k']
translate = i['v']
end=data+'————————'+translate+'\n'
ending = "\n\n\n================================================\n\n\n\n"
print(f'{data}————————{translate}')
f = open(f"{img_path}{wenjian}.txt", 'a')
f.write(end)
f = open(f"{img_path}{wenjian}.txt", 'a')
ending = "\n\n\n================================================\n\n\n\n"
f.write(ending)
print("保存完成")
Myflag = input("退出选‘0’,如果想退出请按任意键:")
print("您退出单词查询")
# fp = open(f'{img_path}.txt', 'w',encoding='utf-8')
# json.dump(dic,fp=fp,ensure_ascii=False)
总体来说,要找清楚,你要查询的请求方式。这个为post,到现在用过的请求方式为get。
post中要加入data!!!也就是百度翻译的要翻译的内容!!!
你会发现这里没有用json转换一下,因为这个本事得到的是一个‘dic’的
而上一个用正则表达式得到的名字为json的东西是str,要改为dic,然后分析文件。
上面写入文件的操作在我前面有写到,前面的文章。多看几个就会了。!!!
新年快乐!!!!

![[论文总结] 深度学习在农业领域应用论文笔记12](https://img-blog.csdnimg.cn/img_convert/b1683bbd890e82d3bd670ad50e0cbef5.png)