文章目录
- 1. 3D-ZeF: A 3D Zebrafish Tracking Benchmark Dataset (CVPR, 2020)
- 摘要
- 背景
- 相关研究
- 所提出的数据集
- 方法和结果
- 个人总结
- 2. Automated flower classification over a large number of classes (Computer Vision, Graphics & Image Processing, 2008)
- 摘要
- 背景
- 分割与分类
- 数据集和实验步骤
- 结论
- 个人总结
- 3. A large-scale hyperspectral dataset for flower classification(Knowledge-Based Systems, 2021)
- 摘要
- 背景
- 相关工作
- 所提出的HFD100数据集
- 实验
- 结论
- 个人总结
- 4. Plant Disease Recognition: A Large-Scale Benchmark Dataset and a Visual Region and Loss Reweighting Approach (IEEE Transactions on Image Processing, 2021)
- 摘要
- 背景
- 相关的工作
- 数据集构建
- 工作的框架
- 实验
- 结论
- 个人总结
- 5. PlantPAD: a platform for large-scale image phenomics analysis of disease in plant science (Nucleic Acids Res,2024)
- 摘要
- 背景
- 图像信息采集
- 个人总结
- 6. PDDD-PreTrain: A Series of Commonly Used Pre-Trained Models Support Image-Based Plant Disease Diagnosis (Plant Phenomics, 2023)
- 摘要
- 背景
- 材料与方法
- 结果
- 讨论
- 个人总结
- 7. Phenotypic Analysis of Diseased Plant Leaves Using Supervised and Weakly Supervised Deep Learning (Plant Phenomics, 2023)
- 摘要
- 背景
- 材料与方法
- 病害分割方法
- 结果
- 讨论
- 结论
- 个人总结
- 8. VTUAV--Visible-Thermal UAV Tracking: A Large-Scale Benchmark and New Baseline(CVPR, 2022)
- 摘要
- 背景
- 相关的工作
- VTUAV可见光-热成像UAV跟踪大规模数据集
- 高质量标注
- 分层多模态融合跟踪器
- RGB-T跟踪的实验分析
- VTUAV-V子集的实验结果
- 结论
- 个人总结
- 9. A novel deep learning method for detection and classification of plant diseases(Engineering Applications of Artificial Intelligence,2023)
- 摘要
- 背景
- 文献综述
- 提出的AgriDet框架
- 实验结果和讨论
- 讨论
- 结论
- 个人总结
1. 3D-ZeF: A 3D Zebrafish Tracking Benchmark Dataset (CVPR, 2020)
摘要
在本研究中,我们推出了一个创新的、公开可用的基于RGB的三维斑马鱼多目标跟踪数据集——3D-ZeF。斑马鱼作为一种日益流行的实验模型生物,广泛应用于神经系统疾病、药物成瘾等领域的研究,其中行为分析是这些研究不可或缺的一环。然而,斑马鱼之间的视觉相似性、相互遮挡以及不规则运动等因素,使得实现准确的三维跟踪成为了一个充满挑战且待解决的难题。我们提供的数据集涵盖了八个视频序列,持续时间从15秒到120秒不等,每个序列包含1至10条自由活动的斑马鱼。这些视频共标注了86,400个点和边界框。此外,我们还介绍了一个复杂度评分机制和一个全新的、开源的、模块化的斑马鱼三维跟踪基准系统。该系统经过两种检测器的评估:一种是基础的朴素方法,另一种是采用Faster R-CNN技术的鱼头检测器。在我们的系统中,多目标跟踪准确率(MOTA)可达到77.6%。有关代码和数据集的链接可以在项目页面https://vap.aau.dk/3d-zef找到。
背景
探讨斑马鱼模型的研究意义,我们必须首先认识到现有研究在该领域所遭遇的局限性。这些缺陷不仅揭示了目前研究所面临的挑战,而且也解释了为何迄今为止鲜有研究者能够有效地解决这些问题。正是基于这样的背景,我们开展了相关工作,包括创建了一个公共3D斑马鱼数据集以及开发了一套开源的模块化基线系统和方法,旨在为该研究领域提供新的思路和工具。
相关研究
- 多目标追踪
探讨了多目标追踪领域内的核心挑战,同时指出当前研究技术的焦点所在。 - 斑马鱼追踪,此部分涵盖三个关键方面:
- 首先,概述了现阶段大部分视觉追踪技术基于二维(2D)的研究背景,并指出从2014年至2019年期间的两个主要技术进展,同时强调了2D追踪技术在动物行为研究中的应用广泛性。
- 接着,考虑到大多数水生生物在三维空间中的运动特性,强调了在三维(3D)空间中全面描述其轨迹和行为的必要性。立体视觉作为研究动物行为时最常采用的3D数据获取方法,尽管如此,对于斑马鱼的三维追踪主要局限于单体或小群体研究,这是由于遮挡问题以及鱼类视觉外观随位置和姿态变化而复杂化,这些因素均增加了3D重识别的难度。(进一步强调了3D识别的重要性及其面临的挑战)
- 最后,简要概述了现有研究在斑马鱼的3D识别方面取得的成果。总结指出:“在没有ID交换的情况下,目前尚无方法能在3D环境中追踪多个斑马鱼超过几秒钟,这一问题依旧待解。”(我个人觉得这个地方介绍别人的工作内容太多了,可以更概括性的总结)
- 数据集提及了其他3D斑马鱼追踪数据集中尚未解决的问题,暗示了该领域研究的潜在改进空间和未来方向。
所提出的数据集
- 介绍了实验设置,如何进行实验设计(包括浴缸大小,色温,拍摄设备,图片分辨率,拍摄速度等),确保全方面的捕捉和追踪斑马鱼。
- 深入阐述了数据集的构建过程,详细描述了在数据收集阶段所遭遇的各种情形及所采用的统计方法,并对该数据集的规则进行了详尽解释。
- 介绍数据集的复杂程度。
方法和结果
介绍该研究用到的各种方法,并介绍这研究在一些列指标上的表现和这些指标的意义。
个人总结
首先本工作阐述了开发3D斑马鱼跟踪系统的迫切需求及其重要性。斑马鱼作为日益受到重视的动物模型,在神经科学和生物学研究中的行为分析扮演着关键角色。然而,手动精确描述斑马鱼在三维空间中的复杂运动既耗时又具有主观性。尽管在其他领域的多目标跟踪(MOT)技术取得了显著进展,但这些进展并未有效应用于3D斑马鱼跟踪领域,主要受限于缺乏公开的数据集和相应的真实标注。为了填补这一空白,我们推出了首个公开的RGB 3D斑马鱼跟踪数据集——3D ZeF,为大规模、高精度的实验研究提供了基础。然后介绍了数据集的设计以及取得的成果,最后说明了该工作的意义 (开源模块化系统为3D斑马鱼跟踪和理解领域的进一步发展提供了基线和垫脚石 The open-source modular based system provides a baseline and stepping stone for further development within the field of 3D zebrafish tracking and understanding )。这篇论文提出了一个开源数据集以及检测的方法,在数据集的搜集,也就是实验设计那块写的非常清楚,此外该论文的写作水平也很高,值得我们学习和模仿。
2. Automated flower classification over a large number of classes (Computer Vision, Graphics & Image Processing, 2008)
摘要
我们进行了一项研究,探索了特征融合在处理具有高度相似类别的大型数据集中提升分类效能的作用。为了这一目的,我们引进了一个包含103种类别的花卉数据集。对于这些花卉,我们计算了四种不同的特征,每种特征针对不同的属性,包括局部形状/纹理、轮廓形状、花瓣的整体空间布局以及颜色。通过采用多重核心框架,我们实现了这些特征的有效整合,并利用支持向量机(SVM)分类器进行了训练。采用 Learning the discriminative power invariance trade-off的方法来学习每个类别的权重,该方法在其他大规模数据集(例如Caltech 101/256)中已展现出前沿性能。尽管我们的数据集在类别数量上呈现出相似的挑战性,但它在减小类别间的相似度和增加类内相似度方面带来了额外的难题。研究结果显示,通过学习多个特征的最优核心组合显著提升了分类性能,从依赖单一特征所获得的最佳性能55.1%提高到了综合所有特征后达到的72.8%。
背景
随着基于图片的分类系统不断完善,很多图像分类任务转移到数据集上。在本文中,我们不是识别大量不同的类别,而是研究在一个大类别中识别大量子类别的问题-花的类别。与自行车、汽车和猫等分类相比,花的分类具有额外的挑战,这是因为不同花卉之间有很大的相似性。此外,花是非刚性的物体,可以以多种方式变形,因此在类别中也有很大的变化。以前的花分类工作只处理了少量的类,从10到30不等。在这里,我们介绍了一个103类数据集。区分花朵的标准有时是颜色,例如蓝铃花和向日葵;有时是形状,例如水仙花和蒲公英;有时是花瓣上的图案,例如三色堇和虎百合等。困难在于找到合适的特征来表示颜色、形状、图案等,也在于分类器有能力学习使用哪个特征或特征。在加州理工学院101/256图像数据集的情况下,通过使用多个特征和SVM分类器中的核的线性组合来实现最先进的性能:为每个特征(例如形状,外观)计算一个基本核,最终核由这些基本核的加权线性组合组成,每个类学习不同的权重集。Varma和Ray表明,权重可以通过求解一个凸优化问题来学习。在本文中,我们研究了这种多核学习方法,用于在相当不受控制的图像情况下获得的花卉图像-这些图像主要是从网络上下载的,并且在规模,分辨率,照明,杂乱,质量等方面差异很大。我们所做的链接是自动分割每个图像(第2节),以便花在图像中被隔离。这使得识别挑战在本质上有点类似于加州理工学院101/256的挑战——在每个图像中只有一个(或很少)物体的实例(除了像风信子这样的花田)——也就是说,背景杂乱已经被去除,并且有相似的数量(103对101)的类别需要分类。另一方面,花有额外的挑战(与Caltech101相比),尺度变化,姿势变化,类之间的相似性也更大。我们设计的特征和相应的内核,适合花类,捕捉花瓣的颜色,纹理和形状(局部和全局)及其排列。这将在第3节中介绍。第4节描述了图像数据集和实验过程,第5节给出了测试集的结果。
分割与分类
这是一个语义分割数据集,先介绍了分割的效果,然后介绍了采用的分类方法。
数据集和实验步骤
在本篇论文中,我们详细介绍了一个涵盖8,189张照片的数据集,这些照片被细分为103种不同的花卉类别。其中,大部分照片通过网络搜集而来,而少数则是我们亲自拍摄。这些照片在各个类别中的分布情况不一,每个类别包含的图像数量从40张到250张不等。此数据集进一步被划分为训练集、验证集和测试集三部分。训练集和验证集都由每个类别中的10张照片组成,共计1030张照片。而测试集则包含了剩余的6,129张照片,每个类别至少有20张照片。验证集的主要用途是调优包括视觉单词数量在内的各项参数,以及SIFT特征的半径和间距。在对验证集和测试集进行性能评估时,我们采取了与Caltech101/256相同的方法,即计算每个类别的平均性能而非所有图像的总体平均性能,以此作为最终的性能衡量标准。
结论
我们已经验证,通过在经过优化的内核框架中结合特征,能够显著提升对于高度相似类别的大型数据集的分类准确率。通过学习对不同类别施加不同的权重,我们得以针对每个分类挑选出最佳的特征组合。例如,某些类别在形状上极为相近,但在颜色上却有所不同;而另一些类别则是通过其整体形状而非内部细节更易于区分,反之亦然。目前面临的主要挑战是类内部的巨大变异性以及相对较少的图像样本量。因此,未来的研究方向应当包括采用视觉上相似的类别共同训练分类器。
个人总结
flowers102经典数据集论文,写作也很好。要注意的是这篇论文介绍了103种花卉,其中petunia矮牵牛出现了两次。
3. A large-scale hyperspectral dataset for flower classification(Knowledge-Based Systems, 2021)
摘要
花卉在我们生活中扮演着不可或缺的角色,它们不仅拥有深远的文化意义、显著的经济价值,还具备重要的生态功能。对花卉进行准确的分类,对于促进其多样化应用具有关键性意义。然而,目前用于视觉分类任务的数据集大多侧重于常规的RGB图像,这一局限性制约了深度学习技术在花卉光谱分析等专门领域的广泛应用。针对此问题,本文介绍了一个全新的、大型高光谱花卉图像数据集——HFD100,旨在推动花卉分类研究的深入发展。HFD100数据集特别包含了超过10700张来自100个不同类别的高光谱图像。此外,我们还在HFD100数据集上执行了若干基准测试,测试结果揭示了该数据集在类内和类间存在的明显差异性挑战。我们坚信,HFD100数据集的发布将有效促进花卉分类、花卉光谱分析以及细粒度分类领域未来的研究进展。该数据集将向整个研究社区开放,以供广泛使用。
背景
本文首先阐述了花卉在文化、经济、景观及生态方面的价值,以及花卉分类在多个领域中的广泛应用。接着,文章概述了以往花卉分类研究工作,主要分为两类。随着深度学习技术的快速进步,该技术已在多种图像分类任务中展现出领先的性能水平。然而,目前深度学习在花卉分类领域的应用仍受限于规模较小的数据集,这些数据集包含的样本数量有限,花种也相对较少。迄今为止,文献中最大的花卉图像数据集为OXFORD-102花卉数据集,但它的规模仍无法满足深度学习训练的需求,因此,迫切需要一个更为完整的花卉图像数据集。目前的分类数据集大多依赖于RGB图像。与RGB图像相比,高光谱图像能够更有效地分辨图像特征。虽然已有一些高光谱数据集存在,但这些数据集的样本以像素形式存在,收集周期较长,且在这些数据集上的研究方法已达到100%的测试准确率,显示出对新的、包含更多样本和物种的高光谱图像数据集的强烈需求,以更好地满足实际研究需求。随后,作者详尽介绍了本项工作中提出的数据集及其贡献。
- 本文全面综述了当前花卉数据集的现状,将这一工作作为本研究的重要贡献之一。
- 提出了一个新的高光谱花卉基准数据集,旨在激励研究社区提出新的、基于数据驱动的算法。
- 对目前最先进的分类算法在该数据集上的性能进行了评估和比较,以测试其分类精度。
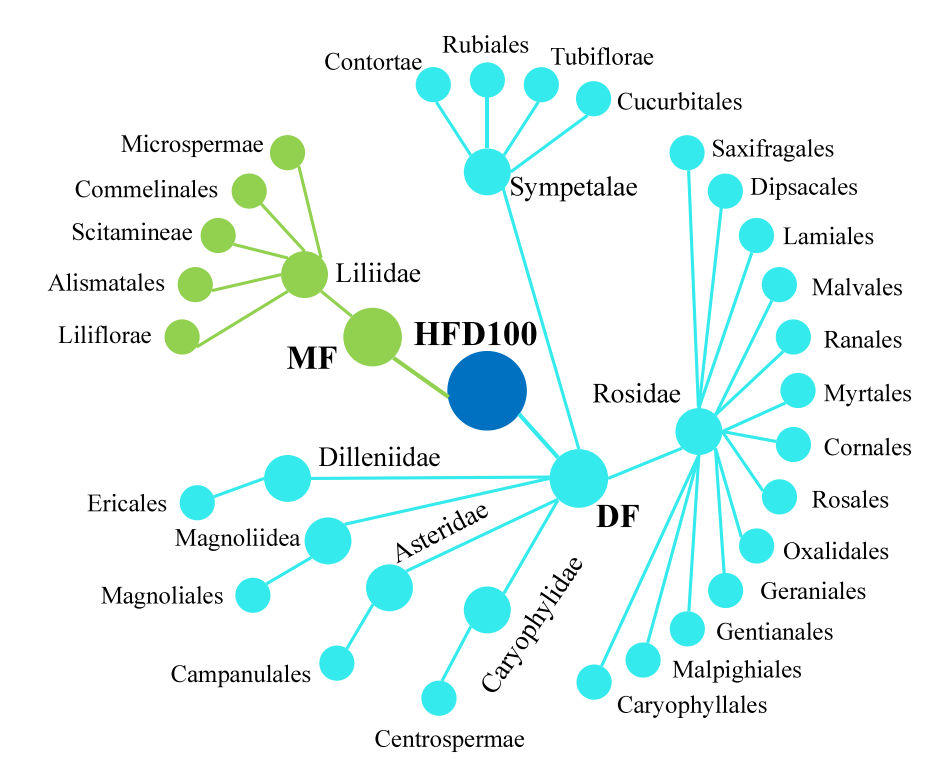
HFD100数据集的结构图如下所示。“MF”和“DF”分别表示单子叶花和双子叶花。
相关工作
- 相关的方法
-
基于手工设计特征的花卉分类方法
本段内容采用总分总的结构,分为三个主要部分进行介绍。首先,论文探讨了基于手工设计特征的花卉分类方法。这些方法利用手工设计的特征,如尺度不变特征变换(SIFT)、加速稳健特征(SURF)、方向梯度直方图(HOG)、局部二值模式(LBP)等,在捕捉低级特征表示方面展现出了良好的性能。众多研究人员采用了包括形状、颜色和纹理在内的各种花卉特征进行花朵识别。然后,文章详细介绍了依据形状、颜色和纹理特征进行花卉识别的相关文献,并对这些方法的局限性进行了分析。虽然这些基于手工设计特征的方法在早期取得了一定的成功,但它们在处理复杂花卉图像时面临着特征提取不充分、泛化能力有限等问题。最后,文章总结了基于手工设计特征的花卉分类方法所存在的缺点。尽管这些方法在某些场景下有效,但难以适应花卉分类任务的高复杂性和多样性,限制了它们在实际应用中的广泛性和准确性。 -
基于深度特征的分类方法
这段介绍的内容很多(个人觉得可以精简)。从AlexNet到SENet,以及各种轻量级模型,和迁移学习等等。主要讲述这些方法都存在某些缺点,而我们的工作可以解决什么问题。
- 相关数据集
- 花卉图像数据集
简单的介绍目前的一些花卉数据集,他们包含的种类和图片数量。总之,现有的花卉数据集存在样本数量少的缺点,无法满足深度学习模型的训练和测试。因此,需要一个具有更多样本和更完整类别的新数据集。 - 高光谱图像数据集
首先详细介绍目前有哪些高光图谱的数据集,以及他们的特点。最后总结由于高光谱图像的获取需要昂贵的硬件设备,并且非常耗时费力,因此上述现有高光谱图像数据集中的样本数量非常有限,这使得这些高光谱图像集无法像RGB图像数据集一样用于基于深度学习的分类方法的研究,也限制了它们在物体分类研究领域的应用。 - 遥感高光谱数据集
作者列了一个表介绍目前的基于遥感高光谱数据。然后介绍了这些数据集的单位和研究对象,以及数据集的空间尺寸。最后总结了这些数据集的缺点,以及对比而言,自己所提出数据的优势。
所提出的HFD100数据集
- 数据集的获取方式和预处理
- 数据结构
- 数据标注
- 数据集的特点
实验
这一部分分为了5个部分介绍:实验数据(介绍数据集收集的详细情况)、实验设置(介绍设备和模型设置)、评价指标评价结果与分析,以及讨论。
结论
本研究收集了一个大规模的高光谱花卉图像数据集HFD100,用于花卉分类,包括100个物种的超过10,700个高光谱图像。与之前的数据集相比,HFD100的最显著优势是样本数量和类别数量都比现有数据集大得多,更适合基于深度学习的分类研究。同时,我们还裁剪和标注了HFD100数据集中的场景样本图像,以获得更大规模的高光谱图像块数据集。此外,我们对HFD100数据集上的十种经典深度卷积网络分类方法进行了评估。未来,我们将在该数据集上进行更多的工作,包括目标检测注释、目标分割注释以及目标检测和分割的基准评估。希望这项工作能够推动未来在几个基本问题以及常见的物体分类、分割和细粒度分类方面的研究。
个人总结
该研究提出了一项大型的高光谱图像数据集,正如作者提到的那样,开源的大型高光谱数据集非常少,这是该论文的最大创新点和意义。我觉得这篇论文各方面而言不错,相关工作的部分介绍太多了一点。
4. Plant Disease Recognition: A Large-Scale Benchmark Dataset and a Visual Region and Loss Reweighting Approach (IEEE Transactions on Image Processing, 2021)
摘要
植物病害诊断在农业生产中扮演着至关重要的角色,其对作物产量有着显著的影响。尽管如此,目前仍缺乏对植物病害进行系统研究的工作。在这项研究中,作者成功构建了一个庞大的植物病害数据集,该数据集涵盖了271种植物类别和220,592张图片,为植物病害的诊断提供了宝贵的资源。利用这一数据集,作者开展了针对病害识别的研究。通过对视觉区域进行重新加权和调整损失函数,本研究旨在凸显受感染的植物部分,从而解决植物疾病识别的挑战。具体而言,作者首先根据这些分割的图块的聚类分布来计算每个图块的权重,这些权重用于指示各个图块的区分能力。接着,在弱监督训练阶段,作者将这些权重应用于每个图块-标签对的损失函数中,以促进区分性疾病部分的学习。最终,作者从经过损失函数重新加权训练的网络中提取图块特征,并采用LSTM网络对加权的图块特征序列进行编码,生成综合的特征表示。通过对该数据集以及另一公开数据集进行广泛的评估,本研究证明了所提出方法的有效性。作者期望这项工作能够推动图像处理领域中植物疾病识别技术的发展。
背景
植物疾病严重威胁全球粮食安全,导致全球范围内作物产量减少。根据统计数据,全球约20%至40%的作物损失是由于植物疾病所致。因此,植物疾病诊断对于预防植物疾病的传播和减少农业经济损失至关重要。大多数植物疾病诊断方法严重依赖分子检测或植物保护者的观察。然而,前者复杂且受限于集中实验室,后者耗时且容易出现错误。目前,基于图像的技术正在通过解读视觉内容广泛应用于各种跨学科任务,例如医学成像、食品计算和细胞图像分析。受益于机器学习,特别是深度学习的最新进展,我们认为植物图像分析和识别也可以为植物疾病诊断提供一种新途径。同时,视觉植物病害诊断的应用反过来促进了图像处理技术的发展。
植物图像分析领域的研究和探索已逐渐展开,包括利用无人机进行空中表型分析和进行叶片指纹识别等先进技术。然而,这些方法往往依赖于高成本的设备或需要复杂的分子技术,限制了它们的广泛应用。近期,随着深度学习技术的发展,一些研究尝试通过深度学习来识别植物病害。尽管如此,这些研究大多数直接从植物病害图像中提取特征,未能充分考虑到任务本身的特殊性。此外,这些研究往往仅限于使用类别较少、视觉背景简单的小型数据集。根据我们的研究,真实世界场景下拍摄的植物疾病图像主要展现出三个特点:(1)病变的随机分布:叶片上的损伤可能在任何位置随机出现;(2)多样化的症状:即便是同一种植物病害,在不同时间段,植物叶片上也可能展现出多种不同的视觉症状;(3)复杂的背景:图像背景的复杂性给病害识别带来了额外的挑战。
为了推动农业图像处理领域内植物病害识别的研究,我们构建了一个大型植物病害数据集PDD271。该数据集含有220,592张图片,覆盖271种植物病害类别。据我们所知,PDD271是农业图像处理研究中首个如此大规模且具有重要意义的植物病害数据集。此外,还展示了部分样本图片和根据类别数量降序展示了各类别的图片数量,并通过饼图展现了三个主要类别间的整体平衡,无论是从类别数量还是图片数量角度考量。所有图片均在真实环境条件下拍摄。
针对植物病害图像的特性,我们采取了一种新颖的方法来解决视觉上的植物病害识别问题,即通过重新加权视觉区域和损失函数。鉴于病变斑点的随机性分布,我们将图像划分为若干非重叠的块,并基于这些块的聚类分布来计算权重,以此标示每个块的辨识度。通过为不同块设置不同的权重,我们强化了病变块的影响力,同时减少了无关块的干扰。在弱监督训练过程中,我们还为每一对块-标签分配了权重,以便更好地学习到患病部位的信息。最终,我们从经过加权损失训练的网络中提取出块特征,并使用LSTM网络对这些加权的块特征序列进行编码,形成一个综合的特征表示。
总之,我们的主要贡献如下:
- 我们首次在农业图像处理社区对植物病害识别问题进行了系统的调查和分析。
- 我们提出了一种新颖的框架,可以通过多尺度策略和重新加权视觉区域和损失来强调植物病害识别中具有判别性的患病部位。
- 我们迄今为止收集了最大规模的带有271个植物病害类别和220,592张图像的PDD271标记植物病害数据集,并对新提出的PDD271进行了广泛评估,证明了我们方法的有效性。
相关的工作
A. 植物病害检测。主要介绍了目前植物病害的数据集,有规模小,类别少的问题,然后将PDD271数据集与其他植物病害数据集在图片数量、种类以及包含的类别进行了比较。
B. 细粒度视觉分类
考虑到植物病害图像的特点,我们设计了一种不同的细粒度识别方法,通过对视觉区域和损失进行重新加权,强调植物病害识别中的患病部位。我们的方法是启发式的,具有许多改进的可能性。例如,我们的方法和基于注意力的方法可以在一个框架中共同工作,进一步提高识别性能,如门控注意力深度网络。我们还可以方便地通过辨别性空间外观核将我们的框架与空间上下文结合起来,以提升性能。
数据集构建
由于植物病害的复杂性、多样性和变异性,构建一个具有高质量的大规模数据集是困难的。首先,构建农业数据集需要依靠许多不同领域的专家进行注释。例如,对苹果树和核桃树上的疾病进行注释需要不同的专家,这是需求特定且耗时的。其次,植物病害图像的收集受到时间和地点的极限。例如,梨黑斑病通常发生在五月份,而苹果环状腐烂病常发生在渤海海域。我们必须及时到达疾病发生地。
具体而言,数据集构建包括以下三个步骤。(1)分类系统建立。我们为PDD271数据集建立了一个四层次的分类系统。我们邀请了几位农业专家,并讨论了日常生活中存在的植物病害的常见类别。每种病害根据遭受该病害的植物被分配到一个上级类别。每个植物根据种植条件和植物形态被分配到一个上级类别。例如,苹果褐斑病破坏了苹果,而苹果属于果树。最后,我们构建了一个带有数据集根、宏类别、植物类别和植物病害的结构,第一层、第二层、第三层和第四层分别有1、3、43和271个节点。(2)数据集收集。为了收集大量的病害图像,我们组织了十个团队。每个团队由农业大学的八名学生和四名相关领域的专家组成。每个团队收集三十种疾病,每种疾病包含来自不同植物的五百多张不同的图像。专家负责保证病害图像的质量和注释。在拍摄图像时,一个标准的协议是相机与植物之间的距离在[20cm,30cm]之间,以确保类似的视觉范围。每个植物病害类别至少包含500张图像,并且每个类别至少捕获了200个植物。此外,可以从不同角度拍摄一棵植物。这是为了获得更高的网络泛化能力而使植物病害数据多样化。(3)数据集处理和扩展。在图像收集后,每个图像由三位专家检查以确保标签的正确性。然后,专家删除模糊图像和其他噪声图像,保持数据集的清洁。对于图像较少的类别,我们进一步收集更多图像来保证每个类别的图像数量。(这一段对数据集的结构介绍写的不错可以参考)
整个数据建设耗时约2年。生成的PDD271包220,592个图像和2,71个类别。每个类别的最小图像数超过400张,最大图像数为2000张。均衡的分布保证了模型训练的稳定性。可靠的数据集在开发特定领域的图像处理技术方面发挥着至关重要的作用。所提出的数据集PDD271提供了广泛的植物病害覆盖范围和多样性。它将进一步推进植物病害识别议程,并将图像处理技术扩展到农业领域。
工作的框架
在本节中,我们详细介绍了我们提出的框架,该框架采用了多尺度策略,并在弱监督学习环境下对视觉区域和损失进行了重新加权。这样做旨在突出植物病害识别中具有显著区分能力的患病部位。众所周知,许多植物疾病呈现为细小且分散的病变,如南瓜霉病、梨树蛙眼叶斑病和猕猴桃褐斑病等。采用图像级标签进行训练的深度卷积神经网络往往会忽略这些微小病变,转而关注更为显眼的图像区域。为了应对这一挑战,我们采纳了一种多尺度策略,通过将图像分割成不重叠的补丁并对每个补丁进行放大,确保不会遗漏任何患病补丁。然而,这种做法也带来了新的问题:在放大过程中,与疾病无关的补丁(例如复杂背景和健康植物部分)也会被同样放大,从而可能导致患病补丁与无关补丁之间出现严重的不平衡。为了克服这一难题,我们尝试通过利用相同疾病补丁之间的视觉相似性,将它们进行聚类。接下来,依据聚类结果,我们对补丁进行重新加权,准确地指示出每个补丁的区分能力。这种方法不仅提高了患病区域的辨识度,同时也优化了模型对于植物病害识别的整体性能。
实验
A. 实验设置
1)数据集划分和评估指标:PDD271包含属于271种疾病的220,592张图像。我们按照大致7:2:1的比例进行划分 (一般应该都是6:2:2)。PDD271被划分为154,701张训练图像,44,002张验证图像和21,889张测试图像。我们采用Top-1分类准确率作为评估指标。
2)超参数设置:所有图像被调整为224×224大小。每个图像被分割成4×4的补丁。初始学习率为0.001,并在每20个epoch后通过标准SGD优化器除以10。我们在所有实验中采用随机水平翻转的数据增强方法。我们的项目将在https://github.com/liuxindazz/PDD271上提供(实际上作者到2024年初没有提供代码和数据集,此外写到代码将在某某处提供一般写在摘要上)。
B.PDD271数据集上的实验
作者对自己的方法与其他模型方法进行了精度对比。结果表明作者提出的改进方法比GoogleNet精度高了0.02.
结论
在本文中,我们系统地研究了图像处理社区中植物病害识别的问题。在农业专家的帮助下,我们构建了第一个具有271个植物病害类别和220,592张图像的大规模植物病害数据集。此外,我们提出了一个基于植物病害特征的植物病害定向框架。我们设计了一种基于补丁特征的聚类分布计算补丁权重的策略,然后使用学习到的权重来重新加权补丁特征以突出患病补丁,并使用损失来指导模型优化。PDD271和PlantVillage数据集的定量和定性评估证明了所提出方法的有效性。然而,我们方法的一个不足之处是加入训练前的聚类过程使得该方法速度较慢。我们将在未来尝试加速我们的方法。另一个有趣的工作是分析补丁的随机未固定顺序的影响。随机未固定顺序增强了性能,这乍一看可能很反直觉。此外,我们可以进一步考虑更先进的LSTM变体作为传统LSTM的替代品.
个人总结
在整篇论文的撰写过程中,数据集结构的介绍部分尤其值得学习和借鉴。然而,尽管该论文所采用的方法并不具备新颖性,作者承诺将项目代码和数据集公布于GitHub上。遗憾的是,距论文发表已多年,在2024年初相关代码和数据集仍未被公开。若作者在投稿时便明确表示不会分享数据集和代码,那么该论文将难以在该期刊上得到发表。
5. PlantPAD: a platform for large-scale image phenomics analysis of disease in plant science (Nucleic Acids Res,2024)
摘要
植物病害构成了一个严重的挑战,有时甚至能导致高达100%的产量损失,同时也加剧了食品安全问题。在这种背景下,采用植物表型组学进行智能病害诊断显得尤为关键,这一过程往往依赖于充足的图像数据。因此,表型组学作为一个独立学科备受青睐,旨在发展高通量表型鉴定技术,以有效应对植物病害挑战。然而,面对不同社区提供的格式各异、描述不一的图片资料,我们常常遭遇大规模图像数据处理的难题。为此,我们开发了一个专门的植物病害表型分析平台,该平台汇集了大量病害信息。我们的平台拥有421,314张图像、涵盖63种作物和310种疾病。与其他数据集相比,PlantPAD提供了大量经过标注的图片和深入的疾病信息,并配备了深度学习预训练模型,以实现病虫害的精准诊断。PlantPAD支持多种有价值的应用场景,包括智能疾病诊断、病害培训以及广泛的疾病检测与控制功能。通过这三个核心应用,PlantPAD展现了其易用性和便捷性。该平台主要服务于生物学家、计算机科学家、农产品管理者、农场经营者以及农药研究人员等专业人士。PlantPAD可通过http://plantpad.samlab.cn免费访问。
背景
植物病害的发生可导致农业生产遭受重大损失,威胁粮食安全和农业可持续性。为了有效减缓这些挑战,采用表型组学的智能农艺技术对于识别和管理植物病害尤为关键。通过精准的植物病害管理,我们不仅能够保护农作物,还能确保粮食供应的稳定性。在植物病害的表型分析领域,主要采用两种方法:专家人工识别和机器自动识别。随着表型组学技术的进步,基于图像的植物病害识别不仅为专家提供了重要的培训资源,还通过挖掘疾病模式的相关信息和特征,极大地提升了机器学习算法的准确性和效率。尽管表型组学技术取得了显著进展,并且相关研究不断涌现,但数据共享过程中的多种挑战,如数据格式不一、观测描述不统一、数据量庞大以及注释的不完整性等问题,仍然限制了跨学科研究的深入开展。为了克服这些挑战,我们团队创建了一个名为植物病害表型组学分析(PlantPAD)的综合数据库。该数据库汇集了421,314张图像,覆盖63种作物和310种病害,旨在通过图像和文字信息,为植物病害的识别与分析提供全面的支持。PlantPAD成为了连接农业生产、教育培训和科学研究的重要桥梁。我们的植物病害图像数据库具有以下几个优势:
- 数据丰富性:拥有广泛的植物病害图像数据,满足不同用户群体的多元需求。
- 信息详实性:提供细致的图像标注和丰富的病害相关信息,增进用户对植物病害的了解,提升管理效能。
- 高效诊断:结合预训练的深度学习模型进行植物病害诊断,显著提高识别和分析的效率。
图像信息采集
在我们搜集的数据中,81.04%的图像源自网络资源,其中33.08%得自各类网站,31.42%来源于其他数据库,而16.54%来自参考文献。另外,有18.96%的图像是通过现场直接拍摄获得。在线搜集图片时,我们首先广泛检索了信誉良好的平台和研究库中提供的开放数据集。这些数据来源涵盖了专注于植物病害及其相关领域的农业研究机构、学术机构和政府机构。在此过程中,我们综合考量了数据来源和规模、相关组织或研究人员的声誉与可信度、所覆盖的疾病种类数量以及标签和注释的准确性与一致性等多个因素。对于田间采集的部分,为确保数据集中每张图像的标注既准确又一致,我们邀请了七位农业专家加入我们的数据集构建工作,并依据分类及命名指南进行图像标注。在标注过程中,我们记录了每张图像的拍摄时间、地点、物种和环境等元数据信息,确保数据集具备充足的数量、多样性和准确性,便于后续的数据处理与分析。此外,鉴于疾病发生的时间和地点具有不确定性和碎片化特征,我们采取了结合野外摄影和在线搜集的方法,以增强数据的数量和多样性。最终,我们通过在线和现场采集相结合的方式,完成了图像数据集的建立。为了深入解析不同植物的病害模式,我们设计了一个基于植物种类和常见病害类型的分层分类系统,用于标记和组织数据集。该系统包括根目录、植物类型目录、植物物种目录以及疾病子目录。例如,水稻叶枯病的目录结构表示为/staple crops/rice/leaf blight/。为保证数据库中数据的时效性和可靠性,我们实施了定期更新计划,持续添加新的图像和相关信息,以反映植物病害领域的最新发现和当前态势。
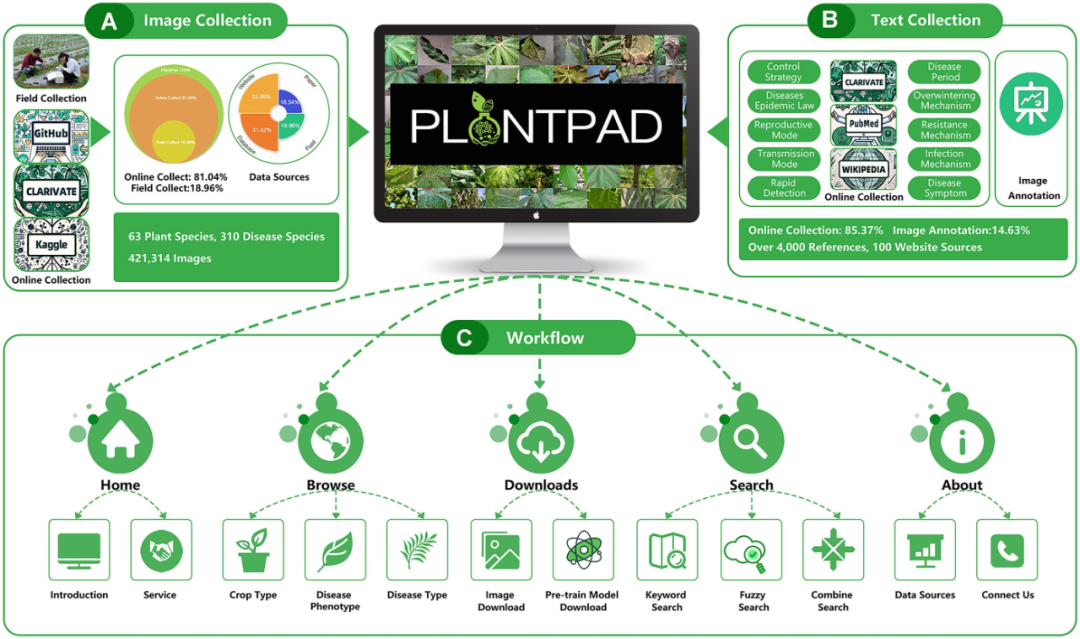
文本信息采集和图像标注
我们的文本数据构成呈现出两个主要部分:其中85.37%的疾病相关信息源自互联网,而剩下的14.63%为我们提供的描述性注释,如图所示。这两种类型的文本数据均经过严格的质量控制与管理流程,旨在保证其准确性、完整性和一致性。这些数据主要收集自书籍、研究机构报告以及农业信息平台等多样化资源。在PlantPAD数据库中,关于植物病害图像的描述性信息分为三个不同的类别。首先是图像元数据,它记录了所有图像共有的基础属性信息,涵盖图像的来源、格式、尺寸、分辨率及清晰度等关键数据。其次是文本注释,这部分内容为精心编撰的文本数据,专门设计以符合植物病害识别过程中的常见特征和搜索需求。最后,我们提供了对图像中展现的特征的文本描述,这些描述详细涉及疾病的形态、颜色和空间分布等多个维度。这些文本描述的目的在于增强和补充图像数据,使之更加丰富和完整。
工作流程
PlantPAD平台的工作流程融合了几个关键环节,如下所述。首先,用户登陆平台主页,可初步了解数据库的核心内容,包括其概述及一系列用户友好的服务功能。紧随其后,通过浏览功能,用户得以利用多种分类手段(如按作物类型、疾病类型或表型)进行植物病害图像的探索。这一简化搜索过程极大地方便了用户迅速找到所需图像,满足其特定需求。除了便捷的图像下载选项和针对具体疾病的图像资源外,PlantPAD进一步提供了PDDD-PreTrain服务。这是一个基于深度学习的植物病害预训练模型库,旨在通过挖掘大型植物病害数据集的丰富性与多样性,从而学习到更加专业和适用的植物病害特征及知识,增强模型的泛化能力和鲁棒性。实验结果已证明,PDDD-PreTrain能够显著提升多个植物病害诊断子任务的准确性和效率。此外,用户还可通过搜索功能,结合关键词、模糊词汇及组合搜索策略,精准地定位到所需的植物病害图像。最终,用户还有机会获取到数据库的详细信息和开发团队的联系方式,以便进一步探索相关功能。
数据统计
我们对健康植物和不同类型植物疾病的图像数据进行了详细的比例分析。具体而言,数据集中33%的图像展示了健康的植物状态,而剩余的67%揭示了各种植物疾病的影响,其中包括42%的图像描绘了真菌引起的病害,14%反映了病毒性疾病,7%展示了细菌性疾病,以及各占2%的图像分别代表了卵菌病和生理性疾病。在这些疾病中,真菌病害因其给植物带来的极大损害而特别引人注目,占据了图像数据中相当大的比例(42%),明显高于其他类型的疾病。这一现象反映了真菌病害在植物疾病中的普遍性和严重性。为了更加直观地呈现这些疾病图像在数据库中的分布情况,我们对数据库内63种植物疾病的图像进行了深入的编号、分析和可视化处理。
网页设计
- 前端
采用 Vue 框架,我们精心开发了一个基于组件和响应式设计的前端界面,专门为植物与疾病数据集而设计。该界面提供了一种直观的方式,让用户能够轻松浏览不同的作物类型及其相关疾病类别,并通过高效的分类和搜索功能,快速检索到关于植物和疾病的详细信息。数据集覆盖了三种主要的作物类型:主食作物、经济作物和园艺作物,用户可以便捷地通过点击标记按钮来访问这些信息。此外,用户还能通过选择相应的标签,深入了解各种疾病类型,包括真菌疾病、细菌疾病、病毒性疾病、卵菌疾病以及生理性疾病等。界面还特别支持根据颜色、纹理和叶片形态等多种属性进行搜索,极大地提高了信息检索的准确性和效率。
- 后端
利用 MySQL 8.0.12 和腾讯云操作系统,我们精心打造了 PlantPAD 的后端系统架构,旨在为前端应用提供高效、稳定的数据交互服务。本系统专门设计以处理前端接口发起的请求,并能够从数据库中准确检索出关于植物及其相关疾病的细致信息,包括但不限于作物种类、疾病类型以及多样化的属性信息。通过精确地处理用户的筛选与搜索需求,该后端系统能够灵活地过滤并抽取所需数据,以响应前端的查询请求。此外,系统还支持图片和文件的上传功能到腾讯云操作系统,并能为前端应用生成相应的文件访问链接,进一步丰富用户体验。我们特别注重后端系统的数据安全性、稳定性及处理效率,以确保为前端接口提供快速准确的数据支持。得益于腾讯云操作系统的高稳定性和良好的可扩展性,该系统能够有效地管理和存储大量数据及文件,保障数据的高可靠性和便捷可访问性,为用户带来无忧的使用体验。
网站功能及用途
PlantPAD是一个开放免费的在线数据库平台,旨在为用户提供便捷的植物病害数据及人工智能模型浏览、搜索和下载服务。该平台设计了直观的用户界面,允许用户根据作物类型、疾病类型或表型特征进行数据浏览,同时支持关键词或多条件组合搜索,以便用户精准定位所需信息。此外,用户还可以轻松下载所需的图像资料和预先训练好的模型,如图 3A 所示,进一步促进科研工作的便捷性。为了帮助用户更好地了解平台,PlantPAD还设有手册页和关于页,详细介绍了PlantPAD团队背景、数据来源及联系方式等重要信息,增强了平台的透明度和可信度。
数据库应用程序
PlantPAD在病害诊断、植物病理学教学和病害人治安中发挥着重要作用。为了从三个方面详细介绍PlantPAD的便利性和功能性,我们选取了果树、粮食和蔬菜的典型案例。
案例1: 如何在智慧农业中训练和使用梨病诊断模型
开发高效的智能梨病诊断技术对于提升病害控制的效率具有至关重要的作用。通过PlantPAD平台,用户得以运用分类、检测及分割模型对梨病进行准确诊断。首先,在图像下载界面上,用户能够获取到所需的疾病图像数据。随后,这些梨图像被划分为训练集(用于构建病害诊断模型)、验证集(用于校验预测结果的准确性)以及测试集(用于评估模型对未知植物病害图像的诊断能力)。特别地,用户能从PlantPAD下载梨病图像数据,并创建梨病数据库,从而为植物病害诊断模型的训练和验证提供数据支持。经过预处理(如数据清洗或增强)的训练集和验证集将被用于模型训练。在此过程中,卷积神经网络负责将图像转化为可区分的植物病害表型特征图,进而通过RPN及ROI对齐模块进行深度处理以捕捉关键特征。此外,这些特征将被送往分类器以确定疾病种类,定位器以确定疾病位置,以及掩码分支以量化疾病程度。反向传播机制通过将模型结果与验证数据结果进行对比,不断优化模型性能。最终,经过充分训练的梨病模型能够在实际应用中准确识别梨病情况。因此,PlantPAD极有潜力在开发梨作物病害诊断模型方面发挥重要作用,促进梨病害的快速识别、定位和分类。目前,PlantPAD已成为设计和实施植物病害诊断模型的可靠数据源。然而,在PlantPAD的应用中,仍存在一些亟待解决的问题:(1)数据分布的不均衡性导致难以获取有效且可区分的植物表型特征,影响利用有限图像数据进行植物病害诊断的能力;(2)图像质量低下,如失焦和模糊的图像,以及某些品种(比如枣和核桃)的图像数据稀缺,可能会削弱诊断模型的性能;(3)尽管PlantPAD提供了植物病害类别的图像注释,但这些注释还缺乏针对病害位置和程度的进一步细化。
案例2: 如何向学生教授玉米病害知识
以玉米种植为例。PlantPAD数据库包含了与玉米病害相关的图像和文本信息,可以帮助教师使用生动的材料向学生传授这些类型的病害、病害形态和常见发生情况。首先,在数据库的主页上,浏览窗口用于定位作物类型界面。在那里列出了三种类型的作物:主要作物、园艺作物和经济作物,其中玉米属于主要作物。选择玉米的作物类别后,会出现各种玉米病害,如细菌条斑病、褐斑病、北方叶枯病、细菌性枯萎病和圆锥孢病。最后,通过点击细菌条斑病,我们可以了解更多关于该病害的定义和特征、传播方式、发病期和条件、越冬方式、检测方法和感染机制等信息。对于玉米细菌条斑病发病期,病害可以在玉米生长的任何阶段发生,但通常在抽雄后症状更加明显。该病害需要温暖(25°C)和湿润(90%)的环境才能感染和发展症状。该病害可以通过雨水、灌溉、风、昆虫和污染的设备传播。我们的数据库可以提供关于玉米病害的教学目的,并帮助学生更深入地了解病害的生命周期、检测和流行情况。
案例3: 如何在田间工作中找到辣椒病害的防治策略
PlantPAD可以为辣椒整个生长过程中的炭疽病管理提供系统的策略和方法。首先,现场工作人员可以通过定位凹陷的坏死同心环、环状病变和分生孢子或刺痛来捕捉果实和叶子中发生的辣椒炭疽病的图像。然后,要了解如何控制这种疾病,从数据库的浏览页面,用户可以单击作物类型,选择蔬菜并查看一些疾病图片。选择辣椒并比较“疾病描述”页面上的图像后,将辣椒叶和果实上的斑点进行匹配。同时,在浏览页面上,我们还可以通过查找真菌病找到辣椒炭疽病。找到病种后,可根据图片和文字描述确定辣椒炭疽病。最后,我们获得了可用于治疗辣椒炭疽病的化学、物理、生物和农业控制措施。因此,我们的数据库可以帮助现场工作人员方便快捷地提高他们在辣椒炭疽病防治方面的知识和技能。
个人总结
本篇论文详细介绍了一个由组合收集(占比18.96%)、网络资源及文献资料共同构建的庞大数据集,该数据集包含超过40万张图像。研究团队不仅搭建了展示这一数据集的前端和后端网页界面,还提供了下载链接,便于公众查阅和使用。该项目的显著优点在于,研究团队成功创建了数字化资源,通过网页形式进行展示,并对不同植物的多种病害按类型、颜色等属性进行了系统分类。
然而,论文也存在一些不足之处。首先,没有将整个数据集公开,限制了其潜在的应用与研究价值。其次,网页设计和后台服务存在缺陷,如用户在点击网页内容时反应速度缓慢,这影响了用户体验。更重要的是,从学术角度来看,该论文难以在计算机科学领域的期刊上发表(实际上该论文发表在生物类期刊)。原因有几方面:首先,尽管数据集庞大,但大部分图片来源于网络,缺乏原创性也没有实验设计;其次,论文在网页设计方面的介绍过多,而技术应用方面的亮点不足;最后,缺少基于该数据集的基准模型结果,这对于展示数据集的实际应用价值至关重要。
6. PDDD-PreTrain: A Series of Commonly Used Pre-Trained Models Support Image-Based Plant Disease Diagnosis (Plant Phenomics, 2023)
摘要
植物病害对全球粮食安全构成严重威胁,通过削减作物产量来影响农业生产。因此,精确诊断植物病害对于保障农业生产的稳定和提高产量至关重要。随着人工智能技术的快速发展,传统的植物病害诊断方法由于其耗时长、成本高、效率低和判断主观等缺点,逐渐被人工智能所替代。在众多人工智能技术中,深度学习作为一种先进的方法,极大地增强了精准农业在植物病害检测和诊断方面的能力。目前,植物病害诊断领域普遍采用预训练的深度学习模型来辅助病叶的准确诊断。然而,这些广泛应用的预训练模型大多源自计算机视觉领域的数据集,而非专门针对植物学的数据集,导致它们缺乏足够的植物病害相关知识。这种预训练方式的局限性使得最终的诊断模型在区分不同植物病害时面临挑战,从而影响了诊断的准确性。为了解决这一问题,我们开发了一系列基于植物病害图像的预训练模型,旨在提高病害诊断的性能。我们还对这些植物病害预训练模型在多个植物病害诊断任务上进行了实验验证,包括植物病害识别、检测、分割以及其他相关子任务。实验结果表明,相比现有的预训练模型,这些专门针对植物病害优化的预训练模型能够在更短的训练时间内达到更高的准确率,从而为植物病害的精确诊断提供了更为有效的支持。此外,我们的预训练模型将在 https://pd.samlab.cn和Zenodo平台https://doi.org/10.5281/zenodo.7856293开源。
背景
植物病害诊断在农作物生产中扮演了至关重要的角色(强调研究主题的重要性)。鉴于绝大多数植物病害的症状主要表现在叶片上,叶片因此成为识别当前植物病害的主要依据。随着机器学习技术,尤其是深度学习技术的兴起,计算机视觉领域已实现显著进步。这些方法也被应用于植物病害的识别与检测中,因为基于深度学习的模型能够有效地从图像中提取出高层次的语义信息和底层的细节信息,作为病害特征的有力表示。尽管许多学者已开展了相关研究,但利用CNN(卷积神经网络)结构来诊断植物病害仍存在一些不足,包括复杂的处理流程、性能与效率的局限以及面临的应用挑战(引出研究方法)。因此,那些具备卓越计算机视觉潜能的预训练模型开始被逐渐应用于植物病害的诊断中。预训练模型成为深度学习方法成功应用于植物病害诊断的关键,其中包含了图像处理的基础先验知识。常见的预训练模型基于ImageNet数据集的先验知识,该数据集包含1,000个类别,使用1,281,167张图像进行训练,50,000张图像进行验证。作为深度学习领域的一个标志性成就,该数据集已成为众多计算机视觉任务的基准。然而,专门针对大型植物病害数据集的预训练模型尚未问世,这限制了在植物病害诊断方面进一步提升的可能性。由于大部分ImageNet或其他非植物类数据与植物病害无直接关联,导致预训练模型缺乏充分的植物表型知识,这在一些子任务(如识别、检测、分割等)中影响了植物病害诊断的准确性。为解决这一问题,我们基于大规模植物病害数据集构建了一系列常用的预训练模型,命名为PDDD(植物病害诊断数据集)。首先,我们收集并整理了涵盖40个植物物种、120个病害类别的超过40万张相关图像,创建了一个庞大的植物病害数据集。同时,我们对该数据集进行了标准模型的预训练,以确保预训练模型充分掌握植物病害领域的专业知识。我们将这些植物病害预训练模型作为开放资源分享,以便所有后续研究都能从植物病害预训练模型的便捷性中受益。
材料与方法
这里作者主要介绍了自己数据集和目前已公开数据集的差异。以及自己拍摄图像的位置的来源。然后建立了图像分类系统。以及是如何进行的野外摄影和在线搜集网络图像。然后介绍了Plant Village以及FGVC(我个人觉得这段介绍的原文写的有点啰嗦),介绍了该数据集从这两个数据集中应用了部分图像。后续又介绍了详细两个公开数据集,从这4个公开可用数据集获得了共计79,260张图像。田间采集的植物病害图像与在线收集的图像之间的比例约为8:2。(意味着这个包含40W张图像的数据集有32万张图是自己拍摄的,这么庞大的数据却没有公开)7位农业专家核实每张图像的标签是否正确,并对数据集进行最终清理,移除模糊、失焦或有其他干扰因素的图像。此外,对于少于100张图像的类别,对该类别下的图像进行图像增强。(因为数据集未公开,所以不知道有多少个类别少于100张图像)。 然后作者介绍了自己数据集的图片数量。类别数目,以及包含植物的类型。(这个是介绍数据集的一个常见方式)

植物病害预训练模型
(1)选择预训练模型:我们首先编制了一份通用模型结构列表,以找到用于植物病害诊断的最佳预训练模型。(2)模型训练:基于收集到的预训练模型,我们采用一些常用的技巧在我们的数据集上训练模型,确保这些模型能够充分吸收植物病害的知识。首先,我们将收集的大规模植物病害数据集中的训练集、验证集和测试集比率设置为8:1:1,并随机分配图像 (计算机常用的比例应为6:2:2)。(3)选择预训练模型。比较了4个预训练模型在测试数据集上的性能,包括随机生成的参数模型、仅使用ImageNet数据集的预训练模型、仅使用大规模植物病害数据集的预训练模型,以及同时使用ImageNet和大规模植物病害数据集的预训练模型。
如何使用预模型
我们开源了所有植物病害预训练模型,以改善植物病害诊断的发展,并将计算机视觉方法与农业相结合。用户可以通过我们的链接访问这些模型权重。此外,我们尽可能地保持与常用模型论文中的结构接近的结构,以提高植物病害预训练模型的可用性。只需对原始代码进行微小的更改,用户就可以将预先训练的植物病害模型用于他们的数据集和任务,从而实现更快、更精确的诊断
结果
为了证明我们提出的植物病害预训练模型的进步水平,我们在植物病害识别、植物病害检测和植物病害分割的植物病害诊断任务中进行了多次实验。
选择预训练模型
比较了4个预训练模型在测试数据集上的性能,包括随机生成的参数模型、仅使用ImageNet数据集的预训练模型、仅使用大规模植物病害数据集的预训练模型,以及同时使用ImageNet和大规模植物病害数据集的预训练模型。
植物病害分类
植物病害分类是植物病害诊断中的一项关键且普遍的任务,其中根据病害的表型进行识别。随着深度学习的出现,通过这种技术进行植物病害识别,由于其成本效益和效率,正在迅速取代传统的人工识别。目前流行的基于深度学习的植物病害分类方法采用图像多分类技术,在现有的植物病害分类任务中取得了显著的准确性。这些方法利用神经网络通过在多个标签中选择最相似的类别来识别图像中的植物病害。
此外,将基于PlantVillage数据集的植物病害预训练模型和基于PlantVillage和ImageNet数据集的混合预训练模型纳入植物病害分类任务,以确认植物病害预训练模型从数据集中学习了先验知识,并验证了基于PDDD的预训练模型的有效性。基于PlantVillage数据集的预训练模型的训练方法与基于PDDD的预训练模型相似,不同之处在于基于PlantVillage数据集的预训练模型是通过随机参数对PlantVillage数据集进行预训练来实现的。另一方面,基于PlantVillage和ImageNet数据集的混合预训练模型是通过对PlantVillage数据集上的官方权重模型的迁移学习来实现的。
预训练模型的比较
我们在测试数据集上比较了 4 个预训练模型:使用随机参数初始化的模型、仅使用 ImageNet 数据集的预训练模型、仅使用 PDDD 的预训练模型以及使用 ImageNet 和 PDDD 的预训练模型。这 4 个模型在 Kaggle 公共数据集上进行了训练和测试,我们的训练集和测试集被划分为 9:1 的比例(这个比例不太合理)用于模行比较。
讨论
预训练模型支持植物病害诊断方法的进步和深度学习技术在植物病害中的逐步普及。所提出的植物病害预训练模型在不改变现有诊断模型结构的情况下,大大减少了训练时间,提高了模型的准确性。此外,我们提出的植物病害预训练模型提供了一系列用于便携式设备快速诊断的模型,以及实验室中的准确诊断,为各种植物病害诊断任务提供了一系列模型。这些将为当前精准农业的发展做出重要贡献。预训练模型经常用于基于深度学习的植物病害诊断方法,一些研究已经认识到这些模型的全部潜力。然而,相关研究并未进一步研究这一现象,因此预训练模型在植物病害诊断中的潜力仍未得到探索。我们提出的预训练模型为植物病害诊断带来了有希望的结果。使用大规模的植物病害数据集,我们为预训练模型提供了足够的植物病害领域知识。同时,我们将ImageNet的通用知识提供给预训练模型,结合这两类知识,可以让植物病害预训练模型获得更鲁棒的植物病害特征表示。
个人总结
该论文的创新点在于使用了40W张植物图片数据建立了植物病害的预训练模型,这篇论文提出的预训练模型的方法很简单,并没有在方法上创新。事实上这篇论文和上一篇论文PlantPAD: a platform for large-scale image phenomics analysis of disease in plant science (Nucleic Acids Res,2024是同一单位同一作者,如果作者将两篇论文合为一篇来发表,并公开数据集将会是一个代表性的工作。
7. Phenotypic Analysis of Diseased Plant Leaves Using Supervised and Weakly Supervised Deep Learning (Plant Phenomics, 2023)
摘要
本文通过深度学习分析了像素级表型特征(斑点的分布)。首先,收集了病叶数据集,并贡献了相应的像素级注释。使用苹果叶样本数据集进行训练和优化。另一组葡萄和草莓叶样本被用作额外的测试数据集。然后,采用监督卷积神经网络进行语义分割;此外,还探讨了弱监督模型进行疾病斑点分割的可能性。设计了Grad-CAM与ResNet-50(ResNet-CAM)相结合,并结合少量预训练U-Net分类器进行弱监督叶斑分割(WSLSS)。他们使用图像级注释(健康与患病)进行训练,以降低注释工作的成本。结果表明,监督的DeepLab在苹果叶数据集上取得了最佳性能(IoU = 0.829)。弱监督 WSLSS 的 IoU 为 0.434。在处理额外的测试数据集时,WSLSS 实现了 0.511 的最佳 IoU,甚至高于完全监督的 DeepLab (IoU = 0.458)。尽管监督模型与弱监督模型在IoU方面存在一定差距,但在处理未参与训练过程的疾病类型时,WSLSS表现出比监督模型更强的泛化能力。
背景
深度学习方法具有许多优点,可以被认为是植物病害分割的有力工具。然而,卷积神经网络 (CNN) 分割模型的训练过程需要足够的样本和像素级注释。像素级标注制作的时间和体力成本很高。据我们所知,大多数公共数据集仅为分类研究提供图像级注释。很少有带有像素级注释的出版物。弱监督学习是一种尝试使用未充分注释的训练样本的新想法,已成为近年来的热门话题。当用于分割目的时,这些方法从与目标类相关的中间特征生成注意力图、显著图、解释图或类激活图(CAM),以确定分配具有相同类索引的对象的位置。使用弱监督学习方法,CNN模型应该被告知图像中涉及哪些对象,然后它可以输出对象所在的位置。这种方法的优点可以在注释的成本中找到。本研究基于深度学习和计算机视觉对病叶表型进行了实验。提出了一个同时具有图像级和像素级注释的植物叶片数据集。建立监督训练下的DeepLab模型和U-Net模型作为基线。受到这些弱监督学习新思想的启发,探索了使用图像级标注训练的 CNN 模型实现疾病斑点分割的可能性。
材料与方法
数据
本研究从互联网上发布的多个数据集中收集了植物叶片的RGB图像。作者准备了用于训练和评估语义分割模型的注释。我们将图像和相应的注释上传到 Mendeley 数据存储库 https://data.mendeley.com/datasets/tsfxgsp3z6。该数据集也可在 https://pan.baidu.com/s/1y7K2dVpfkQ3HVOU1qEeChQ 获得(密码:ecff)。下面将详细介绍数据集准备工作。
图像
图像是从公共数据集中收集的,包括一个名为Plant Village的流数据集(可在 https://data.mendeley.com/datasets/tywbtsjrjv/1 获得)和患病苹果叶数据集(可在 https://aistudio.baidu.com/aistudio/datasetdetail/11591 获得)。为了统一不同来源图像的格式,将病苹果叶数据集中的图像调整为256×256分辨率,并通过旋转、翻转、亮度和对比度值调整来增强植物村数据集中的图像。
标注
对于用于分类和分割的数据集的配置,采用6:2:2的比例将样本分为训练数据集、验证数据集和测试数据集。其余部分(即葡萄叶病和草莓叶病的图像)被定义为一个额外的测试数据集,用于在处理训练和优化过程中不涉及的疾病类型和叶型时检查模型的泛化能力。
病害分割方法
用于细分的监督CNN
本研究采用简化的U-Net模型进行叶病斑分割。该模型最显着的特征是使用跳过连接。它将浅层卷积层(具有丰富的低级信息)的特征传递到高级卷积层,更有利于生成分割掩码
弱监督分割方法
提到的 U-Net 和 DeepLab 模型需要监督学习程序。模型训练的基本事实是与要分割的图像具有相同宽度和高度的掩码(像素级注释)。换句话说,在基于监督学习的训练过程中,模型需要知道疾病点的位置。本研究探索了弱监督病斑分割方法,在模型训练过程中需要告知叶片是否健康(图像级标注)。然后,训练后的模型可以区分病变区域并实现语义分割。受Grad-CAM特性的启发,本研究设计了2种弱监督CNN模型。第一种是 ResNet-50 分类模型和 Grad-CAM方法的组合,该方法被定义为 ResNet-CAM。第二种解决方案结合了少量预训练特征提取器、二元分类器和 Grad-CAM 方法,用于弱监督叶斑分割,定义为 WSLSS。
性能指标、硬件和软件
使用苹果叶样本数据集对CNN模型进行训练和评估。此外,将所有制备的病葡萄叶片和病草莓叶片图像作为额外的测试数据集,以检验所研究模型的泛化能力。分割方法的性能通常通过并集交 (IoU)、精确度和召回率来评估。
结果
首先,分析了病苹果叶片的分割性能;弱监督分割方法中使用的二元分类器取得了令人满意的分类精度(>98.5%)。U-Net-S 和 DeepLab-S 取得了非常高的性能,明显优于所研究的弱监督模型,包括 ResNet-CAM 和 WSLSS。DeepLab-S 在预测数据集上实现了最佳性能,IoU = 0.829、Precision = 0.897 和 Recall = 0.905。对于弱监督模型,典型的方法被定义为DeepLab+Pseudo(使用Grad-CAM生成的伪标签训练的语义分割模型),在测试数据集上实现了0.190的IoU、0.287的AP和0.505的AR。如果没有基于伪标签的再训练和 ExG 方法,这些方法的 IoU 值甚至更低。弱监督模型的最高性能由 WSLSS 生成,IoU = 0.434,精度 = 0.747,召回率 = 0.585。
讨论
全监督方法和弱监督方法的比较
这里的全监督学习比弱监督学习的结果要好了太多,根本没有可比性。后续在额外的测试集中,WSLSS方法在弱监督模型中实现了最佳精度,但是召回率还是比监督学习要低很多。
结论
本研究探讨了深度学习在病株叶片表型分析中的应用。建立全监督和弱监督CNN模型进行疾病斑点分割。给出了一个同时具有图像级和像素级注释的病叶图像数据集。当处理仅涉及苹果叶的数据集时,完全监督的 DeepLab 模型达到了最高性能 (IoU = 0.829)。WSLSS方法在弱监督模型中实现了最佳精度,IoU为0.434。当这些模型与建模训练过程中未涉及的其他植物物种和疾病(葡萄病和草莓病)一起通过图像进行测试时,完全监督的 DeepLab 模型的性能显着降低,产生了 0.458 的 IoU。观察到 WSLSS 的性能指标略有变化。在这项研究中,在处理以前从未见过的疾病类型时,它甚至达到了0.511的最佳IoU值,这揭示了弱监督学习CNN的鲁棒性和泛化能力。除了这些分割模型外,已发表的带有注释斑点区域的患病图像将帮助研究人员节省大量数据集准备时间,并快速开始探索用于病叶斑分割的新深度学习方法。
个人总结
该论文在植物类的5个公开数据集上,比较了监督学习和弱监督学习的方法实现语义分割方式检测植物病虫害。结果表明了在新的数据集中,本研究提出的WSLSS方法在弱监督模型中实现了最佳精度,但是实际结果我个人认为并不太好。该论文的主要优点在于上传了标注图像可供读者下载查看或进一步利用。
8. VTUAV–Visible-Thermal UAV Tracking: A Large-Scale Benchmark and New Baseline(CVPR, 2022)
摘要
随着多模传感器的普及,可见热(RGB-T)物体跟踪旨在利用温度信息实现稳健的性能和更广泛的应用场景。然而,缺乏配对的训练样本是解锁RGB-T跟踪能力的主要瓶颈。由于收集高质量的RGB-T序列是费力的,最近的基准测试只提供测试序列。在本文中,我们构建了一个大规模的可见热无人机跟踪(VTUAV)基准测试,包括500个序列和170万帧高分辨率(1920 * 1080像素)的帧对。此外,全面考虑了各种类别和场景的综合应用(短期跟踪、长期跟踪和分割掩码预测),进行了详尽的评估。此外,我们提供了粗到细的属性注释,其中提供了帧级属性,以利用挑战特定跟踪器的潜力。此外,我们设计了一种名为分层多模态融合跟踪器(HMFT)的新的RGB-T基准线,它在各个级别上融合了RGB-T数据。在几个数据集上进行了大量实验,揭示了HMFT的有效性和不同融合类型的互补性。
背景
文章指出,传统的跟踪算法主要依赖于可见光模态,在极端环境条件下(例如黑暗或雾中)只能提供有限的信息。另一方面,热成像技术对光照变化不敏感,但在温度相近的背景下可能难以区分目标。因此,采用RGB-T数据进行目标跟踪,通过结合这两种模态,能够提供互补信息,从而拓宽应用场景。为了推动RGB-T跟踪领域的研究进展,已经发布了几个数据集,包括灰度RGB-T数据集和VOT-RGBT跟踪挑战赛。提出了多种算法,同时考虑到性能与时间成本的平衡。然而,训练数据的不足已成为RGB-T跟踪技术发展的一个瓶颈。现有数据集在多样性、视角、帧长度和成像质量方面存在局限。本文介绍了一个名为VTUAV的大型RGB-T跟踪数据集,该数据集以其高度的多样性和分辨率为特点。数据集涵盖了短期和长期跟踪任务,并提供了分割掩模预测,以实现对更广泛应用的全面评估。此外,本论文还提出了一种名为HMFT的新型基线方法,该方法将不同的融合策略整合到一个层次化融合框架中。通过在多个数据集上进行实验,分析了不同融合类型的性能表现。总的来说,本论文通过提供一个具有高度多样性和分辨率的大规模RGB-T跟踪数据集及其相关的属性注释,为训练面向特定挑战的跟踪器做出了贡献。它还通过引入一种基于层次化融合框架的基线方法,并通过广泛的实验验证了各种融合类型的效果,从而推进了RGB-T跟踪技术的发展。
相关的工作
RGB-T跟踪基准
通过时间线的方式描述了相关的研究特点和不足。然后介绍了在本文提出的一个统一的大规模RGB-T跟踪数据集,具有高质量的训练对。与最近的数据集(LasHeR)相比,可以总结出三个主要差异。首先,我们具有更高质量的图像和更宽广的帧长度分布。其次,LasHeR侧重于短期评估,而我们的数据集则从跟踪精度、目标重新检测和像素级估计等三个主流角度来衡量跟踪器的性能。第三,提供了详细的帧级属性注释,可以满足挑战感知跟踪器的要求。
RGB-T跟踪算法
最近的RGB-T跟踪器专注于利用多模态信息的对应性和可区分性。提出了几种融合方法,可以分为图像融合、特征融合和决策融合。然后作者分别介绍了这个几个方面的研究进展和特点。在这项工作中,我们还设计了一种新的基准RGB-T跟踪方法,使用分层融合方式,从所有前面提到的三种融合类型中获益。在三个流行的RGB-T数据集上的众多结果显示,不同层次的信息融合可以为获得更优结果做出全面的贡献。
VTUAV可见光-热成像UAV跟踪大规模数据集
基准特征和统计数据 大规模、多样化的序列
最近的RGB-T数据集使用具有2个自由度可旋转平台的多传感器监控摄像头。图像质量和灵活性无法满足跟踪的要求。此外,静止摄像机无法长时间追踪目标,导致帧长度有限。为了解决这些问题,我们的数据集是由专业的无人机(DJI Matrice 300 RTK)配备Zenmuse H20T相机拍摄的,可以在夜晚、有雾和刮风场景等极端条件下实现稳定飞行。红外热像相机捕捉8-14µm的图像,我们控制飞行高度在5-20米之间,以获得适当的目标尺寸。我们收集了500个序列,包含1664549对RGB-T图像。图像以高质量存储,分辨率为1920*1080,格式为jpg,并以30 fps采样。我们将250个序列作为训练集,另外250个序列作为测试集。根据目标消失的情况,将所有序列分为长期和短期两类。在训练集中,有207个短期序列和43个长期序列。在250个测试序列中,总共有74个属于长期追踪集,用于评估长期追踪的性能。另外的176个测试序列用于短期追踪的评估。我们还为短期子集中选取的100个序列提供了遮罩注释(50个序列用于训练,50个序列用于测试),可用于视频对象分割和尺度估计学习。
通用目标和场景类别
相关数据集主要记录了道路、学校等安全监控场景,场景和目标类别有限。我们旨在构建一个具有充足目标类型和场景多样性的数据集。跟踪目标可以分为5个超类(行人、车辆、动物、火车和船)和13个子类,涵盖了大多数实际应用的类别。这些序列是在两个城市的15个场景中捕获的,包括道路、街道、桥梁、公园、海洋、海滩、球场和学校等。为了强调两种模态的有效性,数据采集持续了一整年,以适应各种天气条件和气候。具体来说,325个序列是在白天拍摄的,175个序列是在夜晚拍摄的,具有不同的条件,如有风、多云和有雾的天气。
分层属性
以往的方法旨在利用属性信息的潜力,在挑战性情况下实现令人满意的性能。然而,现有的视觉和RGB-T数据集 在序列级别上标记属性,将各种挑战粗略地整合到单个序列中。在本文中,除了序列级别的属性之外,我们通过额外为训练序列标记帧级别的属性来实现分层属性注释,以充分探索基于属性的方法。我们保持序列的连续性,而不是将整个序列分割成几个片段 ,这使得帧可以被标记为多个标签或无标签。我们总结了13种属性的挑战,此外还列出了序列级别和帧级别的每个属性的数量。属性的描述在补充材料中总结。
对齐
由于多传感器设备无法保证光学聚合,因此会出现视角差异。以往的RGB-T数据集将帧级别对齐应用于计算单应性变换,并逐帧统一视野范围,导致劳动成本巨大,不适用于实际应用。在我们的数据集中,我们在每个视频的初始帧上进行模态对齐,并将其应用于所有帧。我们注意到大多数帧都对齐良好。不同对齐方法的比较可以在补充材料中找到。
高质量标注
在我们的数据集中,我们以三种格式提供充足的专家标注,包括边界框、分割掩模和属性注释。
- 边界框。在VTUAV中,我们为两种模态分别精心注释了边界框。我们确保每个目标都有准确的边界框标注,以便进行目标检测和跟踪任务。
- 分割掩模。为了支持语义分割任务,我们对每个目标提供了像素级别的分割掩模标注。这些掩模准确地表示了目标的像素级边界和区域。
- 属性注释。除了边界框和分割掩模,我们还提供了属性注释。我们标注了一系列属性,如目标的颜色、形状、大小等。这些属性注释可以用于属性识别和分类任务。
我们通过超过10名经过专业培训的标注员进行标注,并进行了严格的质量控制来确保标注的准确性和一致性。我们在每10帧中提供稀疏的标注。通过引导最先进的跟踪器,可以实现密集的标注。因此,我们总共提供了326,961个高质量的边界框标注。 - 分割掩模。我们以1fps的速度为可见光和热像图像标注目标掩模。使用Labelme工具包生成了总共24,464个掩模。
- 注释。在我们的数据集中,我们提供了帧级别的属性注释,以进行详细的基于属性的分析。大多数属性由全职专家标注。因此,我们共标注了301,678个帧,具有430,960个属性,并提供了500 * 13个序列级别的注释。
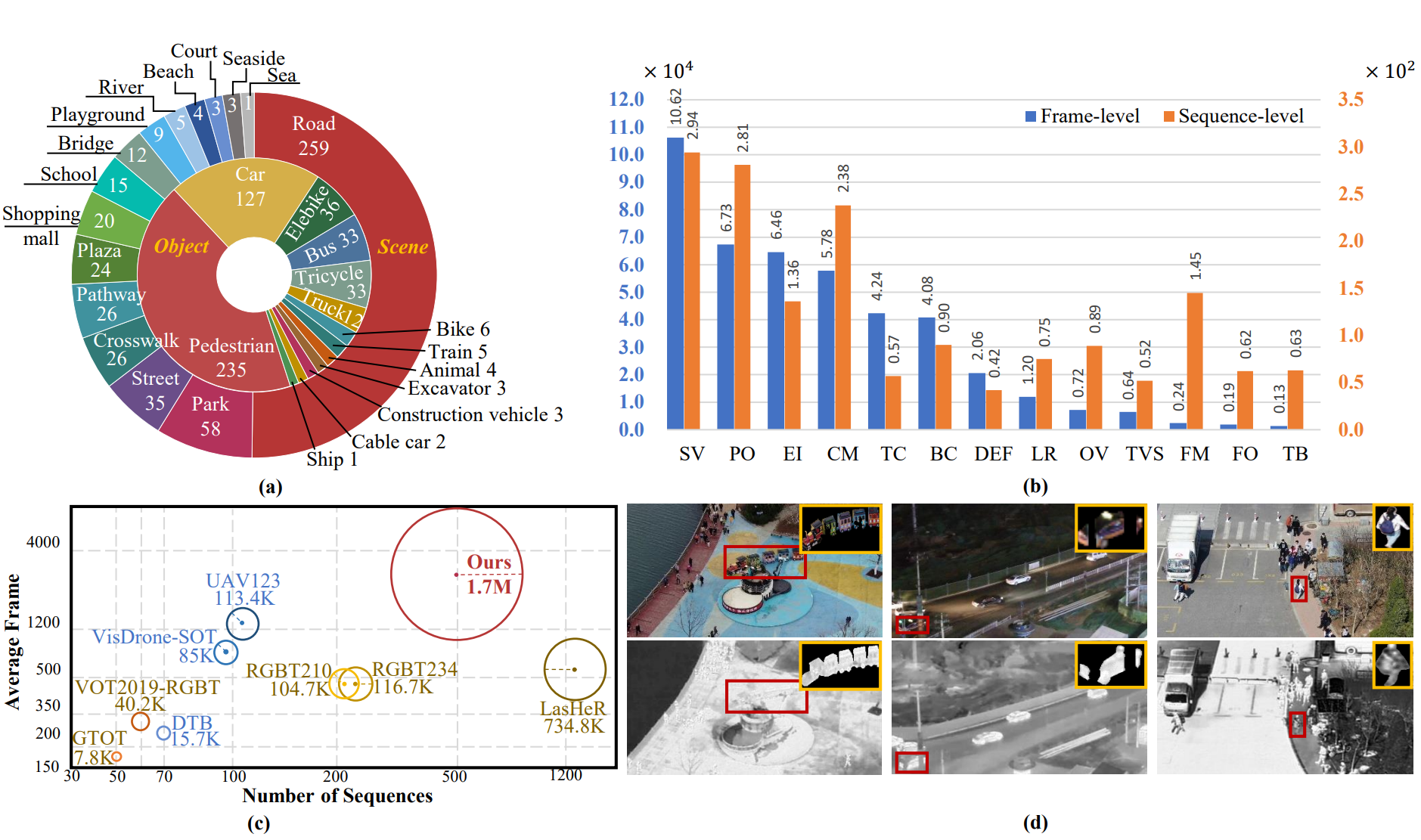
所提出数据集的主要特征和统计信息。(a) 场景分布(外圈)和对象类别分布(内圈)。(b) 帧级和序列级属性的统计信息。© 现有数据集和所提出数据集的比较。每个圆的面积表示总帧数。(d) 使用边界框和分割掩码进行精确注释。
分层多模态融合跟踪器
在本节中,我们将介绍RGB-T跟踪的新基线,以在统一的框架中充分利用各种融合类型。它包括三个主要模块:互补图像融合(CIF)、判别特征融合(DFF)和自适应决策融合(ADF)。CIF旨在学习两种模式之间的共同模式。DFF引入了异构表示的通道组合。最后,ADF是通过考虑判别分类器和互补分类器的响应来提供最终的目标候选者。
RGB-T跟踪的实验分析
短期评价与长期评价
我们选择了四个RGB-T跟踪器,然后比较了他们的性能,。也进行了“消融”实验与质量分析。
VTUAV-V子集的实验结果
为了展示RGB追踪的能力,我们构建了一个子集,即VTUAV-V,其中只包含RGB追踪的可见模态。我们在VTUAV-V数据集上评估了许多流行的短期和长期RGB追踪器。
结论
本文介绍了一个用于RGB-T追踪的大规模基准测试。我们取得了三个主要突破。首先,我们通过提供多样化和高分辨率的RGB-T图像对,解决了训练数据不足的问题。这些图像在各种条件下采集而成。其次,据我们所知,这是第一个统一考虑短期追踪、长期追踪和像素级预测的RGB-T数据集,可以全面评估追踪器。第三,我们在序列和帧级别上标注了13个挑战,以满足场景特定追踪器的需求,并充分发挥属性的有效性。此外,我们设计了一种名为HFMT的新基准方法,结合了图像融合、特征融合和决策融合。在三个基准测试中的出色表现显示了这些融合方法的互补性,以及充足训练数据的重要性。
个人总结
该研究公开了一个追踪的数据集以及设计了一个新的方法。属于在数据和方法上都做出了贡献。写作上分析也很全面。
9. A novel deep learning method for detection and classification of plant diseases(Engineering Applications of Artificial Intelligence,2023)
摘要
农业生产效率对于一个国家的经济进步扮演着至关重要的角色。然而,植物病害堪称影响粮食产量及品质的最大威胁之一。及早识别植物病害对全球健康与福利具有举足轻重的意义。传统上,植物病害的诊断依赖于病理学家通过实地考察对单一植株进行视觉评估。但是,手动检测作物病害由于准确度受限以及人力资源的可获取性有限而面临挑战。为了克服这些问题,迫切需要开发能够有效检测和区分多种植物病害的自动化技术。鉴于图像中背景与前景间存在的低对比度信息、健康与病变植物区域颜色相似性高、样本噪声以及植物叶片在位置、色调、结构和尺寸上可能的变化,精确识别和分类植物病害成为一项极具挑战性的任务。为应对这些难题,我们提出了一种基于DenseNet-77的自定义CenterNet框架的稳健植物病害分类系统。该方法包括三个步骤:首先,开展注释工作以标定感兴趣区域;其次,引入经过改良的CenterNet,并采用DenseNet-77进行深度关键点提取;最后,利用一阶段检测器CenterNet来检测和区分多种植物病害。为了评估性能,我们采用了PlantVillage Kaggle数据库,这是一个关于植物病害的标准数据集,涵盖了强度变化、颜色变化以及叶子形状和大小的多样性等挑战。通过定性和定量分析,我们证实了所提出的方法相较于其他现有技术,能够更有效、更可靠地识别和分类植物病害。
背景
研究人员引入了基于图像处理技术的自动化方法来检测和分类植物叶片病害。然而,现有的方法存在一些问题,如复杂性、计算成本高、模型不准确等。因此,需要开发一种高效、具有成本效益的图像处理系统来准确检测和分类植物病害严重程度。为了解决这些问题,提出了AgriDet框架,它结合了传统的INC-VGGN网络和新的神经网络架构,利用图像预处理和多变量抓切算法来消除图像采集中的问题,并通过基于Kohonen的深度学习来学习叶病的多尺度特征。此外,该框架还使用预训练模型构建了量化疾病严重程度分类策略,以更好地分类疾病的严重程度。通过与其他方法的比较,证明了该框架在性能指标上的优势。总之,AgriDet框架为农业应用提供了一种高效、准确和成本效益的图像处理系统,可以帮助农民及早发现和管理植物病害,提高作物产量。然而,该框架仍有一些局限性,并需要进一步的研究和改进。
文献综述
从现有研究中可以看出,早期技术存在几个限制,包括:(a)捕获图像的不当性质和复杂的背景条件导致遮挡、照明、方向和大小问题;(b)在多个实时应用程序中,成本复杂度、训练损失、过拟合问题和不准确的检测发生;(c)由于样本受环境因素影响而导致分类错误的补丁;(d)由于大量的训练集,执行时间很长;和(e)某些图像存在不规则形状问题。针对这些挑战,需要设计一个改进的预训练模型,可以准确地检测植物病害并高精度分类植物病害的阶段水平。 每种技术的正面和负面方面在表1中显示。
提出的AgriDet框架
在提出的框架中,我们提出了一个农业检测(AgriDet)框架,该框架结合了传统的INC-VGGN和基于Kohonen的深度学习网络,用于检测植物疾病并分类病植物的严重程度。首先,通过图像缩放、增强和对比度调整来执行预处理步骤,以消除图像大小不均和不当的问题。为了解决复杂的多个背景问题,在分割过程中使用多变量Grabcut算法(MGA)来提取叶片区域的病变部分。然后,使用之前学习过的INC-VGGN模型的特征来进行基于Kohonen的深度学习,以学习叶片疾病的多尺度特征。进一步,使用定量疾病严重程度分类(QDSC)策略提取预先学习的特征,并使用传统的预训练INC-VGGN网络将疾病严重程度分类为三类:轻度、中度和重度,基于疾病严重度的百分比(PDS)的严重度测量。因此,该模型在检测效率方面表现良好,并且在PlantDoc和PlantVillage数据集上的实验中,有效性准确度比其他方法提高了。
植物疾病检测和识别被认为是农业领域的关键因素。这种基于图像的检测有助于缓解使用传感器产品保护作物免受疾病的挑战。为此,开发先进的移动应用程序对于协助农民是必不可少的。在这里,农民可以上传作物的可疑图像,并获得有关疾病的必要反馈。AgriDet框架的开发涉及以下程序:
- 首先确定基础网络,并从预训练的CNN模型中获取网络权重。这里使用INC-VGGN作为基础网络。
- 其次,通过插入、更改或删除来自预训练网络的层,建立新的神经网络。
- 最后,调整新形成的网络,以在执行适当的任务时最小化损失的发生。提出的AgriDet框架由两部分组成:第一部分使用预先训练的模型提取特征,第二部分包括用于提取高级特征的扩展层。这些特征映射用于疾病预测。在这里,CNN预先训练执行特定任务的模型被重用来执行第二个模型的任务。通过使用来自预先训练网络的初始化权重,提高效率并减少训练时间。这些权重先前是通过在公共数据集(如ImageNet)上预训练模型获得的。然后,这些权重在现有模型中用于执行疾病检测。
框架中建立了神经网络,其中包含Kohonen的关联多层深度神经网络,为农民提供建议。这允许准确诊断和检测植物疾病。该框架包括数据收集、预处理、分割、深度神经模型训练和实时测试等五个不同过程。提出的AgriDet框架包括五个阶段:数据收集和数据集描述、预处理、分割、用于检测和分类的提出改进的基础网络、定量疾病严重程度分类(QDSC)。这些阶段的描述如下:
数据收集和数据集描述
叶片疾病检测通过收集叶子图像来启动。一旦收集图像,数据将被准备成适合进一步处理的形式,因为原始图像无法处理。这是为了避免在图像采集过程中发生的异常和错误。在这项工作中,考虑了来自两个不同数据集的图像:Plantdoc和Plantvillage数据集,它们分别包括单个背景图像和多个背景图像。这导致遮挡问题,由于照明不良、噪声等可能会出现其他扭曲,因此需要进行预处理以进行检测过程。
在这里,采用了PlantVillage数据集,考虑了超过152种作物,包括38个类别。从同一来源收集了超过56,000张图像。这包括收集当地种植的作物图像,这些作物暴露于适当的疾病集合中。它由从植物中收集的高质量图像组成。图像格式是jpeg,其宽度和高度分别为5472和3648。此外,对其进行预处理以消除噪声,并将数据集中的图像大小进一步缩小到256x256。
PlantDoc数据集包括近29,000张从互联网上下载的图像,使用38种不同植物的通用和科学名称。还进行了过滤以删除不适当的图像,例如非叶植物、超出范围的图像、重复的图像和实验室控制的图像。此外,每个图像都经过了适当的检查,并删除了标签错误。最终,在消除后,PlantDoc数据集包括27个类别,13种物种和2,598张图像。
预处理
在预处理阶段,进行了三种不同的处理,包括图像缩放、增强和对比度调整。由于图像大小不均匀和不合适,无法直接用于图像处理任务。对于植物疾病检测,收集的图像来自不同的背景。因此,在处理之前需要将图像调整为固定的高度和宽度。在这里,缩放是为了调整图像的大小,放大的过程称为“上采样”。图像调整大小时不会损失图像质量。然后,调整大小后的图像包括更多或更少的像素。接下来,对于暗色背景的图像,增强颜色和对比度以便于处理。图像分割可以更容易地在L×a×b格式中执行,而不是RGB格式。因此,RGB图像被转换为L×a×b格式。
分割
在对叶片图像进行预处理之后,需要进行图像分割。这对于包含多种背景的PlantDoc数据集来说尤为适用。常用的分割算法是GrabCut,它利用图割来提取关键的植物病叶区域。该算法通过在需要进行分割的特定物体周围绘制用户特定的边界框(比如病叶部分),来实现分割。从高斯混合模型中估计出估计区域和其背景的颜色分布。这有助于开发马尔可夫随机场,该随机场覆盖了所估计的像素区域,该区域包括连接所选像素区域的能量函数,然后基于图割算法进行优化以推断值。该过程将重复进行,直到获得收敛,并随后将进行进一步的估计以预测错误分类的区域。
PlantDoc数据集包含从真实栽培田采集的图像,因此所获得的图像包含多种背景。因此,必须丢弃背景,仅选择叶片区域以进行病害检测。在这里,我们使用多变量Grabcut算法(MGA)来提取叶片区域的病变部分。MGA的工作过程列举如下:
- 第1步:获取病叶的预处理图像。
- 第2步:应用图像分割算法,获取特定的病叶区域并丢弃背景。进一步,对分割图像应用色调饱和度值(HSV)。
- 第3步:将叶片图像的选定焦点视为前景,其周围视为背景。图像的未知部分被视为背景或前景。
- 第4步:在病叶目标区域周围随机选择一个区域,目标区域内的像素被视为未知,外部的像素被视为已知。
- 第5步:将前景和背景建模为高斯混合模型(GMM)。
- 第6步:分配最重要的高斯分量给图像中的前景和背景像素。
- 第7步:基于学习过程创建新的GMM,以开发像素集。
- 第8步:构建图形并应用GrabCut算法,然后定义新的前景类别。
- 第9步:重复步骤4-6,直到病害区域完全分类。
- 第10步:为背景和前景区域分别构建颜色、大小、纹理和形状等多元特征的l个组件。
- 第11步:从每个聚类的颜色统计中获取GMM的值。具有同质性的颜色聚类具有较低的方差,并提供有效的分割。
- 第12步:最后,通过使用多元特征(如颜色、形状和纹理)对这些区域进行建模,进行图像分割。最终,生成与叶片区域相对应的像素集。
提出的改进基础网络用于检测和分类
在分割之后,对PlantDoc和PlantVillage数据集中的图像进行训练过程。初始基础网络用于学习植物病害的特征。在这里,预训练模型INC-VGGN参与特征提取。它作为一个基本的特征提取器,消除了训练的需求。在这个模型中,前几层负责提取颜色特征。在这里,使用inception来提取特征。然后,在多尺度的特征提取阶段,使用卷积和池化层来提取丰富的特征。为了加快网络速度,在第三个池化层后采用swish激活函数。接着,在INC-VGGN中放置全局池化层和softmax分类器。使用这个基础网络,可以更准确地学习植物病害的特征。然后,将病例样本通过基础INC-VGGN进行学习。这可以扩展到新开发的神经网络,该网络用于执行病害检测任务。新开发的神经网络包括以下层:输入层、卷积层、Kohonen学习层、池化层、softmax层、dropout层、全连接层和输出层。在这个神经网络中,通过更深入地学习病害检测过程,以提取每一种病害类别的关键特征。为了避免误分类问题,更准确地学习纹理、形状、大小、颜色和其他特征。这是使用Kohonen关联多层深度神经网络来实现的。在这个网络中,Kohonen学习被纳入到深度神经网络的层中。不同层的功能如下所示:神经网络的每一层都执行独特的功能。
实验结果和讨论
提出的系统使用改进的两个不同的基准数据集进行训练,分别是Plant Village和PlantDoc数据集。
使用的评估指标、可视化结果、对比评估
用于评估提出模型的三个不同指标是准确率、灵敏度和特异度。在这里,正确检测被视为真正阳性(TP),未检测到的被视为假阴性(FN)。除此之外,还考虑了假阳性和真阴性。然后展示了提出的方法在Plantdoc和Plantvillage数据集上分析各种实验结果的可视化评估结果。为了进行定性评估,将提出方法的评估结果与现有方法进行了比较,
讨论
AgriDet框架的主要目的是帮助农民在田间得到植物病害发生的清晰结果。在实时测试过程中,任何受植物病害影响的农民会拍摄作物的图像。这个图像作为输入发送到AgriDet框架中进行病害检测。首先,图像经过预处理和分割。然后,将预训练模型中学习到的特征用于新开发的神经网络中。在这里,通过深度学习学习叶片上发生的病害的多尺度信息。使用网络中对任何类型的病害的预先学习特征,可以更准确地预测病害的类型,并将输出显示给农民。由于该框架涉及在训练和特征提取过程中使用基础预训练模型和新开发的神经网络,因此预测更准确。因此,避免了错误分类,农民可以对特定病害采取预防措施以获得丰收。因此,该模型适用于实时应用,特别是在农业领域。然而,在训练集中,由于高标签错误引起的意外情况的影响,预测值模型的差异因此有所变化。因此,在访问分类模型时无法保证正确的预测值。因此,由于高标签错误导致无法在病害严重程度分类模型中提供100%的准确性。(这个讨论写的一般,其实删掉对文章内容一点也不影响。)
结论
本文介绍了一个AgriDet框架,将传统的INC-VGGN和基于Kohonen的深度学习网络结合起来,用于检测植物病害并对患病植物的严重程度进行分类。首先,使用图像缩放、增强和对比度调整等预处理步骤来消除来自PlantDoc和PlantVillage数据集的样本图像的不平衡和不恰当的大小。为解决复杂的多个背景问题,使用分割过程利用MGA算法提取叶片区域的患病部分。然后,通过使用INC-VGGN模型先前学习到的特征,进行基于Kohonen的深度学习,以学习叶片病害的多尺度特征。此外,通过在网络中使用dropout层,避免了过拟合。最后,使用传统的预训练INC-VGGN模型,QDSC策略提取预先学习的特征并对病害严重程度进行分类。因此,AgriDet框架表明,PLD严重程度测量的统计结果在从收集的数据集中获得的不同病害方面达到更高的准确性。
个人总结
本文的表述略显冗长,尤其是在摘要部分的背景介绍上。文章的亮点在于提出了一种新方法,整体而言,质量尚可,但实际应用效果仅为一般水平。





![[ai笔记2] 团年饭ai制图大比拼](https://img-blog.csdnimg.cn/img_convert/9037b02598e17c8346b608afa93f3ae5.png)


![【蓝桥杯冲冲冲】k 短路 / [SDOI2010] 魔法猪学院](https://img-blog.csdnimg.cn/direct/7003ab3546a94f21876f60180a88e6ed.jpeg#pic_center)