文章目录
- 前言
- 笔记正文
- 大模型成为热门关键词
- 书生·浦语开源历程
- 从模型到应用
- 书生·浦语全链条开源开放体系
- 数据
- 预训练
- 微调
- 评测
- 部署
- 部署
- 智能体
- Lagent
- AgentLego
- 总结
前言
本系列文章是参与书生浦语全链路开源体系学习的笔记文章。B站视频教程地址:
笔记正文
大模型成为热门关键词
LLM受到高关注,因为大模型成为发展通用人工只能的重要途经。
- 专用模型:针对特定任务,一个模型解决一个问题。
- 通用大模型:一个模型应对多种任务、多种模态。
书生·浦语开源历程
6月7日发布开始,开源第一代InternLM,并接着开源了其他相关模型或数据,如书生万卷开源的多模态数据集。
书生浦语大模型系列开源包含了轻量级7B,中量级20B,重量级123B,对比当时的其他开源模型由优势。
从模型到应用
从LLM到应用是有Gap的。
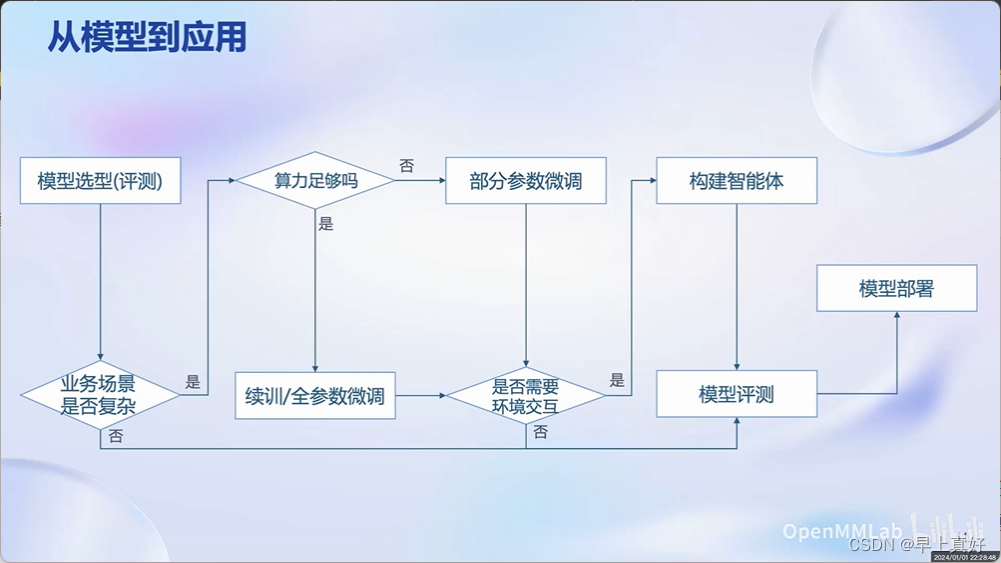
书生·浦语全链条开源开放体系
全链条:包含很完整的大模型应用开发的环节
- 数据:书生万卷,2TB数据,涵盖多种模态与任务
- 预训练:InternLM-Train,并行训练,极致优化,速度达到3600tokens/sec/gpu
- 微调:XTuner,支持全参数微调,支持LoRA等低成本微调
- 部署:LMDeploy,全链路部署,性能领先,每秒生成2000+tokens
- 评测:OpenCompass,全方位评测,性能课复现80套评测集,40万道题目
- 应用:Lagent、AgentLego,支持多种智能体,支持代码解释器等多种工具
数据
包含了文本数据、图像-文本数据集、视频数据,1.0版本发布初总2TB。
OpenDataLab上也有大量数据。
预训练
高可扩展、性能优化、兼容主流、多种配置
微调
LLM的下游应用中,增量续训和有监督微调是经常会用到的两种方式。
- 增量续训:
- 使用场景:让基座模型学习到一些新知识,如某个垂类领域知识
- 训练数据:文章、书籍、代码等
- 有监督微调:
- 使用场景:让模型学会理解和遵循各种指令,或者注入少量领域知识
- 训练数据:高质量的对话、问答数据
微调分为全量参数微调和部分参数微调。
XTuner
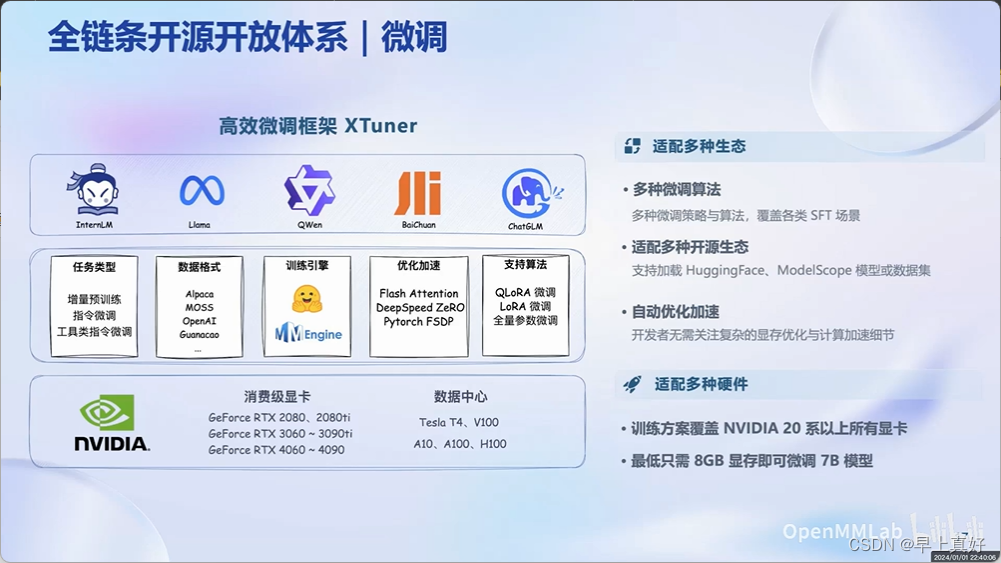
为什么不支持10系的显卡,应该是显卡架构导致的,也没发现有哪个推理框架专门支持了10系的显卡。比如Flash Attention加速,直接不支持Pascal架构,也许是因为这样类似的原因(如vLLM等其他大模型部署框架都依赖于Flash Atten)。
显存优化,能够在8G显卡上进行7B模型的微调。
评测

OpenCompass提供了丰富的模型支持、分布式高效评测、便捷的数据接口、敏捷的能力迭代。Meta也将其作为推荐的评测工具之一。
部署
LLM特点:
- 内存开销巨大:庞大的参数量;采用自回归生成token,需要缓存k/v
- 动态Shape:请求书不固定;token逐个生成,且数量不定
- 模型结构相对简单:Transformer结构,大部分是decoder-only(从算子上来说比部署视觉模型之类的容易)
技术挑战:
设备、推理、服务
部署方案:模型并行、低比特量化、Attention优化、计算和访存优化、Continuous Batching。
部署
LMDeploy提供包括模型轻量化、推理、服务的全流程的GPU上部署方案。
智能体
主要在于工具使用和交互。
Lagent

Lagent的智能体框架目前的功能还是不太能够满足需求,毕竟其定位是“轻量级”智能体框架,但是可以相信之后这个框架将会有更加完善丰富的功能。
AgentLego
提供了很多工具,可以比较方便地集成到智能体系统中,输入输出接口也比较灵活。
但是站在国内的情况来说,大概不能完全算是开箱即用的,毕竟依然是从Huggingface上拉取模型,虽然可以通过代理服务器等方式解决,但是依然造成了一些阻碍;这些阻碍相对于AgentLego工具箱提供的便利来说则不算什么。

总结
书生·浦语全链路开源体系是一个全面、多元化的项目,涵盖了从数据、预训练到微调、部署等多个环节。这个体系包括不同规模的模型,如轻量级的InternLM-7B、中量级的InternLM-20B和重量级的Intern-123B,这些模型在多种任务和模态上表现出色。书生·浦语项目不仅关注模型本身的发展,还重视模型的应用和部署,如LMDeploy和Lagent等工具,这些工具旨在提高模型的推理效率、服务便捷性和应用灵活性。该项目还提供了XTuner等微调框架,支持全参数微调和低成本微调,以及OpenCompass评测平台,用于模型的全面评估。书生·浦语全链路开源体系是一个综合性的项目,旨在推动大模型的研发和应用,同时也关注模型的性能优化和实际部署。