文章目录
- 掌握Pandas:数据筛选方法与高级应用全解析
- 1. between方法
- 2. isin方法
- 3. loc方法
- 4. iloc方法
- 5. 查询复杂条件的结合应用
- 6. 避免inplace参数
- 7. 利用Lambda函数进行自定义筛选
- 8. 处理缺失值
- 9. 多条件排序
- 10. 数据统计与分组
- 总结:
掌握Pandas:数据筛选方法与高级应用全解析
在数据分析和处理中,Pandas是一款强大的Python库,提供了丰富的功能来操作和处理数据。本文将深入介绍Pandas中几种常用的数据筛选方法:between、isin、loc和iloc,并通过代码实例和解析展示它们的用法和优势。

1. between方法
between方法用于筛选数据框中某列的数值在指定范围内的行。下面是一个简单的例子:
import pandas as pd
# 创建示例数据框
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 22, 35],
'Salary': [50000, 60000, 45000, 70000]}
df = pd.DataFrame(data)
# 使用between筛选年龄在25到30之间的行
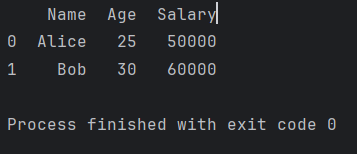
filtered_df = df[df['Age'].between(25, 30)]
print(filtered_df)
这段代码将输出包含年龄在25到30之间的行的数据框。
2. isin方法
isin方法用于筛选数据框中某列的数值是否在给定的列表中。以下是一个例子:
# 创建示例数据框
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Department': ['HR', 'IT', 'Finance', 'Marketing']}
df = pd.DataFrame(data)
# 使用isin筛选属于IT或Marketing部门的行
filtered_df = df[df['Department'].isin(['IT', 'Marketing'])]
print(filtered_df)
这段代码将输出包含属于IT或Marketing部门的行的数据框。

3. loc方法
loc方法基于标签来进行行列选择。以下是一个示例:
# 使用loc筛选年龄在25到30之间的行,并选择Name列和Age列
filtered_df = df.loc[df['Age'].between(25, 30), ['Name', 'Age']]
print(filtered_df)
这段代码将输出包含年龄在25到30之间的行,并选择Name列和Age列的数据框。
4. iloc方法
iloc方法基于整数位置来进行行列选择。以下是一个示例:
# 使用iloc筛选第2到第3行,并选择第1到第2列
filtered_df = df.iloc[1:3, 0:2]
print(filtered_df)
这段代码将输出包含第2到第3行,第1到第2列的数据框。
通过学习这些Pandas常用的数据筛选方法,你将能更灵活地处理和分析数据,提高数据处理的效率。希望这篇文章能够帮助你更好地利用Pandas进行数据分析工作。

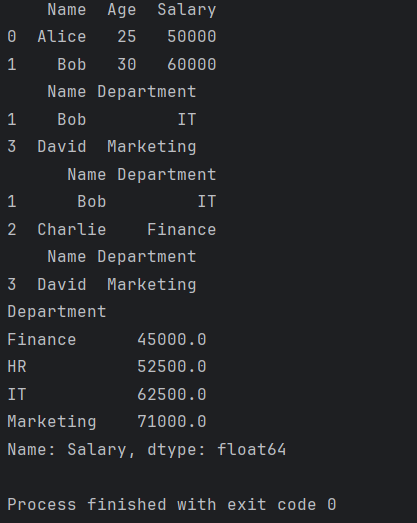
5. 查询复杂条件的结合应用
除了单独使用这些方法外,我们还可以将它们组合起来,以满足更复杂的条件筛选需求。以下是一个综合运用的例子:
# 创建示例数据框
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 22, 35],
'Salary': [50000, 60000, 45000, 70000],
'Department': ['HR', 'IT', 'Finance', 'Marketing']}
df = pd.DataFrame(data)
# 使用复杂条件筛选:年龄在25到30之间且属于IT或Marketing部门的行,并选择Name和Salary列
filtered_df = df.loc[(df['Age'].between(25, 30)) & (df['Department'].isin(['IT', 'Marketing'])), ['Name', 'Salary']]
print(filtered_df)
这段代码将输出包含年龄在25到30之间且属于IT或Marketing部门的行,并选择Name和Salary列的数据框。
6. 避免inplace参数
在Pandas中,这些方法通常返回新的数据框,而不是修改原始数据框。因此,我们应该避免使用inplace参数,而是将结果赋值给新的变量。这样可以更好地维护数据的可追溯性。
# 不推荐使用inplace参数
df.drop('Department', axis=1, inplace=True)
# 推荐的方式:将结果赋值给新的变量
new_df = df.drop('Department', axis=1)
通过遵循这个规则,我们能够更好地追踪数据处理的步骤,减少潜在的错误。
7. 利用Lambda函数进行自定义筛选
除了上述方法外,还可以使用apply方法结合Lambda函数进行自定义筛选。这种方法在处理需要根据列的某些特定条件进行筛选的情况下非常有用。
# 创建示例数据框
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 22, 35],
'Salary': [50000, 60000, 45000, 70000],
'Department': ['HR', 'IT', 'Finance', 'Marketing']}
df = pd.DataFrame(data)
# 使用Lambda函数筛选年龄大于30的行,并选择Name和Department列
filtered_df = df[df.apply(lambda row: row['Age'] > 30, axis=1)][['Name', 'Department']]
print(filtered_df)
这段代码将输出包含年龄大于30的行,并选择Name和Department列的数据框。

8. 处理缺失值
在数据处理中,处理缺失值也是一个常见的任务。使用dropna方法可以轻松删除包含缺失值的行或列。
# 创建含有缺失值的示例数据框
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, None, 22, 35],
'Salary': [50000, 60000, 45000, None],
'Department': ['HR', 'IT', 'Finance', 'Marketing']}
df = pd.DataFrame(data)
# 删除包含缺失值的行
cleaned_df = df.dropna()
print(cleaned_df)
上述代码将删除包含缺失值的行,得到一个不含缺失值的新数据框。
9. 多条件排序
Pandas提供了sort_values方法,可以根据一列或多列的值进行排序。这在数据分析中常常用于观察数据的趋势或找出关键信息。
# 创建示例数据框
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 22, 35],
'Salary': [50000, 60000, 45000, 70000],
'Department': ['HR', 'IT', 'Finance', 'Marketing']}
df = pd.DataFrame(data)
# 按照年龄升序、工资降序的顺序进行排序
sorted_df = df.sort_values(by=['Age', 'Salary'], ascending=[True, False])
print(sorted_df)
这段代码将输出一个根据年龄升序、工资降序排序的数据框。
10. 数据统计与分组
Pandas中的groupby方法允许我们根据某一列的值将数据框分组,然后对每个组进行统计或其他操作。
# 创建示例数据框
data = {'Department': ['HR', 'IT', 'Finance', 'Marketing', 'HR', 'IT', 'Marketing'],
'Salary': [50000, 60000, 45000, 70000, 55000, 65000, 72000]}
df = pd.DataFrame(data)
# 按照部门分组,并计算每个部门的平均工资
grouped_df = df.groupby('Department')['Salary'].mean()
print(grouped_df)
这段代码将输出每个部门的平均工资。
通过这些高级的Pandas操作,我们能够更加深入地挖掘数据的信息,进行更复杂的分析和处理。这些技巧对于数据科学家和分析师来说都是非常有用的工具。
总结:
本文深入介绍了Pandas中几种常用的数据筛选和处理方法,包括between、isin、loc、iloc、Lambda函数、多条件排序、数据统计与分组等。通过代码实例和解析,读者能够更全面地了解这些方法的用法和优势。
首先,我们学习了between方法,用于筛选指定范围内的数据。然后,介绍了isin方法,可以根据给定的列表筛选数据。接着,深入讲解了loc和iloc方法,分别基于标签和整数位置进行行列选择。通过这些方法,我们可以在数据框中轻松定位和提取感兴趣的数据。
进一步,我们了解了如何结合Lambda函数进行自定义筛选,处理复杂的条件需求。同时,强调了避免使用inplace参数的最佳实践,以维护数据处理的可追溯性。
在处理缺失值方面,我们使用dropna方法清理数据,确保得到不含缺失值的数据框。此外,学习了多条件排序和数据统计与分组的高级应用,使数据分析更加灵活和有深度。
通过这篇文章,读者将掌握使用Pandas进行数据处理和分析的关键技巧,能够更有效地应对各种数据处理任务,提高工作效率。希望这些知识能够帮助读者更自信地探索和分析数据,为数据科学和分析领域的工作提供实用的工具和方法。







![[每周一更]-(第86期):PostgreSQL入门学习和对比MySQL](https://img-blog.csdnimg.cn/direct/7661cf42fd9a48d59e2bbc14e1d257f5.jpeg#pic_center)