写在前面
本文看下es的倒排索引相关内容。
1:正排索引和倒排索引
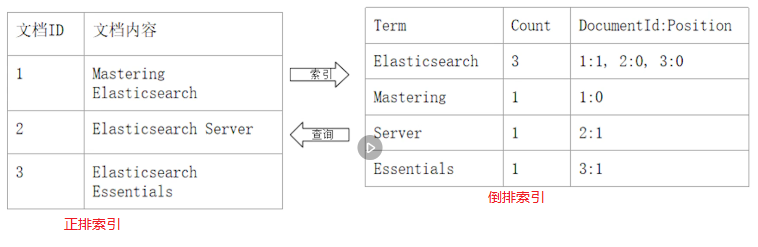
正排索引就是通过文档id找文档内容,而倒排索引就是通过文档内容找文档id,如下图:
2:倒排索引原理
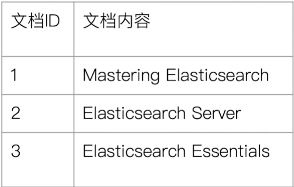
假定我们有如下的数据:
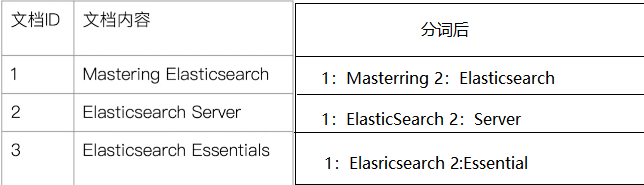
为了建立倒排索引,我们需要先对文档进行分词,如下:
分词后每一个词有一个专门的名词来表示,叫做Term,term就是我们要搜索的目标,但是找到了term并不能找到文档,为了找到文档,每一个term对应一个[<文档id,偏移量,出现次数>]的数组,这个数组我们叫做Posting List,其中每个term对应一个Posing List,如下图:

为了方便查找term,term+Posing List组合在字典的数据结构,叫做Term Dictionary,(注意term是排好序的,所以可以顺序查找,后面会用到!!!),如下图:
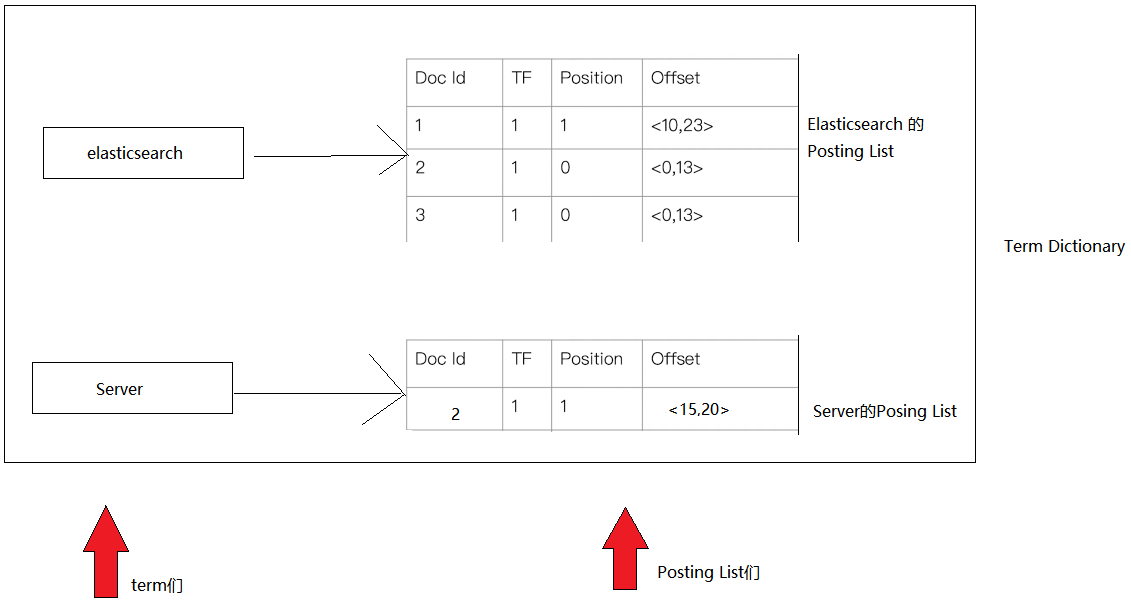
这样,当我们搜索Elasticsearch,可以通过Term Disctionary,查到对应的term,然后通过term就可以找到对应的PosingList,就找到文档了,这个过程如下:
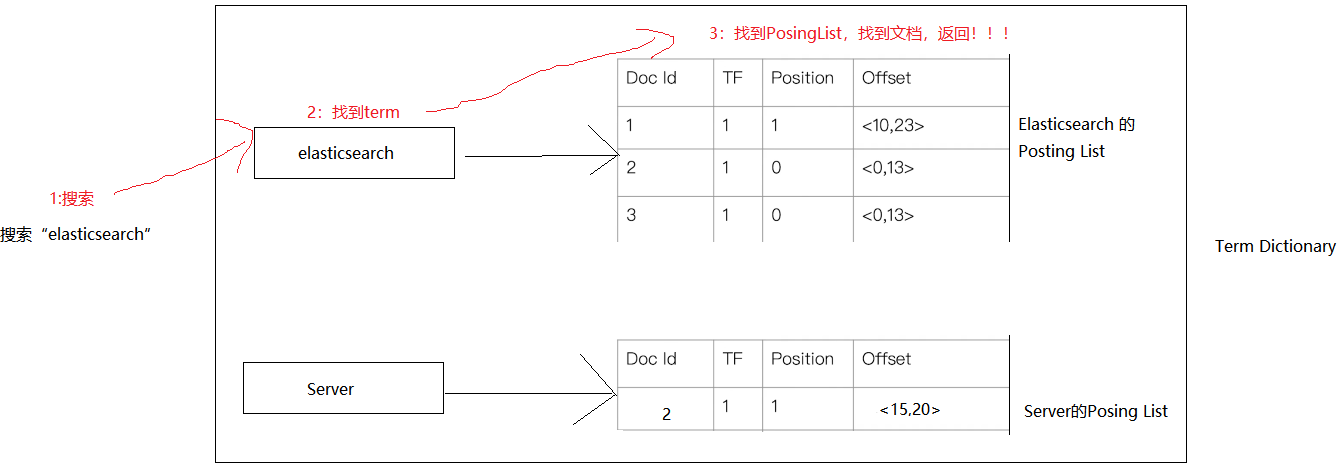
但,实际上我们搜索的关键词,是没有办法直接按照上述流程找到term的,因为term dictionary比较大,是保存在磁盘上的,直接基于磁盘查找,速度就可想而知了,所以,es还设计了另外一种数据结果term index,用来在内存中保存关键词对应的term磁盘页位置,term index是一种基于trie tree的数据结构,大概如下图:
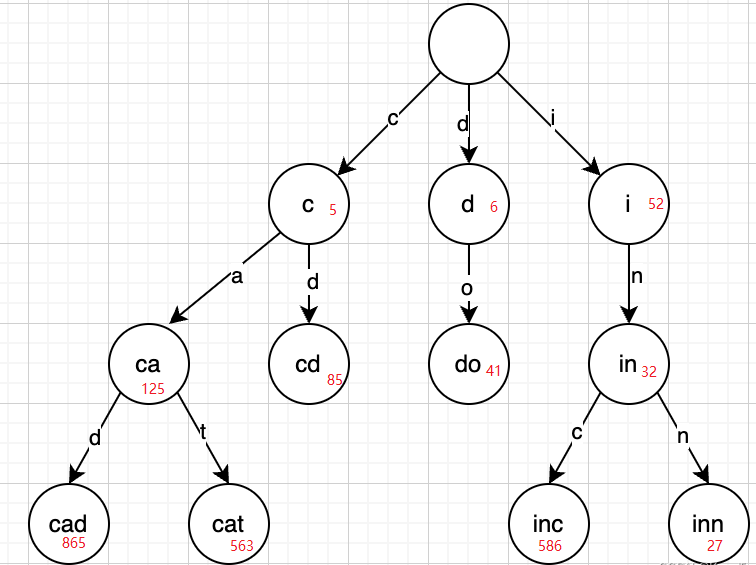
其中红色的就是位置信息,但是注意在term index中只会存储前缀,所以可以定位到一个大概的位置,而因为term是顺序存储的,所以可以顺序读盘,找到目标term,这里我们简单的以直接定位到term为例看下这个过程:
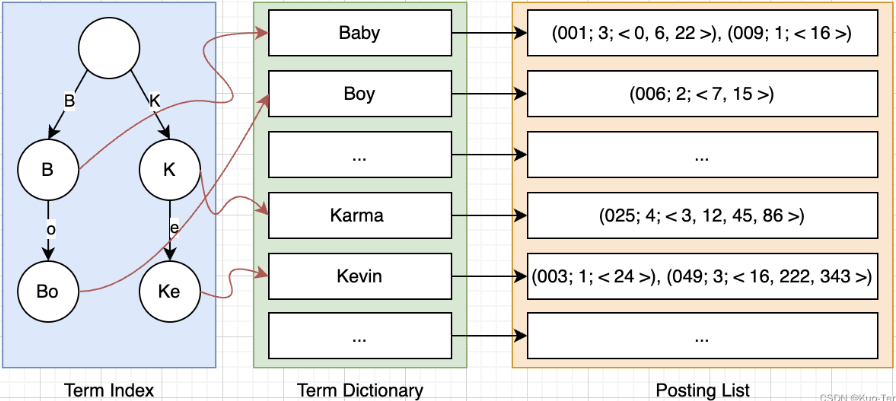
最后,es为了能够将term index存储在内存中,还是用了FST的算法,来压缩空间。则最终查找过程就如下图了:

以上过程分词是及其重要的一个环节,所以我们接下来也来看下分词相关的内容。
3:分词
3.1:什么是分词和分词器
分词:analysis,即将一句话分为多个词(term)的过程。
分词器:analyzer,完成分词这个操作的工具。
如下图:
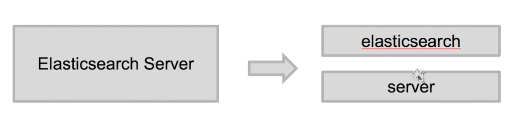
所以,分词是个动词,分词器是个名词。
分词器在我们写入数据构建倒排索引的时候会用到,在输入一句话进行搜索的时候也会用到。
3.2:分词器的工作原理
一个标准的分词器由以下三部分组成:
Charancter Filters:对原始的内容进行处理,如删除html字符,等
Tokenizer:按照某种规则切分为一组单词(term),这部分功能不仅每种分词器都有,而且还可能包含Token Filters的功能(可以看作是分词器的非标准实现)
Token Filters:对切分后的次进行处理,如转小写,删除停用词等
如下简单例子:
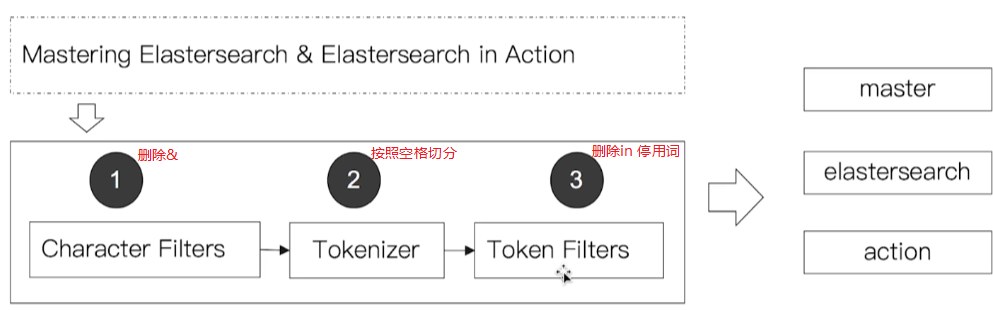
注意这只是一个标准的分词器需要具备的三个部分,但除了Tokennizer必须提供具体的实现外,Chracter Filters和Token Filters并不是必须提供实现的。
3.3:分词器都有哪些

为了方便你我们查看不同的分词效果,es提供了_analysis 的rest api,如下:

3.3.1:Standard Analyzer
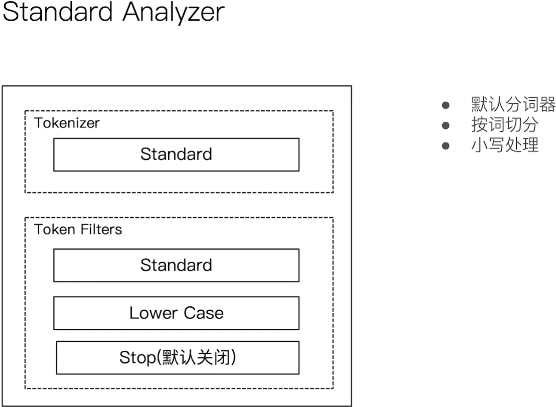
默认分词器,标准分词器三部分提供如下:
charanter Filters:无
Tokennizer:按词切分,就是按照空格切分吧
Token Filters:小写处理
如下图:
首先,我们来看下standard analyzer的执行效果:
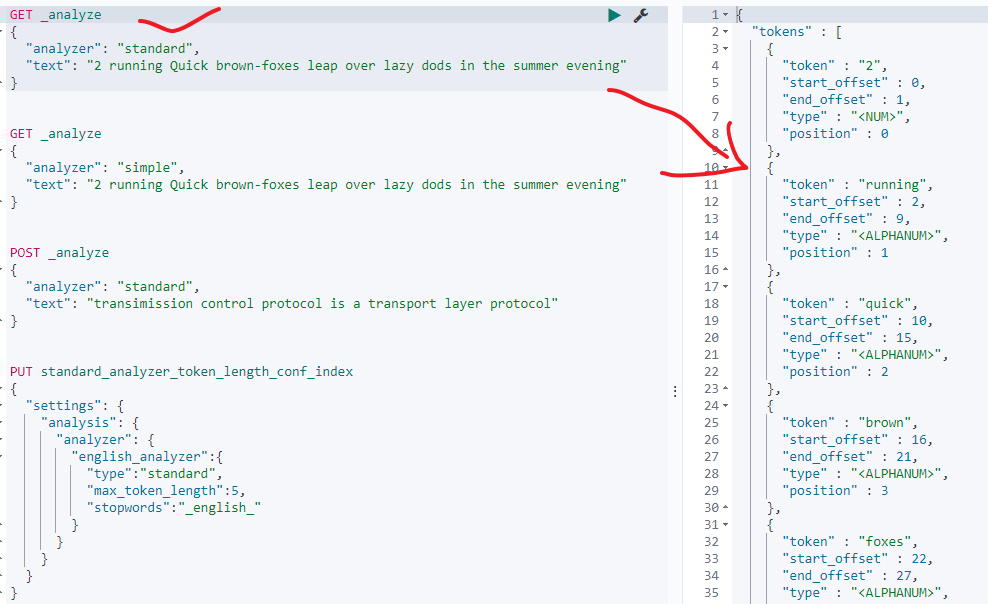
可以看到只是空格划分后转小写了。
如果我们想要启动token fitlers中的停用词该怎么办呢?可以这样,我们来自定义一个分词器,并指定配置,因为在es中自定义分词需要定义在索引下,所以我们需要指定索引来创建(其实就是设置索引的setting),如下:
PUT standard_analyzer_token_length_conf1_index
{
"settings": {
"analysis": {
"analyzer": {
"english_1analyzer":{
"type":"standard",
"max_token_length":5,
"stopwords":"_english_"
}
}
}
}
}
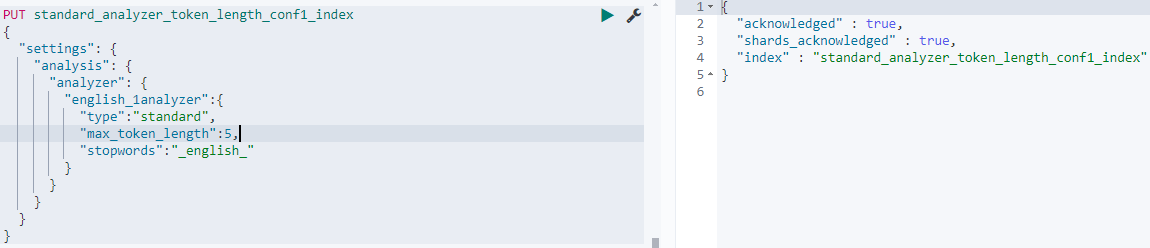
在索引standard_analyzer_token_length_conf1_index中我们定义了一个名称为english_1analyzer的自定义索引,其中的配置项如下:
"type":"standard",
基于standard分词器
"max_token_length":5,
token最大长度为5,即如果term长度大于5则回分为2个,如ABCDEFGHI,会分为ABCDE和FGHI
"stopwords":"_english_"
使用标准的eglish停用词语,也可以通过stopwords_path来指定停用词
测试如下:

可以看到is a这些就没了,并且每个term的最大长度是5,超过5的也被分成了多个。
3.3.2:Simple Analyzer
简单分词器,标准分词器三部分提供如下:
Charanter filters:不提供实现
Tokennizer:按照非字母进行切分(可对比standard分词器只按照空格进行切分),然后还抢了本该属于Token Filters的活,会转小写
Token filters:不提供实现
测试如下:

3.3.3:White space Analyzer
空格分词器,标准分词器三部分提供如下:
Character Filters:不提供实现
Tokenizer:按照空格切分(简单粗暴)
Token Filters:不提供实现
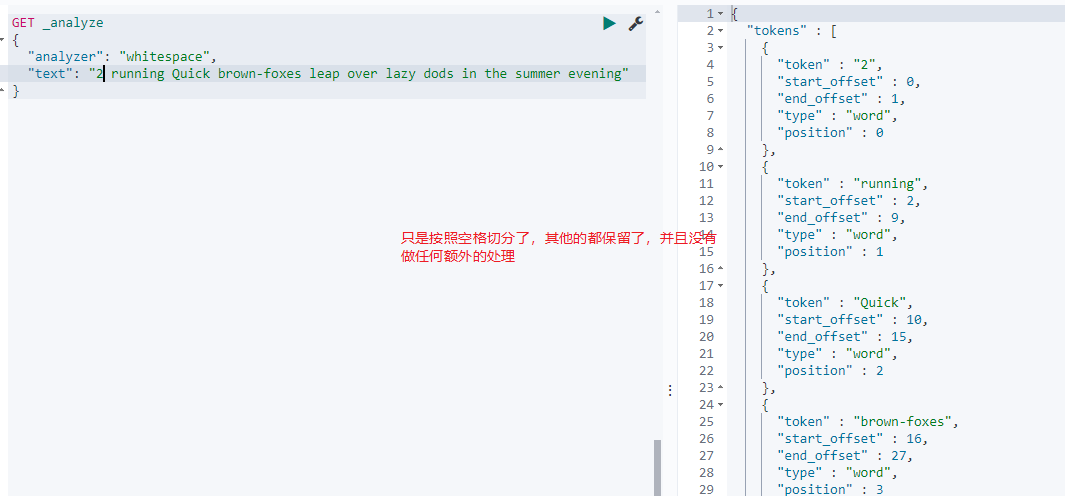
测试如下:
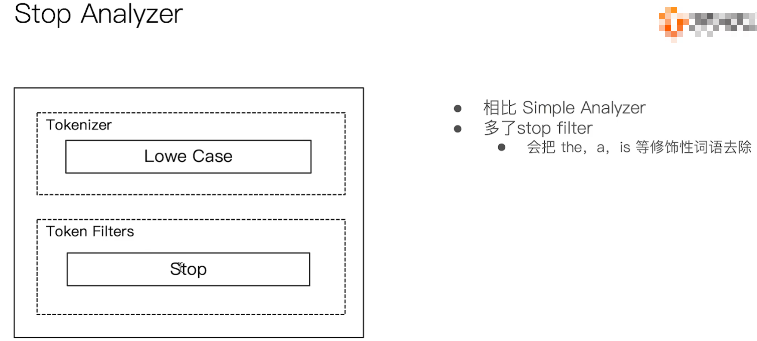
3.3.4:stop anylizer
停用词分词器,标准分词器三部分提供如下:
Character Filters:不提供实现
Tokenizer:按照空格切分
Token Filters:删除is,a等修饰词
可以看到相比于simple analyzer,只是多了tokenfilters的删除修饰词功能。
测试如下:

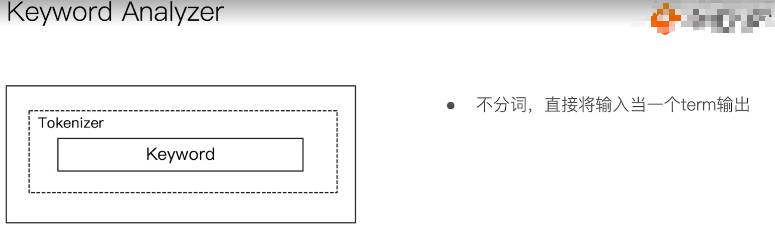
3.3.5:keyword anylizer
关键词分词器,标准分词器三部分提供如下:
Charater Fitlers:不提供实现
Tokennizer:原样输出,也是一种特殊的分割,不是嘛!!!
Token Filters:不提供实现
测试如下:

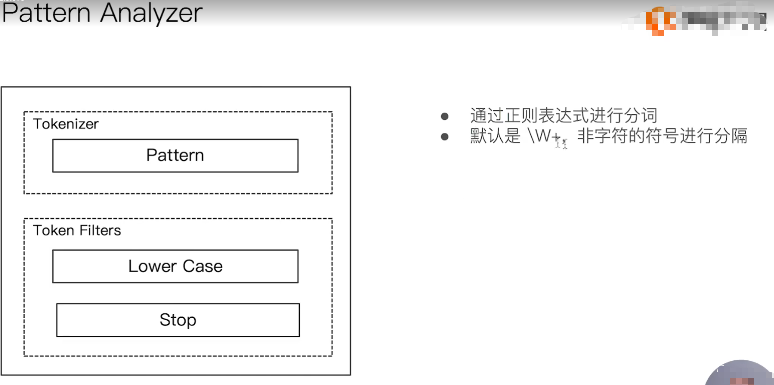
3.3.6:Pattern anylizer
模式分词器,标准分词器三部分提供如下:
Character Fiters:不提供实现
Tokennizer:默认按照\W+进行分割,即按照[0-9a-zA-Z_]之外的字符进行分割
Token Fiters:转小写,以及停用词
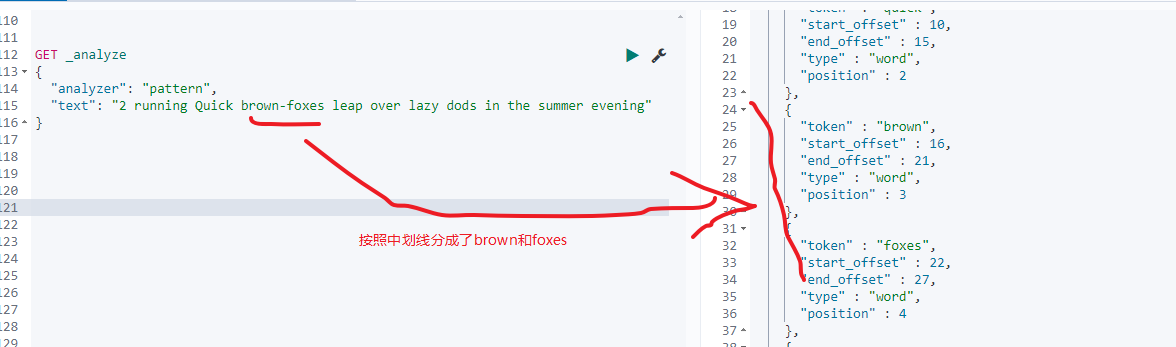
测试如下:
3.3.7:language anylizer
这并不是一个分词器,而是一组分词器,一组针对特定语言的分词器,支持语言如下:

以english为例看下,其token filters还会将一些特定语态的单词变为正常的,如xxxIng变为xxx,如:
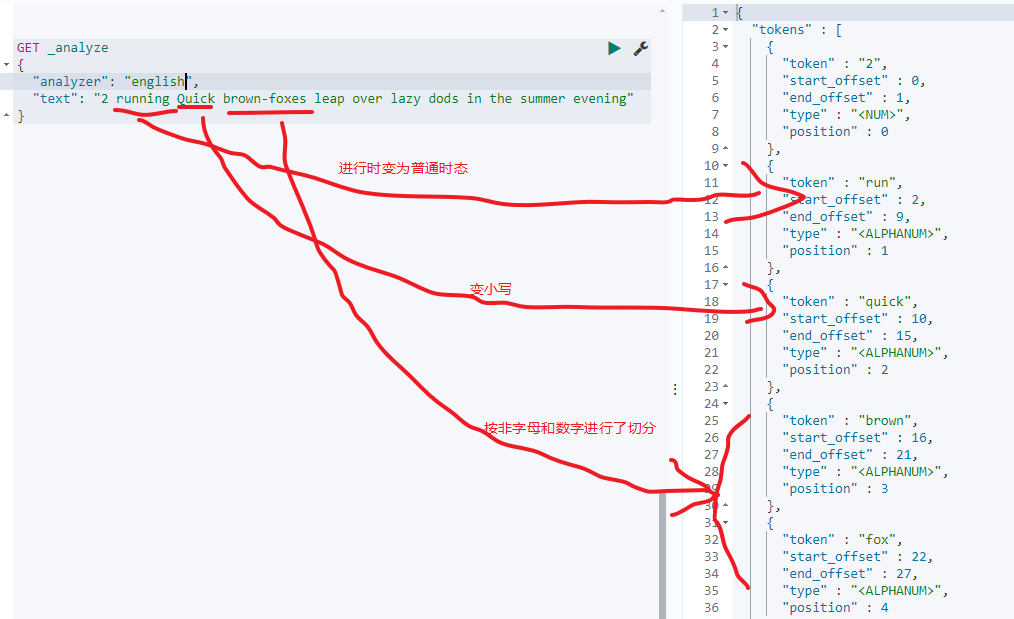
3.3.8:中文分词
因为中华文字,博大精深,变化多端,所以分词的难度相当之大,具体点如下:

为了测试中文分词我们可以来自定义一个安装了ik插件的新镜像,参考docker自定义镜像并使用 。只需要将docker-compose中的es imga改成我们自己定义的就可以测试了,如:
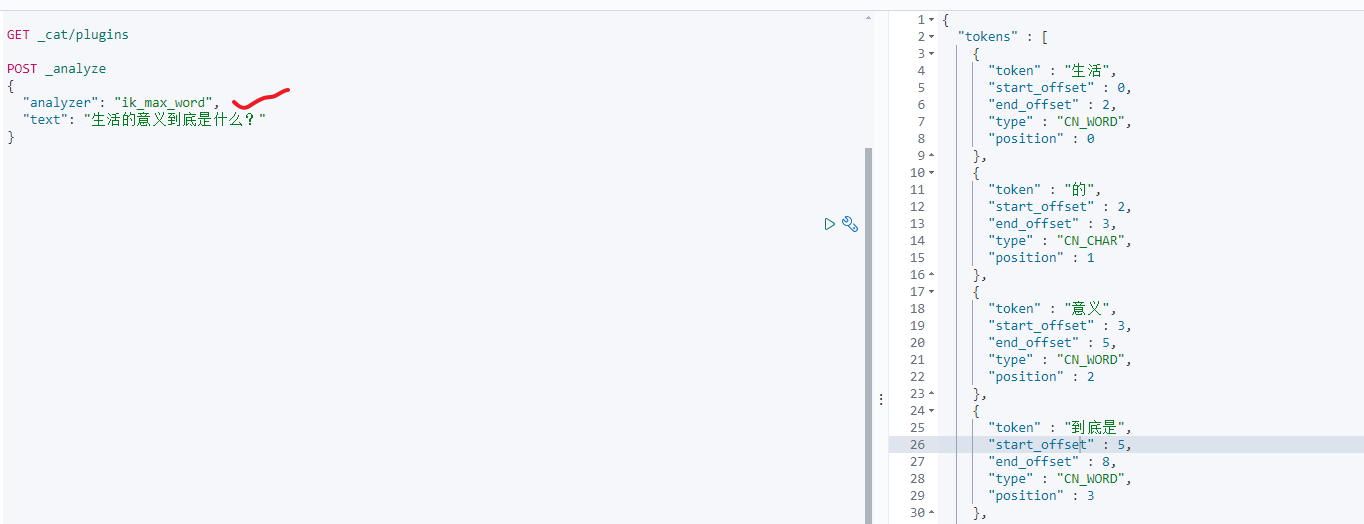
3.3.9:自定义分词器
https://blog.csdn.net/weixin_28906733/article/details/106610972 如果希望自定义一个与standard类似的analyzer,只需要在原定义
- 自定义一个与standard类似的analyzer
先再来看下standard分词器:
charanter Filters:无
Tokennizer:按词切分,就是按照空格切分吧
Token Filters:小写处理
定义和使用:
//测试自定义analyzer
PUT custom_rebuild_standard_analyzer_index
{
"settings": {
"analysis": {
"analyzer": {
"rebuild_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":["lowercase"]
}
}
}
}
}
//测试请求参数
POST custom_rebuild_standard_analyzer_index/_analyze
{
"text": "transimission control protocol is a transport layer protocol"
}
- 自定义一个与simple类似的analyzer
先再来看下simple分词器:
Charanter filters:不提供实现
Tokennizer:按照非字母进行切分(可对比standard分词器只按照空格进行切分),然后还抢了本该属于Token Filters的活,会转小写
Token filters:不提供实现
测试和使用:
//测试自定义analyzer
PUT custom_rebuild_simple_analyzer_index
{
"settings": {
"analysis": {
"analyzer": {
"rebuild_simple":{
"tokenizer":"lowercase",
"filter":[]
}
}
}
}
}
//测试请求参数
POST custom_rebuild_simple_analyzer_index/_analyze
{
"text": "transimission control protocol is a transport layer protocol"
}
写在后面
参考文章列表
Elasticsearch 学习笔记
Elasticsearch是如何做到快速索引的