由于我们目前生活在人工智能革命之中,重要的是要了解许多新应用程序都依赖于向量嵌入(vector embedding)。因此,有必要了解向量数据库以及它们对 LLM 的重要性。
我们首先定义向量嵌入。向量嵌入是一种携带语义信息的数据表示形式,可以帮助人工智能系统更好地理解数据并能够维持长期记忆。
嵌入是由例如 LLM 这样的人工智能模型生成的,它包含大量特征,导致其表示难以管理。嵌入表示数据的不同维度,以帮助人工智能模型理解不同的关系、模式和隐藏结构。
使用传统的基于标量的数据库进行向量嵌入是一个挑战,因为它无法处理或跟上数据的规模和复杂性。由于向量嵌入带来的所有复杂性,所以可以想象它需要的专用数据库。这就是向量数据库发挥作用的地方。
向量数据库为向量嵌入的独特结构提供优化的存储和查询功能。它们通过比较值并查找彼此之间的相似性来提供轻松的搜索、高性能、可扩展性和数据检索。
虽然向量数据库可以处理向量嵌入的复杂结构。但是向量数据库的实现非常困难。
到目前为止,向量数据库仅由那些不仅有能力开发它们而且有能力管理它们的科技巨头使用。向量数据库价格昂贵,因此确保对其进行正确校准对于提供高性能非常重要。
那么向量数据库的工作原理是什么呢?
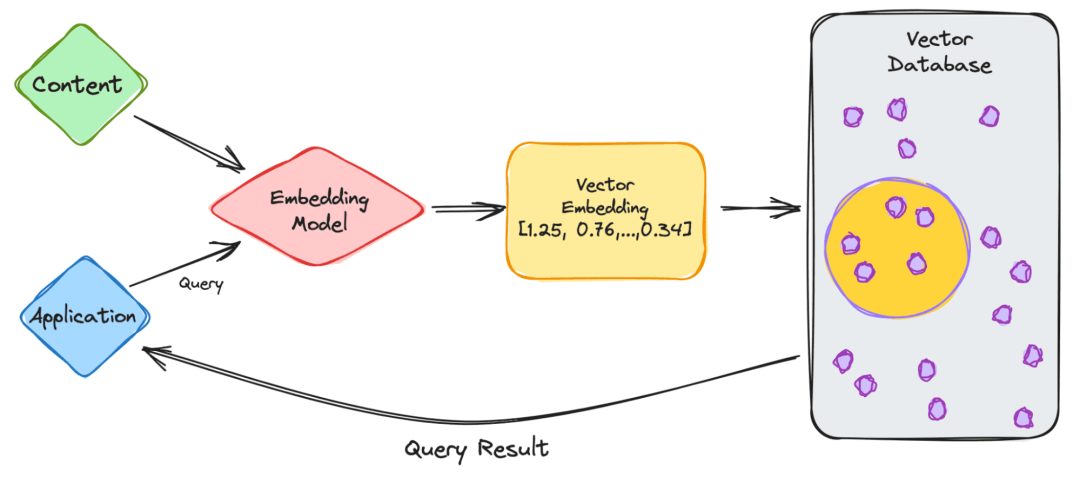
比如,当我们使用 chatGPT 或者其他的 LLM 应用程序时:
-
作为用户,我们将在应用程序(application)中输入查询(query)。
-
然后,我们的查询将被插入到嵌入模型(embedding model)中,该模型根据我们想要索引的内容创建向量嵌入(vector embedding)。
-
再然后,向量嵌入会根据嵌入的内容移入向量数据库(vector database)。
-
最后,向量数据库产生输出并将其作为查询结果(query result)发送回用户。
当用户继续进行查询时,它将通过相同的嵌入模型来创建嵌入,以在数据库中查询类似的向量嵌入。向量嵌入之间的相似性基于创建嵌入的原始内容。
传统数据库在行和列中存储字符串、数字等。当从传统数据库查询时,我们正在查询与我们的查询匹配的行。然而,向量数据库使用向量而不是字符串等。向量数据库还应用相似性度量,用于帮助找到与查询最相似的向量。
向量数据库由不同的算法组成,这些算法都有助于近似最近邻 (Approximate Nearest Neighbor,ANN) 搜索。这是通过散列、基于图形的搜索或量化来完成的,它们被组装到 pipeline 中以检索查询向量的邻居。
结果基于其与查询的接近或近似程度,因此考虑的主要元素是准确性和速度。查询输出越慢,结果越准确。
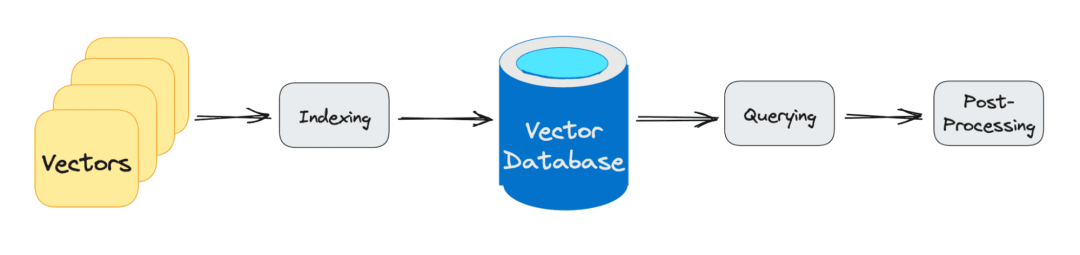
向量数据库查询经历的三个主要阶段是:
-
索引(indexing)。如上例所示,一旦向量嵌入移入向量数据库,它就会使用各种算法将向量嵌入映射到数据结构,以便更快地搜索。
-
查询(querying)。一旦完成搜索,向量数据库就会将查询的向量与索引向量进行比较,应用相似性度量来查找最近的邻居。
-
后处理(post processing)。根据我们使用的向量数据库,向量数据库将对最终最近邻进行后处理,以生成查询的最终输出。 以及可能重新排列最近的邻居以供将来参考。
随着我们不断看到人工智能的发展和每周都会发布的新系统,向量数据库的增长正在发挥重要作用。向量数据库使公司能够通过准确的相似性搜索更有效地进行交互,为用户提供更好更快的输出。