编者按
本次解读的文章发表于 Management Science,原文信息:Hanzhang Qin, David Simchi-Levi, Li Wang (2022) Data-Driven Approximation Schemes for Joint Pricing and Inventory Control Models. https://doi.org/10.1287/mnsc.2021.4212
文章在数据驱动的前提下,研究经典的多周期联合定价和库存控制问题。 在此问题中,零售商定期决定其希望销售的产品的价格和库存水平,其目标是通过将库存水平与随机需求(取决于每个时期的价格)相匹配,在有限的范围内最大化预期利润。
鉴于需求函数或随机噪声分布很难准确掌握完整信息,而过去的需求数据相对容易收集,文章假设零售商对噪声分布或真实的需求函数未知,但假设其可以访问需求假设集,并且真实需求函数可以由需求假设集中候选函数的非负组合表示,或者真实需求函数是广义线性的。基于此,文章提出了一种基于数据驱动的近似算法,使用预先收集的需求数据来解决联合定价和库存控制问题,同时证明了算法的样本复杂度界限。在数值研究中,文章演示了如何从数据构建需求假设集,并验证了所提出的数据驱动算法对动态问题的有效性,其结果显著改善了与基准算法相比的最优性差距。
1 问题介绍
联合定价和库存控制问题以其要求协调定价和库存决策的困难,一直是商业管理中的核心问题之一。大多公司更倾向于跨部门做出独立决策,因此同时考虑定价和库存为公司提供了将其销售和运营活动关联起来的机会。而定价和库存决策的结合更有助于公司提高利润:较高的价格弥补了低库存水平,有助于避免高库存积压量,而较低的价格则加速高库存水平的消耗,降低库存持有成本。 然而,这个问题在理论上和实践中都很难解决,尤其当随机需求的确切形式未知时。
在文章中,作者们研究了数据驱动环境下的多周期联合定价和库存控制问题。 具体来说,文章假设销售单一商品的零售商定期对商品的定价和库存策略做出决策,这直接影响获得的收入和产生的成本。 零售商的目标是通过将库存水平与随机需求(取决于每个时期的价格)相匹配,在多个时期的有限计划范围内最大化总利润(总收入减去总成本)。
在运营管理研究界,该文章前的大多数文献关于此问题的研究基本均假设:零售商确切地知道需求和价格之间的函数依赖性(需求函数)以及需求中的随机噪声分布(噪声分布),即全信息问题。 然而在实践中,需求函数和噪声分布通常并不准确,或者过于复杂而难以处理,而过去的销售数据相对容易收集,即在数据驱动的环境中的此被定义为数据驱动问题。
2 联合定价和库存控制模型
如上所述,文章考虑销售单一商品的零售商,并在 T T T期内定期决定该商品的定价和库存策略。 在每个周期 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T] 开始时,库存水平为 x t x_t xt,零售商做出两个决策:单位售价 p t ∈ [ p t min , p t max ] p_t\in[p_t^{\min},p_t^{\max}] pt∈[ptmin,ptmax] 和库存水平 y t ≥ x t y_t\geq x_t yt≥xt. 假设交货时间 (lead time) 为零,则零售商立即收到 y t − x t ≥ 0 y_t-x_t\geq 0 yt−xt≥0大小的补货。 在每个周期结束时,零售商满足非负随机需求。
假设1:在每个时期 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T]中,随机需求为 D t ( p t ) + η t D_t(p_t)+\eta_t Dt(pt)+ηt,其中 D ( ⋅ ) D(\cdot) D(⋅)是确定性需求期望函数,而 η t \eta_t ηt是在 [ ω t min , ω t max ] [\omega_t^{\min},\omega_t^{\max}] [ωtmin,ωtmax]上有界的零均值连续随机变量,且在时间上独立。 η t \eta_t ηt的累积分布函数是 Lipschitz 连续的,常数为 I t I_t It.
假设 1 中定义的随机需求的形式称为加性需求函数(Chen 和 Simchi-Levi 2004),其随机性会加性地影响需求。 剩余库存水平 y t − D t ( p t ) − η t y_t-D_t(p_t)-\eta_t yt−Dt(pt)−ηt结转到下一个时期并成为其起始库存水平 x t + 1 x_{t+1} xt+1;若剩余库存水平为负,则零售商积压 (backlog) 所有未满足的需求。
零售商对实现的每个需求单位获得
p
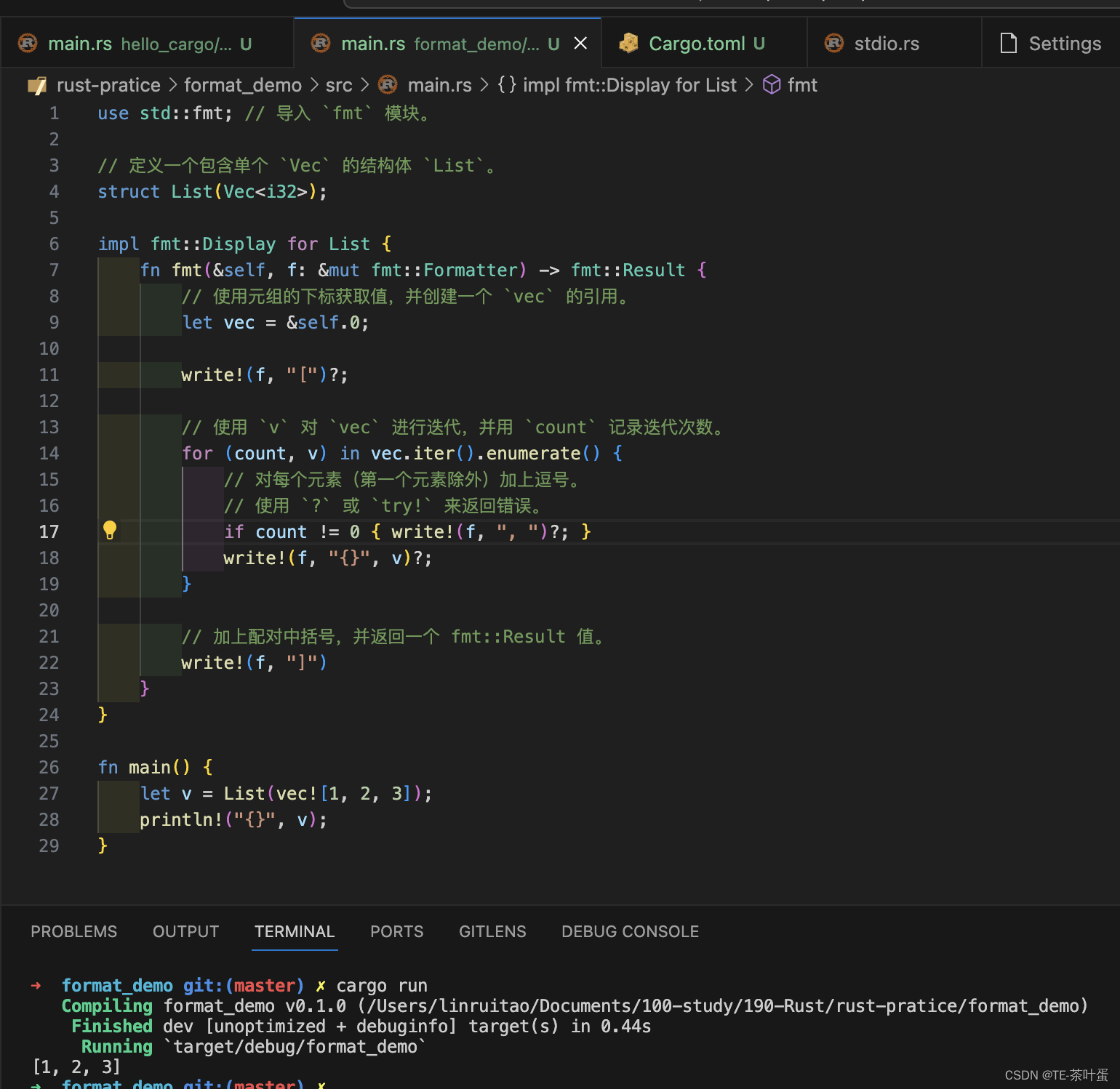
t
p_t
pt的单位收益,从而在
t
t
t期间收到
p
t
D
t
(
p
t
)
p_tD_t(p_t)
ptDt(pt)的预期收益。 零售商为每次补货单位支付
c
t
≥
0
c_t\geq 0
ct≥0的单位订购成本。 在每个时期结束时,每单位正剩余库存会产生
h
≥
0
h\geq 0
h≥0的持有成本,而每单位负剩余库存会产生
b
t
≥
0
b_t\geq 0
bt≥0的积压成本。因此,
t
t
t期间的预期成本为
c
t
(
y
t
−
x
t
)
+
E
η
t
[
h
t
(
y
t
−
D
t
(
p
t
)
−
η
t
)
+
+
b
t
(
D
t
(
p
t
)
+
η
t
−
y
t
)
+
]
c_t(y_t-x_t)+\mathbb{E}_{\eta_t}[h_t(y_t-D_t(p_t)-\eta_t)^+ + b_t(D_t(p_t)+\eta_t-y_t)^+]
ct(yt−xt)+Eηt[ht(yt−Dt(pt)−ηt)++bt(Dt(pt)+ηt−yt)+]
假设单位订购成本为零,则
t
t
t期间的预期利润为
p
t
D
t
(
p
t
)
−
C
t
(
y
t
−
D
t
(
p
t
)
)
p_tD_t(p_t)-C_t(y_t-D_t(p_t))
ptDt(pt)−Ct(yt−Dt(pt))
其中 C t ( q t ) : = E η t [ h t ( q t − η t ) + + b t ( η t − q t ) + ] C_t(q_t):=\mathbb{E}_{\eta_t}[h_t(q_t-\eta_t)^+ + b_t(\eta_t-q_t)^+] Ct(qt):=Eηt[ht(qt−ηt)++bt(ηt−qt)+].
假设 2. 在每个时期 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T]中, D t ( ⋅ ) D_t(\cdot) Dt(⋅)的反函数 D t − 1 ( ⋅ ) D_t^{-1}(\cdot) Dt−1(⋅)是二次连续可微且严格递减的,其一阶导数和二阶导数是有界的。此外,预期收入函数 R t ( d t ) : = d t D t − 1 ( d t ) R_t(d_t):=d_tD_t^{-1}(d_t) Rt(dt):=dtDt−1(dt)在预期需求 d t d_t dt中严格凹。
假设 2 是联合定价和库存控制问题的标准假设(Chen and Simchi-Levi 2004),其保证了动态规划的凹性。 结合假设1,应用和分析样本平均近似方法至关重要。在全信息问题中, D t ( ⋅ ) D_t(\cdot) Dt(⋅)与 D t − 1 ( ⋅ ) D_t^{-1}(\cdot) Dt−1(⋅)已知,因此决策 d t ∈ [ d t min , d t max ] : = [ D t ( p t min ) , D t ( p t max ) ] d_t\in[d_t^{\min},d_t^{\max}]:=[D_t(p_t^{\min}),D_t(p_t^{\max})] dt∈[dtmin,dtmax]:=[Dt(ptmin),Dt(ptmax)]与 p t = D t − 1 ( d t ) ∈ [ p t min , p t max ] p_t=D_t^{-1}(d_t)\in[p_t^{\min},p_t^{\max}] pt=Dt−1(dt)∈[ptmin,ptmax]等价。不失一般性,假设 p t min p_t^{\min} ptmin和 d t min d_t^{\min} dtmin在 t ∈ [ T ] t\in[T] t∈[T]上非负,因此 t t t期的期望收益亦可写为 R t ( d t ) − C t ( y t − d t ) R_t(d_t)-C_t(y_t-d_t) Rt(dt)−Ct(yt−dt). 假设第一个周期的起始库存为 x 1 x_1 x1,并且 T T T周期之后的任何剩余库存的残值为零,零售商的目标是通过优化每个时期 t t t中 p t p_t pt和 y t y_t yt的决策来最大化 T T T周期内的总预期利润。
然而实际上,零售商很难确切地了解期望需求函数 D t ( ⋅ ) D_t(\cdot) Dt(⋅)和 η t \eta_t ηt的分布,但收集模型的过去数据较之容易。文章随后对全信息问题和数据驱动问题的模型分别作出讨论。
2.1 全信息问题
当零售商拥有有关模型的完整信息,即 D t ( ⋅ ) D_t(\cdot) Dt(⋅)和 η t \eta_t ηt已知时,预期利润最大化问题就是经典的有限范围联合定价和库存控制问题,可被如下定义 ( P \mathcal{P} P)
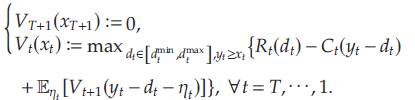
其中 V t ( x t ) V_t(x_t) Vt(xt)为起始库存水平 x t x_t xt下 t t t至 T T T期的最优期望收益。对于 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T],文章定义 U t ( y t , d t ) U_t(y_t,d_t) Ut(yt,dt)为起始库存水平 y t y_t yt、期望需求 d t d_t dt下 t t t至 T T T期的最优期望收益,即
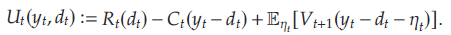
令最优需求方程为
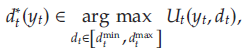
且令 W t ( y t ) W_t(y_t) Wt(yt)表示 t t t至 T T T期间的最优预期利润,假设零售商将 t t t期间的库存水平设置为 y t y_t yt, 即
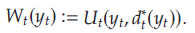
因此亦有
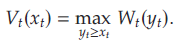
则最优基础库存清单需求策略 (base-stock list-demand policy) ( S t ∗ , D t ∗ ) (S_t^*,D_t^*) (St∗,Dt∗)可被定义为

依据该库存策略,对于 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T],
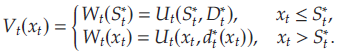
2.2 数据驱动问题
在数据驱动的问题中,零售商对 D t ( ⋅ ) D_t(\cdot) Dt(⋅)或 η t \eta_t ηt未知,因此无法计算最优的基本库存定价策略。 相反,零售商拥有模型的过往数据,并希望使用某些算法,将数据作为输入并计算可以产生接近最优利润的库存和定价决策。 文章通过数据驱动解决方案产生的预期利润 与 最优策略产生的预期利润之间的 绝对利润损失 来衡量这种近似最优性。
文章假设对于任意时期 t t t, 需求假设集合为 Φ t : = { D t 1 ( ⋅ ) , … , D t K t ( ⋅ ) } \Phi_t:=\{D_t^1(\cdot),\ldots,D_t^{K_t}(\cdot)\} Φt:={Dt1(⋅),…,DtKt(⋅)}预先已知,其中未知的真实需求函数 D t ( ⋅ ) D_t(\cdot) Dt(⋅)为 Φ \Phi Φ集合内函数的线性组合。另外定义 R t k ( p t ) : = p t D t k ( p t ) R_t^k(p_t):=p_tD_t^k(p_t) Rtk(pt):=ptDtk(pt)及 R t k ( d t ) : = d t ( D t k ) − 1 ( d t ) R_t^k(d_t):=d_t(D_t^{k})^{-1}(d_t) Rtk(dt):=dt(Dtk)−1(dt)为作为所有 t t t和 k k k的 Φ t \Phi_t Φt中的相关收益函数。
假设3:在每个时期 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T]中, 存在非负系数 θ t , 1 ∗ , … , θ t , K t ∗ \theta_{t,1}^*,\ldots,\theta_{t,K_t}^* θt,1∗,…,θt,Kt∗满足真实需求函数
D t ( ⋅ ) = ∑ k = 1 K t θ t , k ∗ ( D t k ) ( ⋅ ) D_t(\cdot)=\sum_{k=1}^{K_t}\theta_{t,k}^*(D_t^k)(\cdot) Dt(⋅)=k=1∑Ktθt,k∗(Dtk)(⋅)
假设 3 对于主要样本复杂性的分析至关重要。该假设允许保留参数空间的线性结构以进行学习和优化,同时允许基础需求函数具有高度非线性的形式。
满足上述假设的有效需求函数包括线性需求函数的非负组合,或指数/对数需求函数与适当选择的价格区间的非负组合。 由于 Φ t \Phi_t Φt中的所有需求假设都是 D t ( ⋅ ) D_t(\cdot) Dt(⋅) 的有效候选者(即满足假设 2),因此零售商无法利用 Φ t \Phi_t Φt提供的信息直接识别真实的需求函数。然而,零售商一般希望通过 Φ t \Phi_t Φt和历史数据来找到 D t ( ⋅ ) D_t(\cdot) Dt(⋅),其一般为 N t N_t Nt个价格-需求对 ( p t j , d t j ) (p_t^j,d_t^j) (ptj,dtj)的形式,其中 j ∈ [ 1 , … , N t ] j\in[1,\ldots,N_t] j∈[1,…,Nt]. 特别地,任一价格 p t j p_t^j ptj均属于区间 [ p t min , p t max ] [p_t^{\min},p_t^{\max}] [ptmin,ptmax],以及任一需求样本均可表示为 d t j : = D t ( p t j ) + η t j d_t^j:=D_t(p_t^j)+\eta_t^j dtj:=Dt(ptj)+ηtj,其中 η t j \eta_t^j ηtj是随机噪声 η t \eta_t ηt的一实际值。
由于没有关于 d t j d_t^j dtj, p t j p_t^j ptj 的分布的特定假设,文章仅施加简单条件以满足应用普通最小二乘分析的条件。现定义特征矩阵

其中包括使用不同的假设需求函数在数据集中的所有价格下评估的预期需求的信息。
假设4:对于任一时期 t ∈ [ T ] t\in[T] t∈[T],假设 N t ≥ K t N_t\geq K_t Nt≥Kt且存在普适常数 λ ‾ t > 0 \underline{\lambda}_t>0 λt>0满足 λ min ( Γ t T Γ t / N t ) ≥ λ ‾ t \lambda_{\min} (\mathbb{\Gamma}_t^{T}\mathbb{\Gamma}_t/N_t)\geq \underline{\lambda}_t λmin(ΓtTΓt/Nt)≥λt.
假设 4 确保使用价格需求样本的回归过程得到明确定义。 N t ≥ K t N_t\geq K_t Nt≥Kt意味着每个时期至少有 K t K_t Kt个价格需求样本,即减少了 θ ∗ \theta^* θ∗上的误差界限。 另外,样本协方差矩阵 Γ t T Γ t / N t \mathbb{\Gamma}_t^{T}\mathbb{\Gamma}_t/N_t ΓtTΓt/Nt的最小特征值远离零的假设意味着 Γ t T Γ t \mathbb{\Gamma}_t^T\mathbb{\Gamma}_t ΓtTΓt是正定的,因此也是可逆的;继而最小二乘解是唯一的。
直观上看,这是指不完全共线性的情况,即特征向量( Γ t \mathbb{\Gamma}_t Γt任一行向量)中没有任何变量可以表示为其他变量的仿射函数。假设下限与数据大小无关也是温和的,因为大多数常见的采样模型自然满足这个条件。例如,如果所有价格样本都是独立且同分布的,并且是根据高斯分布生成的,那么便可使用均值、基础高斯分布的(协)方差,以及 Negahban and Wainwright (2011) 引理 2 的需求函数,计算显式通用下界 λ t \lambda_t λt,使得 λ min ( Γ t T Γ t / N t ) ≥ λ ‾ t \lambda_{\min} (\mathbb{\Gamma}_t^{T}\mathbb{\Gamma}_t/N_t)\geq \underline{\lambda}_t λmin(ΓtTΓt/Nt)≥λt(概率很高)。
对于任何近似算法
A
\mathcal{A}
A,令
D
^
t
(
⋅
)
\hat{D}_t(\cdot)
D^t(⋅)和
η
^
t
\hat{\eta}_t
η^t分别为经验预期需求函数和经验噪声分布,由
t
∈
[
1
,
…
,
T
]
t\in[1,\ldots,T]
t∈[1,…,T]每一个时期的历史数据和算法
A
\mathcal{A}
A估计所得。令
R
^
t
(
⋅
)
\hat{R}_t(\cdot)
R^t(⋅)为通过
A
\mathcal{A}
A所得的经验收益函数,且定义
[
d
^
t
min
,
d
^
t
max
]
:
=
[
D
^
t
(
p
t
max
)
,
D
^
t
(
p
t
min
)
]
[\hat{d}_t^{\min},\hat{d}_t^{\max}]:=[\hat{D}_t(p_t^{\max}),\hat{D}_t(p_t^{\min})]
[d^tmin,d^tmax]:=[D^t(ptmax),D^t(ptmin)]
为经验期望需求的决策空间。因此有
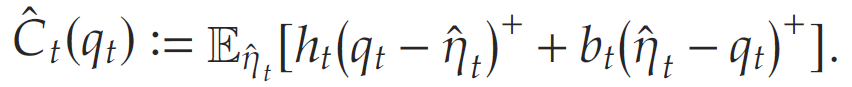
现定义经验动态规划 P ^ \hat{\mathcal{P}} P^
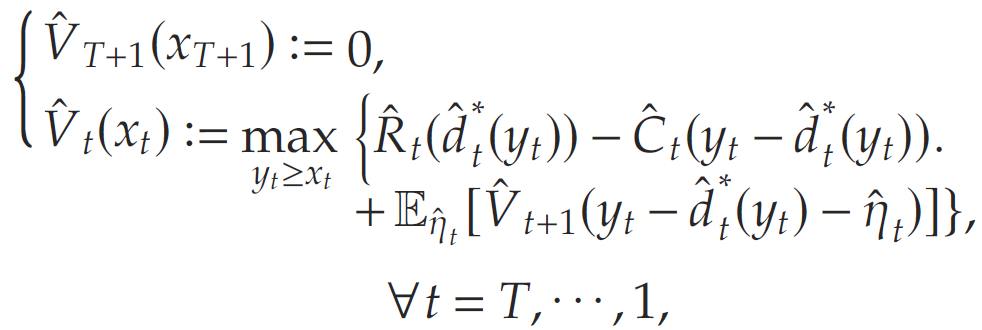
其中
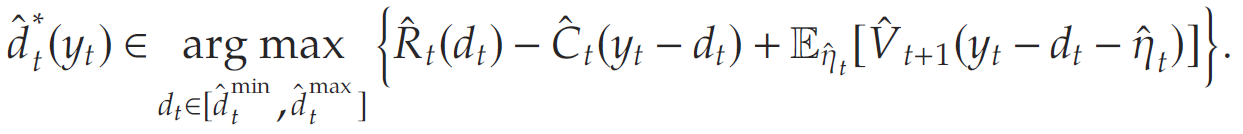
同时定义经验函数与经验策略如下:
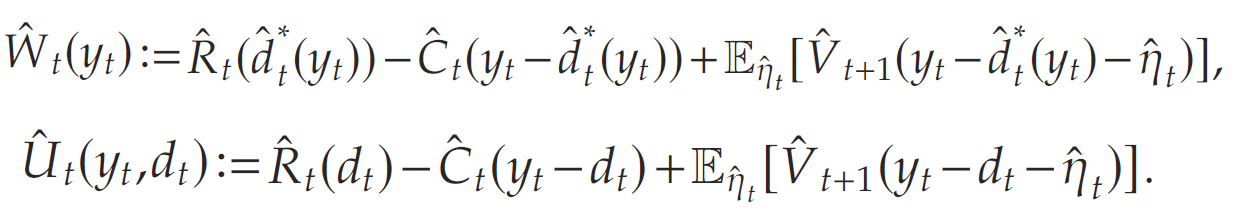
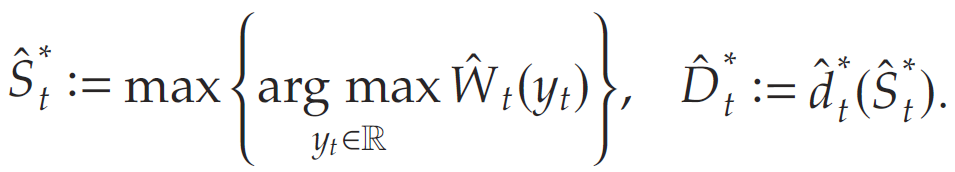
与全信息动态规划 P \mathcal{P} P类似,经验动态规划 P ^ \hat{\mathcal{P}} P^可以使用后向归纳法递归求解。
假设近似算法 A \mathcal{A} A构造的经验收益函数 R ^ t ( ⋅ ) \hat{R}_t(\cdot) R^t(⋅)和经验噪声分布 η ^ t \hat{\eta}_t η^t满足假设5,则经验动态程序 P ^ \hat{\mathcal{P}} P^与全信息动态程序 P \mathcal{P} P具有相同的结构。
假设5:在每个时期 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T]中, R ^ t ( d t ) \hat{R}_t(d_t) R^t(dt)在 d t d_t dt中可微且严格凹,并且 η ^ t \hat{\eta}_t η^t具有有限均值和有界支持集 [ ω ^ t min , ω ^ t max ] [\hat{\omega}_t^{\min},\hat{\omega}_t^{\max}] [ω^tmin,ω^tmax].
3 数据驱动近似算法
在数据驱动问题,文章给出每个时期 t t t需求假设集合 Φ t : = { D t 1 ( ⋅ ) , … , D t K t ( ⋅ ) } \Phi_t:=\{D_t^1(\cdot),\ldots,D_t^{K_t}(\cdot)\} Φt:={Dt1(⋅),…,DtKt(⋅)}以及过往价格-需求对 { ( p t 1 , d t 1 ) , … , ( p t N t , d t N t ) } \{(p_t^1,d_t^1),\ldots,(p_t^{N_t},d_t^{N_t})\} {(pt1,dt1),…,(ptNt,dtNt)},基于此二者,文章的目标是构建经验收益函数 R ^ t ( d t ) \hat{R}_t(d_t) R^t(dt)与经验分布函数 η ^ t \hat{\eta}_t η^t.
以下是所提出的近似算法 DDPIC 的步骤,该算法在每个时期构造经验收入和成本函数的导数,即 R ^ t ′ ( ⋅ ) \hat{R}'_t(\cdot) R^t′(⋅) 与 与 与 C ^ t r ( ⋅ ) \hat{C}^r_t(\cdot) C^tr(⋅):
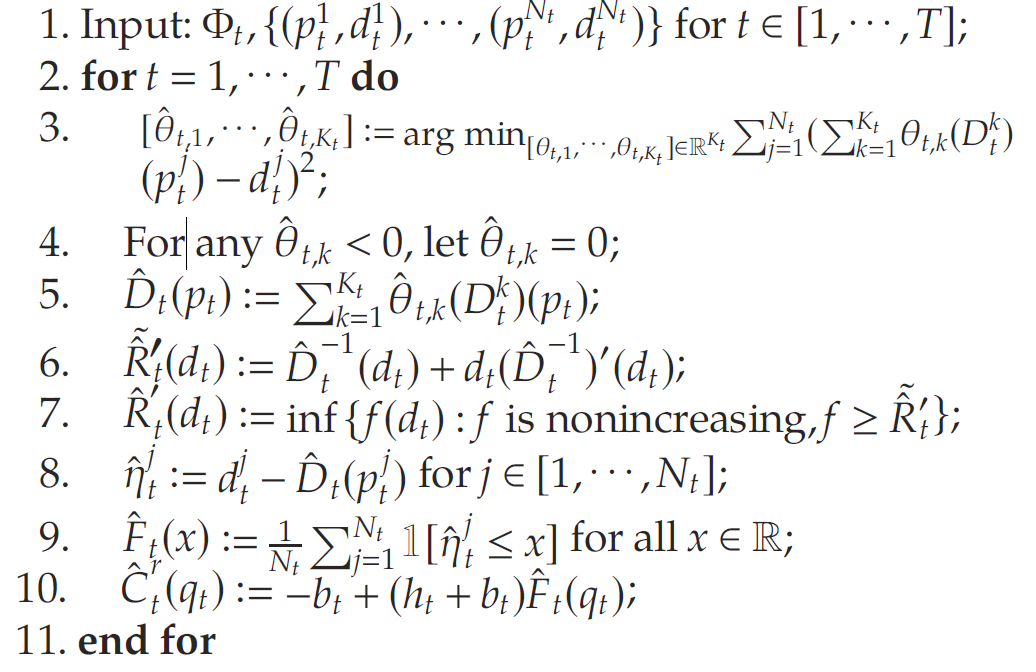
简单来说,算法从需求假设集中,通过普通最小二乘分析找到具有最小(有偏差)噪声样本平均值的需求函数 D ^ t \hat{D}_t D^t;再通过计算上单调包络来求取需求函数的逆函数,保持导数 R ^ t ′ \hat{R}_t^{'} R^t′的单调性;最后,将经验分布 η ^ t \hat{\eta}_t η^t构建为 η ^ t j \hat{\eta}_t^j η^tj上的离散均匀分布以及报童成本 C ^ t r \hat{C}_t^r C^tr的(右)导数经验估计。
文章在此处主要关注算法的样本效率,算法的计算效率在原文的5.3节中有详细讨论,本篇解读稍后会深入。
鉴于 R ^ t \hat{R}_t R^t与 η ^ t \hat{\eta}_t η^t由算法构建,文章通过引理证明该算法成立。
关于算法的近似性能,文章根据数据驱动函数和真实函数之间导数的接近程度来讨论。现定义
η
^
t
j
=
d
t
j
−
D
^
t
(
p
t
j
)
=
η
t
j
−
Δ
t
j
\hat{\eta}_t^j=d_t^j-\hat{D}_t(p_t^j)=\eta_t^j-\Delta_t^j
η^tj=dtj−D^t(ptj)=ηtj−Δtj
为 η t \eta_t ηt的某偏差样本,其中 Δ t j : = D t ( p t j ) − D ^ t ( p t j ) \Delta_t^j:=D_t(p_t^j)-\hat{D}_t(p_t^j) Δtj:=Dt(ptj)−D^t(ptj). 于是文章定义“好”事件 E ( α ) \mathcal{E}(\alpha) E(α)如下:
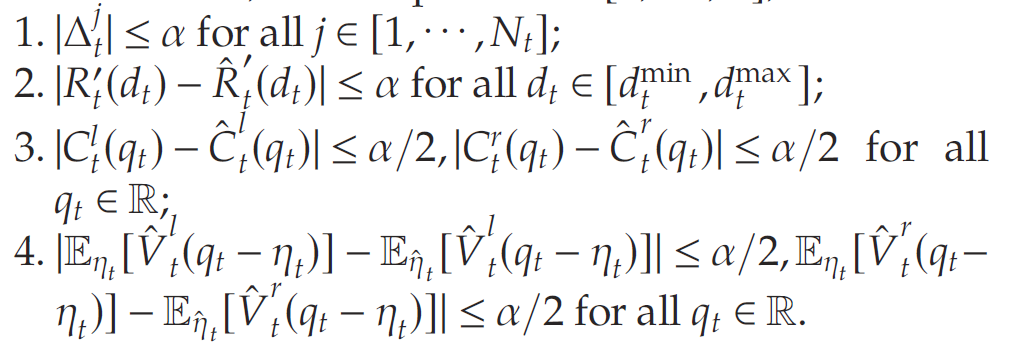
事件 E \mathcal{E} E表示,所提出算法给出了原始动态规划 P \mathcal{P} P中某些函数(的导数)的良好近似。原文随后通过三个引理(详见原文引理2-4)证明了 R ^ t ( ⋅ ) \hat{R}_t(\cdot) R^t(⋅), C ^ t ( ⋅ ) \hat{C}_t(\cdot) C^t(⋅)和 E η ^ t [ V ^ t ( q t − η ^ t ) ] \mathbb{E}_{\hat{\eta}_t}[\hat{V}_t(q_t-\hat{\eta}_t)] Eη^t[V^t(qt−η^t)]在导数方面分别与 R t ( ⋅ ) R_t(\cdot) Rt(⋅), C t ( ⋅ ) C_t(\cdot) Ct(⋅)和 E η t [ V ^ t ( q t − η t ) ] \mathbb{E}_{\eta_t}[\hat{V}_t(q_t-\eta_t)] Eηt[V^t(qt−ηt)]近似,概率随 N t N_t Nt增长。再通过引理5给出准确度系数 α \alpha α与 V ^ t ( ⋅ ) \hat{V}_t(\cdot) V^t(⋅)上下界的关系,进而得到定理1,即对于任一 α > 0 \alpha>0 α>0,所提出算法能够达到 α \mathcal{\alpha} α的概率的下界(该下界数值详见原文定理1)。
4 样本复杂度界限
文章接下来讨论近似算法的经验策略与最优策略相比,作为样本数量 N t N_t Nt的函数的表现如何。考虑任何准确度级别 ϵ > 0 \epsilon>0 ϵ>0和任何置信度级别 1 − β 1-\beta 1−β(其中 0 < β < 1 0<\beta<1 0<β<1)。 文章运用了足够数量的样本 N t ( T , ϵ , β ) N_t(T,\epsilon,\beta) Nt(T,ϵ,β),以确保以至少 1 − β 1-\beta 1−β 的概率,经验策略的预期利润与最优预期利润之间的绝对差最多为 ϵ \epsilon ϵ.
具体来说,在好事件 E ( α ) \mathcal{E}(\alpha) E(α)下,文章推导出经验政策的预期利润与最优预期利润之间的绝对差的上限(用 T T T和 α \alpha α表示)。 该分析分为两部分:
一阶分析:文章证明经验函数的导数与真实函数非常一致(close uniformly),即在很高的概率下,对于某些常数 α F O > 0 \alpha_{FO}>0 αFO>0,有
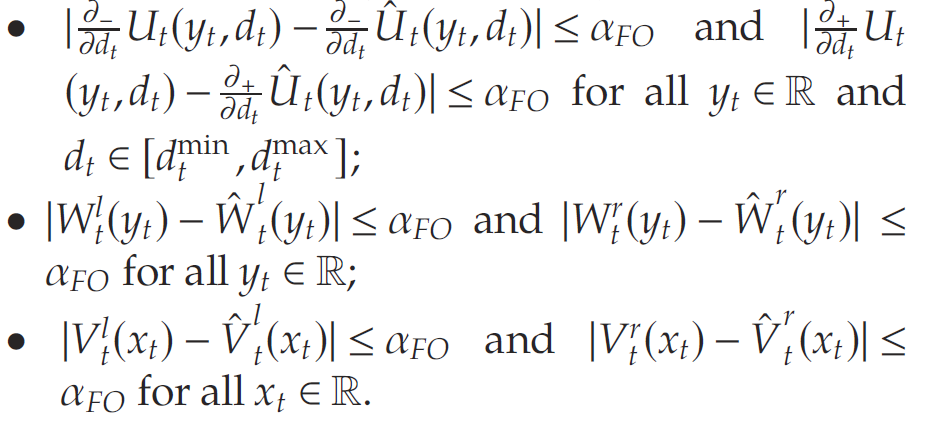
零阶分析:结合一阶分析的结果,实证政策的预期利润与最优预期利润一致接近; 即在很高的概率下,对于一些小常数 α F O > 0 \alpha_{FO}>0 αFO>0,有

基于此,所提出的数据驱动近似算法的样本复杂度界限 N t ( T , ϵ , β ) N_t(T,\epsilon,\beta) Nt(T,ϵ,β). 文章通过数据驱动解决方案的预期利润与最佳预期利润之间的绝对差来衡量近似算法的性能。样本复杂度界限 N t ( ϵ , β ) N_t(\epsilon,\beta) Nt(ϵ,β)被定义为数据驱动算法在每个周期所需的足够数量的数据样本,以保证总预期利润与最优利润的差异不大于概率至少为 1 − β 1-\beta 1−β.
定理(原文定理4):对于任意 ϵ > 0 \epsilon >0 ϵ>0且 β ∈ ( 0 , 1 ) \beta\in(0,1) β∈(0,1),若每个时期 t ∈ [ 1 , … , T ] t\in[1,\ldots,T] t∈[1,…,T]内 N t ≥ N t ( ϵ , β ) N_t\geq N_t(\epsilon,\beta) Nt≥Nt(ϵ,β),则最优期望利润与期望值之间(通过数据驱动策略)的利润的绝对差距不大于 ϵ \epsilon ϵ的概率至少为 1 − β 1-\beta 1−β,其中 N t ( T , ϵ , β ) = O ( T 4 ( T − t + 1 ) 2 ϵ − 2 log ( T / β ) . N_t(T,\epsilon,\beta)=O(T^4(T-t+1)^2\epsilon^{-2}\log(T/\beta). Nt(T,ϵ,β)=O(T4(T−t+1)2ϵ−2log(T/β).
上述定理中推导出的样本复杂度界限对于 β \beta β的依赖性而言是最优的,因为其与单周期有容量限制的报童问题的信息论下界相匹配(Cheung and Simchi-Levi 2019)。 然而,对 T T T的依赖性是否紧密仍然未知,因相应的下界仍然是开放的。 给定准确度水平和概率水平 β \beta β来获得 T T T阶段联合定价和库存控制问题的近乎最优策略,该界限可以被视为对公司所需样本数量的保守估计。 该界限是保守的,因其为针对 η t \eta_t ηt的所有可能的基础分布和 Φ t \Phi_t Φt中所有可能的基础需求函数的最坏情况界限。
我们将在后续推文继续解读该文章,讨论算法的松弛、拓展问题以及其数值实验和主要结果。
参考文献
Chen X, Simchi-Levi D (2004) Coordinating inventory control and pricing strategies with random demand and fixed ordering cost: The finite horizon case. Oper. Res. 52(6):887–896.
Cheung WC, Simchi-Levi D (2019) Sampling-based approximation schemes for capacitated stochastic inventory control models. Math. Oper. Res. 44(2):668–692.
Negahban S, Wainwright MJ (2011) Estimation of (near) low-rank matrices with noise and high-dimensional scaling. Ann. Statist. 39(2):1069–1097.

![C++ lambda [],[=] ,[],[this] 的使用](https://img-blog.csdnimg.cn/direct/19b17deddfa24d78a8ec746f65db9511.png)