引言
在当今数据驱动的时代,机器学习已经成为了解锁数据潜能的关键技术之一。其中,聚类作为机器学习领域的一个重要分支,广泛应用于数据挖掘、模式识别、图像分析等多个领域。本文旨在深入探讨聚类技术的原理、类型及其应用,为读者提供一个全面而深入的了解。

一、什么是聚类?
聚类是一种无监督学习(Unsupervised Learning)技术,它的目标是将相似的对象分组到一起,形成簇(Cluster)。与有监督学习不同,聚类在学习过程中不依赖于事先标注的训练数据,而是通过分析数据本身的特征和相似性来进行分组。简单来说,聚类就是根据相似度将数据集合分成多个类别的过程。
二、关键概念
- 相似度和距离:聚类过程中,相似度(或距离)的计算是核心步骤。常用的距离计算方法包括欧氏距离、曼哈顿距离、余弦相似度等。
- 簇:由相似或相关元素组成的集合。聚类的目的就是要找到这些簇。
- 质心:在某些聚类算法中,质心是代表簇中所有点的中心点。
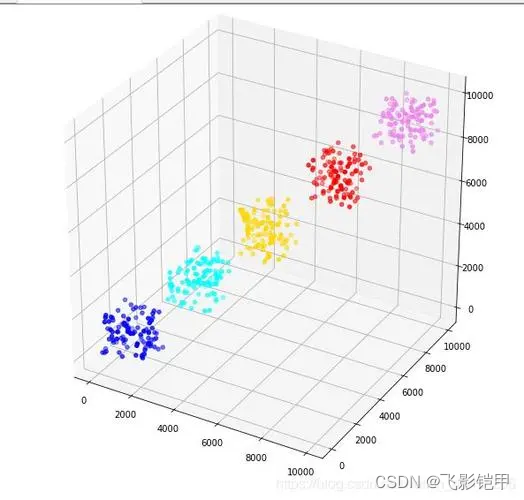
三、常见算法
聚类算法可以大致分为以下几种类型:
1. 划分方法
划分方法将数据集划分为若干个不相交的子集,每个子集就是一个簇。最典型的算法是K-means,它通过迭代的方式优化簇内距离的总和,直到满足特定的终止条件。
2. 层次方法
层次聚类通过逐步合并或分裂现有的簇来构建一个层次结构。这种方法的一个典型代表是AGNES(自底向上的聚合策略)和DIANA(自顶向下的分裂策略)。
3. 基于密度的方法
这类方法根据密度(数据点的紧密程度)来形成簇。DBSCAN是一个经典的例子,它可以发现任何形状的簇,并且能够处理噪声数据。
4. 基于网格的方法
基于网格的方法将数据空间划分为有限数量的单元格,然后在这些单元格上进行快速聚类。STING和CLIQUE是此类方法的例子。
5. 基于模型的方法
这类方法假设数据是由混合模型生成的,通过优化模型参数来寻找最佳的簇划分。高斯混合模型(GMM)是其中的一个代表。
四、应用
聚类技术在许多领域都有广泛的应用,包括:
- 客户细分:通过聚类分析,企业可以将客户分成不同的群体,以提供更加个性化的服务或产品。
- 图像分割:在图像处理中,聚类可用于将图像分割成具有相似特征的区域,便于进一步分析。
- 社交网络分析:聚类可以帮助识别社交网络中的社区结构,理解用户群体的特性。
- 基因表达数据分析:在生物信息学中,聚类用于分析基因表达数据,揭示基因功能和调控机制。
总结
聚类是一种强大且灵活的机器学习技术,它通过将数据分组来揭示数据的内在结构和模式。不同的聚类算法各有优缺点,适用于不同类型的数据集和应用场景。随着技术的不断进步,聚类技术也在不断地发展和完善,为我们提供了更多的可能性和机遇。了解和掌握聚类技术,将有助于我们更好地利用数据,发现新的知识和洞见。