目录
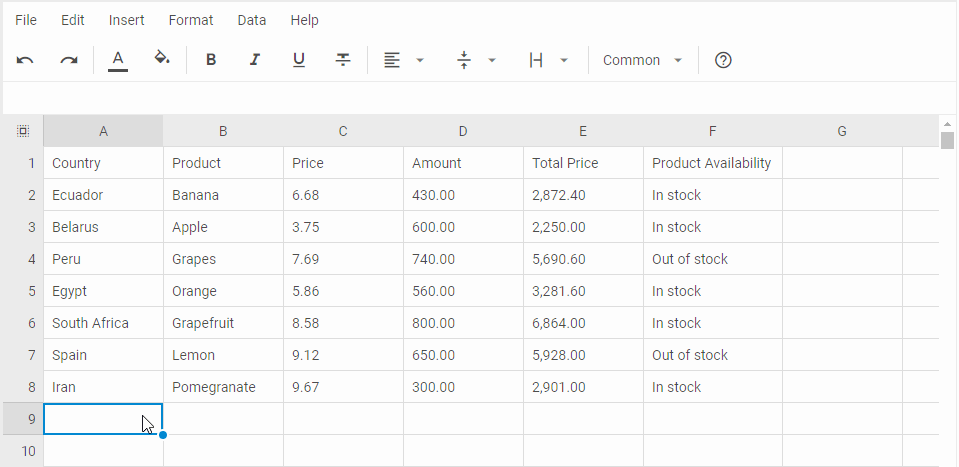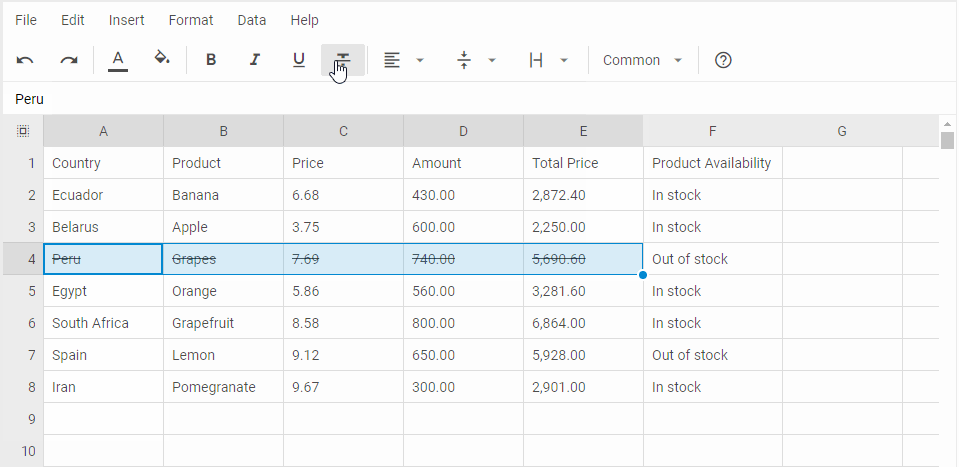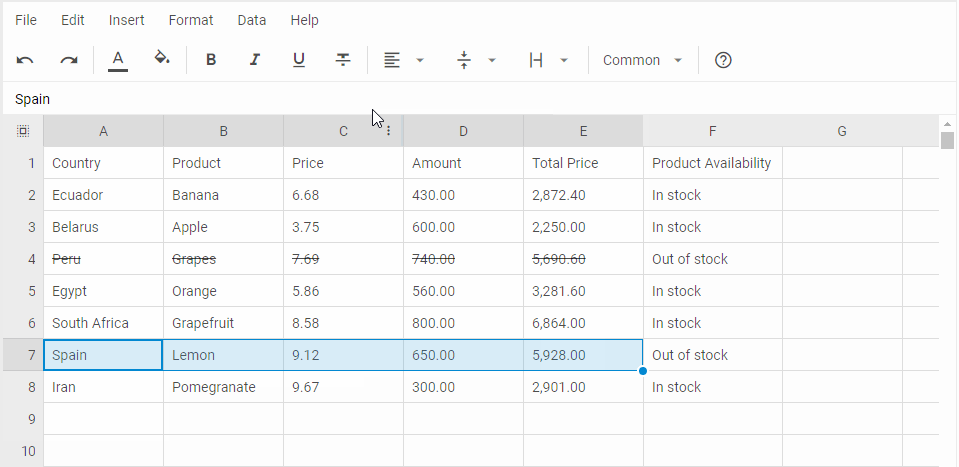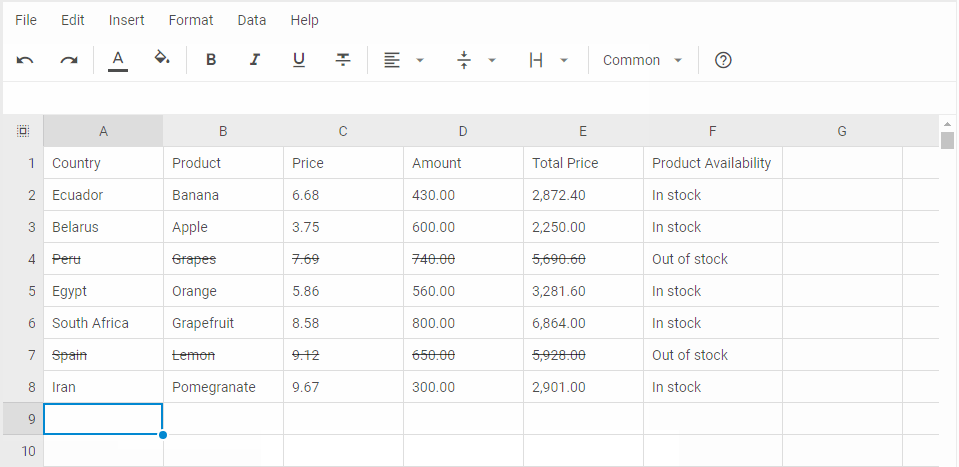
1.函数作用
2.函数流程
3.函数解析
3.1 传入参数解析
3.2 找出和当前帧具有公共单词的所有关键帧,不包括与当前帧连接的关键帧
3.3 统计上述所有闭环候选帧lKFsSharingWords中与当前帧具有共同单词最多的单词数,用来决定相对阈值
3.4 遍历上述所有闭环候选帧,挑选出共有单词数大于minCommonWords且单词匹配度大于minScore存入lScoreAndMatch
3.5 单单计算当前帧和某一关键帧的相似性是不够的,这里将与关键帧相连(权值最高,共视程度最高)的前十个关键帧归为一组,计算累计得分
3.6 只取组得分大于阈值的组,得到组中分数最高的关键帧们作为闭环候选关键帧
1.函数作用
在闭环检测中找到与该关键帧可能闭环的关键帧(注意不和当前帧连接)。
2.函数流程
* Step 1:找出和当前帧具有公共单词的所有关键帧,不包括与当前帧连接的关键帧。
* Step 2:只和具有共同单词较多的(最大数目的80%以上)关键帧进行相似度计算 。
* Step 3:计算上述候选帧对应的共视关键帧组的总得分,只取最高组得分75%以上的组。
* Step 4:得到上述组中分数最高的关键帧作为闭环候选关键帧。
3.函数解析
3.1 传入参数解析
函数的传入参数:
@pKF : 关键帧pKF,本函数的目的是找到关键帧pKF的闭环候选帧
@minScore : 帧pKF和其所有共视关键帧的相似度得分的最低值,且得分越低相似度越低,ORB-SLAM2算法认为回环候选帧与帧pKF的相似度得分不得低于这个分数
函数由LoopClosing::DetectLoop调用,目的是在关键帧数据库mpKeyFrameDB中找到帧pKF的闭环候选关键帧。
我们首先获取与该关键帧连接(>15个共视地图点)的关键帧(没有排序的)。存储在变量spConnectedKeyFrames中。
// 得到与该关键帧连接(>15个共视地图点)的关键帧(没有排序的) set<KeyFrame*> KeyFrame::GetConnectedKeyFrames() { unique_lock<mutex> lock(mMutexConnections); set<KeyFrame*> s; for(map<KeyFrame*,int>::iterator mit=mConnectedKeyFrameWeights.begin();mit!=mConnectedKeyFrameWeights.end();mit++) s.insert(mit->first); return s; }建立变量lKFsSharingWords保存可能与当前关键帧形成闭环的候选帧。
3.2 找出和当前帧具有公共单词的所有关键帧,不包括与当前帧连接的关键帧
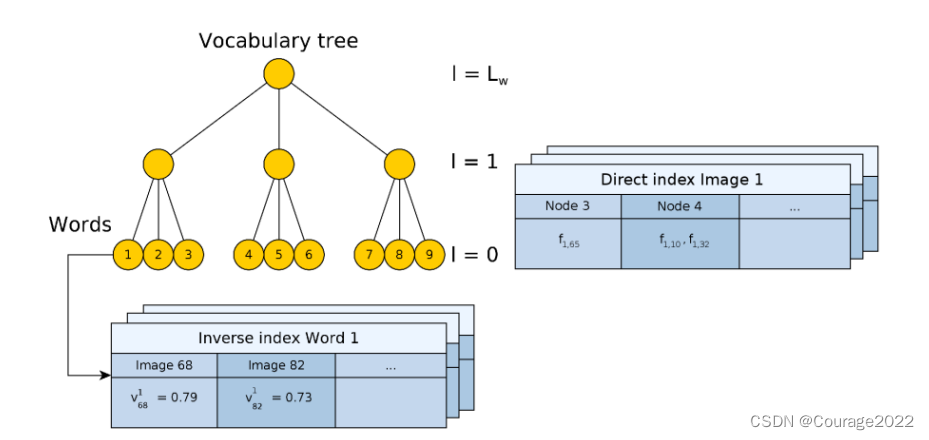
先说一个知识点:倒排索引
// 倒排索引,mvInvertedFile[i]表示包含了第i个word id的所有关键帧 std::vector<list<KeyFrame*> > mvInvertedFile;
我们遍历pKF帧的BowVector向量:
如果有不了解BoWVec的,推荐看完我的博客之后再继续往下看:
详解什么是BowVec和FeatVec
https://blog.csdn.net/qq_41694024/article/details/128007040
通过倒排索引取出所有word的KeyFrame(即所有与pKF帧有相同描述子的帧)存放在变量lKFs中。然后对这些关键帧lKFs展开遍历:
如果这帧没有标记为当前帧pKF的候选关键帧(即这些帧的mnLoopQuery标记不是pKF的帧ID,这么做的目的是为了防止重复添加),我们将此帧的mnLoopWords置为0,即初始化该帧和pKF的能看见相同地图点的数量为0。
若该帧和当前关键帧共视的话不作为闭环候选帧,因为闭环候选帧是能和当前帧有相同的观测但不相连。
若该帧和当前关键帧没有共视的话作为闭环候选帧,将该帧的mnLoopQuery标记为pKF的帧ID,并将该帧放入lKFsSharingWords中作为闭环候选关键帧。
如果这帧标记为当前帧pKF的候选关键帧,则将mnLoopWords++。
完成3.2节这些之后,我们得到了一个闭环候选关键帧的集合lKFsSharingWords,并且这里面的关键帧的mnLoopWords属性记录着该帧和pKF帧的共视程度。

3.3 统计上述所有闭环候选帧lKFsSharingWords中与当前帧具有共同单词最多的单词数,用来决定相对阈值
我们遍历lKFsSharingWords中的关键帧,统计上述所有闭环候选帧中与当前帧具有共同单词最多的单词数存放在maxCommonWords变量中,并取maxCommonWords的0.8倍为最小公共单词数用于进一步筛选闭环候选关键帧,存储在minCommonWords中。
3.4 遍历上述所有闭环候选帧,挑选出共有单词数大于minCommonWords且单词匹配度大于minScore存入lScoreAndMatch
我们新建变量lScoreAndMatch用于存储这一步从lKFsSharingWords筛选后的关键帧,其定义格式为list<pair<float,KeyFrame*> >。
遍历每一个在lKFsSharingWords中的关键帧,pKF只和具有共同单词较多(大于minCommonWords)的关键帧进行比较,若公共单词数少则直接淘汰掉该帧。计算此帧和pKF的相似度得分,记录在该帧的mLoopScore中,如果这个score大于我们传入的参数,则将该帧的分数和帧存入lScoreAndMatch变量中等待下一轮的筛选。
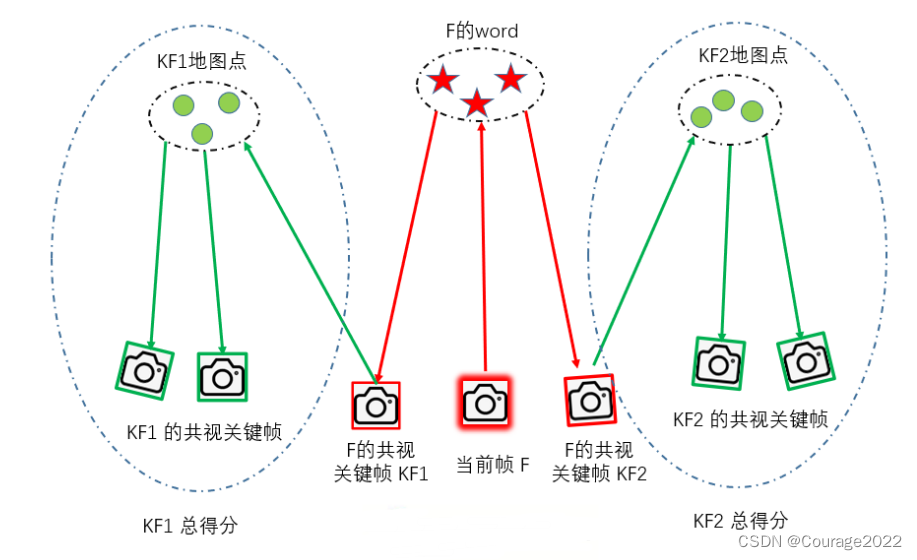
3.5 单单计算当前帧和某一关键帧的相似性是不够的,这里将与关键帧相连(权值最高,共视程度最高)的前十个关键帧归为一组,计算累计得分
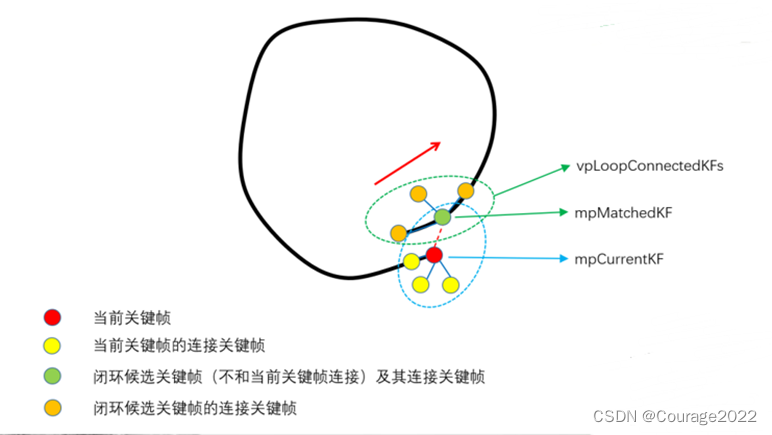
我们遍历lScoreAndMatch中的每一帧,对其中的每一帧,我们建立一个关键帧组,取出和它连接的共视程度最好的十个关键帧。
即在上图中表现出来即是,lScoreAndMatch是对应的红色的帧,对于每一个红色帧,建立一个关键帧组(对应绿色部分)。
在每一组中,记录组中的最高得分bestScore、累计得分accScore、该组最高分数对应的关键帧pBestKF。
遍历每一组内的关键帧更新这三个变量,且只有这些帧也在闭环候选帧中,且公共单词数超过最小要求,才能贡献分数。
并记录所有组中组得分最高的组的得分bestAccScore,用于确定相对阈值。
走完3.5节后我们完成了如下流程:
对于每个关键帧组:我们得到了该组内分数最高的关键帧pBestKF以及得分bestScore和该组的累计得分accScore。
对于所有关键帧组:我们得到了所有组中组得分最高的组bestAccScore。
对于整个函数:我们创立list<pair<float,KeyFrame*> >型变量lAccScoreAndMatch,存储闭环候选关键帧和它的组分数。
3.6 只取组得分大于阈值的组,得到组中分数最高的关键帧们作为闭环候选关键帧
此步我们进行最终筛选,我们设置筛选阈值minScoreToRetain为所有组中最高得分的0.75倍。
遍历lAccScoreAndMatch,只取组得分大于阈值的组,得到组中分数最高的关键帧们作为闭环候选关键帧。将最终的候选的关键帧放入vpLoopCandidates容器中,返回给上层函数。