目录
- 环境
- 1. 安装cudnn
- 2. 使用pytorch自带NCCL库进行编译
- 3. 修改NCCL源代码并重新编译后测试,体现出源码更改
环境
- Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)
- cuda 11.8+ cudnn 8
- python 3.10
- torch V2.0.1+ nccl 2.14.3
- NVIDIA GeForce RTX 4090 *2
1. 安装cudnn
下载cudnn包之后打开
cd cudnn-linux-x86_64-8.9.7.29_cuda11-archive
sudo cp ./include/cudnn*.h /usr/local/cuda/include
sudo cp ./lib/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn*.h
chmod a+r /usr/local/cuda/lib64/libcudnn*
确认已经安装cudnn,除了cudnn_version.h,务必检查同目录下也有cudnn_ops_infer.h文件
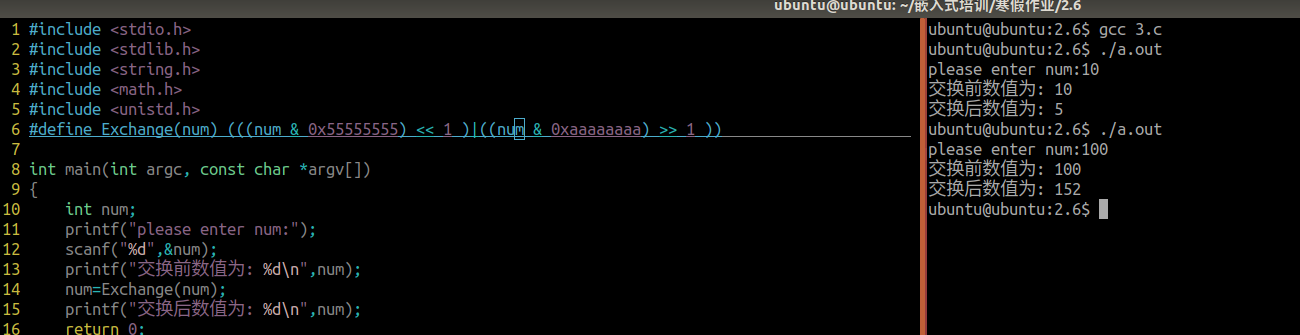
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
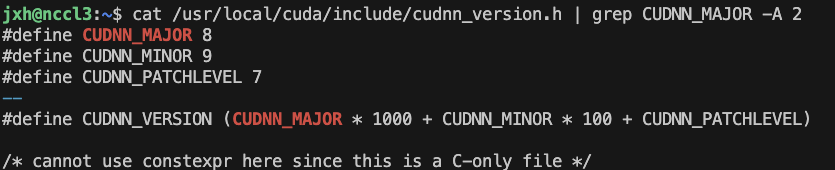
可以看到对应cudnn版本为8.9.7
2. 使用pytorch自带NCCL库进行编译
这里选择在 docker 内进行源码编译和修改,方便直接将 docker 打包到新机器,方便移植,减少配置环境的问题的同时也避免破坏本地环境。
如果不用docker的话,之前是新建了一个conda 环境mynccl,编译之前先
conda activate mynccl,再使用mynccl对应的解释器执行setup.py实测也是可以的。
使用 python setup.py 命令进行源码编译,develop 命令通常在开发过程中使用,以在"开发模式"中安装包,其中对源代码的更改会立即生效而无需重新安装。develop更改为install 就是直接安装。
#下载v2.0.1 源码
git clone --branch v2.0.1 --recursive https://github.com/pytorch/pytorch
cd pytorch/ # v2.0.1
pip install -r requirements.txt
#编译源码-不使用本地nccl
#这里添加了USE_GLOO=0,未添加之前会报与gloo有关的错误,
#因为我的目的是研究nccl就暂时不用gloo了,不知道其他版本的torch会不会有类似问题
#正常的话只用MAX_JOBS=32 USE_CUDA=1 USE_NCCL=1 USE_SYSTEM_NCCL=0 python setup.py develop即可
MAX_JOBS=32 USE_CUDA=1 USE_NCCL=1 USE_SYSTEM_NCCL=0 USE_GLOO=0 python setup.py develop
未添加use gloo=0时报错如下:

编译成功提示如下:
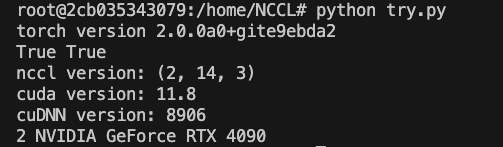
编译完毕,测试能否用torch,cuda,nccl以及识别出GPU。这里新建了一个try.py
# try.py
import torch
print("torch version",torch.__version__)
print(torch.cuda.is_available(), torch.distributed.is_nccl_available())
print("nccl version:",torch.cuda.nccl.version())
print("cuda version:", torch.version.cuda)
cudnn_version = torch.backends.cudnn.version()
print("cuDNN version:", cudnn_version)
print(torch.cuda.device_count(), torch.cuda.get_device_name(0))
结果如下,可以看到nccl版本,对应双卡等
3. 修改NCCL源代码并重新编译后测试,体现出源码更改
执行以下代码,使用 nccl 作为通信后端,测试分布式训练中张量的 all_reduce 操作。
#test.py
import os
import torch
import torch.distributed as dist
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group("nccl", rank=0, world_size=1)
x = torch.ones(6)
if torch.cuda.is_available():
y = x.cuda()
dist.all_reduce(y)
print(f"cuda allreduce: {y}")

修改 pytorch/third_party/nccl/nccl/src/collectives/all_reduce.cc 文件后,重新编译
原代码如下
/*************************************************************************
* Copyright (c) 2015-2020, NVIDIA CORPORATION. All rights reserved.
*
* See LICENSE.txt for license information
************************************************************************/
#include "enqueue.h"
NCCL_API(ncclResult_t, ncclAllReduce, const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, ncclComm* comm, cudaStream_t stream);
ncclResult_t ncclAllReduce(const void* sendbuff, void* recvbuff, size_t count,ncclDataType_t datatype, ncclRedOp_t op, ncclComm* comm, cudaStream_t stream)
{
NVTX3_FUNC_RANGE_IN(nccl_domain);
struct ncclInfo info = { ncclFuncAllReduce, "AllReduce",
sendbuff, recvbuff, count, datatype, op, 0, comm, stream, /* Args */
ALLREDUCE_CHUNKSTEPS, ALLREDUCE_SLICESTEPS };
return ncclEnqueueCheck(&info);
}
我们将函数内部全部注释掉,加一句 return ncclSystemError;
/*************************************************************************
* Copyright (c) 2015-2020, NVIDIA CORPORATION. All rights reserved.
*
* See LICENSE.txt for license information
************************************************************************/
#include "enqueue.h"
NCCL_API(ncclResult_t, ncclAllReduce, const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, ncclComm* comm, cudaStream_t stream);
ncclResult_t ncclAllReduce(const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, ncclComm* comm, cudaStream_t stream)
{
// NVTX3_FUNC_RANGE_IN(nccl_domain);
// struct ncclInfo info = { ncclFuncAllReduce, "AllReduce",
// sendbuff, recvbuff, count, datatype, op, 0, comm, stream, /* Args */
// ALLREDUCE_CHUNKSTEPS, ALLREDUCE_SLICESTEPS };
// return ncclEnqueueCheck(&info);
return ncclSystemError;
}
每次修改pytorch中Nccl源码生效需要进行重新编译,先删除原有编译文件再重新编译
#删除原有nccl相关的
rm -r pytorch/build/nccl*
#重新编译
MAX_JOBS=32 USE_CUDA=1 USE_NCCL=1 USE_SYSTEM_NCCL=0 USE_GLOO=0 python setup.py develop
#运行测试文件,看看有没有报错
python test.py

报错ncclSystemError,体现出了源码的更改。