三者的区别
- 训练集(train set) —— 用于模型拟合的数据样本。
- 验证集(validation set)—— 是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。 通常用来在模型迭代训练时,用以验证当前模型泛化能力(准确率,召回率等),以决定是否停止继续训练。
在神经网络中, 我们用验证数据集去寻找最优的网络深度(number of hidden layers),或者决定反向传播算法的停止点或者在神经网络中选择隐藏层神经元的数量;
在普通的机器学习中常用的交叉验证(Cross Validation) 就是把训练数据集本身再细分成不同的验证数据集去训练模型。
- 测试集 —— 用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。
小规模数据集
对于传统机器学习阶段(数据集在万这个数量级),一般分配比例为训练集和测试集的比例为7:3或是8:2。为了进一步降低信息泄露同时更准确的反应模型的效能,更为常见的划分比例是训练集、验证集、测试的比例为6:2:2。
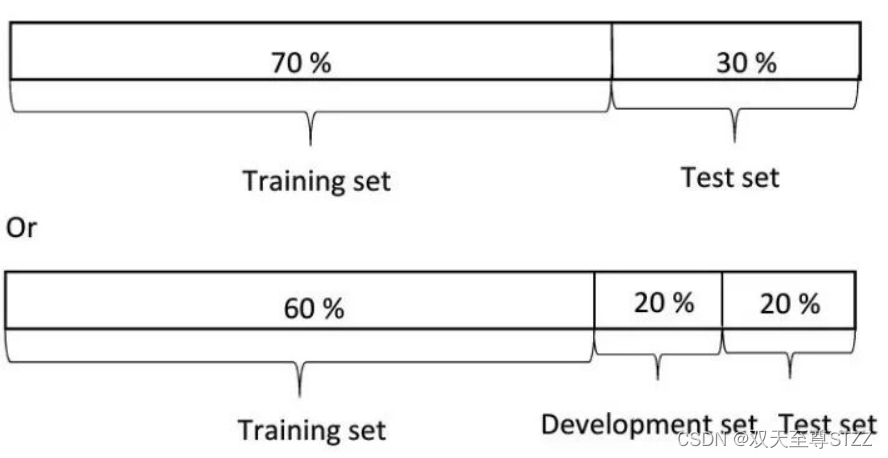
对于小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。
大规模数据集
而大数据时代,这个比例就不太适用了。因为百万级的数据集,即使拿1%的数据做test也有一万之多,已经足够了。可以拿更多的数据做训练。因此常见的比例可以达到98:1:1,甚至可以达到99.5:0.3:0.2等。
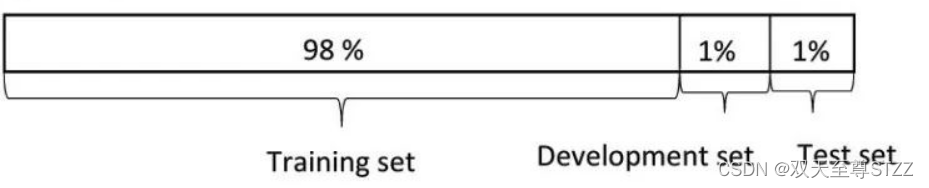
对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。



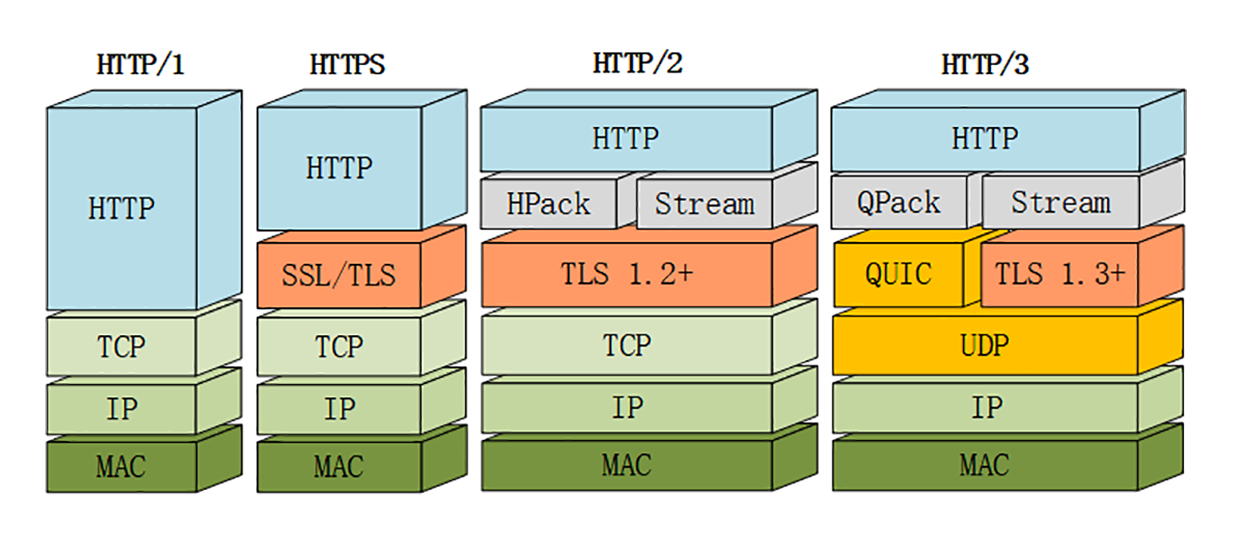

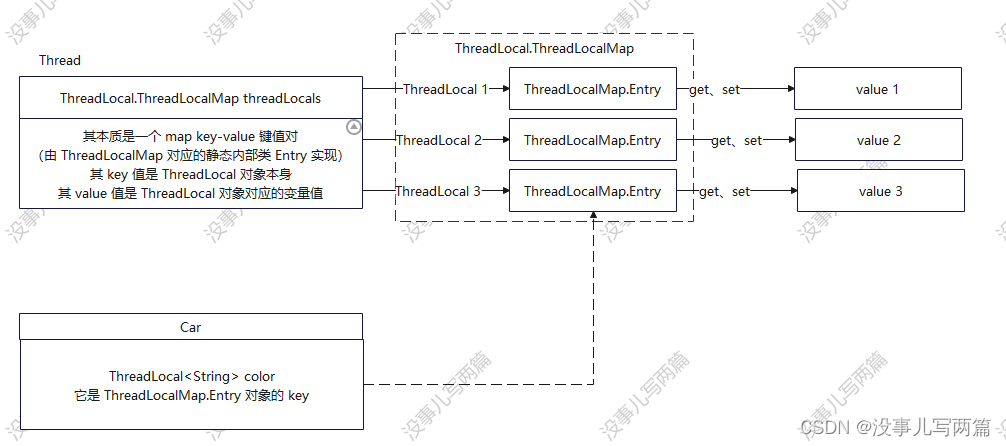
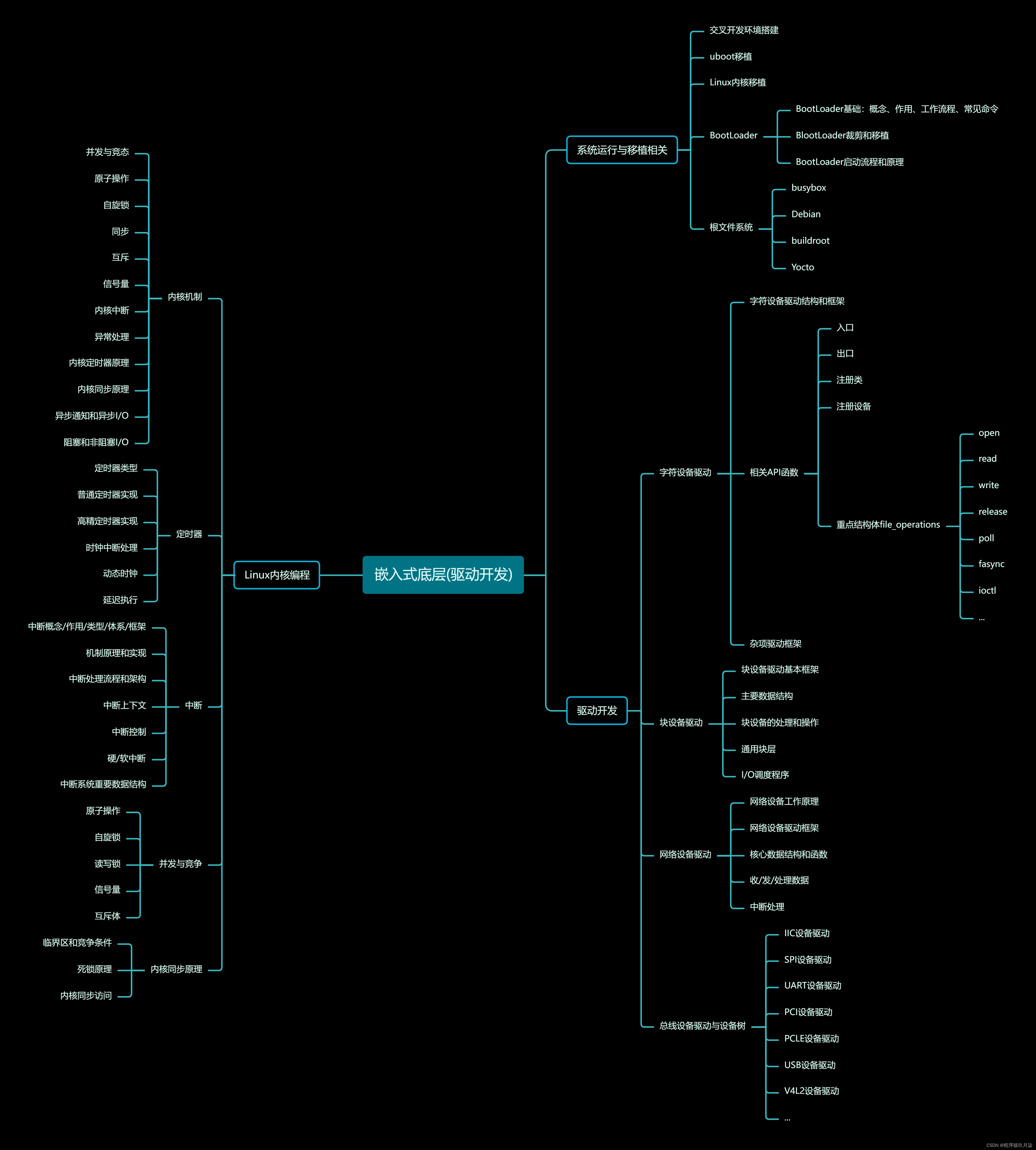
![【PyTorch][chapter 15][李宏毅深度学习][Neighbor Embedding-LLE]](https://img-blog.csdnimg.cn/direct/091f57fee7244cd8abac80af960ede62.png)


![[word] word表格内容自动编号 #经验分享#微信#其他](https://img-blog.csdnimg.cn/img_convert/fb445b31d281f1b6d97a58a56f7c7cdf.gif)