题目概述
小明维护着一个程序员论坛。现在他收集了一份”点赞”日志,日志共有 N 行。
其中每一行的格式是:
ts id
表示在 ts 时刻编号 id 的帖子收到一个”赞”。
现在小明想统计有哪些帖子曾经是”热帖”。
如果一个帖子曾在任意一个长度为 D 的时间段内收到不少于 K 个赞,小明就认为这个帖子曾是”热帖”。
具体来说,如果存在某个时刻 T 满足该帖在
[
T
,
T
+
D
)
[T,T+D)
[T,T+D)
这段时间内(注意是左闭右开区间)收到不少于 K 个赞,该帖就曾是”热帖”。
给定日志,请你帮助小明统计出所有曾是”热帖”的帖子编号。
输入格式
第一行包含三个整数 N,D,K。
以下 N 行每行一条日志,包含两个整数 ts 和 id。
输出格式
按从小到大的顺序输出热帖 id。
每个 id 占一行。
数据范围
1
≤
K
≤
N
≤
1
0
5
,
1 ≤ K ≤ N ≤10^5,
1≤K≤N≤105,
0
≤
t
s
,
i
d
≤
1
0
5
0 ≤ ts, id ≤ 10^5
0≤ts,id≤105
1
≤
D
≤
10000
1 ≤ D ≤ 10000
1≤D≤10000
输入样例:
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
输出样例:
1
3
双指针算法是一种优化的思想,我们可以先想一下暴力的做法。
题意:有n条日志,统计在某个时间长度为d的区间中如果帖子的点赞数 >= k,那就判断它是热帖。最后输出所有热帖。
那么我们如果要暴力的话就是从小到大枚举每一个时间段,统计该时间段中各帖子的点赞情况,若满足条件就输出帖子id。这样的话时间复杂度也要 1 0 9 10^9 109,肯定是通过不了,我们需要进行优化。第一层循环不好优化,我们只能想办法优化里面的内容。
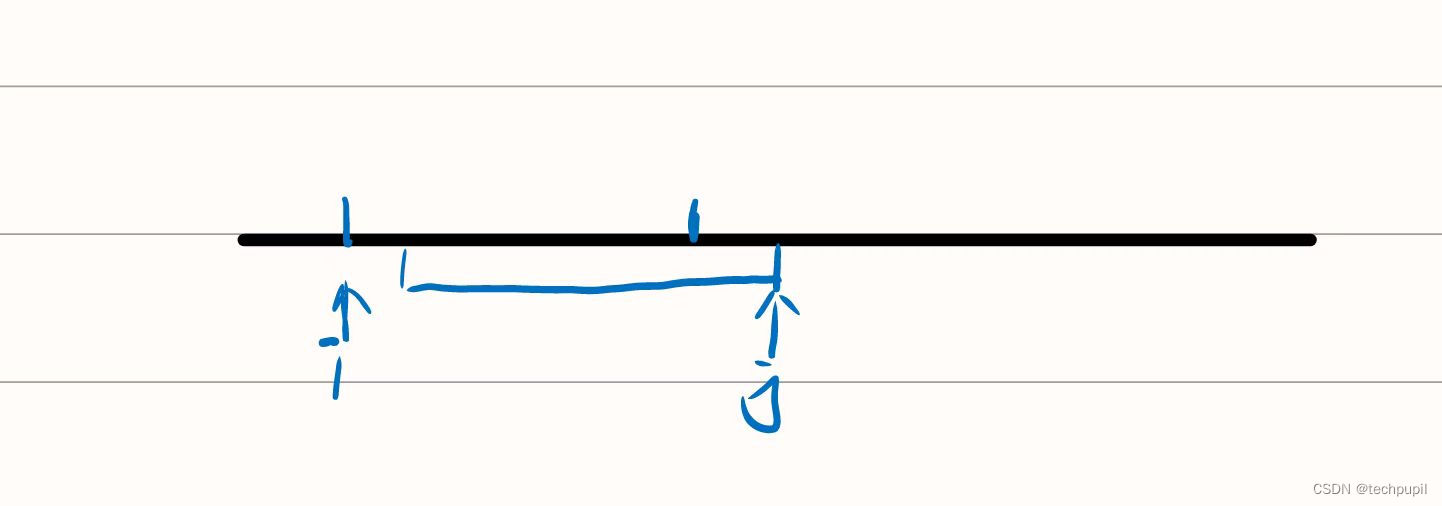
我们可以发现,在相邻的两个时间段中,大部分都是重复的,那么第二个时间段的结果不就是上一个减去时间i时的点赞,加上时间j时的点赞,这样我们就用两个指针将其优化为一重循环了
- 完整代码
里面还是有一些细节的
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <iostream>
#include <cmath>
using namespace std;
// 方便书写
#define x first
#define y second
// 用pair对来存储日志,方便排序(pair对默认根据第一元素升序排列)
typedef pair<int, int> PII;
const int N = 100005;
int n, d, k;
PII logs[N]; // 表示日志
int cnt[N];
bool st[N];
int main() {
cin >> n >> d >> k;
for (int i = 0; i < n; i ++)
cin >> logs[i].x >> logs[i].y;
sort(logs, logs + n);
// i在前,j在后
for (int i = 0, j = 0; j < n; j ++) {
// 每次都添加一条日志
int id = logs[j].y;
cnt[id] ++;
// 如果时间满了,就移动i指针,这里不能写成if循环,一个时间点可能有多条日志
while (logs[j].x - logs[i].x >= d) {
cnt[logs[i].y] --;
i ++;
}
if (cnt[id] >= k)
st[id] = true;
}
for (int i = 0; i <= 100000; i ++) {
if (st[i])
cout << i << endl;
}
}
- 本题的分享就结束了,本题主要就是学习一个双指针的优化思想,第一次思考不好理解。
别忘了点赞关注加收藏!

![【PyTorch][chapter 15][李宏毅深度学习][Neighbor Embedding-LLE]](https://img-blog.csdnimg.cn/direct/091f57fee7244cd8abac80af960ede62.png)


![[word] word表格内容自动编号 #经验分享#微信#其他](https://img-blog.csdnimg.cn/img_convert/fb445b31d281f1b6d97a58a56f7c7cdf.gif)


](https://img-blog.csdnimg.cn/direct/c68f0d99341f461ca94e024fe056db23.png)