QAnything和BCEmbedding简介
QAnything[github]是网易有道开源的检索增强生成式应用(RAG)项目,在有道许多商业产品实践中已经积累丰富的经验,比如有道速读和有道翻译。QAnything是一个支持任意格式文件或数据库的本地知识库问答系统,可获得准确、快速、靠谱的问答体验。QAnything支持断网离线使用,可私有化。
BCEmbedding是网易有道研发的两阶段检索算法库,作为QAnything的基石发挥着重要作用。作为RAG技术路线中最为重要和基础的一环,二阶段检索器一般由粗召回和精排这个模块组成。本文将详细讲述有道BCEmbedding二阶段检索算法的设计和实践过程,为RAG社区语义检索的研发提供思路。
背景介绍
检索增强生成(Retrieval-Augmented Generation, RAG)
开放域问答(Open domain question answering,ODQA)是自然语言处理(NLP)中一个长期存在的任务,也是实际生产生活中经常遇到的需求。ODQA的任务目标是根据大规模语料(知识库)相关信息,以自然语言的形式来对用户的问题进行回答,而不是仅仅将相关文本片段罗列出来[1][2]。如图一所示[1],ODQA技术原型一般包含两个主要模块:检索器(Retriever)和阅读器(Reader)。其中,Retriever模块的作用是根据用户的query在大规模语料中检索到相关候选片段,这些片段包含回答用户问题所需的信息。目前,常用的Retriever有稀疏表示检索(比如,TF-IDF[6]和BM25[3]),以及密集向量检索(比如,DPR[4]和RocketQAv2 [5])。Reader模块的作用是根据检索出来的相关背景材料,进行理解、总结、提炼、推理等,给出最终人性化(自然语言形式)的回答。常见的Reader采用transformer架构,一般分为两种,一种是信息抽取式Reader(比如,BERT[7]、 RoBERTa[8]等),另一种是文本到文本的生成式Reader(比如,T5[9]、BART[10]、GPT[11]等)。
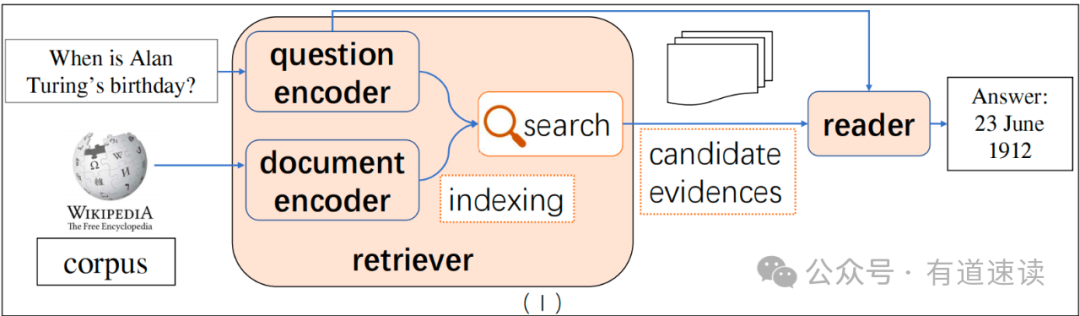
图一、开放域问答框架图
2022年底,OpenAI发布了对话大语言模型(Large Language Model, LLM)产品ChatGPT[13],ChatGPT因其“善解人意”和“博闻强识”的特点而走红,在全世界掀起了一场风暴。“善解人意”意味着LLM有很强的问题理解能力(query understanding),很好地理解用户指令;“博闻强识”展示了LLM对世界知识的记忆和理解,搭配其强大的in context learning的能力,可以很好地理解用户给的背景知识,根据用户问题进行回答。这些特点让大众认识到LLM在ODQA场景的巨大潜力。
不幸的是,强如ChatGPT这样的LLM还是有一些局限性。Chatgpt有时会给用户错误的回答而误导用户,并且Chatpgt也无法告诉用户它对自己的回答有多大把握[14]。另一方面,即使ChatGPT这类LLM参数量很大,但也无法记住海量的世界知识[15],尤其是那些长尾知识。LLM的预训练数据是某一时间之前的,不能很好地“紧跟时代”,存在知识时效性问题[16]。
检索增强生成(Retrieval-Augmented Generation,RAG)[16]利用检索非参数化的知识来提升知识密集型任务的性能,为解决大模型“幻觉”,知识的“时效性”,私域数据等问题提供了很好的方向。
二阶段检索器(Two-stage Retriever)
检索模块对RAG最终问答的正确率和用户体验非常重要,获得一个“善解人意”的高效检索器成为大家重要的研究方向。大家认同一个好的检索器的 评判标准 是:1、尽可能召回用户问题所需的相关文本片段,2、越相关的、对回答问题越有帮助的片段应该在越靠前的位置,过滤低质量片段[17]。
“离线”的Embedding搭配“在线”的Reranker
二阶段检索包含检索和精排两个阶段(如图二所示[12]),因其很好地平衡了检索效果和速度,成为RAG流程中的常用选择。检索阶段常采用基于向量的密集检索方法,对用户问题和知识库语料进行语义向量提取,然后搜索和用户问题语义相近的若干片段。提取语义向量的Embedding模型一般采用dual-encoder的架构,可以预先(offline)对庞大的知识库语料提取语义向量。用户提问时,模型只需实时提取用户问题的语义向量,就可利用向量数据库进行语义检索了。这个过程中,知识库语料的语义向量提取是一个“静态”的、“离线”的过程,模型在提取用户问题和知识库语料的语义向量时,没有信息交互。该方式的好处是效率可以非常高,但这也限制了语义检索性能的上限。精排阶段为了解决信息交互的问题,采用cross-encoder架构,Reranker模型可以实现用户问题和知识库语料有信息交互,可以识别到更加准确的语义关系,算法性能上限非常高。该方式的缺点是,需要对用户问题和知识库语料进行实时(online)语义关系提取,效率比较低,无法对全量的知识库语料进行实时处理。所以结合检索和精排二者的优势,检索阶段可以快速召回用户问题所需的相关文本片段,精排阶段可以将正确相关片段尽可能排在靠前位置,并过滤掉低质量的片段。二阶段检索可以很好的权衡检索效果和效率,具有巨大应用价值。
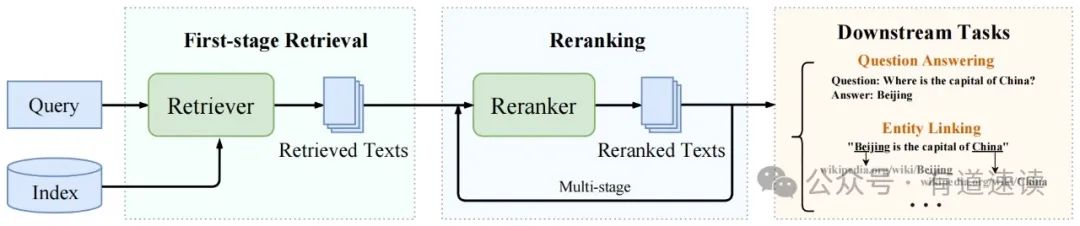
图二、二阶段检索框架
二阶段检索在QAnything中的实践
在QAnything产品实践中发现,当知识库语料增大的过程中,里面会充斥很多干扰的信息,Embedding模型由于其能力有限,通过语义向量检索到的相关片段整体质量变差,导致LLM回答效果变差(如图三中,绿色曲线)。当我们采用二阶段方式时,精排Reranker可以对检索到的相关片段进行进一步重排和过滤,可以显著提升最终检索的质量,可以实现数据越多,问答效果越好(如图三中,紫色曲线)的愿景。
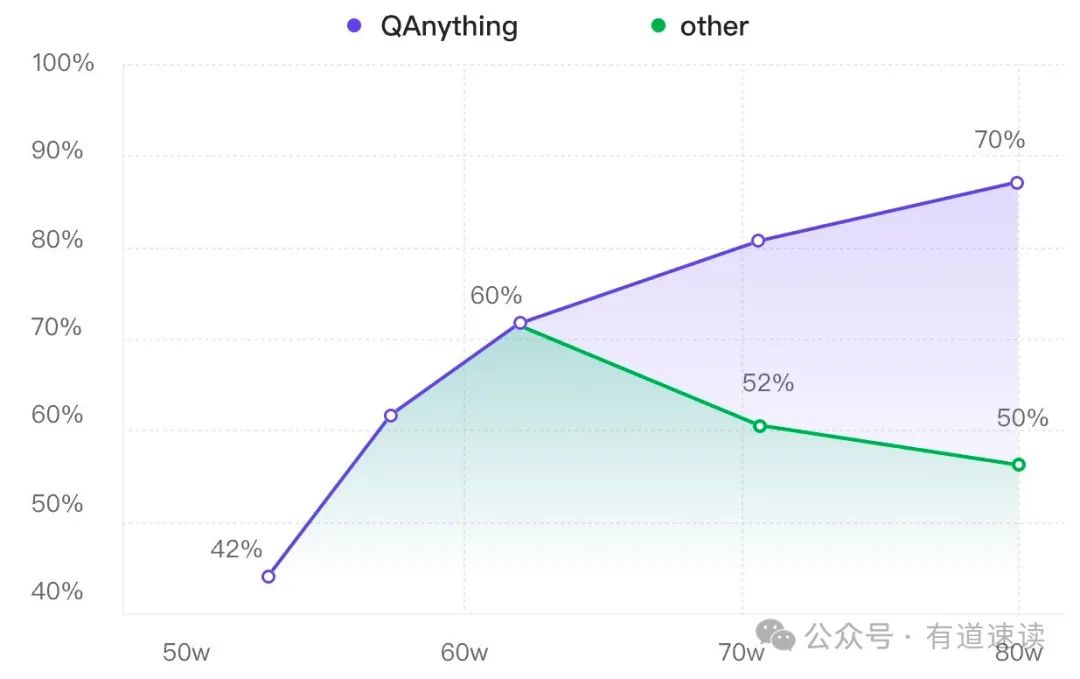
图三、二阶段检索(QAnything)优势
BCEmbedding - 二阶段检索算法模型库
需求分析
首先我们分析RAG场景检索的目标是什么,需要检索的相关文本片段有什么特征。用户的问题一般可以分为翻译、总结、信息查询、问答等几类需求,所以检索器应该具备将不同语种的翻译文本做关联的能力(跨语种检索能力),具备将长原文和短摘要进行关联的能力,具备将不同表述但相同语义的文本做关联的能力,具备将不同问题但相同意图的问题进行关联的能力,具备将问题和可能的答案文本进行关联的能力。此外,为了给问答大模型尽可能高质量的知识片段,检索应该给出尽可能多的相关片段(EmbeddingModel),并且真正有用的片段应该在更靠前的位置(RerankerModel),可以过滤掉低质量文本片段。最后,我们期望我们的算法模型可以覆盖尽可能多的领域和场景,可以实现一个模型打通多个业务场景,让开源社区的用户获得开箱即用的模型,不需要再做微调。
算法设计
功能设计
-
中英双语和跨语种能力
我们收集开源数据集(包括摘要、翻译、语义改写、问答等),来实现模型通用的基础语义表征能力。为了实现一个模型就可以实现中英双语、跨语种的检索任务,我们依赖网易有道多年积累的强大的翻译引擎,对数据进行处理,获得中英双语和跨语种数据集。实现一个模型就可以完成双语和跨语种任务。
-
多领域覆盖
我们分析现有市面上常见或可能的应用场景,收集了包括:教育、医疗、法律、金融、百科、科研论文、客服(faq)、通用QA等场景的语料,使得模型可以覆盖尽可能多的应用场景。同样的依靠网易有道翻译引擎,获得多领域覆盖的中英双语和跨语种数据集。实现一个模型就可以支持多业务场景,用户可以开箱即用。
标签分配(label assign)
我们的BCEmbedding设计为二阶段检索器,“离线”的Embedding负责尽可能召回,“在线”的Reranker负责精排和低质量过滤。原因正如之前分析,Embedding模型是dual-encoder,query和passage在“离线”地语义向量提取时没有信息交互,全靠模型将query和passages“硬”编码到语义空间中,再去语义检索。可想而知,只要训练目标和任务稍微难一点,就会显著影响训练模型的最终性能。Reranker “在线”的cross-encoder可以充分交互query和passage信息,可以被安排来做“精排”这个有难度的工作。
前面我提到想要让模型做多领域覆盖,多语种、跨语种覆盖(还要覆盖代码检索和工具检索),这已经给Embedding增加很多负担了,下一步想想怎么给Embedding“减负”。
标签分配直接决定你训出来模型能做什么样的事,有什么“脾气”和“秉性”。标签分配也直接决定模型训练的难易程度。其实只要你的标签分配和你的业务目标一致就可以,学术研究设定的标签分配和你的业务目标有时候是不一致的。
-
难负样例挖掘?
我们在Embedding模型训练中,不使用难负样例挖掘,只在Reranker中使用。以下是我们的几点看法,仅供参考。
-
我们在训练Embedding模型时发现,过难的负样本对模型训练有损害,训练过程中会使模型“困惑”,影响模型最终性能[19]。Embedding模型算法本身性能上限有限,很多难负样本只有细微差异,“相似”程度很高。就像让一个小学生强行去学习微积分,这种数据对Embedding训练是“有毒”的。
-
在大量的语料库中,没有人工校验的自动化难负样例挖掘,难免会“挖到正例”。语料库很大,里面经常会混有正例,利用已有Embedding模型去挖掘正例,经常会挖到正例,毒害模型训练。应该有不少调参工程师有这种惨痛经历。
-
其实所谓的“正例”和“难负样例”应该是根据你业务的定义来的。RAG场景下,之前人们认为的难负样例可能就成为了正例。比如要回答“小明喜欢吃苹果吗?”,RAG场景下召回“小明喜欢吃苹果”和“小明不喜欢吃苹果”都是符合目标的,而学术定义的语义相似这两句话又是难负样例。
所以回归我们业务目标和好检索器的“评判标准”,Embedding模型应该能尽量召回相关片段,不要将精排Reranker要干的事强压在Embedding身上,“越俎代庖”终究会害了它。
-
抛弃Instruction设定
关于为什么抛弃instruction,下面结合我们实际使用给出我们的看法。INSTRUCTOR[18]将instruction引入到语义向量表征中,对各个任务、各个数据集设计不同的instruction,可以使模型产生类似LLM指令跟随的能力。当遇到新场景、新数据集时,利用instruction可以实现zero-shot的语义表征能力。类似prompt的作用,设计instruction可以对不同的任务、不同的数据集进行子空间划分,缓解不同任务不同数据集之间数据分布和模式的冲突,激发出模型在预先定义的子空间的语义表征能力。从算法角度出发,将LLM的prompt应用在Embedding模型中,缓解不同任务、不同数据模式冲突,利用instructions让模型将文本编码到指定的语义空间,是一个精妙的想法。
不过,对每个任务、每个数据“精心”地设计instruction,人工设计痕迹较重,使用起来不方便通用。而且这种人为划分子空间来训练模型的方式复杂化学习目标,非常考验模型本身的容量(能力),比如INSTRUCTOR[18]在Base模型规模上的增益比Large模型规模的增益小很多。最近开源的Embedding模型将instruction更加简化,只对不同类任务进行instruction设计,或者只对Retrieval任务和非Retrieval任务进行区分。这种简化的方式更像人工设计硬编码一些任务子空间,缓解不同类任务的训练冲突。此时的instruction已经失去了INSTRCTOR的zero-shot的能力,沦为硬编码(instrcution稍微变一下,会有明显性能损失)。
其实更深一步,instruction也可以看成是标签分配的问题,较优的标签分配原则是:1、尽可能相同的数据分布、没有冲突的模式,分成一类,2、类别定义尽量简单,简化学习目标,3、紧跟业务目标(影响评测指标的计算方式)。
首先考虑到模型能力和实际模型推理效率,我们选用Base规模的模型,该规模的模型本身能力不是那么强悍。我们的算法模型定位是多语种、跨语种和尽可能多的专业领域覆盖,该定位本身目标难度就比较大了。如果再通过instrcution划分子空间复杂化学习任务,可能并不是一个好的选择。其次,从实际的使用角度来说,在RAG产品使用过程中,用户的实际问题多种多样,用户问题的意图也是千万变化,算法开发者“绞尽脑汁”地精心设计instrcution对用户来说常常是不易理解的,甚至用户自己都不知道自己的问题属于算法开发者预定义的哪种类型任务、是否需要instrcution、以及用哪种类型的instrcution,使用起来不友好。另一方面,RAG中检索的业务目标是,找出用户问题相关的片段。此时不仅仅要检索该问题的答案相关的片段,也要检索该问题相似问题,因为相似问题的上下文常常含有原问题的答案相关内容,比如客服FAQ场景。所以,我们将RAG需要检索的目标设置为正例(这个目标可能是相似问题,可能是对应答案,可能是短摘要对应的原长文,也可能是相关的推理过程)。
-
最终效果
如表一所示,Embedding检索top 10片段,由Reranker精排,最后取top 5片段算指标。“WithoutReranker”设置下,bce-embedding-base_v1在top 5的片段检索性能虽然不是最好的,因为bce-embedding-base_v1并不善于精排(将groundtruth放在前面top 5)。但是经过Reranker之后的top 5,bce-embedding-base_v1指标是最好的,说明bce-embedding-base_v1在top 10的检索片段,召回的groundtruth比其他Embedding都要多,再利用bce-reranker-base_v1就可以实现最好的性能。
所以正如我们一开始的设计,Embedding负责尽可能召回,不把精排的压力压在Embedding身上,让Reranker这种上限高的角色来做精排这种难任务。bce-embedding-base_v1和bce-reranker-base_v1的组合拳可以实现最好的检索效果。
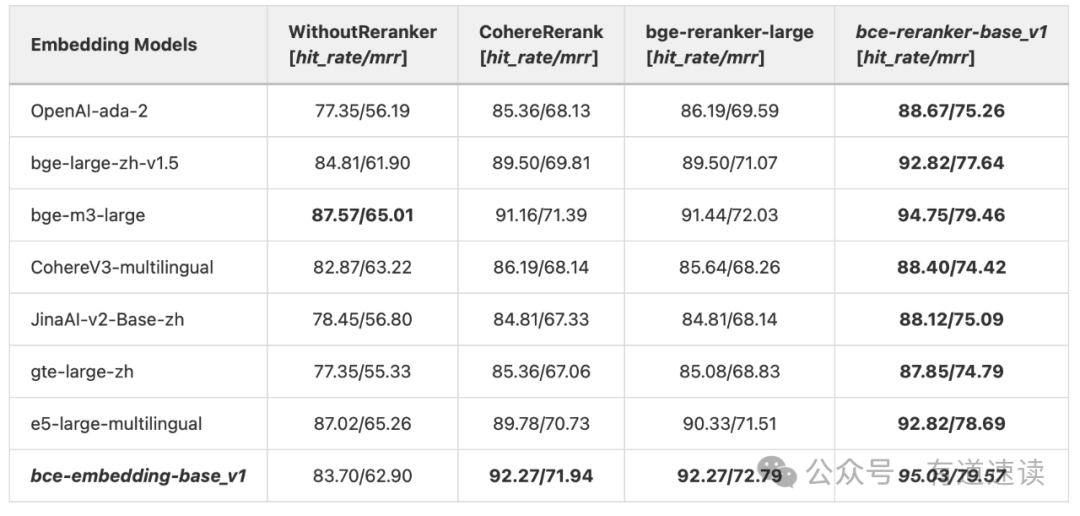
表一、纯中文场景,LlamaIndex RAG评测,`bce-embedding-base_v1`和`bce-reranker-base_v1`的组合拳
有意义的Rerank分数
“评判标准”中好检索器还有一个特点,可以过滤低质量信息。我们设计的Reranker模型,输出的(query, passage)语义相关分数,不仅能用来做psaages排序,其分数的绝对值还有真实的语义相关意义,表征(query, passage)语义相关程度到底有多少,这可以用来判断哪些是低质量passages,就可以实现低质量片段过滤。这对RAG中LLM的回答问题非常有帮助,更干练、干扰信息少的context,可以提高LLM回答质量。
根据我们业务实践经验和开源社区同事的反馈,我们的bce-reranker-base_v1输出的分数可以以0.35~0.4为阈值,来进行低质量passage过滤。用户实际使用反馈,收获很不错的效果。
小结
我们设计了BCEmbedding(Bilingual and Crosslingual Embedding, BCEmbedding)算法模型库,包含EmbeddingModel和RerankerModel两种模型。设计一套RAG适配的标签分配方法,给Embedding减负;EmbeddingModel抛弃Instruction设定,不需要费尽心思设计每个任务设计的instruction,就能实现问题与相似问题检索,问题与候选答案检索,短摘要与长文本检索;设计RerankerModel训练loss,使得模型可以输出有意义的语义相关分数,实现低质量片段过滤,而不是仅仅用于排序。
最终,EmbeddingModel一个模型实现中英双语,以及中英跨语种的检索能力;RerankerModel可以只需一个模型实现中英日韩,以及中英日韩四个语种跨语种语义精排能力;EmbeddingModel和RerankerModel一个模型可以覆盖常见的RAG落地领域,比如:教育、医疗、法律、金融、科研论文、客服(FAQ)、通用QA等场景。
使用指南
我们开源二阶段检索模型EmbeddingModel(bce-embedding-base_v1)和RerankerModel(bce-reranker-base_v1),可免费商用。同时我们提供一个配套的模型使用算法库BCEmbedding:
-
EmbeddingModel和RerankerModel可支持BCEmbedding,transformers,sentence-transformers框架推理模型;
-
提供LangChain和LlamaIndex的集成接口,可方便集成到现有基于LangChain或LlamaIndex的RAG产品中。
-
RerankerModel提供rerank方法,可以支持长passages(token数超过512)的精排。
-
RerankerModel提供rerank方法,可以提供有意义的query和passage的语义相关分数(0~1),可用于在精排,进一步过滤低质量passage,减少无关信息对LLM问答的干扰。
效果评测
语义表征效果
为了检验我们EmbeddingModel在双语和跨语种的能力,我们基于MTEB和C_MTEB评测框架,结合MTEB和CMTEB的公开集,以及我们发布的检验模型跨语种Retrieval能力的跨语种多领域RAG评测集,对包括BCEmbedding在内的现有开源模型进行评测分析。该评测在双语和跨语种设置下进行,也就是['en', 'zh', 'en-zh', 'zh-en'],总共包含MTEB和CMTEB的"Retrieval", "STS", "PairClassification", "Classification", "Reranking"和"Clustering" 六大类任务的114个数据集,119个评测指标(某些数据集包含多个语种)。
所有模型的评测均采用各自推荐的pooling method,其中"jina-embeddings-v2-base-en", "m3e-base", "m3e-large", "e5-large-v2", "multilingual-e5-base", "multilingual-e5-large"和"gte-large"采用mean pooling method,其余模型采用cls pooling method。所有模型均采用各自建议的instruction设置,其中“e5”和“bge”系列模型都需要instruction,其余模型不需要instruction。
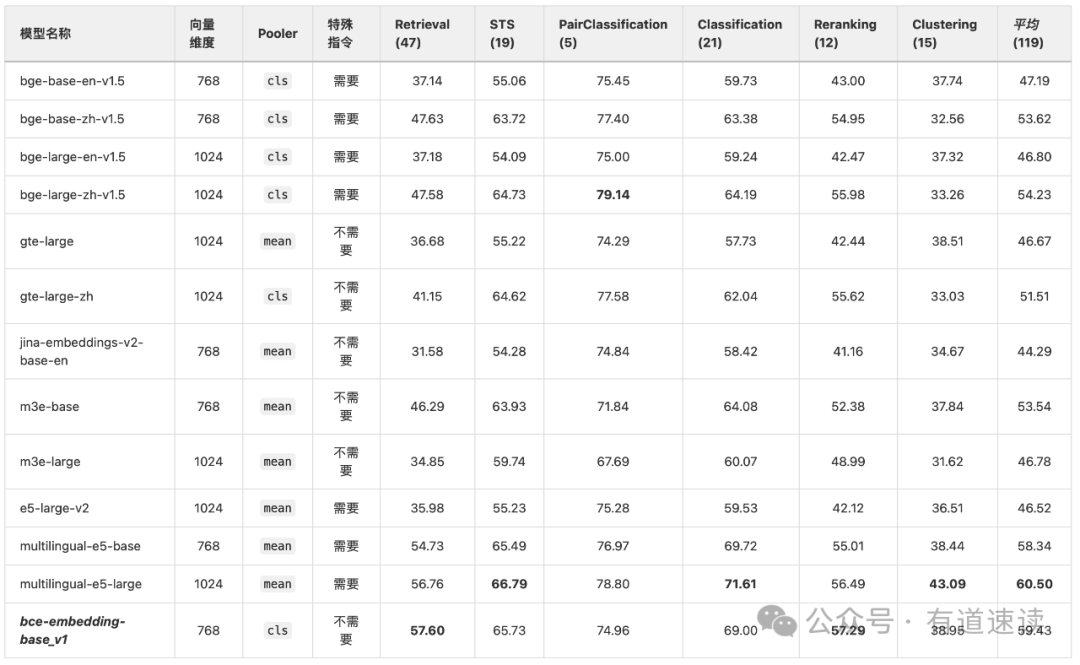
表二、在中英双语和跨语种设置下,各种Embedding模型的语义表征评测结果
分析表二可知,从语种支持的角度来看,在中英双语和跨语种设置下,multilingual-e5-base、multilingual-e5-large和bce-embedding-base_v1这类多语种、双语种模型表现更佳。其中,bce-embedding-base_v1相对multilingual-e5系列模型,在跨语种能力上表现更佳突出,详见en-zh和zh-en跨语种评测结果。从模型规模来看,bce-embedding-base_v1在同等体量的模型中表现最佳,比大部分large版本模型表现更好。从算法设计的角度来看,bce-embedding-base_v1算法设计更宽松,使用起来更方便。向量维度只有768维,对向量数据库存储压力适中;pooler采用最简单、高效的cls方式;也不需要特殊指令,方便集成和使用。综上所述,bce-embedding-base_v1可以一个模型实现很好的中英双语和跨语种能力,而且设置简单,使用很方便。
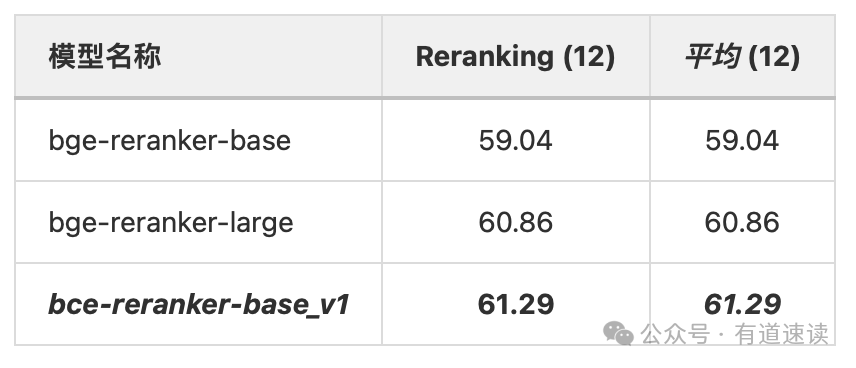
表三、Reranker模型语义精排评测结果
同样地,为检验我们的RerankerModel(bce-reranker-base_v1)的语义精排能力,我们基于MTEB和CMTEB公开评测集,在双语和跨语种设置下(['en', 'zh', 'en-zh', 'zh-en']),利用MTEB和CMTEB的"Reranking"任务的12个数据集进行评测。由表三可知,我们的bce-reranker-base_v1表现出更好的语义精排能力。
LlamaIndex评测RAG效果
LlamaIndex是一个著名的大模型应用的开源框架,在RAG社区中很受欢迎。最近,LlamaIndex博客对市面上常用的embedding和reranker模型进行RAG流程的评测,吸引广泛关注。
为了公平起见,我们复刻LlamaIndex博客评测流程,将bce-embedding-base_v1和bce-reranker-base_v1与其他Embedding和Reranker模型进行对比分析。在此,我们先明确一些情况,LlamaIndex博客的评测只使用了llama v2这一篇英文论文来进行评测的,所以该评测是在纯英文、限定语种(英文)、限定领域(人工智能)场景下进行的。
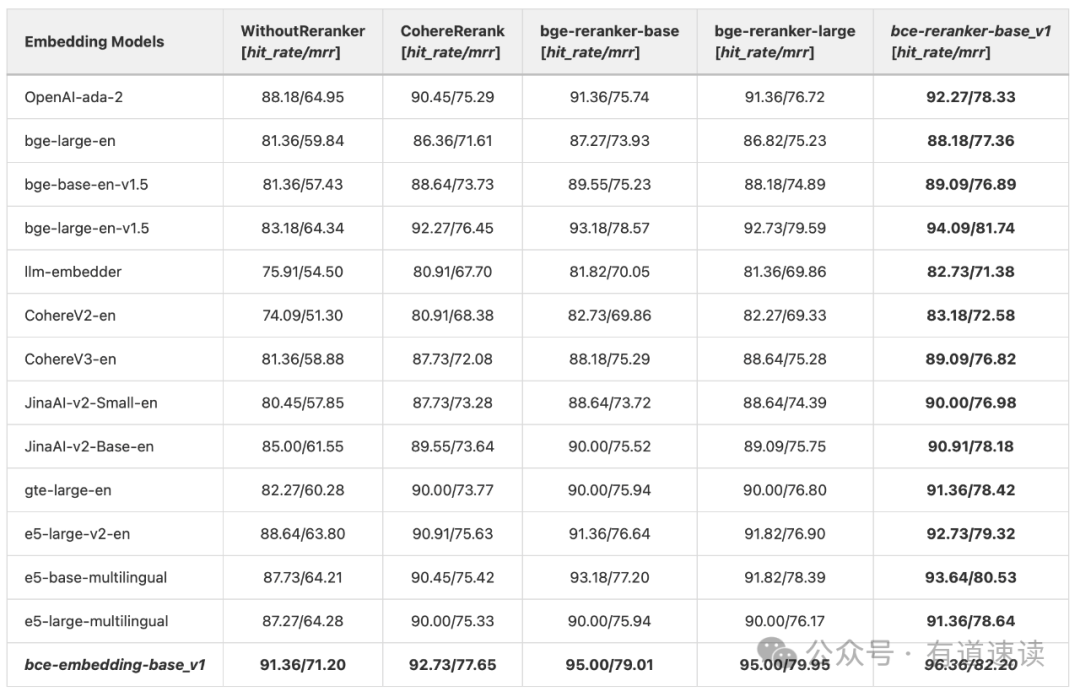
表四、LlamaIndex博客评测复刻,对比
如上表四所示,在没有Reranker模块的设置下,bce-embedding-base_v1显著优于其他常见的开源和闭源英文embedding模型。同样地,在相同reranker模型配置下(竖排对比),bce-embedding-base_v1也都是优于其他开源、闭源embedding模型。在相同的embedding配置下(横排对比),利用reranker模型可以显著提升检索效果,验证前面所述二阶段检索的优势。在此之中,bce-reranker-base_v1比其他常见的开源、闭源reranker模型具备更好的精排能力。综上,bce-embedding-base_v1和bce-reranker-base_v1的组合可以实现最好的效果。
多领域、多语种和跨语种RAG效果
正如上所述的LlamaIndex博客评测有些局限,为了兼容更真实更广的用户使用场景,评测算法模型的 领域泛化性,双语和跨语种能力,我们按照该博客的方法构建了一个多领域(计算机科学,物理学,生物学,经济学,数学,量化金融等领域)的中英双语种和中英跨语种评测数据,CrosslingualMultiDomainsDataset。
为了使我们这个数据集质量尽可能高,我们采用OpenAI的 gpt-4-1106-preview用于数据生成。为了方式数据泄漏,评测英文数据选择ArXiv上2023年12月30日最新的各领域英文文章;中文数据选择Semantic Scholar相应领域高质量的尽可能新的中文文章。
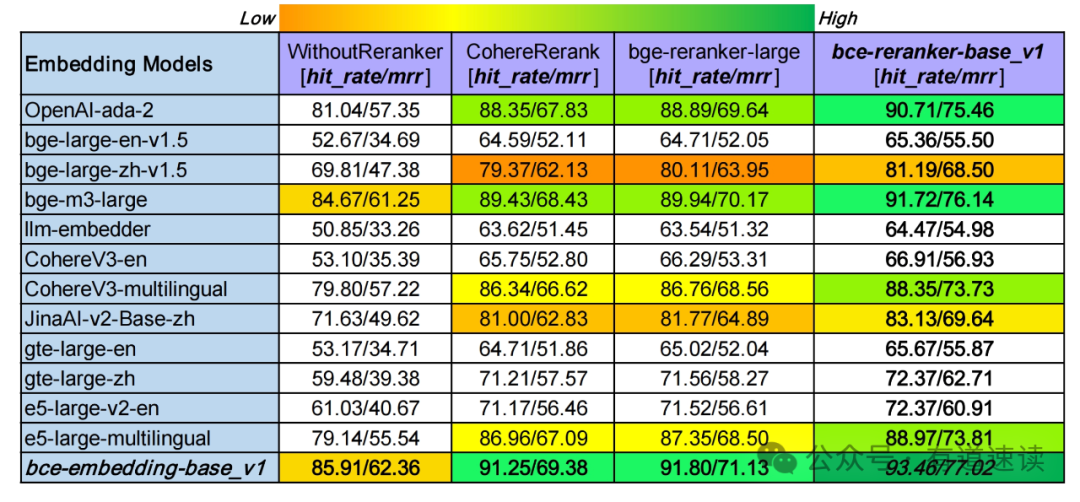
图四、多领域、多语种和跨语种RAG评测
我们针对市面上最强的常用开源、闭源embedding和reranker模型,进行系统性评测分析(如图四)。竖排对比,bce-embedding-base_v1的表现和之前一样,具备很好的效果,语种支持和领域覆盖都很不错。openai-ada-2和最新的bge-m3表现出顽强的性能,具备较好的多语种和跨语种能力,具备较好的领域泛化性。Cohere和e5的多语种embedding模型同样表现出不错的效果。而其他单语种embedding模型表现却不尽如人意(JinaAI-v2-Base-zh和bge-large-zh-v1.5稍好一些)。横排对比,reranker模块可以显著改善检索效果。其中CohereRerank和bge-reranker-large效果相当,bce-reranker-base_v1具备比前二者更好的精排能力。综上,bce-embedding-base_v1和bce-reranker-base_v1的组合可以实现最好的检索效果(93.46/77.02),比其他开源闭源最好组合(bge-m3-large+bge-reranker-large, 89.94/70.17),hit rate提升3.53%,mrr提升6.85%。
总结和展望
我们开源的BCEmbedding的两个检索模型bce-embedding-base_v1和bce-reranker-base_v1,最终目的是给RAG社区提供一套强有力的检索基础算法模型,可以拿来直接用,最好不需要finetune。bce-embedding-base_v1和bce-reranker-base_v1组合的二阶段检索器可以实现一个模型覆盖中英双语、跨语种场景,一个模型可以覆盖众多RAG常见的落地应用场景,并具备优异的性能。
未来针对RAG更多的应用场景,BCEmbedding会进行以下几个方向的关注和尝试:更多常用语种的支持,比如EmbeddingModel后续会支持中英日韩及其跨语种能力;支持更多场景的检索需求,比如代码检索和工具检索,适配更广阔的RAG应用场景;更好的用户意图理解,利用语义向量尽可能关联到到用户意图目标的片段。
期待社区的建议和意见,让我们为推动RAG更好地落地应用,一起努力,添砖加瓦!
联系我们:
BCEmbedding更多详细信息,详见Github (https://github.com/netease-youdao/BCEmbedding)。
如果本项目对您的工作或者研究有帮助,烦请引用:
@misc{youdao_bcembedding_2023,
title={BCEmbedding: Bilingual and Crosslingual Embedding for RAG}, author={NetEase Youdao, Inc.},
year={2023},
howpublished={\url{https://github.com/netease-youdao/BCEmbedding}}}
如果对BCEmbedding技术感兴趣,欢迎加入技术交流群:

如果想直接体验RAG的效果,可以到:GitHub - netease-youdao/QAnything: Question and Answer based on Anything. 下载有道自研RAG引擎QAnything,搭建私有RAG系统。
参考文献
[1] Zhang Qin, Chen Shangsi, Xu Dongkuan, Cao Qingqing, Chen Xiaojun, Cohn Trevor, Fang Meng. A Survey for Efficient Open Domain Question Answering. arXiv.org, 2022.
[2] Zhu Fengbin, Lei Wenqiang, Wang Chao, Zheng Jianming, Poria Soujanya, Chua Tat-Seng. Retrieving and Reading: A Comprehensive Survey on Open-domain Question Answering. arXiv.org, 2021.
[3] Mao Yuning, He Pengcheng, Liu Xiaodong, Shen Yelong, Gao Jianfeng, Han Jiawei, Chen Weizhu. Generation-Augmented Retrieval for Open-Domain Question Answering. arXiv.org, 2020.
[4] Karpukhin Vladimir, Oğuz Barlas, Min Sewon, Lewis Patrick, Wu Ledell, Edunov Sergey, Chen Danqi Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. arXiv.org, 2020.
[5] Ren Ruiyang, Qu Yingqi, Liu Jing, Zhao Wayne Xin, She Qiaoqiao, Wu Hua, Wang Haifeng, Wen Ji-Rong. RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking. arXiv.org, 2021.
[6] Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. Reading Wikipedia to answer open-domain questions. Association for Computational Linguistics, 2017.
[7] Devlin Jacob, Chang Ming-Wei, Lee Kenton, Toutanova Kristina. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv.org, 2018.
[8] Liu Yinhan, Ott Myle, Goyal Naman, Du Jingfei, Joshi Mandar, Chen Danqi, Levy Omer, Lewis Mike, Zettlemoyer Luke, Stoyanov Veselin. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv.org, 2019.
[9] Raffel Colin, Shazeer Noam, Roberts Adam, Lee Katherine, Narang Sharan, Matena Michael, Zhou Yanqi, Li Wei, Liu Peter J.. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv.org, 2019.
[10] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv.org, 2019.
[11] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, et.al.. Language Models are Few-Shot Learners. arXiv.org, 2020.
[12] Wayne Xin Zhao, Jing Liu, Ruiyang Ren, Ji-Rong Wen. Dense Text Retrieval based on Pretrained Language Models: A Survey. arXiv.org, 2022.
[13] ChatGPT Blog: Introducing ChatGPT
[14] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, et.al.. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. arXiv.org, 2022.
[15] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, Hannaneh Hajishirzi. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. arXiv.org, 2022.
[16] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, et.al..Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv.org, 2020.
[17] Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang. Lost in the Middle: How Language Models Use Long Contexts. arXiv.org, 2023.
[18] Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, Tao Yu. One Embedder, Any Task: Instruction-Finetuned Text Embeddings. arXiv.org, 2022.
[19] CoSENT(一):比Sentence-BERT更有效的句向量方案 - 科学空间|Scientific Spaces