文章目录
- Pandas数据处理技能大全:索引标签修改函数全攻略
- 1. `rename`函数
- 参数说明:
- 代码实例:
- 2. `set_index`函数
- 参数说明:
- 代码实例:
- 3. `reset_index`函数
- 参数说明:
- 代码实例:
- 4. `reindex`函数
- 参数说明:
- 代码实例:
- 5. `map`函数
- 参数说明:
- 代码实例:
- 6. `apply`函数
- 参数说明:
- 代码实例:
- 7. `astype`函数
- 参数说明:
- 代码实例:
- 8. `str`方法
- 参数说明:
- 代码实例:
- 9. 自定义函数
- 代码实例:
- 10. `pd.MultiIndex`多级索引
- 参数说明:
- 代码实例:
- 11. `swaplevel`和`sort_index`函数
- 代码实例:
- 总结
Pandas数据处理技能大全:索引标签修改函数全攻略
Pandas是Python中一种强大的数据分析库,广泛应用于数据处理和清洗。在数据分析过程中,经常需要对DataFrame的索引标签进行修改以满足特定需求。本文将介绍一些常用的Pandas索引标签修改函数,包括参数说明和代码实战。

1. rename函数
rename函数用于修改DataFrame的行或列的标签,可以通过传递字典或函数来实现重命名。
参数说明:
index: 用于指定行索引的映射关系。columns: 用于指定列索引的映射关系。inplace: 如果为True,将在原地修改DataFrame,否则返回一个新的DataFrame。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['one', 'two', 'three'])
# 使用rename函数修改行索引标签
df.rename(index={'one': 'first', 'two': 'second'}, inplace=True)
# 使用rename函数修改列索引标签
df.rename(columns={'A': 'Column_A', 'B': 'Column_B'}, inplace=True)
print(df)
2. set_index函数
set_index函数用于将某一列或多列设置为DataFrame的行索引。
参数说明:
keys: 指定要设置为索引的列名或列名列表。drop: 如果为True,则将原来的列保留在DataFrame中;如果为False,则删除原来的列。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': ['X', 'Y', 'Z']}
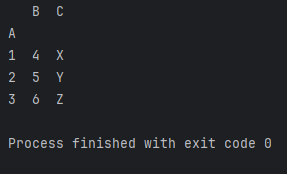
df = pd.DataFrame(data)
# 使用set_index函数将列'A'设置为行索引
df.set_index('A', inplace=True)
print(df)
3. reset_index函数
reset_index函数用于将行索引重置为默认的整数索引,并可以选择是否保留原来的行索引。
参数说明:
level: 如果DataFrame有多级索引,可以指定要重置的级别。drop: 如果为True,则删除原来的行索引;如果为False,则将原来的行索引作为新的一列保留。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
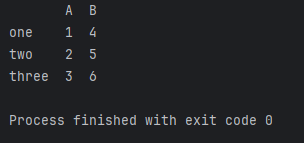
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['one', 'two', 'three'])
# 使用reset_index函数重置行索引
df_reset = df.reset_index()
print(df_reset)
通过掌握这些Pandas索引标签修改函数,你可以更灵活地处理DataFrame,适应不同的数据分析任务。在实际应用中,根据具体情况选择合适的函数,灵活运用这些技巧将提高数据处理的效率和准确性。
4. reindex函数
reindex函数用于重新排列DataFrame的行或列,并可指定缺失值的填充方式。
参数说明:
index: 用于指定新的行索引。columns: 用于指定新的列索引。fill_value: 指定缺失值的填充值。method: 用于插值的方法,例如ffill(向前填充)或bfill(向后填充)。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['one', 'two', 'three'])
# 使用reindex函数重新排列行索引,并向前填充缺失值
new_index = ['three', 'two', 'four']
df_reindexed = df.reindex(new_index, method='ffill')
print(df_reindexed)
5. map函数
map函数用于根据提供的映射关系对DataFrame的元素进行替换。
参数说明:
arg: 用于指定映射关系的字典、Series或函数。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': ['apple', 'banana', 'orange'], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# 使用map函数将'A'列的元素映射为对应的长度
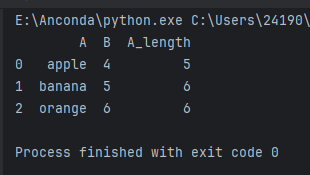
df['A_length'] = df['A'].map(lambda x: len(x))
print(df)
以上是一些常用的Pandas索引标签修改函数,它们能够帮助你更好地处理和定制DataFrame的索引标签,提高数据处理的灵活性和效率。在实际应用中,根据任务的不同需求,选择合适的函数进行操作,深入理解这些函数的用法将使你在数据分析和处理中游刃有余。希望本文能对你在Pandas中处理索引标签的任务中提供帮助。
6. apply函数
apply函数用于在DataFrame的行或列上应用指定的函数,可以实现对索引标签的复杂修改。
参数说明:
func: 要应用的函数,可以是内置函数、自定义函数或匿名函数。axis: 指定应用函数的轴,axis=0表示在列上应用,axis=1表示在行上应用。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['one', 'two', 'three'])
# 使用apply函数将行索引添加前缀
df = df.apply(lambda row: 'Row_' + row.index, axis=1)
print(df)
7. astype函数
astype函数用于更改DataFrame的数据类型,可以用于修改索引标签的类型。
参数说明:
dtype: 指定要转换成的数据类型。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['one', 'two', 'three'])
# 使用astype函数将行索引转换为字符串类型
df.index = df.index.astype(str)
print(df)
通过apply和astype等函数的灵活运用,你可以实现更复杂和个性化的索引标签修改。这些函数的强大功能使得Pandas成为处理各种数据分析任务的理想工具。在实际应用中,结合任务需求选择适当的函数,并深入了解函数的使用方式,将更好地应对复杂的数据处理场景。希望本文能够帮助你更好地掌握Pandas中索引标签的修改技巧。
8. str方法
对于包含字符串的索引标签,str方法提供了一系列字符串处理函数,可用于修改和处理字符串索引。
参数说明:
case: 控制字符串大小写,可选值为lower、upper。- 其他具体方法可根据需要选择,如
str.replace()用于替换字符串。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['one', 'Two', 'Three'])
# 使用str.lower方法将索引标签转换为小写
df.index = df.index.str.lower()
print(df)
9. 自定义函数
根据具体需求,你还可以编写自定义函数来修改索引标签,实现更加灵活的操作。
代码实例:
import pandas as pd
# 创建一个示例DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data, index=['one', 'two', 'three'])
# 自定义函数,将索引标签加上特定前缀
def add_prefix(label):
return 'Prefix_' + label
# 应用自定义函数到行索引
df.index = df.index.map(add_prefix)
print(df)
通过str方法和自定义函数的结合使用,你可以更加灵活地处理字符串索引标签,根据具体需求进行个性化的修改。
在实际应用中,选择适当的函数和方法,根据数据的特点和任务需求,能够更加高效地完成数据处理工作。希望这些代码实例和解析对你在Pandas中处理索引标签时提供了帮助。
10. pd.MultiIndex多级索引
对于多层级索引的情况,pd.MultiIndex提供了强大的功能,可用于修改和操作多层级索引标签。
参数说明:
levels: 多层级的标签值,可以是嵌套的列表。labels: 指定每个层级的标签的位置,可以是嵌套的列表。
代码实例:
import pandas as pd
# 创建一个示例DataFrame with MultiIndex
arrays = [['A', 'A', 'B', 'B'], [1, 2, 1, 2]]
multi_index = pd.MultiIndex.from_arrays(arrays, names=('letters', 'numbers'))
data = {'values': [10, 20, 30, 40]}
df = pd.DataFrame(data, index=multi_index)
print(df)
11. swaplevel和sort_index函数
swaplevel函数用于交换多层级索引的层级顺序,而sort_index函数用于对多层级索引进行排序。
代码实例:
import pandas as pd
# 创建一个示例DataFrame with MultiIndex
arrays = [['A', 'A', 'B', 'B'], [2, 1, 2, 1]]
multi_index = pd.MultiIndex.from_arrays(arrays, names=('letters', 'numbers'))
data = {'values': [10, 20, 30, 40]}
df = pd.DataFrame(data, index=multi_index)
# 使用swaplevel函数交换层级顺序
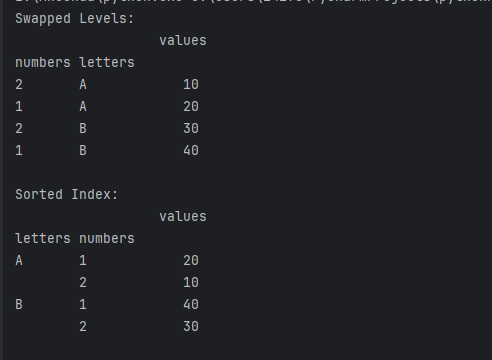
df_swapped = df.swaplevel()
# 使用sort_index函数对索引进行排序
df_sorted = df.sort_index()
print("Swapped Levels:\n", df_swapped)
print("\nSorted Index:\n", df_sorted)
通过pd.MultiIndex和相关的函数,你可以更加灵活地处理多层级索引,实现复杂的数据操作和修改。
以上这些Pandas索引标签修改函数和方法覆盖了不同的场景,能够满足各种数据处理需求。在实际应用中,根据数据的结构和任务的要求,选择合适的函数进行操作,将极大地提高数据处理的效率和灵活性。希望这篇文章对你在Pandas中处理索引标签时提供了全面的指导。
总结
Pandas提供了丰富的索引标签修改函数和方法,使得在数据分析和处理过程中能够更加灵活和高效地操作DataFrame的索引。以下是一些重要的总结点:
-
rename函数:用于修改DataFrame的行或列的标签,支持通过字典或函数进行重命名。 -
set_index函数:将某一列或多列设置为DataFrame的行索引,可选择是否删除原来的列。 -
reset_index函数:将行索引重置为默认的整数索引,可选择是否保留原来的行索引。 -
reindex函数:重新排列DataFrame的行或列,可指定缺失值的填充方式。 -
map函数:根据提供的映射关系对DataFrame的元素进行替换。 -
apply函数:在DataFrame的行或列上应用指定的函数,可实现对索引标签的复杂修改。 -
astype函数:更改DataFrame的数据类型,可用于修改索引标签的类型。 -
str方法:针对包含字符串的索引标签,提供了一系列字符串处理函数。 -
自定义函数:通过编写自定义函数,可以实现更加灵活和个性化的索引标签修改。
-
pd.MultiIndex多级索引:用于处理多层级索引,提供了交换层级、排序等功能。
这些函数和方法的灵活运用,使得Pandas成为处理各种数据分析任务的强大工具。在实际应用中,根据任务的不同需求,选择适当的函数进行操作,能够更加高效地完成数据处理工作。深入理解这些函数的使用方式,将为你在数据分析和处理中提供强大的支持。希望这篇文章对你在Pandas中处理索引标签时有所帮助。