在redis源码之:集群创建与节点通信(1)分析clusterCron定时任务及在redis源码之:集群创建与节点通信(2)分析**clusterReadHandler处理ping请求与pong响应时(clusterProcessPacket)**时,我们跳过了故障处理的部分,现在我们回过头学习这两部分的内容:
一、下线与疑似下线标记
在clusterCron中,会检测cluster->nodes中的每个节点的nodedelay,看是否超过node time out,超过则标记为疑似下线:


同时会把所有的疑似下线节点,通过gossip协议发布出去:
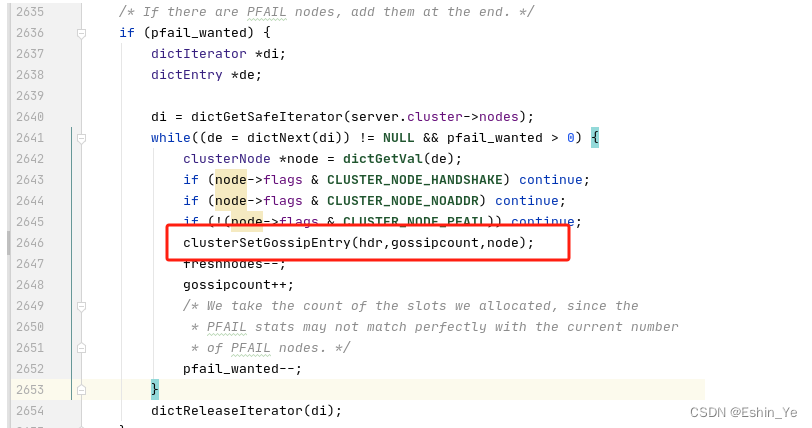
再回到redis源码之:集群创建与节点通信(2)看看在处理gossip节点时,如何标记下线
因此下线是有个先对某个节点记录疑似下线,最后收集其他主节点的下线报告,超过半数认为该节点下线,才真正标记该几点下线。
二、clusterCron定时任务故障处理

clusterCron首先会收集孤立主节点,以备后续的从节点迁移,并且对cluster->nodes中的每个节点检测ping和pong的延迟时间,并在超时情况下会尝试重ping,并对超时的节点,标记疑似下线。最后,当本方节点是个slave时,会检查自身主从复制的偏移量,并通过clusterHandleSlaveFailover处理尝试处理故障转移,竞争成为新的master:


redis cluster中的每个node的主从选举,是个变形的raft,它不是直接在node本身的主从集群里发起选举,而是在cluster集群里,通过cluster中其他的node的主节点对当前node投票,超过半数以上的其他主节点确认,当前节点才能成为本主从集群的主节点。这里区分下主从集群和cluster集群。clusterRequestFailoverAuth()会向集群所有的节点发消息,不管是主节点还是从节点,但只有主节点会回应。
clusterHandleSlaveFailover方法时会多次进入的,而且每个阶段进入执行的部分不一样,需要仔细区分
笔误:在上面的图解中,在设置clusterDoBeforeSleep状态后,写的cron时执行clusterbeforesleep,其实不是在执行main()->aeMain()->aeProcessEvents()->eventLoop->beforesleep()->beforeSleep()->
if (server.cluster_enabled) clusterBeforeSleep();这个流程在后面第五章节还会涉及到。
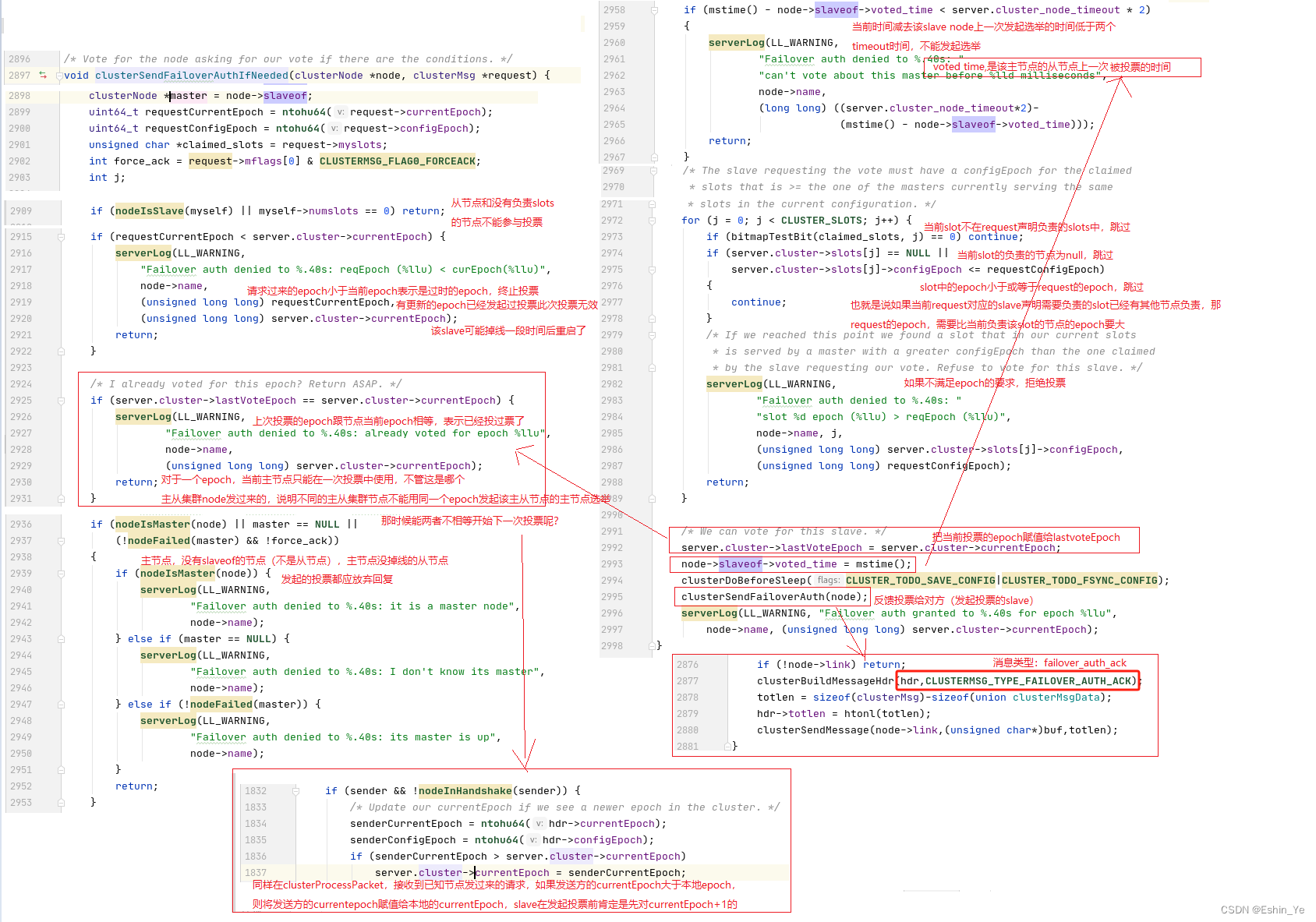
接下来,看看主节点收到投票请求后如何回复投票:
三、主节点投票
其他的主节点收到投票请求后,通过epoll读事件处理,最终进入clusterReadHandler->clusterProcessPacket->clusterSendFailoverAuthIfNeeded(sender,hdr);

四、收集投票处理
再回到发送投票请求的slave节点,看接收到failover_auth_ack响应后如何处理,同样接收响应也是通过epoll读事件处理,进入clusterReadHandler->clusterProcessPacket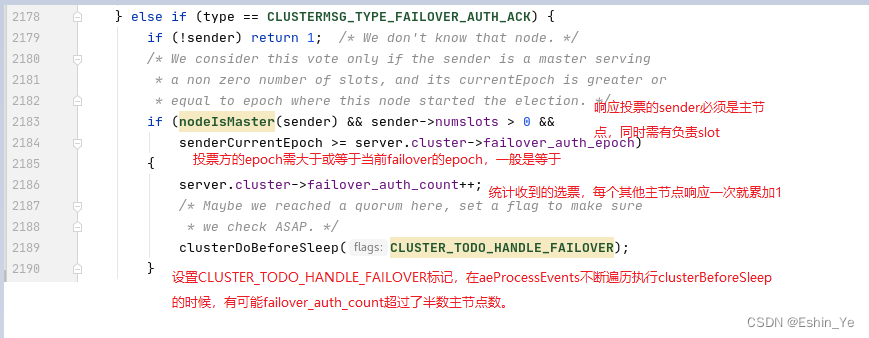
五、执行故障切换
当main()->aeMain()->aeProcessEvents()->eventLoop->beforesleep()->beforeSleep()->`if (server.cluster_enabled) clusterBeforeSleep();不断遍历执行的时候,failover_auth_count也在不断增加,并可能超过半数主节点数:
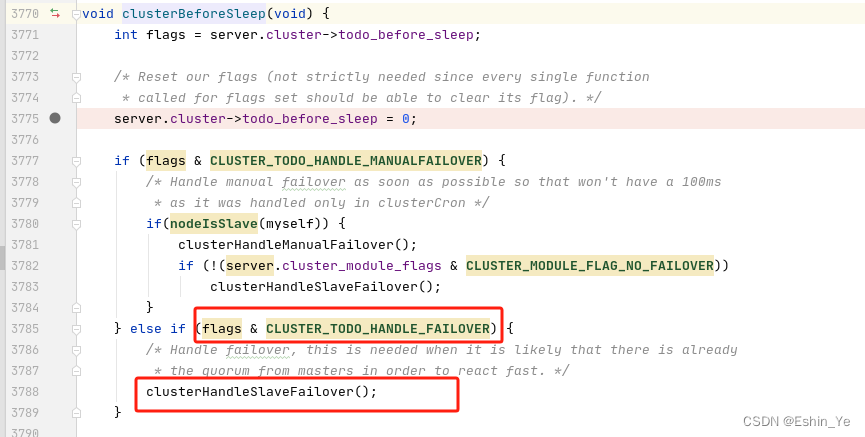
此时再次进入到clusterHandleSlaveFailover():