文章目录
- 什么是NLP自然语言处理
- 发展历程
- 自然语言处理模型
- 模型能识别单词的方法
- 词向量
- 分词
- 一个向量vector表示一个词
- 词向量的表示-one-hot
- 多维词嵌入word embeding
- 词向量的训练方法 CBOW Skip-gram
- 词嵌入的理论依据
- 一个vector(向量)表示短语或者文章
- vector space Model
- bag-of-word
- vector space Model + bag-of-word 实现信息搜索
- 改进版 bag-of-word
本文关注NLP自然语言处理中的基础,词向量
什么是NLP自然语言处理
人工智能的重要突破点之一,就是自然语言处理,应用范围很广,下游任务包括词性分析、情感分析、生成对话等等。

发展历程
自然语言的处理经历了多个阶段,基于概率、统计等等,但是很难满足复杂的语言体系,直到最近基于深度学习模型的出现,才更好的解决了这个问题。
自然语言处理模型
目前流行的模型都是基于transformer架构的大模型,不去了解细节的话,transfomer是编码器加解码器。
简单理解:编码器用来处理输入,解码器用来输出。
现在比较出名的三大模型分支里全部都是由transformer演化出来,基于transformer的编码器BERT家族,基于解码器的GPT一支,还有一支是编码器和解码器都用了,比如google的T5模型,所以很多模型的简写里面都带了T,是因为都是transformer的变体。
所谓的大模型****,大是指参数大,GPT-3就已经是1750亿的水平了,这些参数的训练已经不是普通中小玩家可以训练起来的水平了;
对于自然语言来说肯定是要处理句子和单词的,那么问题就来了,电脑或者说模型知道每个单词的意思么?
模型能识别单词的方法
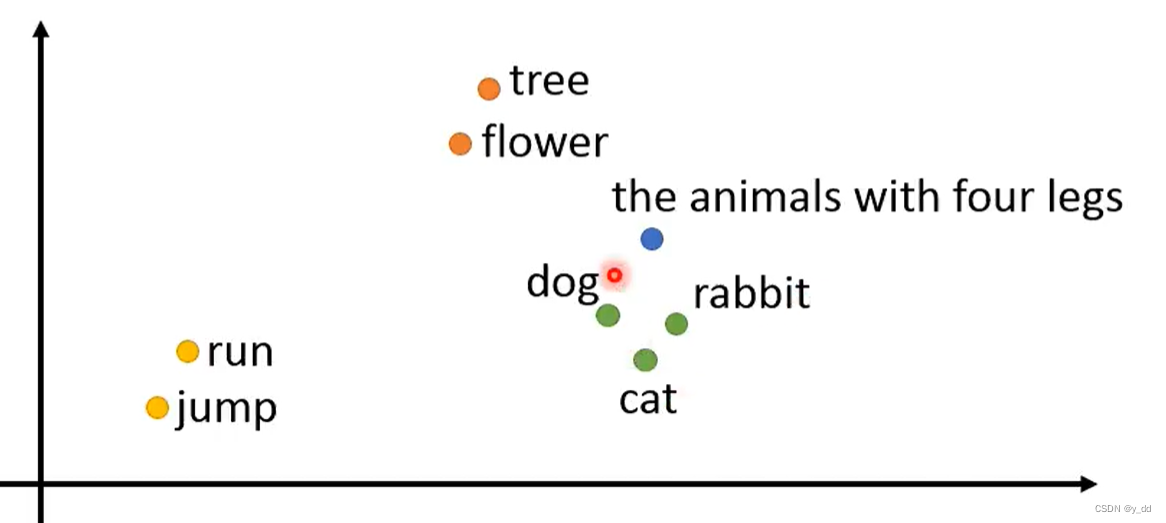
计算知道单词的意思,就是需要知道 tree和flower相近, dog rabbit cat相近,run jump相近这样一种联系,那么模型可以做到么?
答案是虽然不了解每个词的具体含义,但是可以模拟出词之间的关系。
词向量
模型需要输入要么是一个词(字),或者是个短句或者整篇文章。比如翻译任务,模型的输入是一句话,如果文章摘要任务,模型的输入就是一篇文章。
第一种一个vector表示一个词,有两种方法,第一种 one-hot,也叫one-of-n-coding,是一个稀疏矩阵,第二种,叫词嵌入,是一个稠密矩阵。
第二种一个vector表示一个短句或者文章,方法vecbag-of-word。
下面会逐步介绍,无论那种方法,基本都需要先分词。
分词
分词方法很多,有现成的语料库可以实现分词,英文的NTLK,中文的结巴等等。你可能会觉得这个很简单,不就是简单分一下嘛!
实际上不然,分词包含很多细节。举个例子:
比如英文doing,英文的词汇表里只有do,那这种情况,通常又会分为子词,所以NLTK库分词后,经常会被分成do和 ##ing
再比如说输入错误的英文又该怎么处理,通常NLTK库也会留下部分词根,比如输入一个错的词doning,那么通常也会把部分词根分出来。 会分成do 和 ## ning。
所有的语料整理完毕后通常会形成一个语料库,类似于一个词典,保存分词
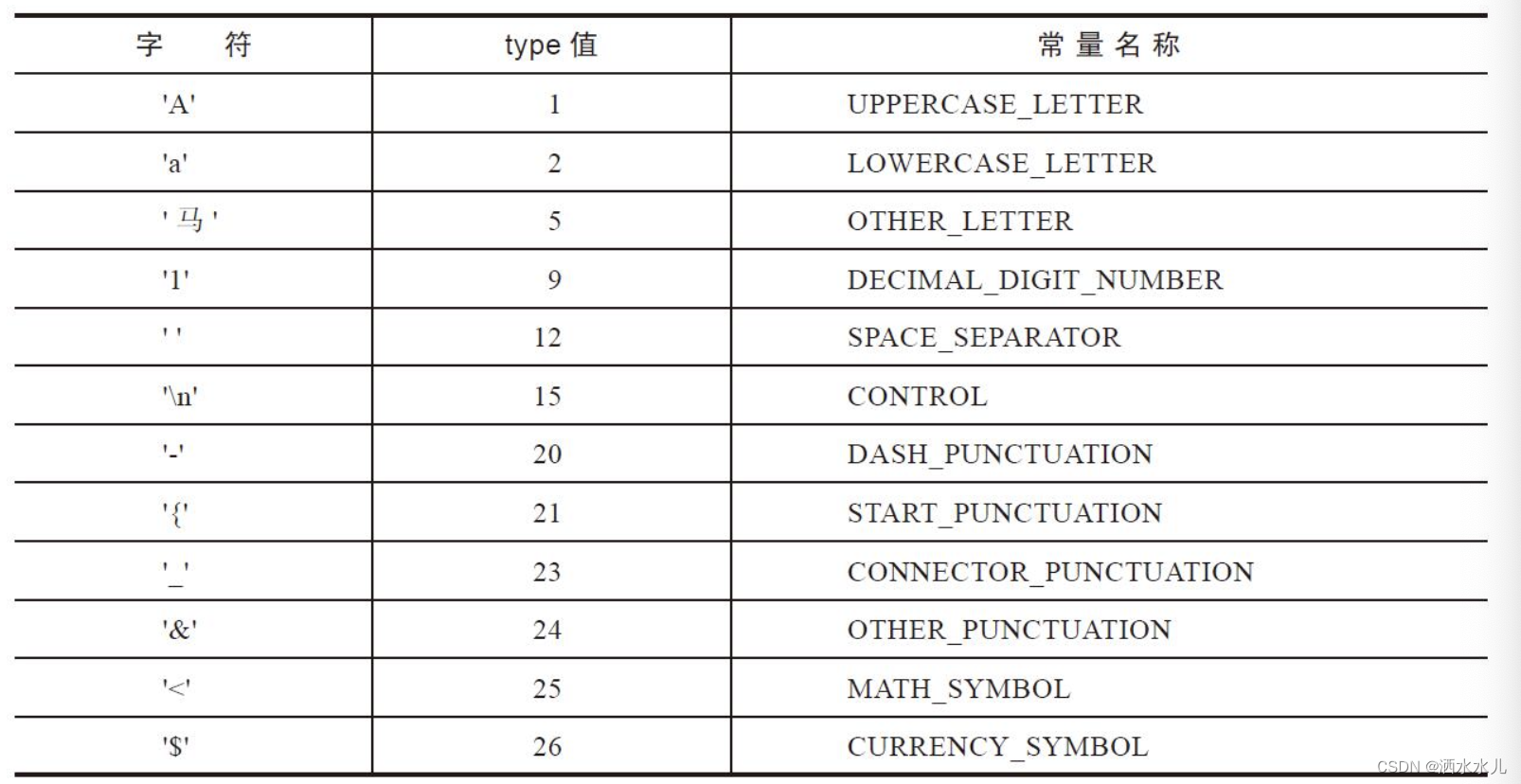
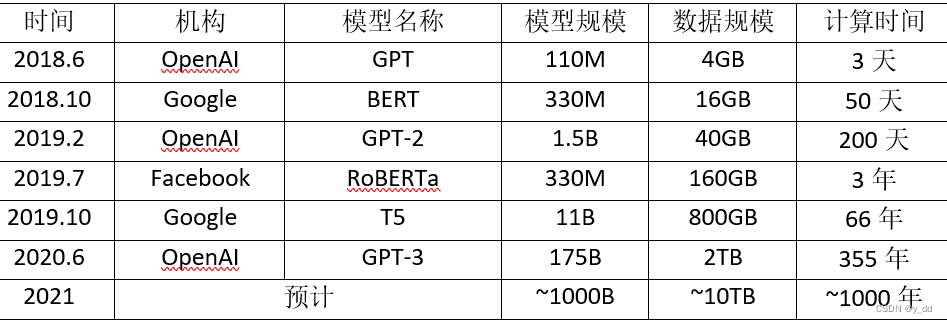
| 序号 | 词汇 |
|---|---|
| 1 | a |
| 2 | do |
| 3 | apple |
| … | … |
但很多语言没办法穷举所有对的词,所以一般词表中还会加一个特殊词"Other" ,来表示一种特殊的,不认识的词汇。
那转换后的分词如何表示呢?分为One -hot 和 多维词嵌入两种办法
一个向量vector表示一个词
词向量的表示-one-hot
比如词汇表有5个词,{apple, dog, do,this,cat}
那么apple的表示就是[1,0,0,0,0]
dog的表示就是[0,1,0,0,0]
do的表示就是[0,0,1,0,0]
this的表示就是[0,0,0,1,0]
cat的表示就是[0,0,0,0,1]
但这种表示方法浪费空间,且无法表示出不同词之间的联系
多维词嵌入word embeding
考虑一个文本预测问题:
比如输入“”这里有一只小" ,让模型预测下文,
模型的输出是每个单词的概率,大小词表的大小,概率最大的那个就是预测的下一个单词。
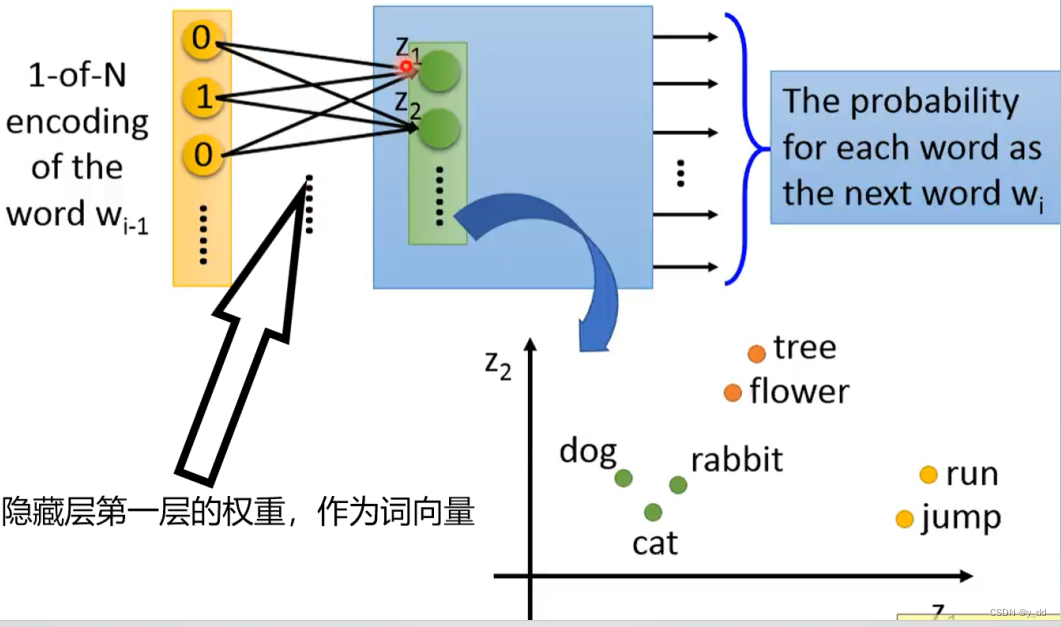
实际上,这这个模型输出不重要,重要的是网络模型中的第一层隐藏层的权重z1,z2,…zn,把这一层的权重z作为要预测词的w的向量,观察向量z,会发现,相近的词距离更近。
比如上面图中,确实表现出了tree和flower等相近的词距离更近,所以 词向量能够表达词之间的逻辑关系
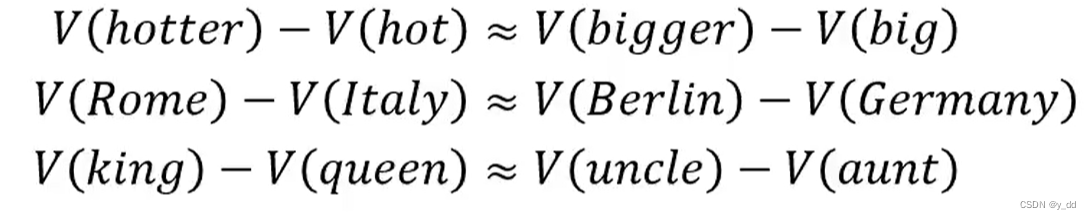
这种逻辑关系有什么用呢? 当你问模型Rome的Italy 就相当于Berlin的? 的时候,电脑真正去做的事情是:

而这个的输出的Germany的概率最大
这种表示方法就是词嵌入,或者叫word vector
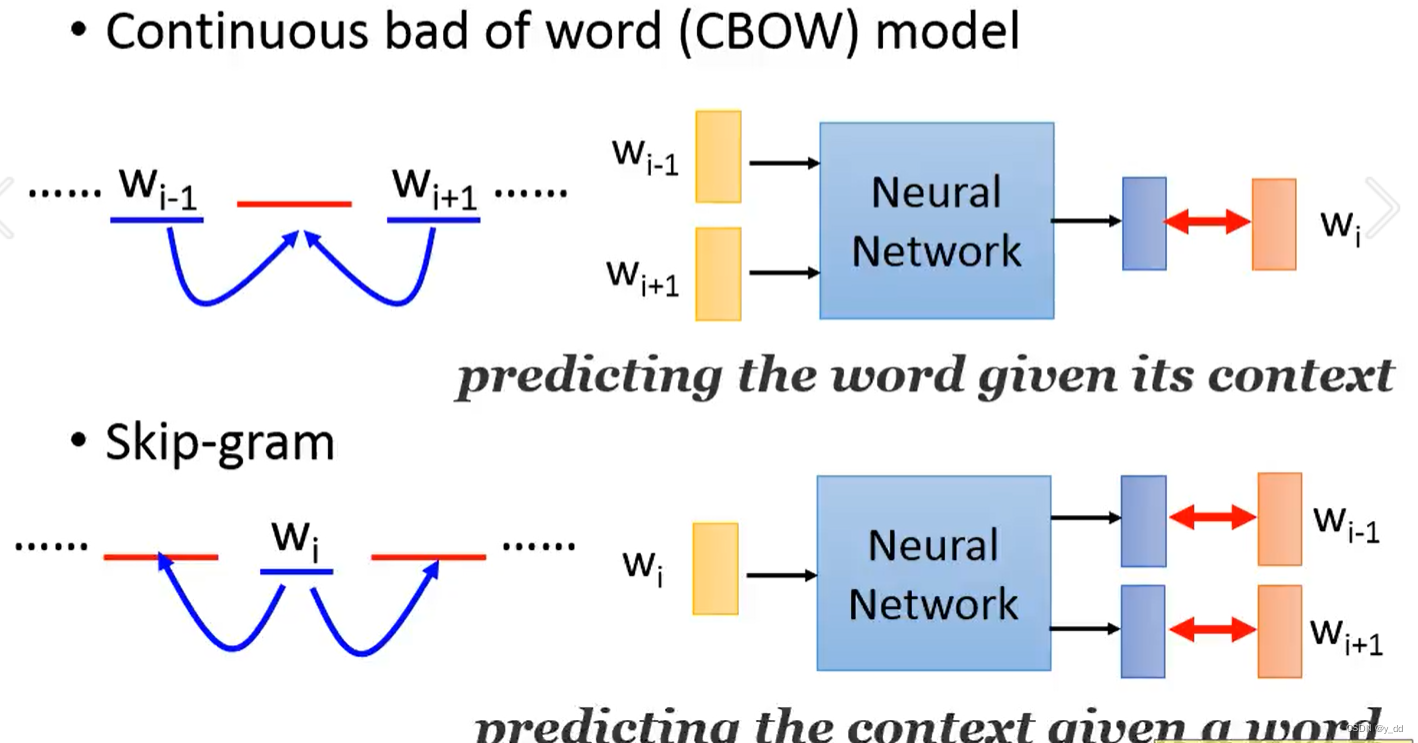
词向量的训练方法 CBOW Skip-gram
当然训练的方法除了下面的预测下一个词,还有SKIP-Gram,Cbow等等,这些不同的方法,区别就是预测的方式不一样:
- CBOW 上下文预测中心词
- Skip-gram,是通过中心词预测两边的词
那么这种表示方法到底是巧合呢还是有理论依据呢
词嵌入的理论依据
一个人人品怎么样,看他周围的朋友,而一个词是什么意思,可以看他经常跟什么词一起出现,当然这个在模型上也是有理论依据的(另外在语言学上也有理论依据)。
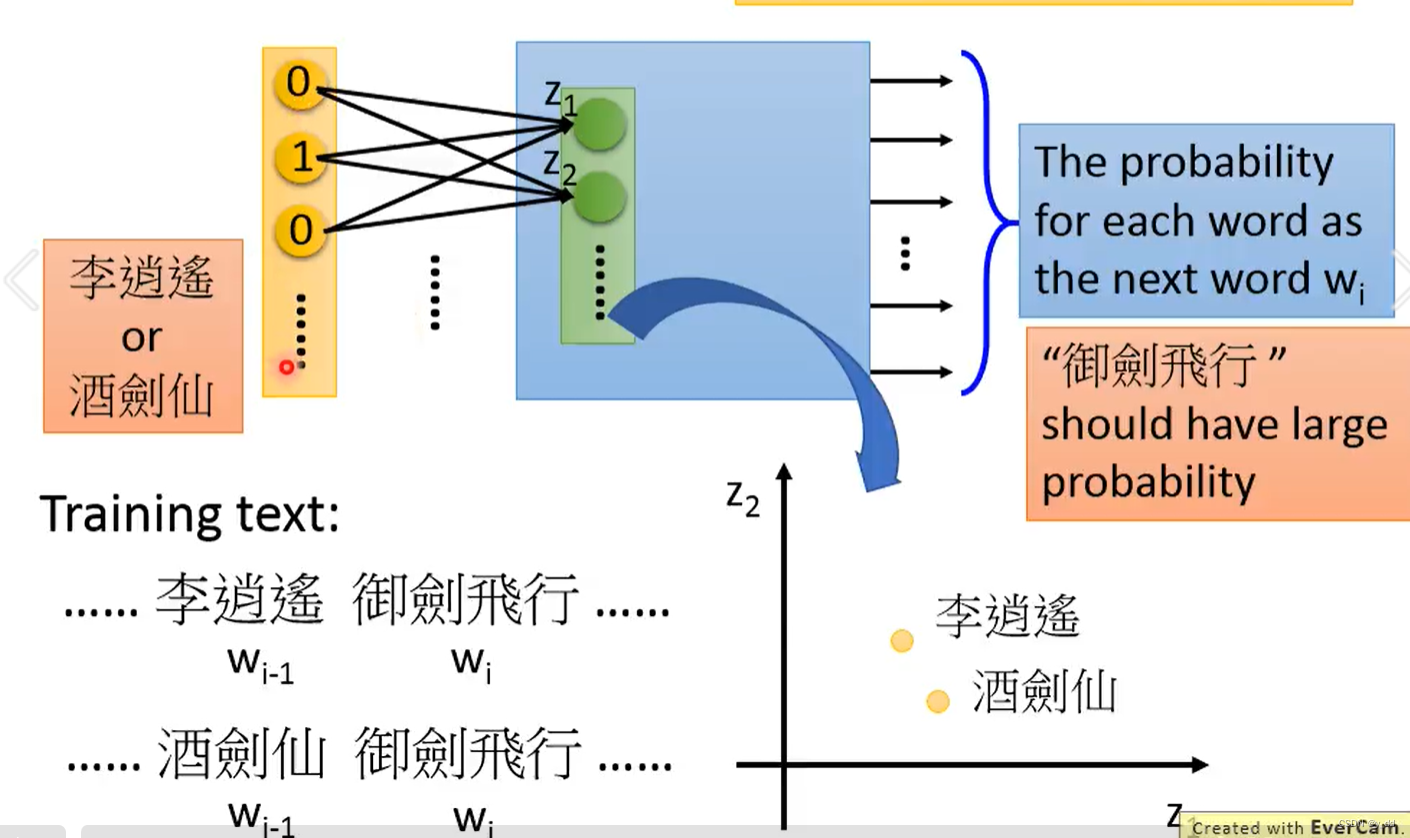
放到深度模型中来看,当我们有两个输入:
李逍遥御剑飞行
酒剑仙御剑飞行
模型起初不知道李逍遥和酒剑仙是同一个东西,但是模型最后的输出都是要输出 御剑飞行的概率最大,因此这两个不同的输入对应的z1,z2,…zn ,就必须是相似的。
经过词嵌入之后的模型不再是一个稀疏矩阵,而是嵌入在多维空间里的一个稠密矩阵:
下面再来说如何用一个vector表示句子或者一篇文章
一个vector(向量)表示短语或者文章
vector space Model
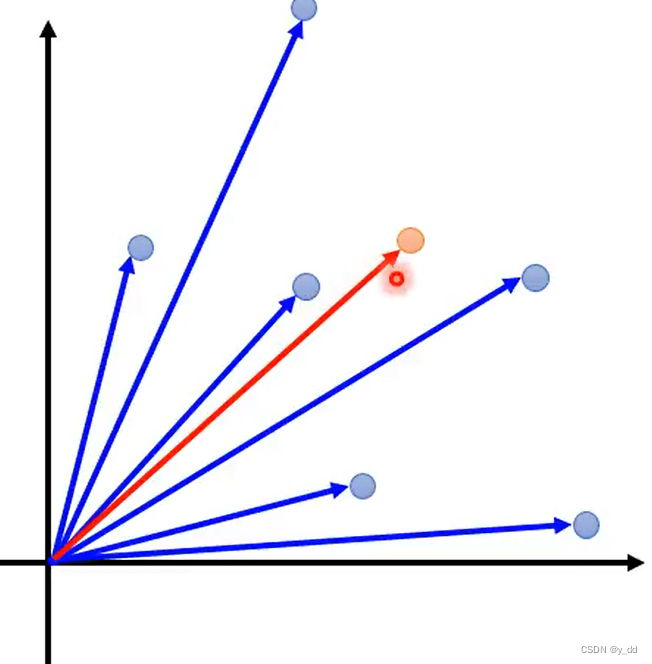
比如一个信息检索的任务,我们通常是把每篇文章变成一堆vector,也就是下图中的蓝色的点,而要检索的信息也是一个vector,当两个向量的夹角比较大的时候,我们认为这两个向量就更相近。
那怎么把文档表示成一个vector呢?
bag-of-word
比如文档中是this is an apple,如果this这个单词在词表中有,我们就将词表中对应位表示为1。

这样的表示方法显然没有考虑文本的顺序,如果两个文档的单词一样,但顺序不一致,其实是完全不同的文档
vector space Model + bag-of-word 实现信息搜索
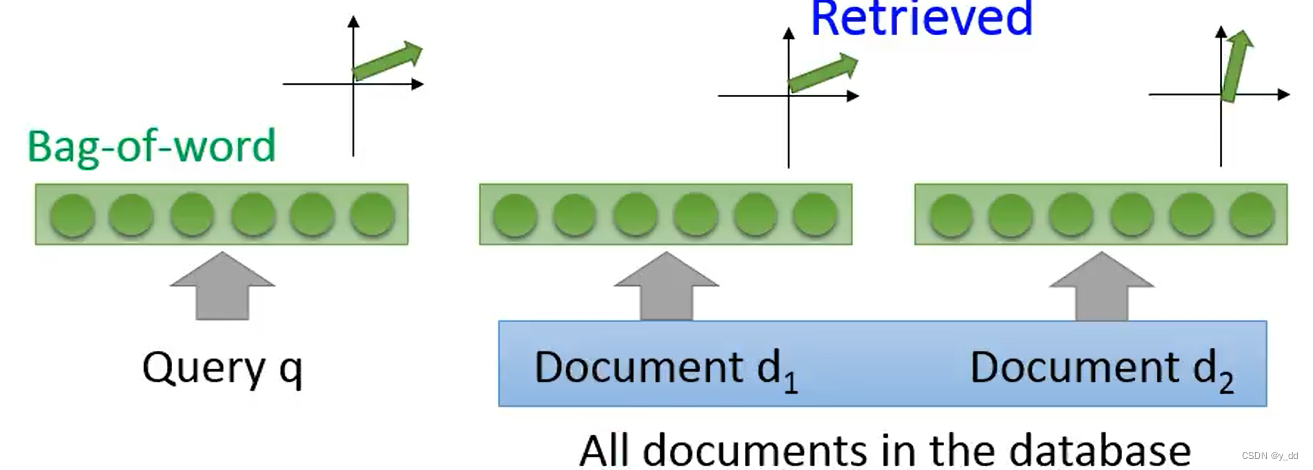
这种表示方法就是将要搜索的信息座位查询q,文档作为被检索的资料,计算两个向量的夹角。
这种检索方法,把词都是看做独立的个体,没有考虑顺序,也没有考虑不同的词其实是表达了同一个意思,又或者不同的词在某种情景下其实是相同的意思。
改进版 bag-of-word
我们在上述基础上,加入神经网络,改进了句子的表示方法。
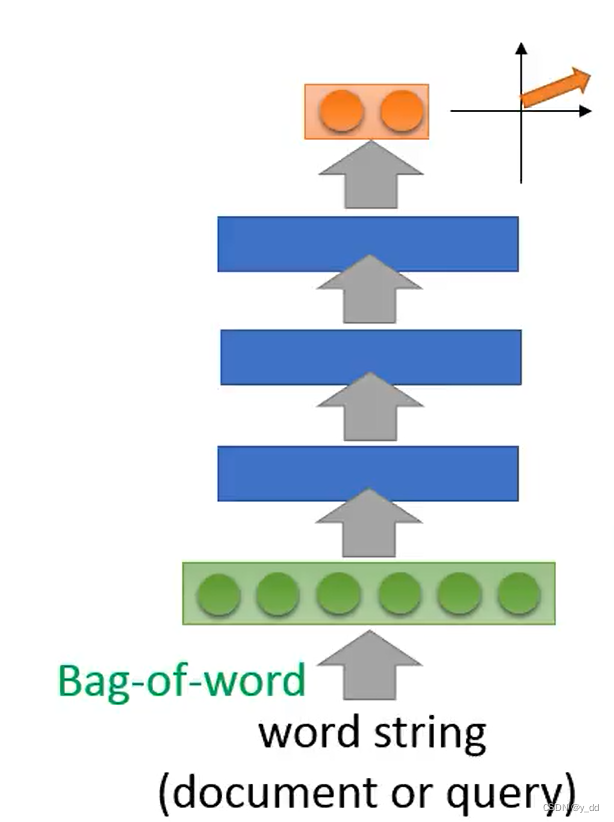
需要查询和检索的句子和文档,都加入神经网络,用神经网络的输出代表这个词向量,可问题是这个神经网络如何训练呢?如何获取这些training data,这些的target又是什么呢?
实际上是有方法获取这些标签数据的,比如百度的时候,我们输入的查询就是query,但是它怎么知道结果是哪个呢?就靠你点击的链接了
总之是有办法获取神经网络的输入和target,从而训练一个网络。
![力扣精选算法100道——和为 K 的子数组[前缀和专题]](https://img-blog.csdnimg.cn/direct/173b9e1be6ed43e9afc25073148b7af1.png)


![【蓝桥杯冲冲冲】[NOIP2017 提高组] 宝藏](https://img-blog.csdnimg.cn/img_convert/0133354571d6164ee90cda7abb9e9549.png)