简介
在本文中,我们将简单介绍什么是No-SQL数据库。然后我们会讨论一种使用关系数据库比较容易实现的查询,即连接查询,怎么样使用No-SQL来实现。
什么是No-SQL数据库
与No-SQL数据库相对应的是传统的关系数据库(RDBMS)。我们还要从RDBMS开始介绍。RDBMS是传统的数据管理方法。数据存储在包含列和行的表中。每列代表了一个属性,每行代表数据的一个实例。每个表都要指定一个主键,即唯一标识表的标识符列。使用主键在表之间建立关系。可以使用它作为表的外键,在两个表的行之间建立关联。
No-SQL数据库的名称来自于not only SQL。基本包含了RDBMS之外的其它类型的数据库。可以参看这篇文档了解No-SQL数据库的具体介绍。No-SQL数据库包含如下几种类型:
- Key-value数据库
- Document数据库
- Graph数据库
- In-memory数据库
- Search数据库
具体的每种No-SQL数据库的介绍可以参看文档的介绍。有必要说明,key-value数据库是使用最多的No-SQL数据库。所以我们一般说No-SQL数据库如果没有特别说明指的是key-value数据库。
Key-value数据库
Key-value数据库按照key-value pair的形式存储数据。也就是说如果我们想要访问一条数据,我们必须先知道它的key。比如我们有如下的key-value:
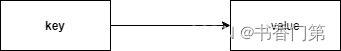
我们可以使用如下的API通过key获取value:
Value = load(key)
与RDBMS比较起来,key-value数据库有如下的有点:
- No-SQL数据库的schema定义和修改非常灵活。因为保存和读取数据只要依赖key,对于value的定义可以非常灵活;
- No-SQL数据库可以支持低latency的操作。因为和RDBMS比较起来,key-value的保存和读取非常简单,因此通常可以做到latency很低;
- No-SQL数据库可以很好的支持数据库的SCALE。因为key-value的存储形式,可以很容易应用partition来根据需求scale out和scale in数据库。
正式因为以上有点,key-value数据库在现在的service中使用的越来越多。
问题
现在我们来考虑这样一个问题:我们有点到点的航班数据,也就是说某一次航班从一个城市在几点起飞到另一个城市。如果我们有了起飞城市和目标城市,想查询一个航班,无论使用RDBMS还是key-value都很容易实现。这里我们不做过多讨论。我们想解决的问题是如果没有直飞的航班,我们如何查询需要一次转机的航班。
使用RDBMS是很容易使用连接查询来解决这个问题的。比如我们定义如下的表 - flight:
| id | source | target | Time |
这里ID是主键。
我们可以使用如下的连接查询:
Select flight_1.id, flight_2.id
From flight as flight_1, flight as flight_2
where flight_1.target = flight_2.source
and flight_1.time < flight_2.time
and flight_1.source = 'source city'
and flight_2.target = 'target city';那么如果我们使用key-value数据库如何解决这个问题呢?
解决方案
这里我们使用AWS的DynamoDB(即DDB)作为key-value数据库。DDB的key可以由两部分组成:partition key和sort key。具体介绍可以参看这个文档。简单来说,partition + sort是完整的key。我们可以使用这个key来找到唯一的记录。同时我们还可以使用partition来查询所有拥有相同partition key的所有记录。举例来说,如果我有如下两条记录:
Partition1, sort1, value1
Partition1, sort2, value2如果我使用如下API:
Load(partition1, sort1)我将得到并且只得到第一条记录。
如果我使用如下API:
Query(partition1)我同时将得到第一条和第二条记录。
首先我们还是先定义表。但是不同于RDBMS的表结构,我们将定义如下表 – source_flight:
| source | id | target | Time |
Source是partition key,id是sort key。Target和time是value。
我们还定义如下表 – target-flight:
| Target | Id | Source | Time |
Target是partition key,id是sort key。Source和time是value。
为了使这个例子更容易理解,我们定义一些数据如下:
Source-flight:
| Source | Id | Target | Time |
| 北京 | 1 | 上海 | 2024-03-01 |
| 北京 | 2 | 重庆 | 2024-03-02 |
| 上海 | 3 | 香港 | 2024-03-02 |
| 大连 | 4 | 香港 | 2024-03-03 |
Target-flight:
| Target | Id | Source | Time |
| 香港 | 3 | 上海 | 2024-03-02 |
| 香港 | 4 | 大连 | 2024-03-03 |
| 重庆 | 2 | 北京 | 2024-03-02 |
| 上海 | 1 | 北京 | 2024-03-01 |
现在我们要寻找从北京经过一次转机飞到香港的飞机。首先我们使用“北京”用query操作从source-flight表里得到从北京起飞的所有飞机 – 数据集1
ID:1, 2
其次我们使用“香港”用query操作从target-flight表里得到飞到香港的所有飞机 – 数据集2
ID:3, 4
如果我们使用集合里的“交”操作,得到数据集1里的“target”和数据集2里的“source”的交集。然后我们比较time来filter掉数据集2的time在数据集1的time之前的记录。
结论和扩展
我们可以看到对于连接查询这样的用例使用key-pair来解决使比较麻烦的。但是我们可以认为即便使看起来更麻烦的key-pair解决方案latency也很有可能低于RDBMS的解决方案。并且考虑到key-pair数据库在scale,performance,flexibility方面的优势,可以解决具体情况综合考虑哪种方案更好。
作为扩展,我们考虑一下如果我们要查询经过两次甚至更多次转机的方案时,使用key-pair数据库又该怎样解决呢?
这里的解决方法仅是我个人目前能想到的。如果大家有更好的解决方案,请大家进行分享。谢谢!