Character类除了封装了一个char外,还封装了Unicode字符级别的各种操作,是Java文本处理的基础。下面结合源码分析Character的贡献。
Unicode
也许你没听过Unicode,但应该见过UTF-8。UTF-8(8-bit Unicode Transformation Format)是一种常用的Unicode字符编码方案之一。它使用变长编码方式,将Unicode码点编码成1至4个字节的序列。UTF-8编码保证了对ASCII字符的向后兼容性,因此在处理纯英文文本时,其存储效率与ASCII编码相同。
而Unicode是一种字符编码标准,它为世界上几乎所有的字符分配了一个唯一的数字标识符。它旨在为文字的表示提供一种统一的方式,使得不同国家和语言的字符都能被正确地编码和解码。
在字符编码中,有两个重要的概念:代码点(code point)和代码单元(code unit)。
代码点是Unicode标准中给每个字符分配的唯一整数值。它对应于一个字符的抽象概念,表示文本中的一个字符。Unicode的代码点范围从U+0000到U+10FFFF。每个代码点都有一个唯一的编号,可以用十六进制形式表示,例如U+0041表示字符'A'。
代码单元是计算机中存储和处理字符时使用的最小单位。在Unicode中,代码单元的大小可以是8位(1个字节)或16位(2个字节)。在Java中,字符是使用Unicode编码表示的。Java的char类型是16位无符号整数(即UTF-16) ,用于表示一个Unicode字符。因此,Java中的字符串实际上是由一系列Unicode字符组成的。
然而,Unicode中的某些字符需要用多个代码单元来表示,这种情况下被称为代理对(surrogate pair)。代理对由一个高位代理项(High Surrogate,范围U+D800至U+DBFF)和一个低位代理项(Low Surrogate,范围U+DC00至U+DFFF)组成,它们一起表示一个字符。通过组合高位和低位代理项可以得到完整的代码点。
比如 ☺️ 的码点U+1F60A可以通过代理对的方式表示:
- 计算出该码点在辅助平面中的偏移量:U+1F60A - U+10000 = 0xF60A
- 将偏移量拆分为高位和低位代理项:
- 高位代理项:0xD83D (U+D800 + 0xF60A >> 10)
- 低位代理项:0xDE0A (U+DC00 + 0xF60A & 0x3FF)
- 使用这两个代理项来构成代理对,从而表示 ☺️。
int codePoint = 0x1F60A;
char[] surrogatePair = Character.toChars(codePoint);
System.out.println("UTF-16 编码: " + new String(surrogatePair));
检查代码点和字符
Character类中有很多相关静态方法,以下是对code point和char的检查
//判断一个int是不是一个有效的代码点,小于等于0x10FFFF的为有效,大于的为无效
public static boolean isValidCodePoint(int codePoint)
//判断一个int是不是BMP字符,小于等于OxFFFF的为BMP字符,大于的不是
public static boolean isBmpCodePoint(int codePoint)
//判断一个int是不是增补字符,0x010000~0X10FFFF为增补字符
public static boolean isSupplementaryCodePoint(int codePoint)
//判断char是否是高代理项,0xD800~0xDBFF为高代理项
public static boolean isHighSurrogate(char ch)
//判断char是否为低代理项,0xDC00~0xDFFF为低代理项
public static boolean isLowSurrogate(char ch)
//判断char是否为代理项,char为低代理项或高代理项,则返回true
public static boolean isSurrogate(char ch)
//判断两个字符high和low是否分别为高代理项和低代理项
public static boolean isSurrogatePair(char high, char low)
//判断一个代码点由几个char组成,增补字符返回2,BMP字符返回1
public static int charCount(int codePoint)
代码点和字符的互转
之前仅针对int和char之间的转换相信大家都很熟悉,就是参照ASCII码
从代码点到字符的转换:
int codePoint = 65; // 代码点(Unicode码点)
char c = (char) codePoint; // 将代码点转换为字符
System.out.println(c); // 输出字符 'A'
从字符到代码点的转换:
char c = 'A'; // 字符
int codePoint = c; // 将字符转换为代码点(Unicode码点)
System.out.println(codePoint); // 输出代码点 65
而有了低代理项和高代理项后,需要用复杂的公式转换。这个公式的基本思想是将高代理项和低代理项分别减去一个偏移量(0xD800和0xDC00),然后将它们组合起来生成代码点。
public static int toCodePoint(char high, char low) {
return ((high - 0xD800) << 10) + (low - 0xDC00) + 0x10000;
}
下面是其他的处理函数
//根据高代理项high和低代理项1ow生成代码点,这个转换有个公式,这个方法封装了这个公式
public static int toCodePoint(char high, char low)
//根据代码点生成char数组,即UTF-16表示,如果code point为BMP字符,则返回的char
//数组长度为1,如果为增补字符,长度为2,char[0]为高代理项,char[1]为低代理项
public static char[] toChars(int codePoint)
//将代码点转换为char数组,与上面方法类似,只是结果存入指定数组dst的指定位置index
public static int toChars(int codePoint, char[] dst, int dstIndex)
//对增补字符code point,生成低代理项
public static char lowSurrogate(int codePoint)
//对增补字符code point,生成高代理项
public static char highSurrogate(int codePoint)Unicode字符属性
Unicode在给每个字符分配一个编号之外,还分配了一些属性Unicode给每个字符分配了一个类型,这个类型是非常重要的,很多其他检查和操作都是基于这个类型的。getType方法的参数可以是int类型的code point,也可以是char类型。char类型只能处理BMP字符,而int类型可以处理所有字符。Character类中很多方法都是既可以接受int类型,也可以接受char类型。
//获取字符类型
public static int getType(int codePoint)
public static int getType(char ch)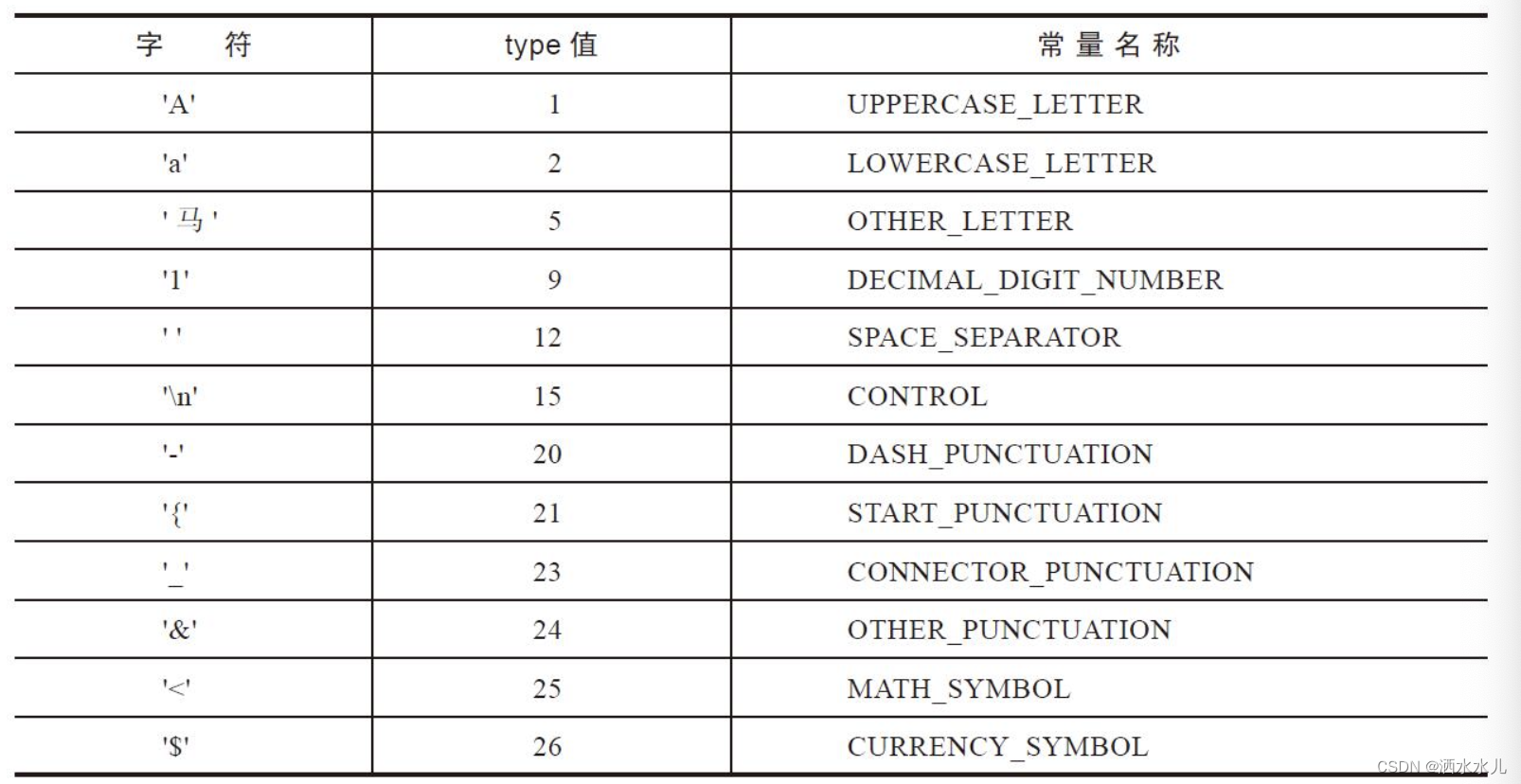
根据这个类型属性,可以获得字符的信息
//检查字符是否在Unicode中被定义:
public static boolean isDefined(int codePoint)
//检查是否为字母:
public static boolean isLetter(int codePoint)
//检查是否为字母或数字:
public static boolean isLetterOrDigit(int codePoint)
//检查是否为字母(Alphabetic):
public static boolean isAlphabetic(int codePoint)
//检查是否为空格字符:
public static boolean isSpaceChar(int codePoint)
//匹配实际产生空格效果的字符,如Tab控制键't'。更常用的检查空格的方法:
public static boolean isWhitespace(int codePoint)
//检查是否为小写字符:
public static boolean isLowerCase(int codePoint)
//检查是否为大写字符:
public static boolean isUpperCase(int codePoint)