概要
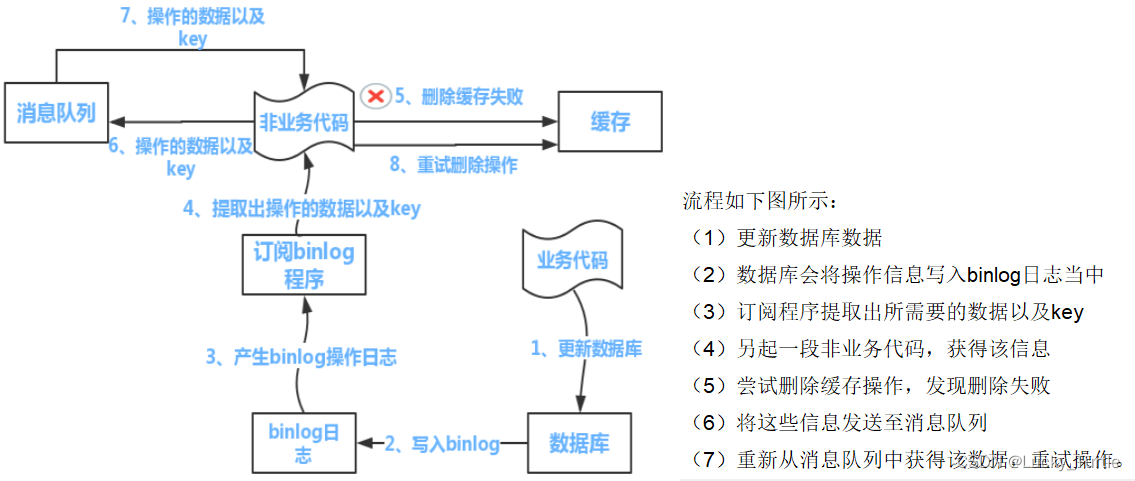
NCNN的CPU初始化速度很快,但是当使用GPU进行推理时,初始化往往要花费几秒甚至更长时间。其他框架例如MNN有载入cache的方式来进行加速,NCNN目前没有相关接口来实现加速,那么NCNN是否也可以加载cache来实现加速呢?
整体流程
通过测速以及查看NCNN的源码可以发现,在gpu.cpp源文件下的VulkanDevice::create_pipeline函数内的vkCreateComputePipelines占了相当长时间,而vkCreateComputePipelines是vulkan的一个函数,该函数可以通过载入pipelineCache来实现加速。本文所做的工作就是通过生成读取这个pipelineCache来进行加速的。
具体实现
NCNN的GPU初始化加速分为写和读两部分。
写:
因为create_pipeline这个函数会被执行多次,例如我这边两个模型需要执行171次,所以保存文件的时候需要一个计数器来对文件分别进行命名,我这边创建了一个GlobalCounter.cpp,这个源文件的内容很简单,新建一个globalCounter 变量。
int globalCounter = 0;gpu.cpp包含这个cpp文件,#include "GlobalCounter.cpp"。
在每次保存的时候globalCounter++进行自增来区分不同的cache文件。
修改原来的vkCreateComputePipelines,改成如下:
VkPipelineCache pipelineCache;
VkPipelineCacheCreateInfo cacheCreateInfo{};
cacheCreateInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_CACHE_CREATE_INFO;
// 创建VkPipelineCache对象
VkResult result = vkCreatePipelineCache(d->device, &cacheCreateInfo, nullptr, &pipelineCache);
VkResult ret = vkCreateComputePipelines(d->device, pipelineCache, 1, &computePipelineCreateInfo, 0, pipeline);
// 将pipelineCache的值保存到本地文件
globalCounter++;
char filename[50];
sprintf(filename, "/sdcard/dcim/tmp/%d.bin", globalCounter);
FILE* fp = nullptr;
VkDeviceSize size;
VkResult res = vkGetPipelineCacheData(d->device, pipelineCache, &size, nullptr);
if (res != VK_SUCCESS) {
NCNN_LOGE("Error getting size of pipeline cache %d\n", res);
}
void* data = malloc(size);
res = vkGetPipelineCacheData(d->device, pipelineCache, &size, data);
if (res != VK_SUCCESS) {
NCNN_LOGE("Error getting data of pipeline cache %d\n", res);
}
fp = fopen(filename, "wb");
if (!fp) {
NCNN_LOGE("Failed to open file for writing.\n");
}
fwrite(data, size, 1, fp);
fclose(fp);
free(data);
改完后重新编译并生成ncnn库,再在设备上运行一次。cache文件就被保存到了指定的地方。
可以按照写的方式,通过一个计数器来分别一次读取二进制文件。为了更快的进行初始化,我的想法是合并这些cache文件,通过创建一个数组,把cache文件的数据全部放到数组里去,在初始化的时候直接读数组的内容,省去了读的这个操作,实测下来相比依次读取二进制文件两个模型总共快了1s。
因此我的实现还多了一步,合并:
if (globalCounter == 0)
{
VkPipelineCache pipelineCache[171];
VkPipelineCache MergeCache;
VkPipelineCacheCreateInfo MergecacheCreateInfo{};
MergecacheCreateInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_CACHE_CREATE_INFO;
VkResult result = vkCreatePipelineCache(d->device, &MergecacheCreateInfo, nullptr, &MergeCache);
for (int i = 0; i < 171; i++)
{
char filename[50];
sprintf(filename, "/sdcard/dcim/tmp/%d.bin", (i + 1));
std::ifstream file(filename, std::ios::binary);
file.seekg(0, std::ios::end);
size_t fileSize = static_cast<size_t>(file.tellg());
file.seekg(0, std::ios::beg);
std::vector<char> cacheData(fileSize);
file.seekg(0);
file.read(cacheData.data(), fileSize);
VkPipelineCacheCreateInfo cacheCreateInfo{};
cacheCreateInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_CACHE_CREATE_INFO;
cacheCreateInfo.initialDataSize = fileSize;
cacheCreateInfo.pInitialData = cacheData.data();
VkResult result = vkCreatePipelineCache(d->device, &cacheCreateInfo, nullptr, &pipelineCache[i]);
}
vkMergePipelineCaches(d->device, MergeCache, 171, pipelineCache);
char filename[50];
sprintf(filename, "/sdcard/dcim/tmp/MergeCache.bin");
FILE* fp = nullptr;
VkDeviceSize size;
VkResult res = vkGetPipelineCacheData(d->device, MergeCache, &size, nullptr);
if (res != VK_SUCCESS) {
NCNN_LOGE("Error getting size of pipeline cache %d\n", res);
}
void* data = malloc(size);
res = vkGetPipelineCacheData(d->device, MergeCache, &size, data);
if (res != VK_SUCCESS) {
NCNN_LOGE("Error getting data of pipeline cache %d\n", res);
}
fp = fopen(filename, "wb");
if (!fp) {
NCNN_LOGE("Failed to open file for writing.\n");
}
fwrite(data, size, 1, fp);
fclose(fp);
free(data);
}
通过第一步写可以得知总共创建了多少cache文件,我这边一共是171个cache文件。随后利用vulkan的vkMergePipelineCaches来合并cache文件,最后将MergeCache保存到本地。因为我还是放在create_pipeline函数下,这个函数是要执行100多次的,而合并文件只需要执行一次,所以我这边通过globalCounter == 0来让它只执行一次合并操作。
合并完后,因为我们要把它放到数组里去,而MergeCache.bin是一个二进制文件,里面的内容如何复制呢?这里推荐使用HxD,它可以读取二进制文件并将其导出为c文件,它会自动把数据全部存到一个数组里去。

读:
重新生成新的ncnn文件,因为原来写的内容在读的时候并不需要。修改MergeCache.c,内容如下:
#include <vulkan/vulkan.h>
VkPipelineCache GlobalPipelineCache = 0;
unsigned char CacheData[759974] = {xxxxxxxxxxxxxxxx}
void CreateGlobalPipelineCache(VkDevice *device)
{
VkPipelineCacheCreateInfo cacheCreateInfo{};
cacheCreateInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_CACHE_CREATE_INFO;
cacheCreateInfo.initialDataSize = sizeof(CacheData);
cacheCreateInfo.pInitialData = CacheData;
VkResult result = vkCreatePipelineCache(*device, &cacheCreateInfo, nullptr, &GlobalPipelineCache);
}创建了一个GlobalPipelineCache 变量,并定义了创建GlobalPipelineCache的函数。CacheData是HxD转换好的数组,因为数据过多,这边用xxxx表示其内容。并将MergeCache.c重命名为PipelineCacheData.cpp。
然后在gpu.cpp下包含这个源文件,#include "PipelineCacheData.cpp"。
CreateGlobalPipelineCache我把它放在了
VulkanDevice::VulkanDevice(int device_index)
: info(get_gpu_info(device_index)), d(new VulkanDevicePrivate(this)) 函数最后,其实只要让CreateGlobalPipelineCache放在create_pipeline实现的前面任一函数内且保证这个函数只执行一次就可以了,我这边选择的是VulkanDevice函数下。
最后修改vkCreateComputePipelines,将原来的
VkResult ret = vkCreateComputePipelines(d->device, 0, 1, &computePipelineCreateInfo, 0, pipeline);改为
VkResult ret = vkCreateComputePipelines(d->device, GlobalPipelineCache, 1, &computePipelineCreateInfo, 0, pipeline);重新编译ncnn库文件,至此NCNN GPU初始化加速——cache实现就全部完成了。
初始化速度对比:
| 方法 | 初始化速度 |
| NCNN | 8s |
| NCNN-cache | 4.6s |
| MNN-cache | 3.1s |
这里的初始化速度包含了项目的整个初始化时间,并不单单只是模型的载入。具体速度的话对于NCNN-cache 库,NCNN初始化时间:创建shader 1.5s,创建pipeline 0.3s ,上传模型2s。剩下的时间花在其他初始化上。