目录
一、快速入门
1.1 准备数据
1.2 创建SpringBoot工程
1.3 使用MP
1.4 获取Mapper进行测试
二、常用设置
2.1 设置表映射规则
2.1.1 单独设置
2.1.2 全局设置
2.2 设置主键生成策略
2.2.1 为什么会有雪花算法?
2.2.2 垂直分表
2.2.3 水平分表
2.2.4 单独设置
2.2.5 全局设置
2.3 设置字段映射关系
2.4 设置字段和列名的驼峰映射
2.5 设置打印日志
目前主要的ORM数据库的持久化框架主要有:MyBatis、Hibernate、Spring Data JPA,由于MyBatis的缺点还是较为明显的,所以国内团队就创建了MP来弥补这一缺陷。
MybatisPlus (简称 MP)是一个 Mybatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
一、快速入门
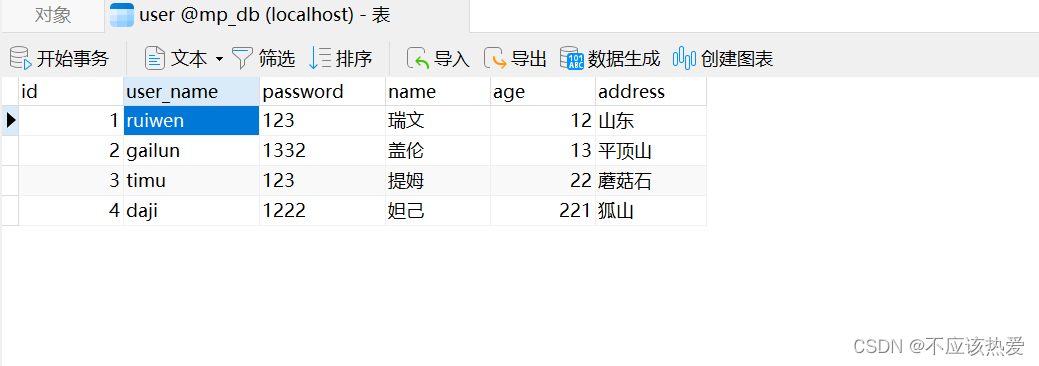
1.1 准备数据
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_name` varchar(20) NOT NULL COMMENT '用户名',
`password` varchar(20) NOT NULL COMMENT '密码',
`name` varchar(30) DEFAULT NULL COMMENT '姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`address` varchar(100) DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
insert into `user`(`id`,`user_name`,`password`,`name`,`age`,`address`) values
(1,'ruiwen','123','瑞文',12,'山东'),(2,'gailun','1332','盖伦',13,'平顶山'),
(3,'timu','123','提姆',22,'蘑菇石'),(4,'daji','1222','妲己',221,'狐山');1.2 创建SpringBoot工程
pom.xml文件的依赖如下:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>观察依赖关系发现,如果添加了MP的依赖,那么就不需要添加Mybatis的依赖,因为MP内置了Mybatis:
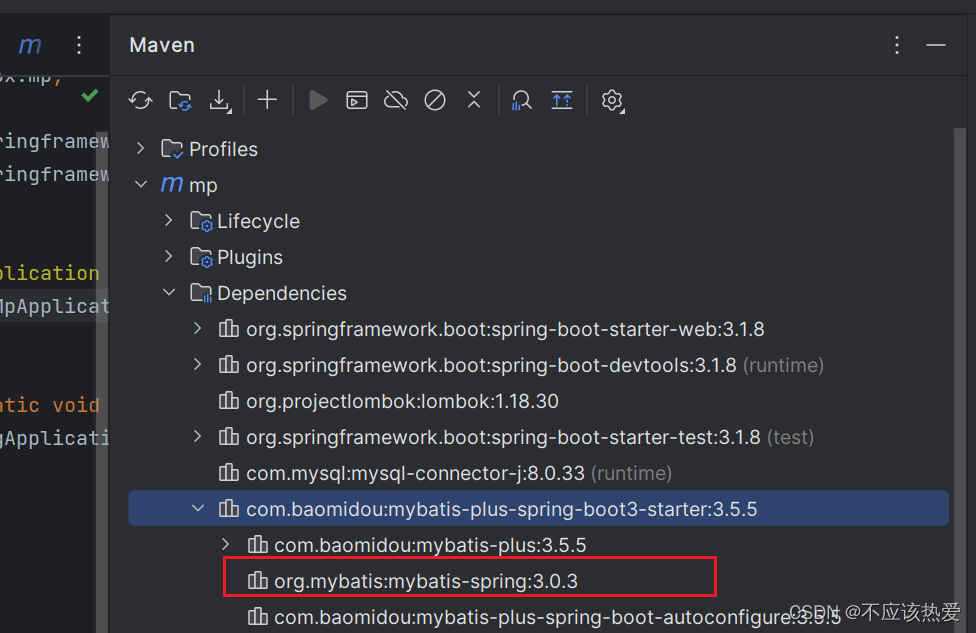
启动类如下:
package com.fox.mp;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MpApplication {
public static void main(String[] args) {
SpringApplication.run(MpApplication.class, args);
}
}
实体类如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private Long id;
private String userName;
private String password;
private String name;
private Integer age;
private String address;
}1.3 使用MP
添加依赖:
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.5</version>
</dependency>配置数据库信息:
spring:
datasource:
url: jdbc:mysql://localhost:3306/mp_db?characterEncoding=utf-8&serverTimezone=UTC
username: "root"
password: "root"
driver-class-name: com.mysql.cj.jdbc.Driver
创建Mapper接口
package com.fox.mp.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.fox.mp.domain.User;
public interface UserMapper extends BaseMapper<User> {
}
配置Mapper扫描
package com.fox.mp;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.fox.mp.mapper")
public class MpApplication {
public static void main(String[] args) {
SpringApplication.run(MpApplication.class, args);
}
}
1.4 获取Mapper进行测试

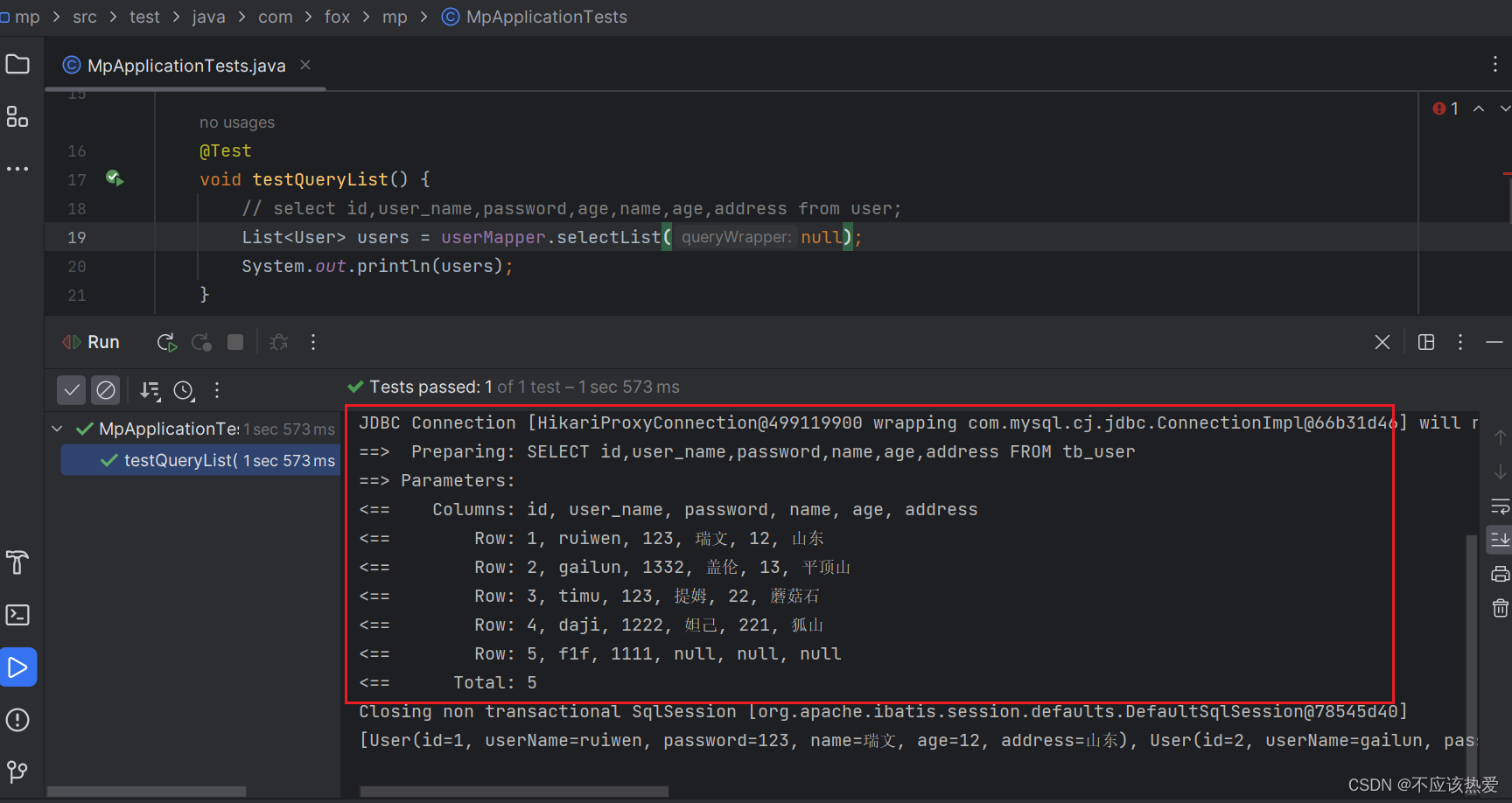
可以观察到,我们在测试方法中正确的查询了User表里面的内容。
二、常用设置
2.1 设置表映射规则
默认情况下,我们最好是让MP操作的表名就是实体类的类名,但是如果表名和类名不一致就需要我们自己设置映射规则,否则则会查询不到:
2.1.1 单独设置
可以在实体类的类名上加上@TableName注解进行标识。 例如: 如果表名是tb_user,而实体类名是User则可以使用以下写法:

2.1.2 全局设置
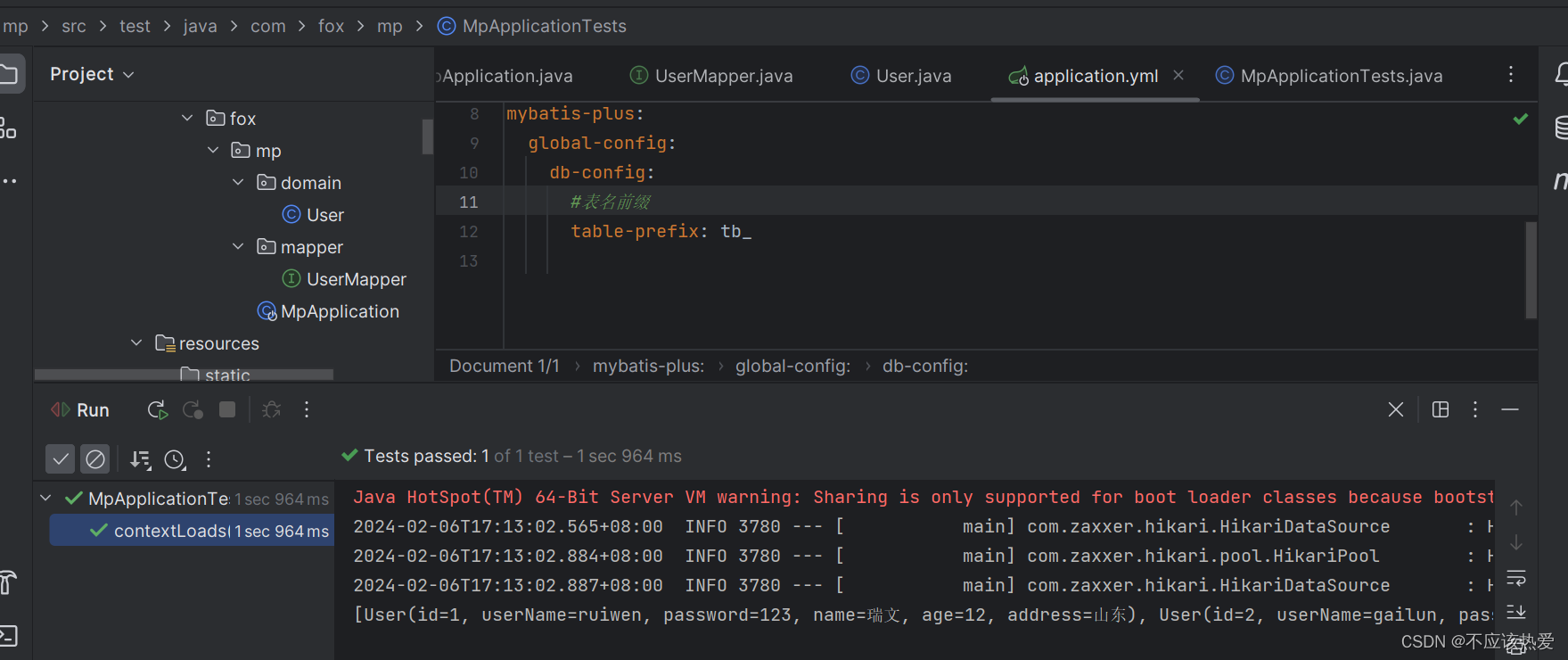
代码如下:
mybatis-plus:
global-config:
db-config:
#表名前缀
table-prefix: tb_2.2 设置主键生成策略
执行以下代码:

查看数据库:

2.2.1 为什么会有雪花算法?
主要是由于数据规模的增长,可能会涉及到水平分表,而水平分表相比于垂直分表,会引入更多的复杂性,例如要求 :全局唯一的数据 ID。
而雪花算法在分布式场景下较为常用,其可以产生全局唯一且趋势递增的ID,以下简答概念了解即可:
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
核心思想:
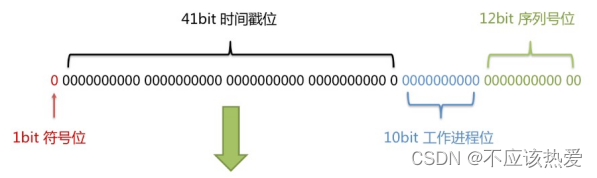
长度共64bit(一个long型)。
首先是一个符号位,1bit标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
41bit时间截(毫秒级),存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年。
10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID,可以部署在1024个节点)。
12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID)
优点:整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高。
顺便简单聊聊数据库分表:
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进行拆分。
单表数据拆分有两种方式:垂直分表和水平分表,示意图如下:

2.2.2 垂直分表
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
例如,前面示意图中的 nickname 和 description 字段,假设我们是一个相亲网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要用于展示,一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
2.2.3 水平分表
水平分表适合表行数特别大的表,有的公司要求单表行数超过 5000 万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过 1000万就要分表了;而对于一些简单的表,即使存储数据超过 1 亿行,也可以不分表。
但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能瓶颈或者隐患。
水平分表相比垂直分表,会引入更多的复杂性,例如要求全局唯一的数据id该如何处理。
主键自增
- 以最常见的用户 ID 为例,可以按照 1000000 的范围大小进行分段,1 ~ 999999 放到表 1中,1000000 ~ 1999999 放到表2中,以此类推。
- 复杂点:分段大小的选取。分段太小会导致切分后子表数量过多,增加维护复杂度;分段太大可能会导致单表依然存在性能问题,一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。
- 优点:可以随着数据的增加平滑地扩充新的表。例如,现在的用户是 100 万,如果增加到 1000 万,只需要增加新的表就可以了,原有的数据不需要动。
- 缺点:分布不均匀。假如按照 1000 万来进行分表,有可能某个分段实际存储的数据量只有 1 条,而另外一个分段实际存储的数据量有 1000 万条。
取模
- 同样以用户 ID 为例,假如我们一开始就规划了 10 个数据库表,可以简单地用 user_id % 10 的值来表示数据所属的数据库表编号,ID 为 985 的用户放到编号为 5 的子表中,ID 为 10086 的用户放到编号为 6 的子表中。
- 复杂点:初始表数量的确定。表数量太多维护比较麻烦,表数量太少又可能导致单表性能存在问题。
- 优点:表分布比较均匀。
- 缺点:扩充新的表很麻烦,所有数据都要重分布。
还有一种方式就是雪花算法了,由于上面介绍了,这里就不再进行赘述。
2.2.4 单独设置
默认情况下使用MP插入数据时,如果在我们没有设置主键生成策略的情况下默认的策略是基于雪花算法 的自增id。 如果我们需要使用别的策略可以在定义实体类时,在代表主键的字段上加上 @TableId 注解,使用其 type 属性指定主键生成策略。
例如: 我们要设置主键自动增长则可以设置如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
@TableId(type = IdType.AUTO)
private Long id;
//.....
}全部主键策略定义在了枚举类 IdType 中, IdType 有如下的取值:
AUTO
数据库ID自增,依赖于数据库。该类型请确保数据库设置了 ID自增 否则无效
NONE
未设置主键类型。若在代码中没有手动设置主键,则会根据主键的全局策略自动生成(默认的主键 全局策略是基于雪花算法的自增ID)。
INPUT
需要手动设置主键,若不设置。插入操作生成SQL语句时,主键这一列的值会是 null。
ASSIGN_ID
当没有手动设置主键,即实体类中的主键属性为空时,才会自动填充,使用雪花算法。
ASSIGN_UUID
当实体类的主键属性为空时,才会自动填充,使用UUID。
2.2.5 全局设置

代码如下:
mybatis-plus:
global-config:
db-config:
# id生成策略 auto为数据库自增
id-type: auto2.3 设置字段映射关系
默认情况下MP会根据实体类的属性名去映射表的列名。 如果数据库的列表和实体类的属性名不一致了我们可以使用 关系。 例如: @TableField 注解的 value 属性去设置映射 如果表中一个列名叫 address而 实体类中的属性名为addressStr则可以使用如下方式进行配置。
@TableField("address")
private String addressStr2.4 设置字段和列名的驼峰映射
默认情况下MP会开启字段名列名的驼峰映射, 即从经典数据库列名 A_COLUMN(下划线命名) 到经 典 Java 属性名 aColumn(驼峰命名) 的类似映射 :
例如以下操作:
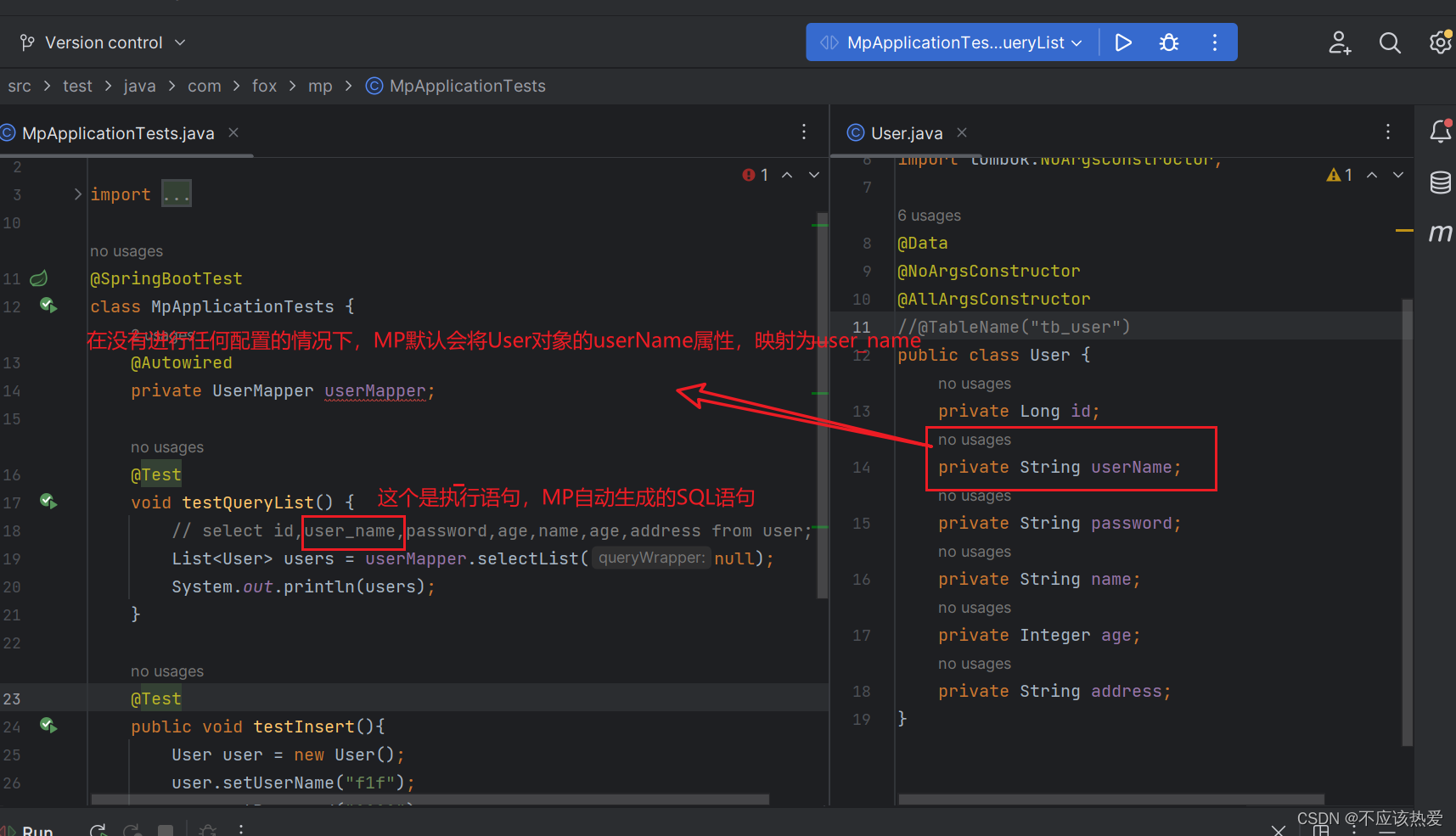
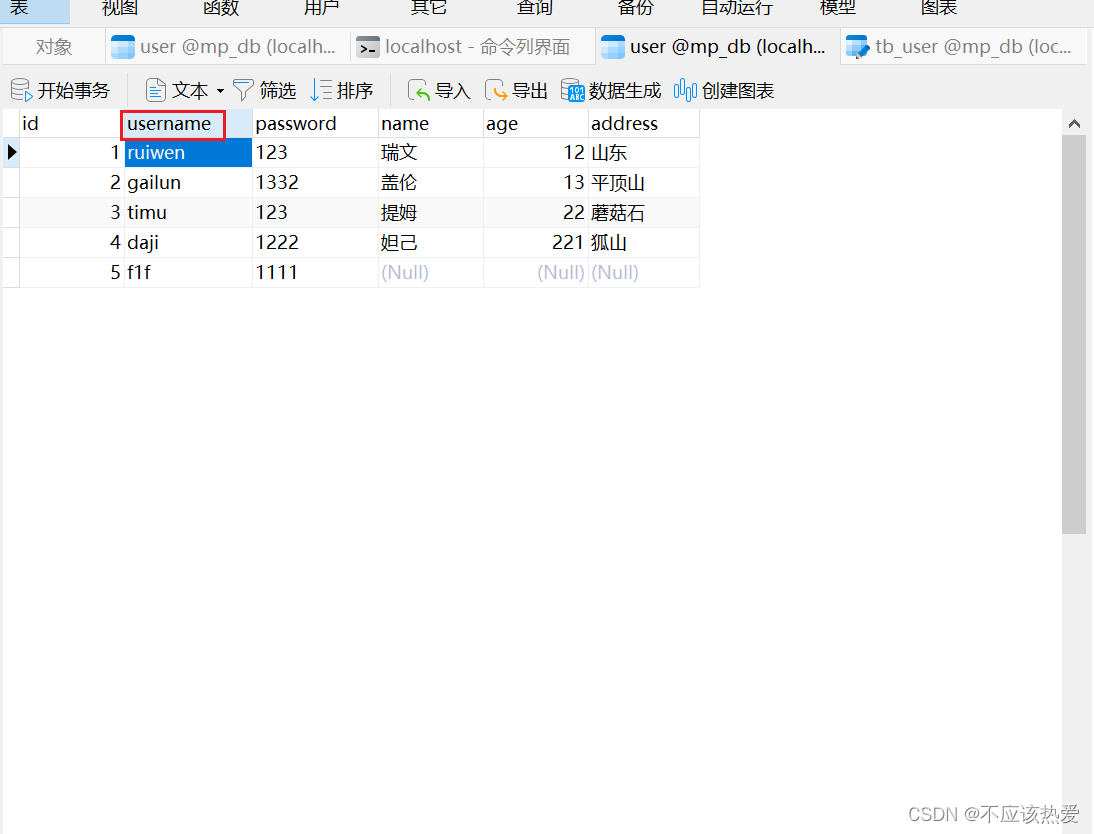
数据库如下:

也正是因为这种映射,所以才能程序执行成功:

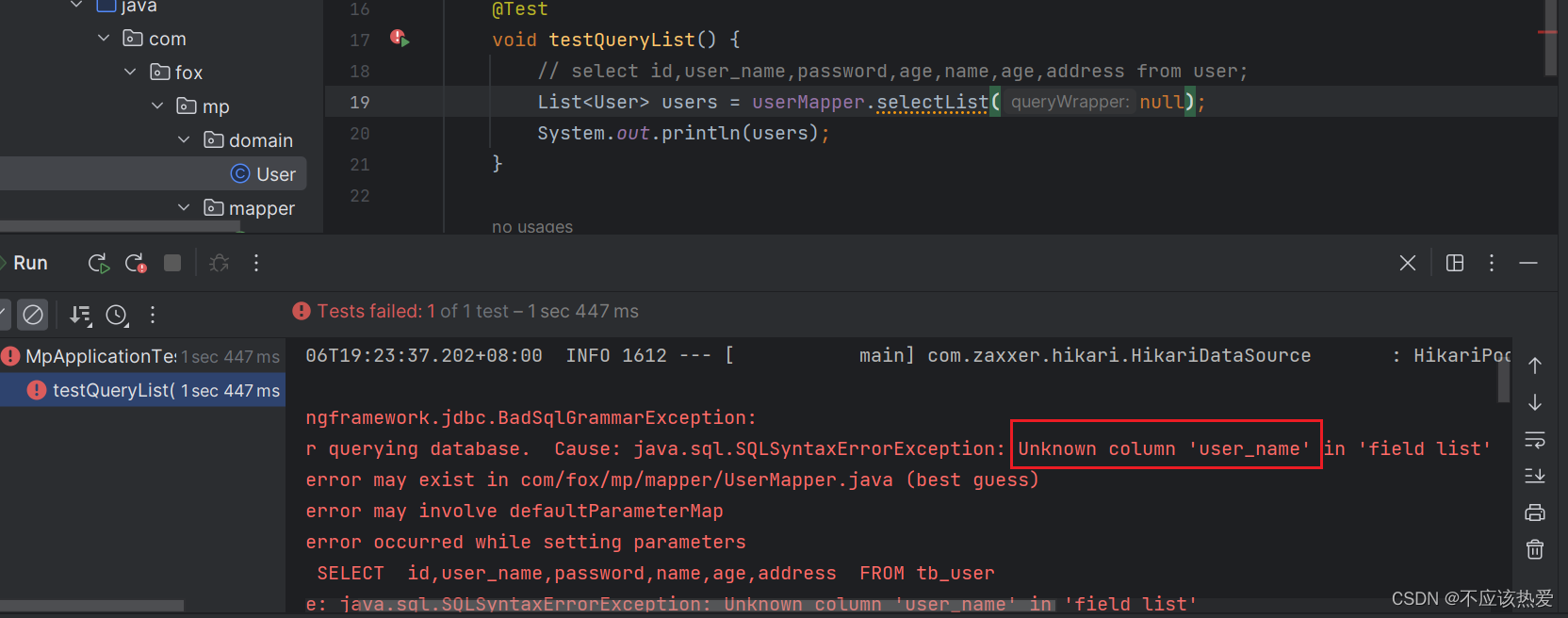
这时我们将列名改为username,程序就会报错:
报错如下:
这时我们可以通过配置,取消MP的默认驼峰映射即可:
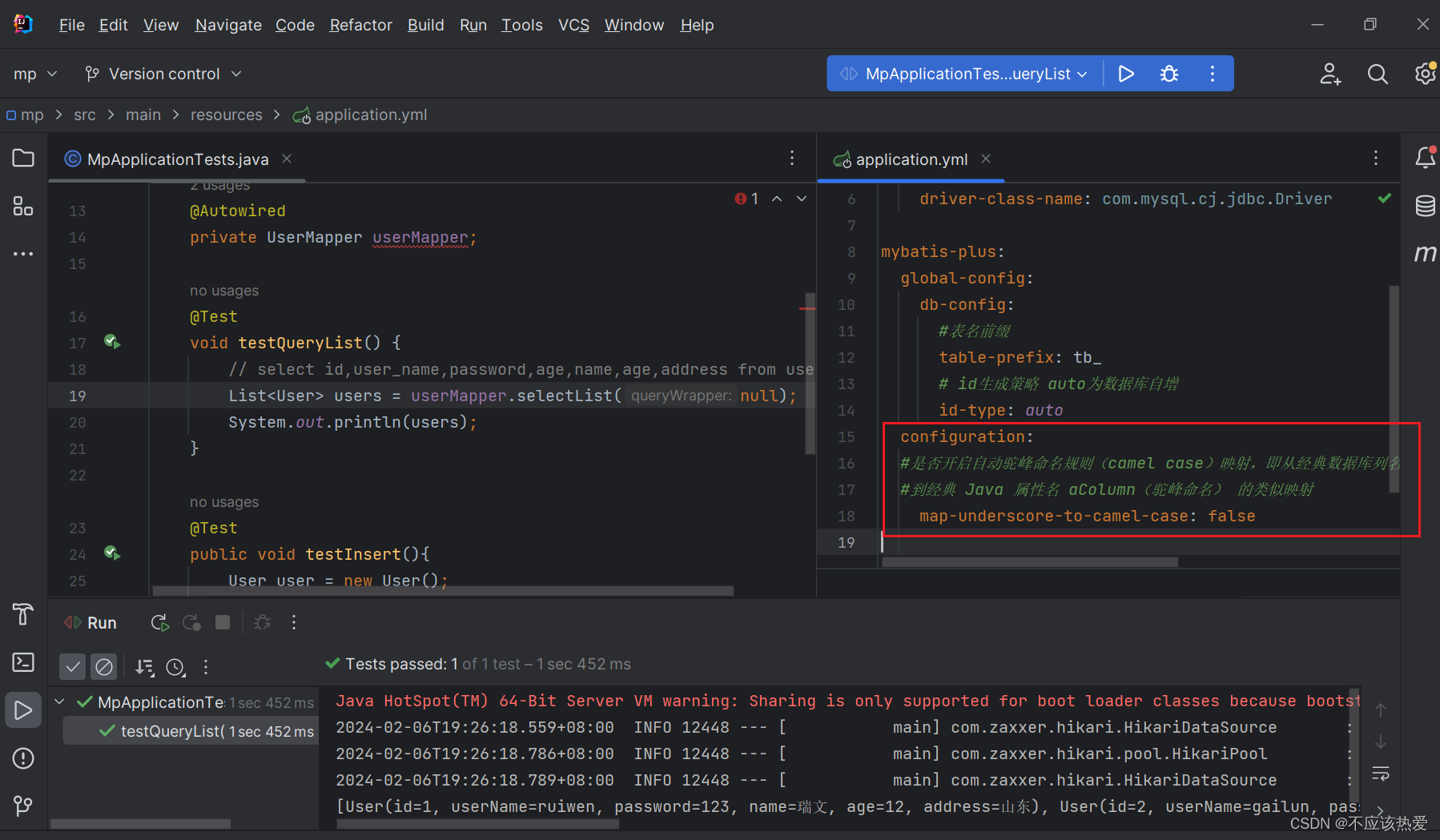
yml代码如下:
mybatis-plus:
configuration:
#是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN(下划线命名)
#到经典 Java 属性名 aColumn(驼峰命名) 的类似映射
map-underscore-to-camel-case: false当然,其实我们一般也不会关闭它,因为默认这种关联方式较为主流。
2.5 设置打印日志
如果需要打印MP操作对应的SQL语句等,可以配置日志输出。 配置方式如下:
mybatis-plus:
# 日志
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
展示效果: