scrapy实现自定义代理中间件
- 前言
- 关卡:实现自定义代理中间件
- 代理中间件源码解析
- 代理池
- 自定义代理中间件
- 结束
前言
ip检测是比较常规的反爬手段,一般站点会限制ip的访问频率,或者根据ip的访问规律和频率来识别异常访问,从而点对点封ip。相信大家对代理ip并不陌生,这是ip反爬的绕过方式,且进一步衍生出代理池。
按笔者过往经验来看:
- 站点限制ip但不会绑定其他信息,这种情况下我们只要每次请求都切换ip即可(短效ip)
- 站点限制ip且绑定cookie等信息,可以每次切换ip时生成一次cookie;或者一个ip直接采集完(长效ip)
各站点的风控机制不同,大家以后遇到的话需要研究它的风控机制并设计突破方案,这个过程需要不断试错,控制变量并找出规律,而这种攻坚过程对逆向思维的训练是很有帮助的。
关卡:实现自定义代理中间件
代理中间件源码解析
进入scrapy->downloadermiddlewares->httpproxy.py,HttpProxyMiddleware便是原生的代理中间件,主要功能逻辑是process_request方法,我们研究它干了什么
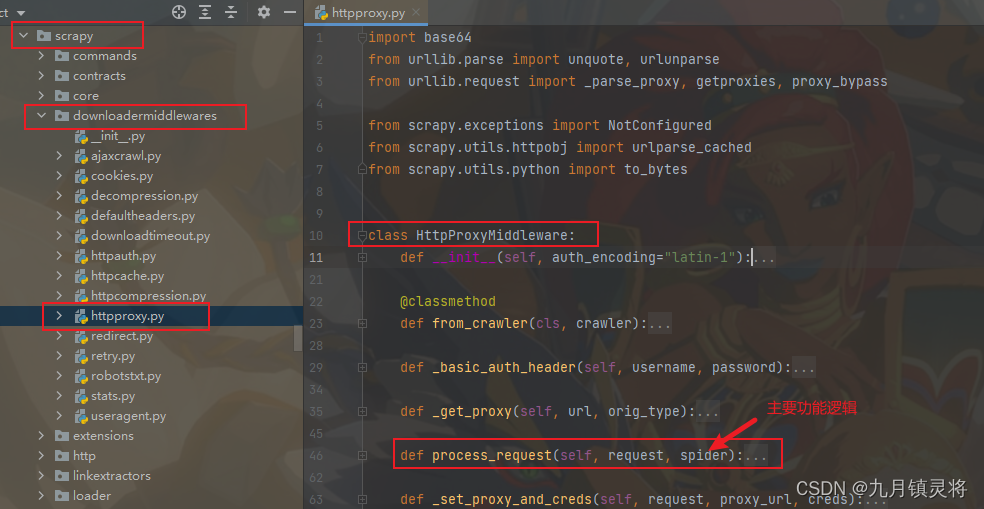
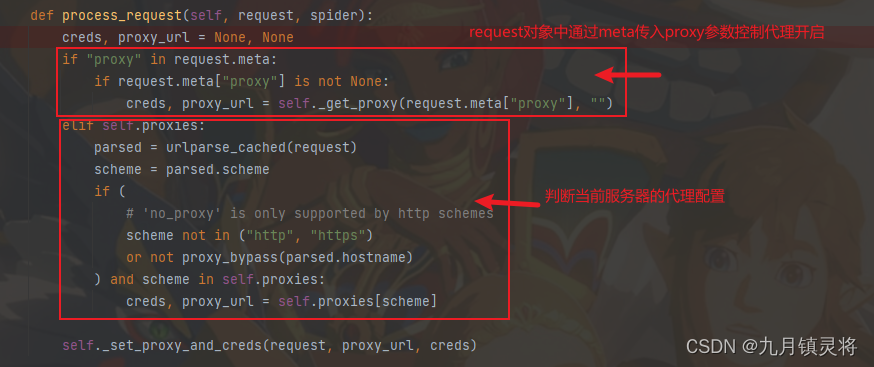
从源码中我们可以知道配置代理的方式
- 通过配置
request.meta["proxy"]来实现代理切换,它的样式是{protocol}://{username}:{password}@{host}:{port} - 利用
requests库的getproxies()函数,它返回当前环境变量中配置的代理设置,也就是self.proxies,在HttpProxyMiddleware初始化时实现
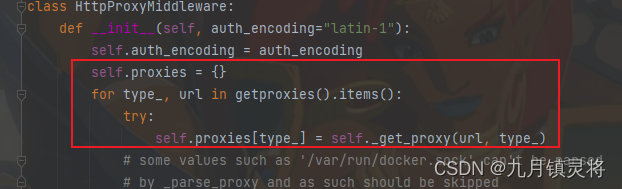
代理池
市面上有很多代理ip厂商,他们的产品有很多种,如隧道代理、短效代理等,有兴趣或者有需求的可以去咨询了解。但是这些代理商是服务众多用户的,他提供的代理池质量不一定能满足我们的需求,最好的选择就是维护一套属于自己的高质量代理池。
有兴趣可以看看这篇博客 高效代理池的维护
自定义代理中间件
笔者这里使用的是自己的代理池,通过接口拿到代理字典,需要使用时随机取值即可
{
"status":1,
"data":[
{
"host":host,
"port":port,
"create_time":create_time,
"expired_time":expired_time,
"priority":priority,
"protocol":protocol,
"source":"source"
}
]
}
主要功能逻辑
def process_request(self, request, spider):
""" 默认代理会一直使用,可以使用下面的参数实现动态使用
meta auto_change_proxy change_proxy _proxy
1. auto_change_proxy:程序自动指定代理
2. change_proxy:更新代理(单次)
3. _proxy:存储上一次代理
"""
meta = request.meta
add_proxy_meta = False
if spider.proxy: # 使用代理
if meta.get('auto_change_proxy', None) or meta.get('change_proxy', None):
add_proxy_meta = True
elif not meta.get('proxy'):
add_proxy_meta = True
# 白名单处理
if add_proxy_meta:
for pattern in spider.custom_settings.get('whitelist_pattern', []) + \
meta.get('proxy_whitelist_pattern', []):
if re.search(pattern, request.url):
add_proxy_meta = False
if meta.get('proxy'):
request.meta['_proxy'] = meta['proxy']
del meta['proxy']
break
if add_proxy_meta:
get_suc, get_proxy = self.get_random_proxy(spider.crawler.settings.attributes['PROXY_POOL_URL'].value)
if not get_suc:
spider.print_log(get_proxy, log_type='error')
# todo: 代理异常处理
else:
spider.print_log(f'随机代理: {get_proxy}')
request.meta['proxy'] = get_proxy
设计逻辑如下:
- 脚本全局增加
proxy参数,集中控制代理使用与否 request.meta增加auto_change_proxy,change_proxy,_proxy参数来实现动态切换和固定使用- 增加白名单机制,对指定站点采集不使用代理
- 日志记录与异常提醒
结束
这个关卡的设计方案是笔者根据自己业务场景实现的,大家如果有同样的需求,需要结合自己的业务场景来思考、设计与实现。
好了,分享就到这了,有啥错误的地方请指正~