1,视频地址
https://www.bilibili.com/video/BV1BB421z7oA/
2,关于Yi-VL-34B
https://www.modelscope.cn/models/01ai/Yi-VL-34B/summary
易视觉语言(Yi-VL)模型是易大型语言模型(LLM)系列的开源多模态版本,能够理解和识别图像内容,并围绕图像进行多轮对话。
Yi-VL表现出色,在包括英语的MMMU和中文的CMMMU最新基准测试中排名第一(基于2024年1月前的数据)。
Yi-VL-34B是全球首个开源的34B视觉语言模型。
github地址:
https://github.com/01-ai/Yi/tree/main/VL
3,启动服务并下载模型
https://github.com/01-ai/Yi
克隆项目
2024-02-06 21:46:27,918 xinference.core.supervisor 3109 INFO Xinference supervisor 0.0.0.0:26770 started
2024-02-06 21:46:28,017 xinference.core.worker 3109 INFO Starting metrics export server at 0.0.0.0:None
2024-02-06 21:46:28,021 xinference.core.worker 3109 INFO Checking metrics export server...
2024-02-06 21:46:31,034 xinference.core.worker 3109 INFO Metrics server is started at: http://0.0.0.0:39893
2024-02-06 21:46:31,036 xinference.core.worker 3109 INFO Xinference worker 0.0.0.0:26770 started
2024-02-06 21:46:31,038 xinference.core.worker 3109 INFO Purge cache directory: /root/autodl-tmp/cache
2024-02-06 21:46:36,394 xinference.api.restful_api 3044 INFO Starting Xinference at endpoint: http://0.0.0.0:9997
2024-02-06 21:47:27,396 xinference.model.llm.llm_family 3109 INFO Caching from Modelscope: 01ai/Yi-VL-34B
2024-02-06 21:47:27,511 - modelscope - INFO - PyTorch version 2.1.2+cu121 Found.
2024-02-06 21:47:27,514 - modelscope - INFO - Loading ast index from /root/autodl-tmp/modelscope/ast_indexer
2024-02-06 21:47:27,514 - modelscope - INFO - No valid ast index found from /root/autodl-tmp/modelscope/ast_indexer, generating ast index from prebuilt!
2024-02-06 21:47:27,587 - modelscope - INFO - Loading done! Current index file version is 1.12.0, with md5 f1ea4cb1dc3276d0fbfad220fd4b82dc and a total number of 964 components indexed
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 122/122 [00:00<00:00, 60.6kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 1.13k/1.13k [00:00<00:00, 518kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 571/571 [00:00<00:00, 258kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 58.0/58.0 [00:00<00:00, 30.7kB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████| 183/183 [00:00<00:00, 93.7kB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 17.0k/17.0k [00:00<00:00, 741kB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 512k/512k [00:00<00:00, 4.13MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 637/637 [00:00<00:00, 358kB/s]
Downloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████▉| 3.67G/3.67G [02:48<00:00, 23.4MB/s]
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 316/316 [00:00<00:00, 172kB/s]
Downloading: 64%|███████████████████████████████████████████████████████████████▎ | 5.94G/9.29G [04:39<02:01, 29.7MB/s]
git clone https://github.com/01-ai/Yi.git
cd Yi/VL
pip install -r requirements.txt
4,启动成功使用命令测试
CUDA_VISIBLE_DEVICES=0,1,2 python3 single_inference.py --model-path /root/autodl-tmp/modelscope/01ai/Yi-VL-34B --image-file images/cats.jpg --question "描述图片的详细内容"
You shouldn't move a model when it is dispatched on multiple devices.
----------
question: 描述图片的详细内容
outputs: 图中,三只猫在室外的石地板上一起吃东西,它们都聚集在一个碗里,享受他们的饭菜。两只猫在碗的左边,另一只猫在右边。
除了猫和碗之外,还有两个额外的碗在场景中可见。一个碗在图像的左边,另一个在右边。这些碗可能包含食物或水,为猫提供充足的供应。
占用内存情况:
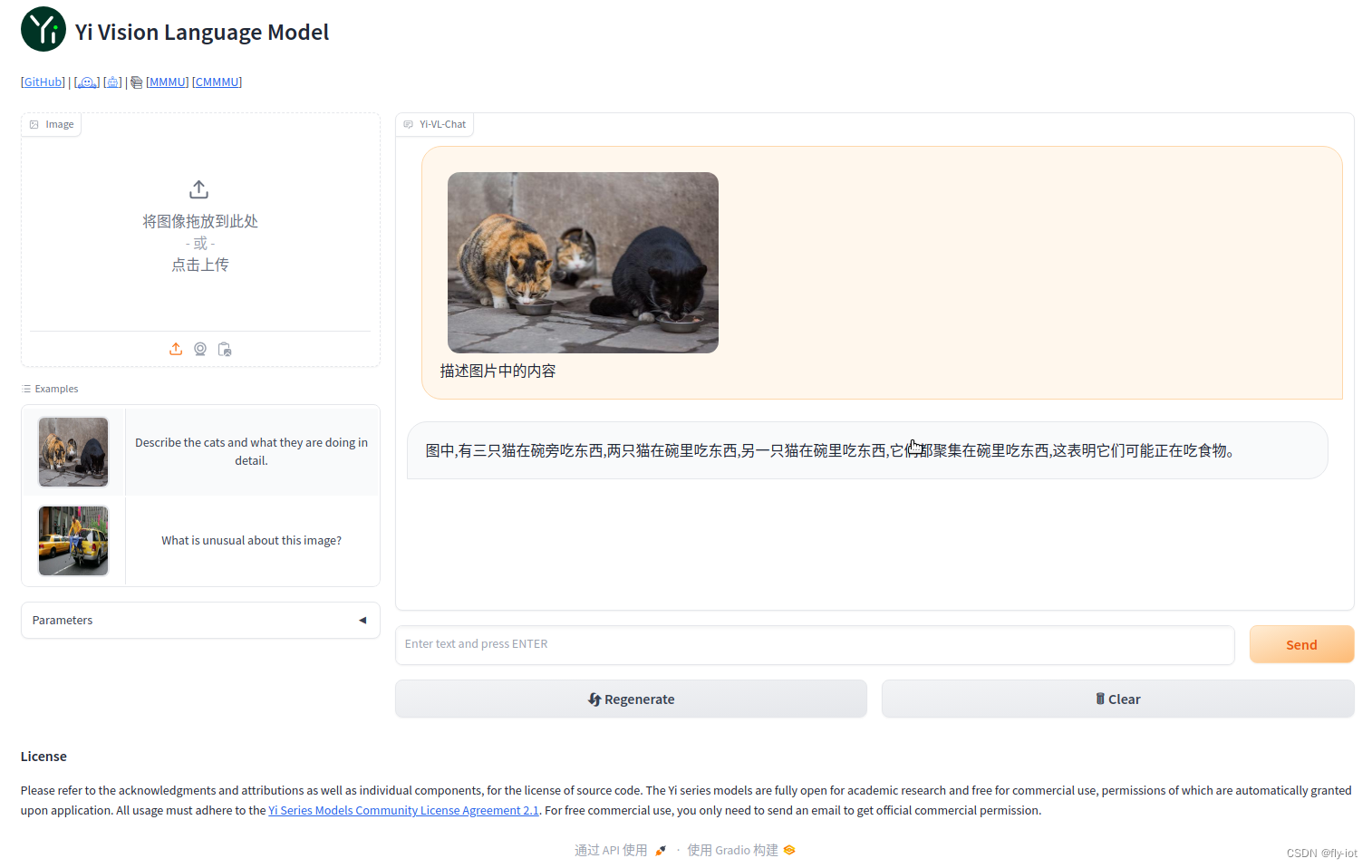
5,启动web界面测试
CUDA_VISIBLE_DEVICES=0,1,2 python3 web_demo.py --model-path /root/autodl-tmp/modelscope/01ai/Yi-VL-34B --server-port 6006
然后通过web界面测试图片
6,总结
使用 Yi-VL-34B模型也是不错的,参数更多。理解能力更强了。
可以用来做一些图片处理的审核工作了。
可以做出更多的智能工具来了。大模型真的特别方便了。