纵观人类历史,从结绳计数、木制计数到巴比伦的粘土板上的刻痕,再到中国古代的算盘,社会生产力的提高与当时所采用的计算工具密切相关。计算工具能力越强,就能大幅缩短人类解决复杂问题的时间,社会生产力水平自然就会越高。
CPU
CPU,全称Central Processing Unit,即中央处理器。现代电子计算机的发明是基于1940年代诞生的冯·诺依曼架构,这个架构主要由运算器、控制器、存储器、输入设备、输出设备等五个主要部分组成。
- 特点:CPU具有通用性和灵活性,能够执行各种任务,如操作系统管理、软件运行和数据处理等。它擅长串行计算,即按照指定顺序执行任务。
- 应用:广泛应用于个人电脑、服务器、移动设备等各种计算设备中。
按照冯·诺依曼架构,数据来了会先放到存储器。然后,控制器会从存储器拿到相应数据,再交给运算器进行运算。运算完成后,再把结果返回到存储器。大致的架构如图1所示,其中运算器和控制器两个部分组成了CPU的主要功能。

上面的计算方式,从数据输入到输出算一个完整的处理流程,冯·诺依曼体系采用的就是串行运算方式。即一次只能进行一项计算任务,只有上一个计算指令完成了,数据存储了,才能开启下一个指令。
这就是CPU所采用的先进先出运算模式。从个人计算机诞生起,CPU的硬件架构到指令集都是基于串行运算模式设计,其优势是逻辑控制力好,即计算通用性很好,为的就是能应付各种复杂的计算需求,在软件对计算性能要求不高的时代,这种设计是有优势的。
GPU
GPU,全程Graphics Processing Unit,又称图像处理器(显示核心、视觉处理器、显示芯片),是一种专门用于处理图形和图像计算任务的处理器。
- 特点:GPU拥有大量的小型处理核心,可同时处理多个任务,能够高效地执行并行计算。它在处理复杂图像、视频和3D图形等方面表现出色。但值得注意的是,GPU无法单独工作,必须由CPU进行控制调用才能工作。
- 应用:基于它的特点,GPU不仅可以在图像处理领域大显身手,如游戏产业、动画制作;它还被用来科学计算、数值分析、海量数据处理、金融分析等需要大规模并行计算的领域。
GPU除作为独立显卡的核心用于个人电脑,为高清视频、大型游戏提供高质量3D图形渲染,基于GPU构建的专业显卡还配置在高端工作站上做复杂的三维设计和工程仿真。但当前GPU最重要的应用场景还是AI计算,支撑AI大模型的训练和推理。
Q:那为什么CPU不行,非GPU不可?
A:GPU的推出就是为了接手原本由CPU负责的图形显示处理工作。因而GPU架构有其先天的计算特征,就是完全为3D图形处理而设计。
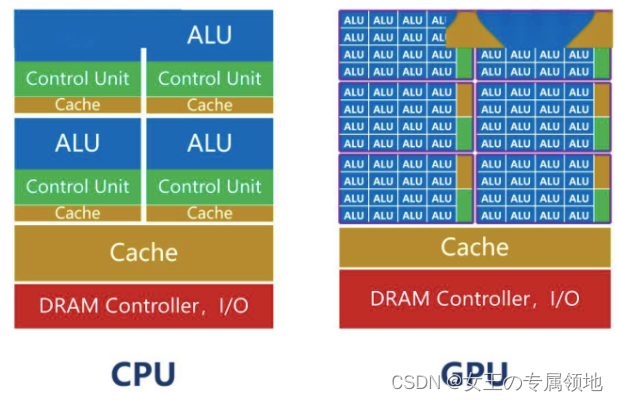
- CPU指令相对复杂,它需要做好资源的调度和控制,支持操作系统的中断处理、内存管理、I/O处理等,运算过程需要大量的逻辑控制,因此内部的控制单元较多,极大挤压了计算单元数量,使计算性能受到很大限制,还需要预留空间为数据建立多级缓存;
- GPU运算就不需要考虑这些,也无需太多的控制单元,芯片上大部分空间都留给了计算单元,因此适合并行计算任务和大规模数据访问,通常具有更高的带宽和更低的延迟。
ASIC
ASIC(Application Specific Integrated Circuit)是一种为专门目的而设计的集成电路。无法重新编程,效能高功耗低,但价格昂贵。近年来涌现出的类似TPU、NPU、VPU、BPU等各种芯片,本质上都属于ASIC。
ASIC不同于 GPU 和 FPGA 的灵活性,定制化的 ASIC 一旦制造完成将不能更改,所以初期成本高、开发周期长的使得进入门槛高。目前,大多是具备 AI 算法又擅长芯片研发的巨头参与,如 Google 的 TPU。由于完美适用于神经网络相关算法,ASIC 在性能和功耗上都要优于 GPU 和 FPGA,TPU1 是传统 GPU 性能的 14-16 倍,NPU 是 GPU 的 118 倍。寒武纪已发布对外应用指令集,预计 ASIC 将是未来 AI 芯片的核心。
ASIC芯片的计算能力和计算效率都可以根据算法需要进行定制,所以ASIC与通用芯片相比,具有以下几个方面的优越性:体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低。但ASIC芯片的算法是固定的,一旦算法变化就可能无法使用。
NPU
NPU(Neural network Processing Unit), 即神经网络处理器。神经网络处理器NPU采用“数据驱动并行计算”的架构,是专门为人工智能应用开发的处理器,尤其擅长进行神经网络的训练和推理计算,特别是处理视频、图像类的海量多媒体数据。
- 特点:NPU采用了专门的硬件加速技术,能够高效地进行大规模的矩阵运算,解决了传统芯片在神经网络运算时效率低下的问题。
- 应用:NPU主要应用于人脸识别、语音识别、自动驾驶、智能相机等需要进行深度学习任务的领域。
TPU
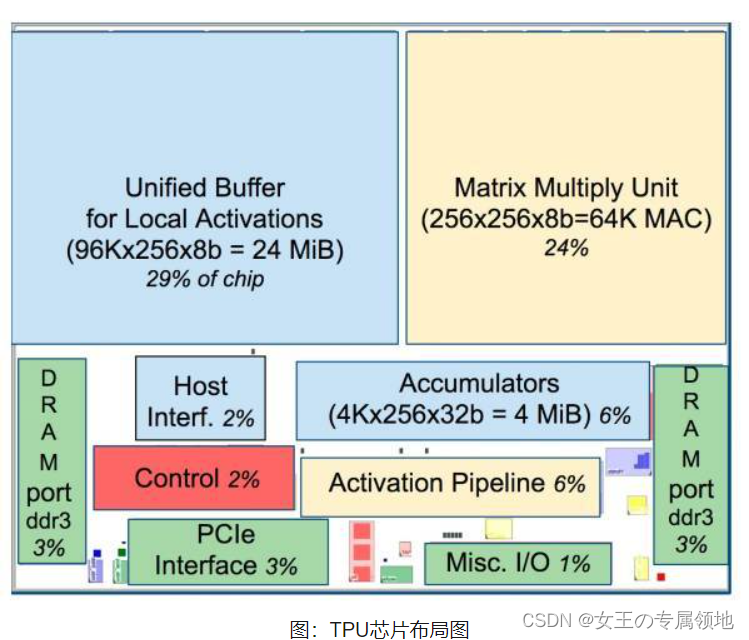
TPU,全称Tensor Processing Unit,即张量处理单元,TPU是谷歌开发的一种特殊类型的芯片,专门用于加速人工智能和机器学习工作负载。(张量(tensor)是一个包含多个数字/多维数组的数学实体)。
目前,几乎所有的机器学习系统,都使用张量作为基本数据结构。所以,张量处理单元,我们可以简单理解为“AI处理单元”。TPU主要针对张量(tensor)操作进行了优化,提高了机器学习相关任务的性能。
- 特点:TPU具有卓越的张量计算能力,能够高速进行大规模矩阵运算,支持高性能的神经网络训练和推理计算。
- 应用:常用于机器学习模型的训练和推理计算,例如在自然语言处理、计算机视觉和语音识别等领域中发挥重要作用。
BPU
BPU,Brain Processing Unit,大脑处理器。是由地平线科技提出的嵌入式人工智能处理器架构。第一代是高斯架构,第二代是伯努利架构,第三代是贝叶斯架构。目前地平线已经设计出了第一代高斯架构,并与英特尔在2017年CES展会上联合推出了ADAS系统(高级驾驶辅助系统)
FPGA
FPGA全称是可编程逻辑门阵列,内部结构由大量的数字(或模拟)电路组成,可以实现各种功能。FPGA是ASIC的一种,只是ASIC是全定制电路芯片,FPGA是半定制电路芯片,它解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
数据计算包括两种方式:一种是利用CPU或GPU基于指令的架构编写计算所需的软件,另一种是针对特定计算需求设计制造出一套专用的电路,比如ASIC、FPGA。但不同的是,对FPGA进行编程要使用硬件描述语言,硬件描述语言描述的逻辑可以直接被编译为晶体管电路的组合。所以FPGA实际上直接用晶体管电路实现用户的算法,没有通过指令系统的翻译。
相比于CPU 和GPU数据处理需先读取指令和完成指令译码,FPGA不采用指令和软件,是软硬件合一的器件。因而计算效率更高、功耗更低,且更接近IO。
总结
-
功能:CPU具有通用性,适用于各种计算任务;GPU擅长图形渲染和并行计算;NPU专注于神经网络的训练和推理计算;TPU专为机器学习任务而设计。
-
并行能力:GPU和TPU具有更多的处理核心和更高的并行计算能力,适合处理大规模并行计算任务。
-
硬件加速:NPU和TPU采用专门的硬件加速技术,能够高效地执行特定类型的计算任务。
-
应用领域:CPU广泛应用于个人电脑、服务器等各种设备;GPU主要应用于游戏、动画制作、科学计算等领域;NPU常用于人脸识别、语音识别等人工智能应用;TPU常用于深度学习任务和自然语言处理等领域。
目前主流Al芯片就三类:以GPU为代表的通用芯片、以ASIC定制化为代表的专用芯片以及以FPGA为代表的半定制化芯片,其中GPU市场最为成熟且应用最广。但人工智能产业发展除了需要强大的算力,还需要更优秀的算法和庞大的数据支撑,GPU能否在AI算力竞争中持续保持优势仍是未知。在我们看来,有谷歌和华为背书的ASIC,以及英特尔和AMD背书的FPGA,未来都是有很大破局机会的。


![[office] Excel2007在工作簿中创建区域名称 #职场发展#经验分享](https://img-blog.csdnimg.cn/img_convert/417563c35c430b1924340cba1b71556a.jpeg)