text-generation-webui搭建大模型运行环境
- text-generation-webui
- 环境初始化
- 准备模型
- 启动项目
- Bug说明
- 降低版本
- 启动项目
text-generation-webui
text-generation-webui是一个基于Gradio的LLM Web UI开源项目,可以利用其快速搭建部署各种大模型环境。
环境初始化
下载该开源项目
git clone https://github.com/oobabooga/text-generation-webui.git
创建conda环境并进入
conda create -n ui python=3.10
conda activate -n ui
安装项目依赖
cd text-generation-webui
pip install -r requirements.txt
在安装text-generation-webui项目的依赖库文件时,出现如下异常:
WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.HTTPSConnection object at 0x7fed6cb7abf0>, 'Connection to github.com timed out. (connect timeout=15)')': /oobabooga/llama-cpp-python-cuBLAS-wheels/releases/download/cpu/llama_cpp_python-0.2.24+cpuavx2-cp310-cp310-manylinux_2_31_x86_64.whl
解决方案:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
注意:
这里最大一个问题是:
requirements.txt中存在大量GitHub项目中的文件,需要访问GitHub,其速度不言而喻,如果是云服务器中特别注意一点,不要使用proxy服务器,直接在该服务器上安装proxy服务
准备模型
这里以Llama2-7B模型为例说明,将其放到text-generation-webui/models目录
mv /root/models/llama-2-7b-hf text-generation-webui/models
启动项目
python server.py
(base) root@instance:~/text-generation-webui-main# python server.py
15:49:18-962453 INFO Starting Text generation web UI
15:49:18-966915 INFO Loading the extension "gallery"
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
运行成功,访问:http://127.0.0.1:7860
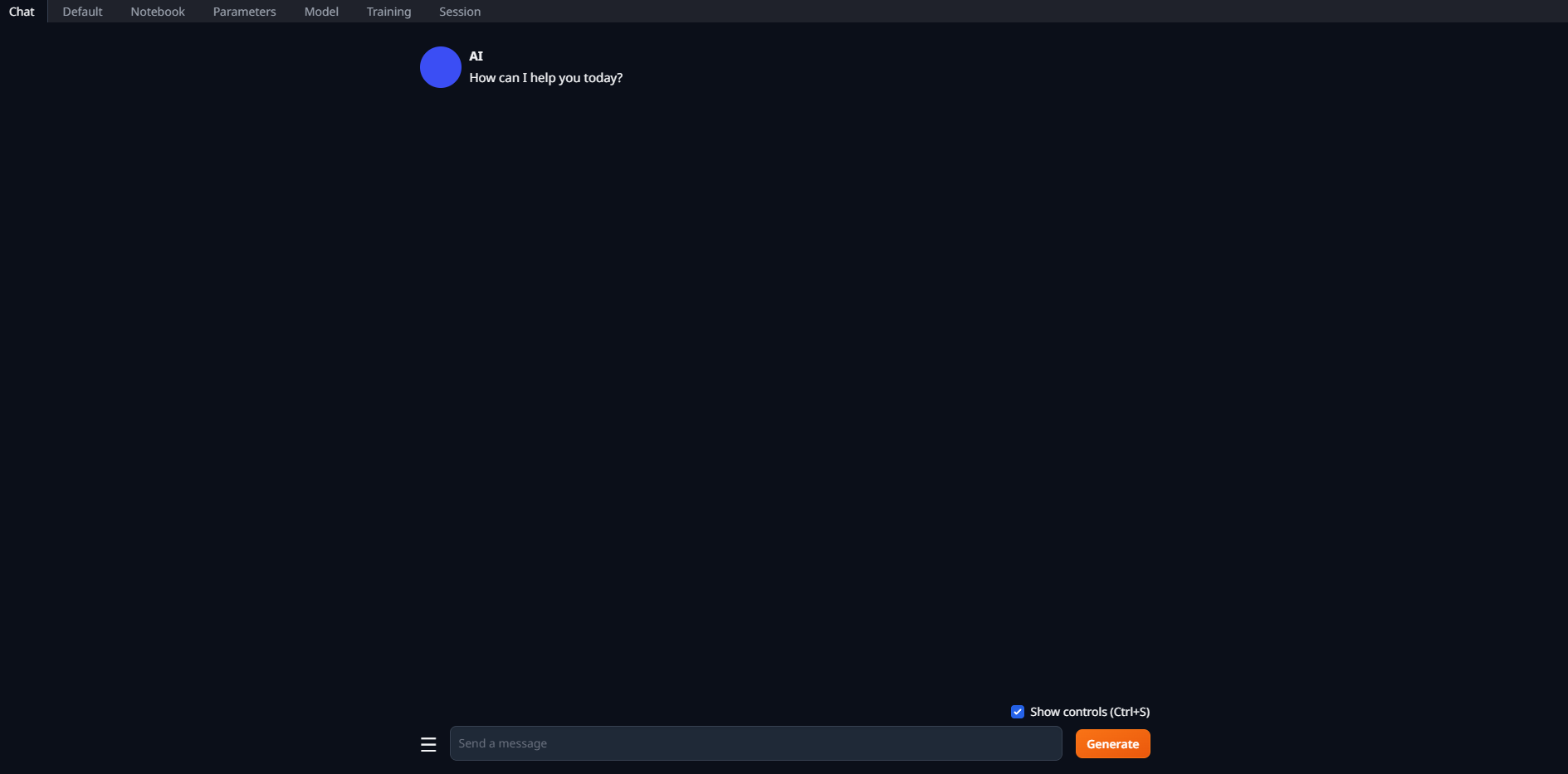
Bug说明
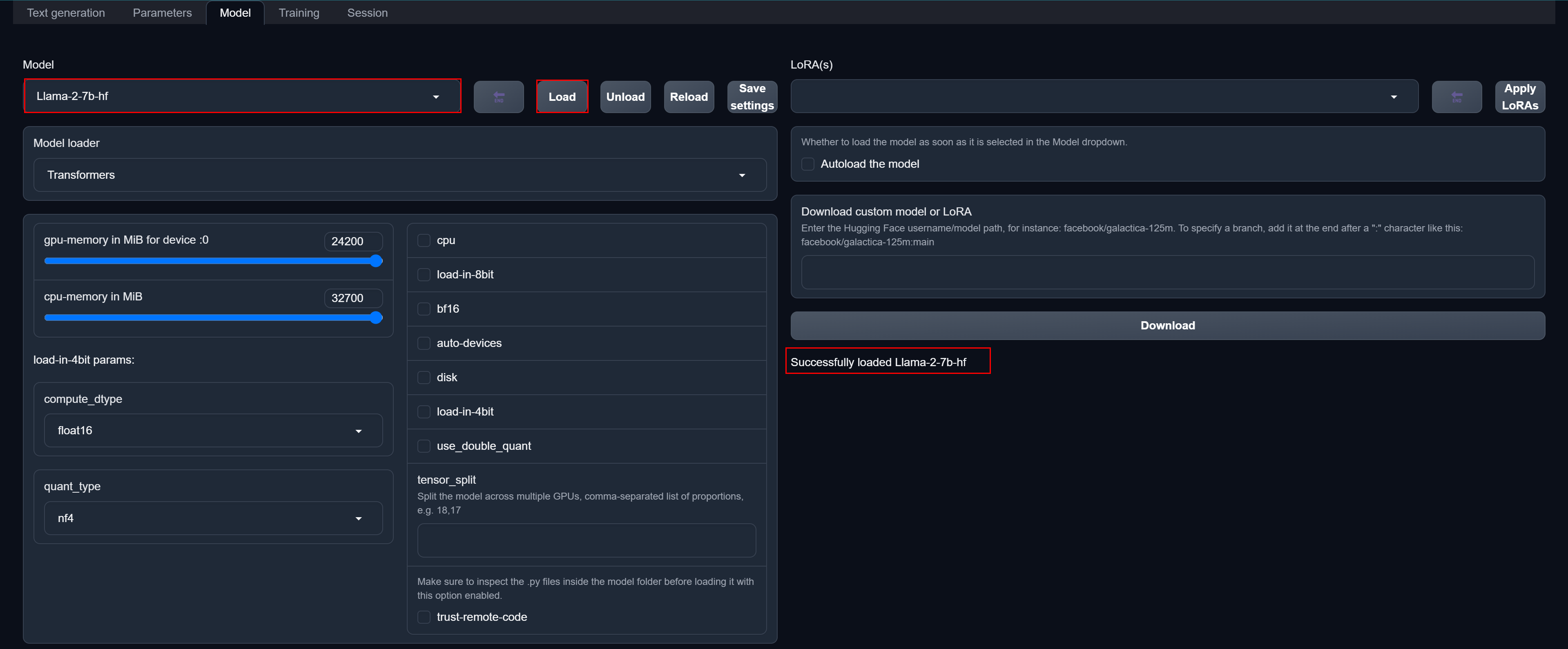
在选择模型后,点击Load加载模型
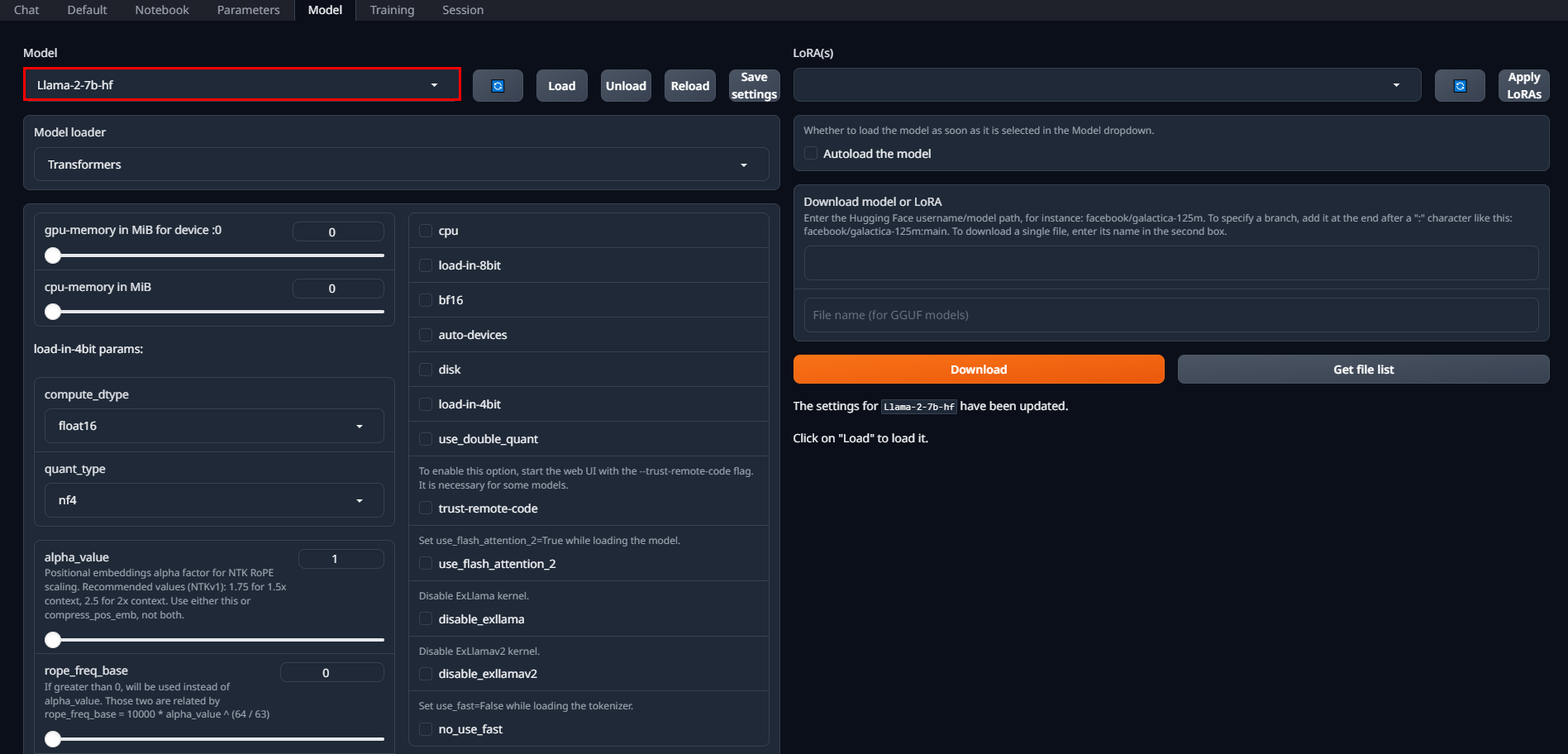
注意:
这里加载模型始终加载失败,不管是什么模型。另外这里踩了2天坑,不是环境、配置什么的不对,根本原因是该项目的Bug,可以在
Issues进一步确认
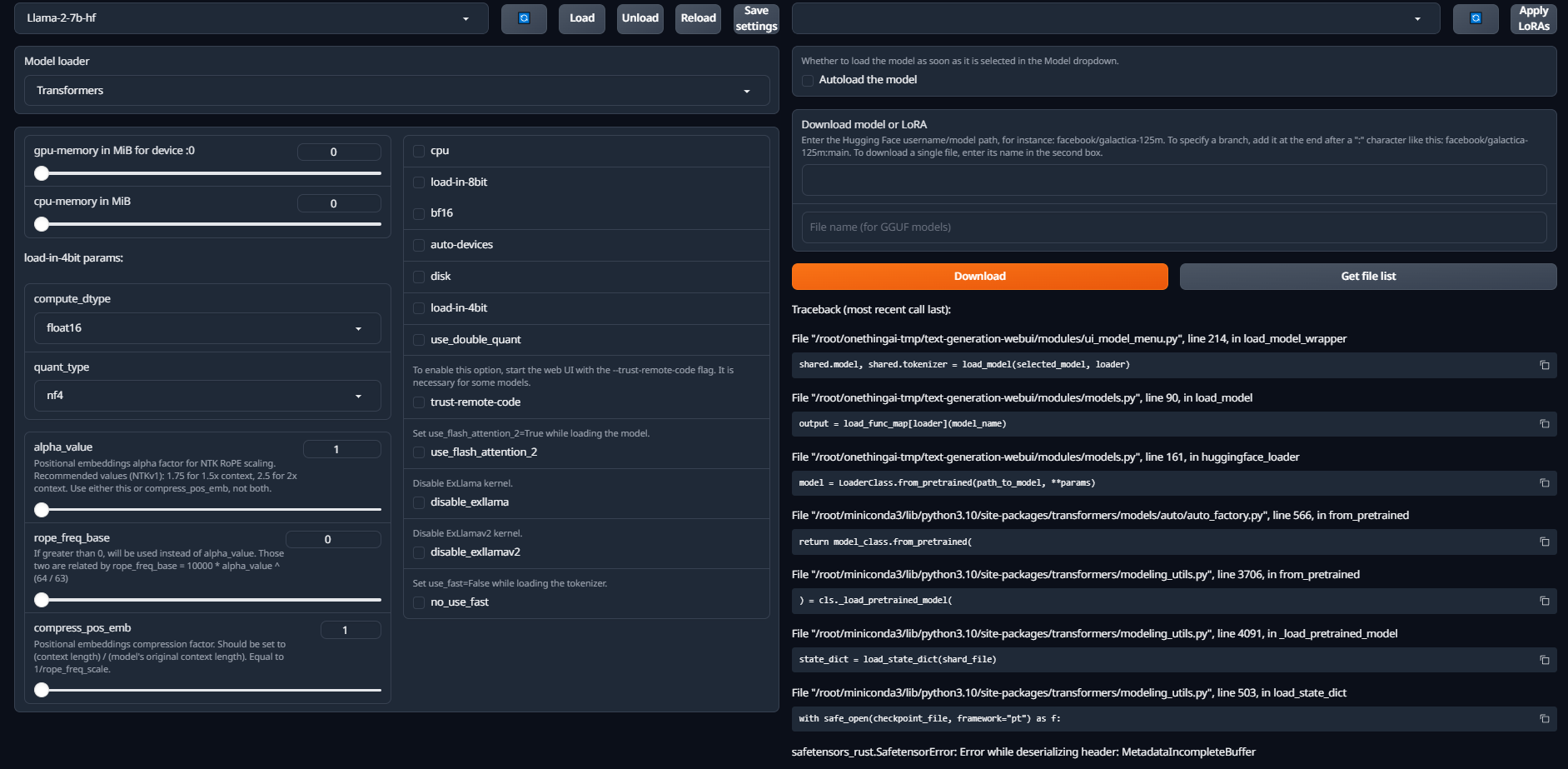
控制台异常日志如下:
(base) root@instance:~/text-generation-webui# python server.py
13:38:23-216368 INFO Starting Text generation web UI
13:38:23-224693 INFO Loading the extension "gallery"
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
13:38:57-356736 INFO Loading Llama-2-7b-hf
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
13:38:57-739003 ERROR Failed to load the model.
Traceback (most recent call last):
File "/root/text-generation-webui/modules/ui_model_menu.py", line 214, in load_model_wrapper
shared.model, shared.tokenizer = load_model(selected_model, loader)
File "/root/text-generation-webui/modules/models.py", line 90, in load_model
output = load_func_map[loader](model_name)
File "/root/text-generation-webui/modules/models.py", line 161, in huggingface_loader
model = LoaderClass.from_pretrained(path_to_model, **params)
File "/root/miniconda3/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 566, in from_pretrained
return model_class.from_pretrained(
File "/root/miniconda3/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3706, in from_pretrained
) = cls._load_pretrained_model(
File "/root/miniconda3/lib/python3.10/site-packages/transformers/modeling_utils.py", line 4091, in _load_pretrained_model
state_dict = load_state_dict(shard_file)
File "/root/miniconda3/lib/python3.10/site-packages/transformers/modeling_utils.py", line 503, in load_state_dict
with safe_open(checkpoint_file, framework="pt") as f:
safetensors_rust.SafetensorError: Error while deserializing header: MetadataIncompleteBuffer
降低版本
下载使用V1.5版本的text-generation-webui,然后重新把模型放到text-generation-webui/models目录下
git clone --branch v1.5 https://github.com/oobabooga/text-generation-webui.git
1.启动该项目,指定加载chatglm3-6b模型
(base) root@instance:~/text-generation-webui# python server.py --model chatglm3-6b --trust-remote-code
2023-12-26 20:54:04 WARNING:trust_remote_code is enabled. This is dangerous.
2023-12-26 20:54:06 INFO:Loading chatglm3-6b...
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:28<00:00, 4.06s/it]
2023-12-26 20:54:38 INFO:Loaded the model in 32.00 seconds.
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
2.启动该项目,指定加载Llama-2-7b-hf模型
(base) root@instance:~/text-generation-webui# python server.py --model Llama-2-7b-hf
2023-12-26 21:17:52 INFO:Loading Llama-2-7b-hf...
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 4.48it/s]
2023-12-26 21:18:03 INFO:Loaded the model in 11.05 seconds.
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
启动项目
执行python server.py 命令启动Web UI
(base) root@instance:~/text-generation-webui# python server.py
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
访问:http://127.0.0.1:7860
选择模型,然后加载该模型,显示加载成功