FlashAttention-2
- 提出背景
- FlashAttention-2 改进
- 前向传播和反向传播对比
- FlashAttention前向传播
- FlashAttention反向传播
- FlashAttention-2前向传播
- FlashAttention-2反向传播
- FlashAttention-2并行性
- 线程束之间的工作分区
- 总结
- FlashAttention
- FlashAttention-2
论文:https://arxiv.org/pdf/2307.08691.pdf
提出背景
前置:FlashAttention:高效注意力计算的新纪元
核心问题在于,如何提升 Transformer 模型在处理长序列数据时的效率,尤其是在注意力(Attention)层的计算上?
在Transformer架构中,注意力层的计算复杂度和内存需求随着输入序列长度的增加而呈二次方增长,这限制了模型的扩展性和效率。
为了解决这个问题,研究人员提出了 FlashAttention 技术,并在其基础上进一步发展出 FlashAttention-2。
FlashAttention-2 改进
FlashAttention-2的改进:
- 算法调整减少非矩阵乘法FLOPs:
- 改进:FlashAttention-2通过减少非矩阵乘法操作,优化了计算流程,提高了利用专用硬件单元的效率。
- 例子对比:如果FlashAttention像一个老式工厂依赖多功能但速度慢的机器,FlashAttention-2则像升级后的工厂,更多地使用专用于高速组装的机器。
- 在FlashAttention中,非矩阵乘法操作占用了相当一部分计算资源,而在FlashAttention-2中,这些操作被优化以利用GPU的Tensor Cores,从而加快整体计算速度。
- 并行计算注意力:
- 改进:FlashAttention-2通过在更多的线程块上并行化计算来增加GPU资源的占用率,提高了计算效率。
- 例子对比:在FlashAttention中,注意力计算可能更集中,类似于一个分析师处理整批数据。
- 而在FlashAttention-2中,这项工作被分成多部分,类似于多个分析师同时处理数据的不同部分,显著提高了处理速度。
- 工作分配:
- 改进:FlashAttention-2在每个线程块内部更智能地分配工作给线程束,减少了线程束间的通信开销。
- 例子对比:在FlashAttention中,所有的文件传递都要通过中央档案室,导致效率低下。
- 而在FlashAttention-2中,每个部门有自己的存档点,员工可以快速获取文件,类似于在每个线程块中进行优化,使得线程束间几乎不需要通过共享内存通信,提高了效率。
这些改进的结果是FlashAttention-2的计算速度比FlashAttention快了大约2倍,达到了接近GEMM操作的效率水平。
对比原有的 FlashAttention 解法,FlashAttention-2 通过更好的工作划分和并行计算策略,显著提高了处理长序列时的效率和吞吐量,达到了更接近矩阵乘法操作的理论最大 FLOPs/s,同时减少了内存使用量,解决了处理长序列数据时面临的主要瓶颈。
前向传播和反向传播对比
FlashAttention前向传播
- 数据装载:从HBM(高带宽内存)到SRAM(静态随机存取内存)加载数据块。
- 计算:对加载的块计算注意力输出。
- 更新输出:不写入大型中间矩阵S和P,而是直接更新输出O。
- 优化:通过在线softmax技术进行分块计算和重缩放每个块的输出,避免了完整softmax计算,以此减少内存操作。
想象一个图书馆的书籍检索系统。
在FlashAttention的前向传播中,每当有人请求一本书时,工作人员(GPU的线程)会去一个巨大的仓库(HBM)中找到这本书,然后将它带到前台(SRAM)进行检查。
如果需要检索多本书(即处理大量数据),他们会尽量避免一次性搬运所有的书籍,而是采用分批搬运的方式来减少往返仓库的次数。
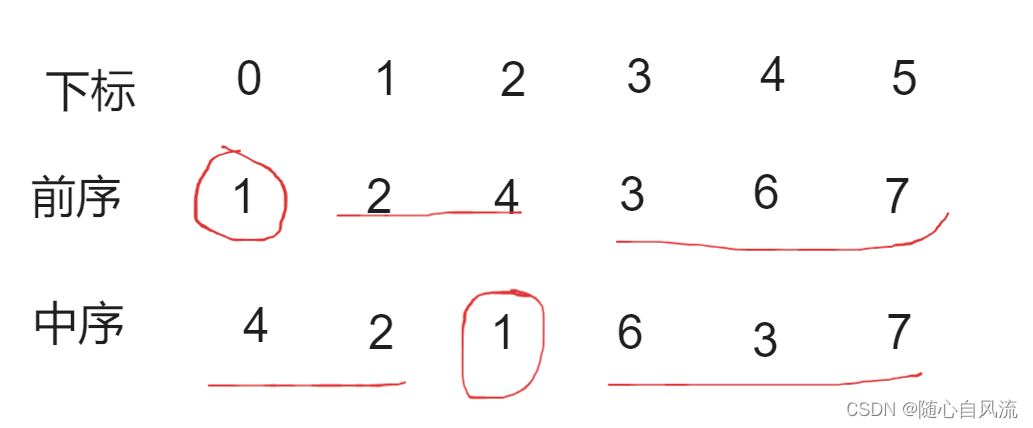
将键矩阵 ( K ) 和值矩阵 ( V ) 分成块,并对每个块计算注意力。
通过这种方式,计算避免了在高带宽内存(HBM)中存储完整的中间注意力矩阵 ( S ) 和 ( P ),而是在片上SRAM中进行计算,并且只存储必要的输出,这减少了内存的读/写操作。
FlashAttention反向传播
- 重计算:重新计算注意力矩阵S和P的值,以避免在HBM中存储这些大型矩阵。
- 内存效率:FlashAttention在反向传播中也实现了显著的内存节约和计算加速。
在图书馆的例子中,如果客户想要返回一些书籍,FlashAttention的反向传播相当于工作人员重新确认每本书的位置,然后将它们放回仓库中的正确位置。
这个过程被优化以确保最小化搬运和存储过程,以便书籍可以在下次被快速检索。
FlashAttention-2前向传播
- 算法优化:减少了非矩阵乘法FLOPs的数量,充分利用专门的GPU计算单元(如Tensor Cores)。
- 维护未缩放版本:在整个计算循环中维护一个未缩放的输出版本,只在最后缩放最终输出。
- 存储优化:只存储logsumexp,而不是最大值和指数和,以简化后向传播中的计算。
在改进版的系统中,FlashAttention-2对前向传播进行了优化,就像工作人员现在使用一个电子目录(非矩阵乘法FLOPs的减少)来快速确定书籍的位置,然后只搬运所需的书籍到前台。
他们还开始记录哪些书籍最受欢迎,以此减少未来的检索时间(存储logsumexp代替max和sum)。
FlashAttention-2反向传播
- 与前向传播类似:FlashAttention-2的反向传播与FlashAttention大致相同,但进行了一些小的调整,例如,仅使用行logsumexp L 而不是行最大值和行指数和。
在返回书籍时,工作人员现在只需要检查电子目录中的位置,然后直接将书放回正确的架子上,而不需要再次确认整个仓库的存储布局(使用行logsumexp代替完整的行最大值和行指数和计算)。
FlashAttention-2并行性
- 序列长度并行化:在序列长度维度上进行并行化,提高了GPU资源的占用率,尤其是在批量小或头数少时。
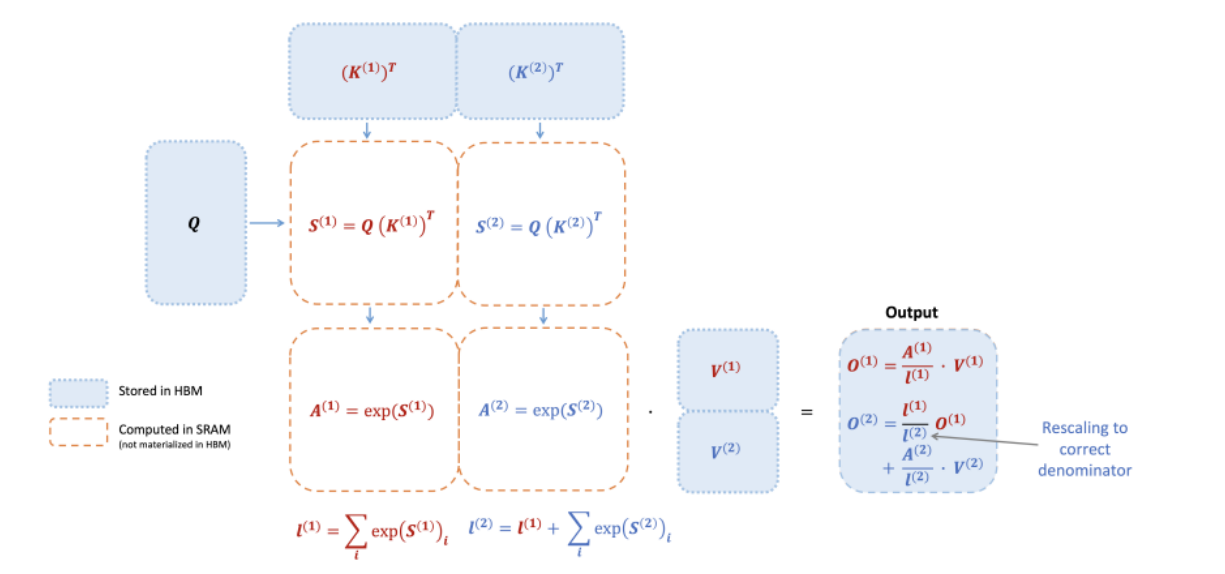
在FlashAttention-2中,图书馆现在雇佣了更多的工作人员,并将仓库分成了几个区域。
现在,当多个请求同时到来时,不同的工作人员可以同时在不同的区域检索书籍,大大加快了整个系统的响应速度(序列长度并行化)。
FlashAttention-2的前向传播和反向传播的并行化策略。
在前向传播中,不同的工作单元(线程块)负责注意力矩阵的不同行块,而在反向传播中,它们处理列块。
线程束之间的工作分区
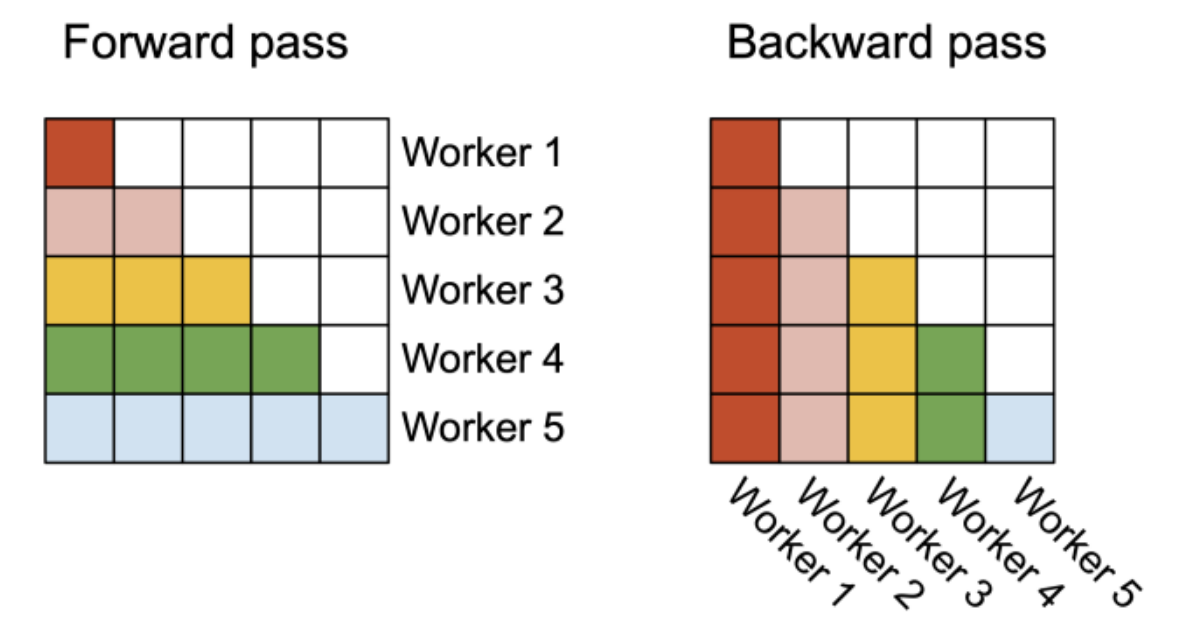
- FlashAttention:在计算QKᵀ时将K和V分割在不同的线程束中。
- FlashAttention-2:改进了工作分区,减少了在不同线程束之间共享内存读写的需要。
在FlashAttention中,所有工作人员在检索书籍后都需要到一个中央台账(共享内存)进行登记。
在FlashAttention-2中,这个过程被优化了。
每个工作人员都有自己的手持设备(线程束内部的工作分配),可以在找到书籍的同时进行登记,这减少了在中央台账前排队的时间。
在FlashAttention中,由于所有线程束都需要写入它们的中间结果到共享内存,同步后再加起来,这导致了前向传播中的效率损失。
而在FlashAttention-2中,通过将Q分割在不同线程束中,并保持K和V对所有线程束可访问,每个线程束只需与它们的共享片段V进行乘法运算以获得输出的一部分,从而无需线程束间通信。
比较了FlashAttention和FlashAttention-2在前向传播中不同线程束(一组线程)之间的工作分区。
在 FlashAttention(a) 中,线程束分割 ( K ) 和 ( V ) 同时计算 ( QK^T ) 的切片,这需要同步操作来组合结果。
FlashAttention-2(b) 通过在线程束间分割 ( Q ),同时保持所有线程束都能访问 ( K ) 和 ( V ),优化了这一点,减少了同步和共享内存访问的需求,有可能提高了计算效率。
总结
FlashAttention
- IO感知计算:FlashAttention通过优化内存访问来减少计算时间和内存占用。
- 分块计算(Tiling):通过将数据分块处理,减轻了内存压力,并使注意力计算更高效。
- 重计算策略:反向传播时不存储大型中间矩阵S和P,而是重计算,从而节省内存。
FlashAttention-2
- 算法调整减少非矩阵乘法FLOPs:通过减少非矩阵乘法操作来优化计算流程,提高专用硬件单元的效率。
- 并行计算注意力:在更多的线程块上并行化计算来提高GPU资源的占用率,提高计算效率。
- 工作分配优化:在每个线程块内部更智能地分配工作给线程束,减少线程束间的通信开销。
- FlashAttention 强调了在单个GPU上实现注意力计算的IO效率,通过分块计算和重计算来减少内存需求和提高效率。
- FlashAttention-2 在FlashAttention的基础上进一步改进,特别是在并行计算和线程束工作分配方面做了优化,以提高在处理长序列时的效率和吞吐量。
例如,如果将FlashAttention比作一辆提升了燃油效率的汽车,那么FlashAttention-2就像是在此基础上增加了涡轮增压器,进一步提升了性能。FlashAttention-2的主要改进在于更高效地使用GPU资源,减少了内存访问和同步操作,使得模型能够在更长的序列上更快地进行训练和推理,同时还能减少模型训练和使用时的资源消耗。