🚩🚩🚩Transformer实战-系列教程总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
1、SwinTransformer
- SwinTransformer 可以看作为一个backbone
- 用来做分类、检测、分割都是非常好的
- 也可以直接套用在下游任务中
- 不仅源码公开了,预训练模型也公开了
- 预训练模型提供大中小三个版本
图像中的像素点太多了,如果需要更多的特征就必须构建很长的序列
很长的序列会导致效率问题
SwinTransformer 针对ViT使用了窗口和分层的方式来替代长序列进行改进
CNN经常提起感受野,怎样在Transformer中体现出来呢?进行分层
SwinTransformer 怎样进行分层呢?在ViT或者原始Transformer中,假如最开始是400个Token,在堆叠过程中,还是会有400个Token。
而SwinTransformer 将原本的400个Token进行了合并处理,在堆叠过程中400个Token会变成200、100
也就是说SwinTransformer 就是在堆叠Transformer过程中,Token数量会不断减少,每一层的特征提取效率就会更高
2、网络架构
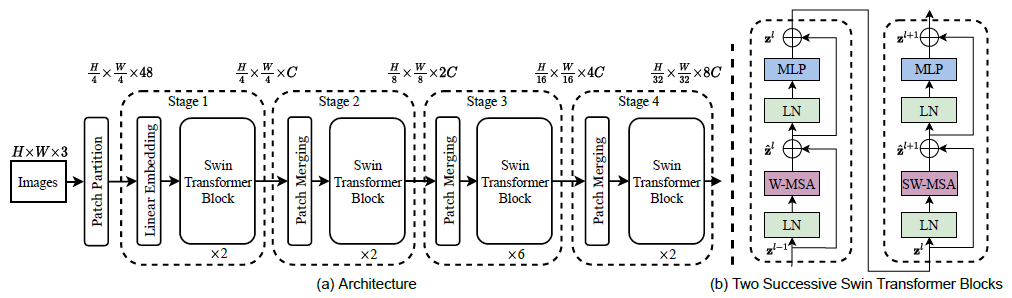
- 首先输入还是一张图像数据,2242243
- 通过卷积得到多个特征图,把特征图分成每个Patch,和ViT一样
- 堆叠Swin Transformer Block,与ViT 的Block不同的是,Swin Transformer
Block在每次堆叠后长宽减半特征图翻倍,这与CNN的堆叠过程有点类似,特别像VGG - 减少序列的长度,同时增加模型每一层的特征通道数,可以看作为是一个下采样的操作,是Patch Merging完成的
- Block最核心的部分是对Attention的计算方法做出了改进
3、Swin Transformer Block

- W-MSA与SW-MSA是一个组合
- W-MSA:基于窗口的注意力计算
- SW-MSA:窗口滑动后重新计算注意力
- 串联在一起就是一个Block
4、Patch Embbeding
- 输入:图像数据(224,224,3)
- 输出:(3136,96)相当于序列长度是3136个,每个的向量是96维特征
- 通过卷积得到,Conv2d(3, 96, kernel_size=(4, 4), stride=(4, 4))
- 3136也就是 (224/4) * (224/4)得到的,也可以根据需求更改卷积参数
5、window_partition
- 输入:特征图(56,56,96)
- 默认窗口大小为7,所以总共可以分成8*8个窗口
- 输出:特征图(64,7,7,96)
- 之前的单位是序列,现在的单位是窗口(共64个窗口)
56=224/4,5656分成每个都是77大小的窗口,一共可以的得到8*8的窗口,因此输出为(64,7,7,96),因此输入变成了64个窗口不再是序列了
6、W-MSA
W-MSA,Window Multi-head Self Attention
- 对得到的窗口,计算各个窗口自己的自注意力得分
- qkv三个矩阵放在一起了:(3,64,3,49,32)
- 3个矩阵,64个窗口,heads为3,窗口大小7*7=49,每个head特征96/3=32
- attention结果为:(64,3,49,49) 每个头都会得出每个窗口内的自注意力
原来有64个窗口,每个窗口都是77的大小,对每个窗口都进行Self Attention的计算
(3,64,3,49,32),第一个3表示的是QKV这3个,64代表64个窗口,第二个3表示的是多头注意力的头数,49就是77的大小,每头注意力机制对应32维的向量
attention权重矩阵维度(64,3,49,49),64表示64个窗口,3还是表示的是多头注意力的头数,49*49表示每一个窗口的49个特征之间的关系
7、window_reverse
- 通过得到的attention计算得到新的特征(64,49,96)
- 总共64个窗口,每个窗口7*7的大小,每个点对应96维向量
- window_reverse就是通过reshape操作还原回去(56,56,96)
- 这就得到了跟输入特征图一样的大小,但是其已经计算过了attention
attention权重与(3,64,3,49,32)乘积结果为(64,49,96),这是新的特征的维度,96还是表示每个向量的维度,这个时候的特征已经经过重构,96表示了在一个窗口的每个像素与每个像素之间的关系