目录
- 1 ChatGPT概述
- 1.1 what is chatGPT
- 1.2 How does ChatGPT work
- 1.3 The applications of ChatGPT
- 1.3 The limitations of ChatGPT
- 2 算法原理
- 2.1 GPT-1
- 2.1.1 Unsupervised pre-training
- 2.1.2 Supervised fine-tuning
- 2.1.3 语料
- 2.1.4 分析
- 2.2 GPT-2
- 2.3 GPT-3
- 2.4 InstructGPT (GPT-3.5孪生模型)
- 2.4.1 对齐技术
- 2.5 GPT-4
- 3 总结
- 4 参考
1 ChatGPT概述
1.1 what is chatGPT
ChatGPT (Generative Pre-Trained Transformer) 是由OpenAI团队与2022年11月基于GPT-3.5 (目前已经开放基于GPT-4的ChatGPT模型)开发出来的一个大语言聊天机器人模型。GPT基于Transformer模型结构,ChatGPT通过对输入的指令 (prompt) 来生成文本,更适应聊天机器人,客服等这类型对话应用。模型基于大量的对话语料进行训练,包括网站,书籍,社交媒体等文本语料,目前ChatGPT支持理解生成多种语言的文本,包括英语,中文,法语,德语等。
1.2 How does ChatGPT work
要了解ChatGPT是怎么工作的,首先我们需要来看下ChatGPT是怎么训练出来的,ChatGPT工作阶段主要有如下几个过程:
-
预训练 (Pre-training) 阶段
在预训练阶段,ChatGPT使用了来自互联网上的大规模的文本数据集进行训练,这些数据包含了广泛的内容:新闻,维基百科,书籍,网络文本信息等。预训练的目标是让ChatGPT学习自然语言的语法,语义以及常识知识。ChatGPT采样的是Transformer结构作为模型的基础,通过采用自注意力机制 (self-attention) 来捕捉输入序列中单词之间的关系,通过预训练过程,ChatGPT学会了上下文的理解以及句子结构等。在预训练过程中,ChatGPT通过自回归 (autoregressive) 的方式进行训练,通过将输入序列中的一部分作为上下文,预测下一个单词或者标记,通过这种方式,模型逐渐学习到了语言的统计规律和潜在的语义含义。 -
微调 (Fine-tuning) 阶段
在预训练完成后,ChatGPT需要经过微调来适应特定的任务或应用场景。微调阶段需要特定的对话数据集,这些数据集用于模型进行监督训练。在微调阶段,模型可以学习如何根据上下文生成连贯和有意义的回复,在微调的过程中通常会使用一些技术来引导模型的生成,比如加权重要性采样 (weighted importance sampling) 或使用特定的响应样本作为模型输出的参考。这些技术可以帮助改善模型生成的质量和准确性。 -
预测 (predict) 阶段
一旦ChatGPT完成了训练过程,输入一个指令或者一个问题,ChatGPT就可以生成像人类一样的回答。ChatGPT主要基于学到的知识以及对语言的理解进行生成回答,通过给定的上下文输入,ChatGPT从模型中的词汇概率分布中采用生成。ChatGPT可以提供有帮助的有信息的回答,但是毕竟是AI模型,还是可能存在生成不准确或者不可靠的信息。所以有时候需要从可靠的资源信息里确认模型生成的信息是否可靠。
1.3 The applications of ChatGPT
ChatGPT在许多领域有很多的应用,其中最常见的应用可以归纳如下:
- 客服问答:ChatGPT可以用来充当各种客服支持,与用户交互,帮助解决用户关于产品或者服务等相关问题。
- 个性化推荐:ChatGPT可以分析用户的偏好以及过去的一些交互来提供产品,电影,书籍或者音乐等个性化推荐。
- 语言翻译:ChatGPT可以提供实时的语言翻译,使得用户可以与说不同语言的人进行交流,打破语言障碍。
- 内容生成:ChatGPT可以协助产生各种不同目的的文本内容,比如写一篇文章,产品描述,社交媒体内容等,也可以产生有创意的建议,主题想法等帮助用户克服书写障碍。
- 教育协助:ChatGPT可以扮演一个虚拟的导师或者教育者助理,回答学生的问题,解释概念,提供各科的指导。
- 虚拟个人助理:ChatGPT可以扮演一个虚拟的个人助理,帮助用户管理他们的行程,设置提醒,做预订,找信息等。
- 心理健康支持:ChatGPT可以提供个人心理健康问题的一些指导和支持,可以提供信息,方案以及富有同情心的协助用户处理压力,焦虑或者沮丧情绪。但是,ChatGPT并不能代替专业的心理健康咨询师。
上面只是大概举出了一些常见的应用,ChatGPT可以在很多场景中发挥作用。在使用ChatGPT,我们可能需要监控ChatGPT的偏见,保护用户的隐私以及确保透明度等问题。
1.3 The limitations of ChatGPT
ChatGPT有很多益处和应用,但是它也有一些限制,如下是目前ChatGPT的一些问题:
- 缺乏真实世界的知识:ChatGPT对实时信息以及知识是没法获取的,它的知识受限于训练数据,所以导致对最新的一些事件,新闻等信息是没有感知的。
- 没有校验信息的能力:ChatGPT可以提供信息以及回复,但是它没有能力去校验它产生信息的真实性和准确性。所以在一些关键或者敏感信息,要是从模型中获取,进行事实性的校验是很重要的。
- 信息冗余:ChatGPT有时候会产生较长的或者过于详细的细节内容,这样的回答并不是总是有必要,有时候会导致不那么相关或者有必要。ChatGPT并不总是优先考虑简明扼要的回答。
- 缺乏长期的上下文和记忆信息:在一定程度上,ChatGPT不会保持之前较长时间的对话信息。ChatGPT将用户的每个query当做独立的,所以并不会记得之前的对话详细的信息。这样会导致不连贯以及重复回答的问题。
- 对输入的短语或者prompt敏感:问问题的方式或者prompt如何构造的都会对ChatGPT的回答结果影响较大。即使对相似的query只是短语构成或者prompt稍微不一样,ChatGPT可能产生不一样的回答。
- 偏见问题:由于ChatGPT是语言模型,从之前的训练数据学习知识,若训练数据本身存在偏见问题,ChatGPT产生的答案有时候也会带来偏见。
所以,我们可以把ChatGPT当做一个提供信息和协助的工具,能够意识到ChatGPT的局限性,对ChatGPT提供的回答需要做严格的评估。
2 算法原理
2.1 GPT-1
Improving Language Understanding by Generative Pre-Training
2018年发表,训练数据40GB,模型参数大小1.3B。
2.1.1 Unsupervised pre-training
基于大量的语料进行无监督学习,无监督学习建模目标如下:
给定无监督语料的上下文tokens
U
=
{
u
1
,
u
2
,
.
.
.
,
u
n
}
U=\{u_1,u_2,...,u_n\}
U={u1,u2,...,un},使用标准的语言模型目标函数是最大化如下似然函数:
L
1
(
U
)
=
∑
i
log
P
(
u
i
∣
u
i
−
k
,
.
.
.
,
u
i
−
1
;
θ
)
L_1(U) = \sum_i \log P(u_i|u_{i-k},...,u_{i-1};\theta)
L1(U)=i∑logP(ui∣ui−k,...,ui−1;θ)
其中
k
k
k表示的是文本窗口大小,条件概率
P
P
P是一般是由参数为
θ
\theta
θ的神经网络建模预测得到。而在GPT-1算法里,使用的是多层Transformer decoder 作为语言模型,这个模型对输入的上下文tokens通过使用multi-head的self-attention产生目标tokens的向量表征:
h
0
=
U
W
e
+
W
p
h_0 = UW_e + W_p
h0=UWe+Wp
h
l
=
t
r
a
n
s
f
o
r
m
e
r
b
l
o
c
k
(
h
l
−
1
)
∀
i
∈
[
1
,
n
]
h_l = transformer_{block}(h_{l-1}) \forall i \in [1,n]
hl=transformerblock(hl−1)∀i∈[1,n]
P
(
u
)
=
s
o
f
t
m
a
x
(
h
n
W
e
T
)
P(u) = softmax(h_nW_e^T)
P(u)=softmax(hnWeT)
其中
U
=
(
u
−
k
,
.
.
.
,
u
−
1
)
U = (u_{ -k}, ...,u_{-1})
U=(u−k,...,u−1)是上下文tokens的索引向量,
n
n
n代表模型层数,
W
e
W_e
We是tokens向量矩阵,
W
p
W_p
Wp是位置向量矩阵。
2.1.2 Supervised fine-tuning
基于上述的pre-train训练完后,接下来就是基于有标签的数据进行fine-tune。每一个样本由输入序列
x
1
,
.
.
.
,
x
m
{x^1,...,x^m}
x1,...,xm以及对应的标签
y
y
y组成,输入经过我们Pre-trained的模型获得最后的transformer block提取的向量
h
l
m
h_l^m
hlm,然后将其输入到一层参数为
W
y
W_y
Wy的线性输出层预测
y
y
y值:
P
(
y
∣
x
1
,
.
.
.
,
x
m
)
=
s
o
f
t
m
a
x
(
h
l
m
W
y
)
P(y|x^1,...,x^m) = softmax(h_l^mW_y)
P(y∣x1,...,xm)=softmax(hlmWy)
目标函数是最大化如下函数:
L
2
(
C
)
=
∑
(
x
,
y
)
l
o
g
P
(
y
∣
x
1
,
.
.
.
,
x
m
)
L_2(C) = \sum_{(x,y)}logP(y|x^1,...,x^m)
L2(C)=(x,y)∑logP(y∣x1,...,xm)
论文中发现加入语言模型建模作为辅助任务有利于提升fine-tune阶段的模型的泛化能力以及加速模型的收敛速度。所以,在fine-tune阶段,加入了语言模型的学习辅助任务,所以最终的目标函数如下:
L
3
(
C
)
=
L
2
(
C
)
+
λ
×
L
1
(
C
)
L_3(C) = L_2(C) + \lambda \times L_1(C)
L3(C)=L2(C)+λ×L1(C)
在Fine-tune阶段,我们只需要fine-tune的参数是
W
y
W_y
Wy以及分隔符tokens的词向量。整体结构如下所示:
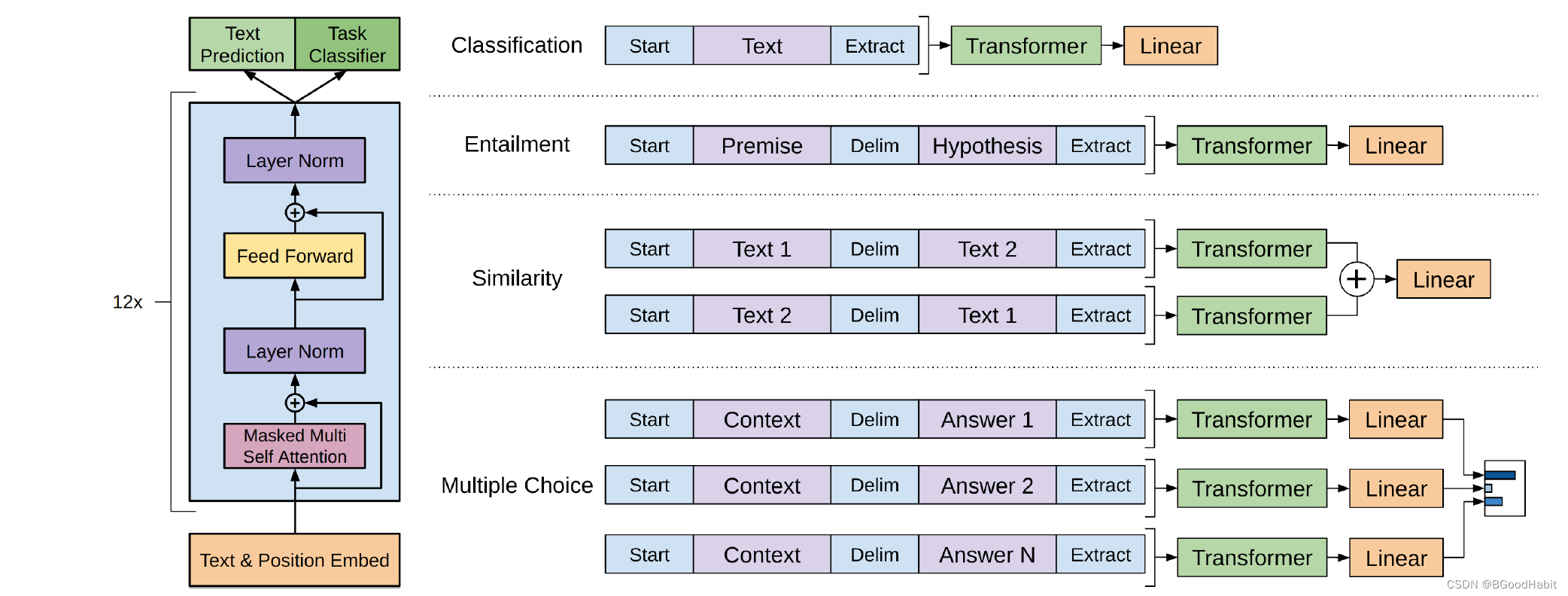
其中fine-tune过程的任务有文本分类,语言推理,句子相似性,问答任务,如上图所示,详细细节如下:
-
Natural Language Inference (NLI): 也被称为文本蕴涵识别,任务旨在评估计算机系统对于理解和推断自然语言文本之间关系的能力。具体而言,NLI 要求系统阅读一对句子(通常是前提和假设),并判断这两个句子之间的关系,这个关系通常被归为三类:
蕴涵(Entailment): 如果一个句子的意义包含在另一个句子中,那么这两个句子之间存在蕴涵关系。
矛盾(Contradiction): 如果一个句子的意义与另一个句子的意义相矛盾,那么这两个句子之间存在矛盾关系。
中性(Neutral): 如果两个句子之间没有蕴涵关系,也没有矛盾关系,那么它们被认为是中性的,即彼此之间的关系是中立的。
NLI 是自然语言处理领域中一个重要的任务,它涉及到语义理解和推理,对于许多应用,如问答系统、机器翻译和对话系统等,都具有关键性的作用。 -
Question answering and commonsense reasoning:
Question Answering (QA): 问题回答任务旨在使计算机系统能够理解和回答自然语言中提出的问题。这包括阅读理解任务,其中系统需要从给定的文本中提取信息来回答问题,以及开放领域的问答任务,其中系统需要回答用户提出的任意问题。
Commonsense Reasoning: Commonsense reasoning 是指计算机系统理解和应用常识知识来推理和解决问题的能力。这涉及到对于日常情境和人类行为的理解,而这些情境和行为可能在文本中没有直接提及,但是基于常识知识可以进行推断。 -
Semantic Similarity: 预测两个句子是否是语义等同,这一概念涉及到对语言意义的理解,而不仅仅是表面的语法结构。
-
Classification: 文本分类任务是比较常见的,论文基于两种不同的语料库进行了两种文本分类任务。一种是基于CoLA语料库判断一个句子是不是语法正确的,另外一个分类任务是基于SST-2语料库的情感分类。
2.1.3 语料
无监督学习的训练语料来自BooksCorpus dataset书籍语料库文本信息,包括冒险,科幻,浪漫等题材7000多本书籍。
2.1.4 分析
论文对比了几种试验变量的效果对比,整体试验结论如下:
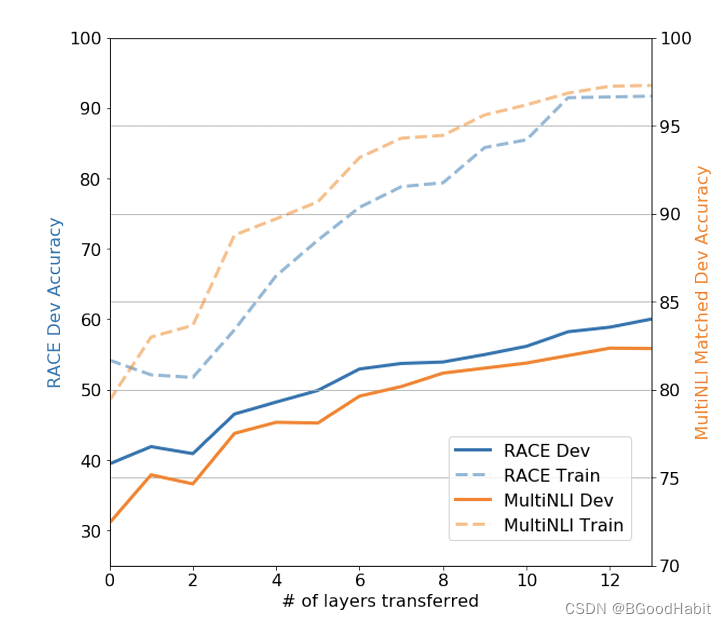
-
在fine-tune阶段,将pre-train阶段学习的模型层数参数迁移越多效果越好
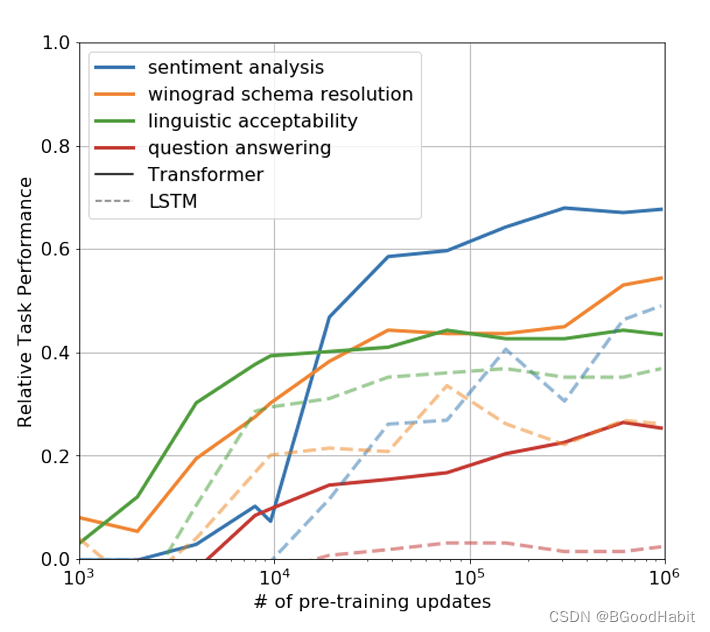
-
生成性预训练有效性验证
论文给出了只用pre-training的模型观察试验效果的表现,发现预训练模型在训练过程中预测也稳步增加,表明生成性预训练支持学习广泛的与任务相关的功能,试验结果如下:
2.2 GPT-2
Language Models are Unsupervised Multitask Learners
2019年发表,GPT-2有1.5B (billion 十亿)也就是15亿的参数,训练样本40G。从paper内容来看,GPT-2相比GPT核心变化点如下:
-
训练数据重点是来自网上高质量信息,包含了45 million个链接,抽取了800w的文本,大概有40G的文本量。
-
论文中探测了训练集与测试集重合度对模型表现的影响。论文提出了Bloom filters,给定一个数据集,通过计算8-grams与WebText数据集的重合比率来判断测试集和训练集重合度情况
-
证明了预训练模型不做进一步有监督的调整在具体的任务中也可以取到不错的效果,基于无监督的pre-train学习是一个很值得探索的一个研究领域。
2.3 GPT-3
Language Models are Few-Shot Learners
2020年发表,训练数据数十TB数据,模型参数大小175B。如下是论文作者公开训练GPT-3的数据来源:
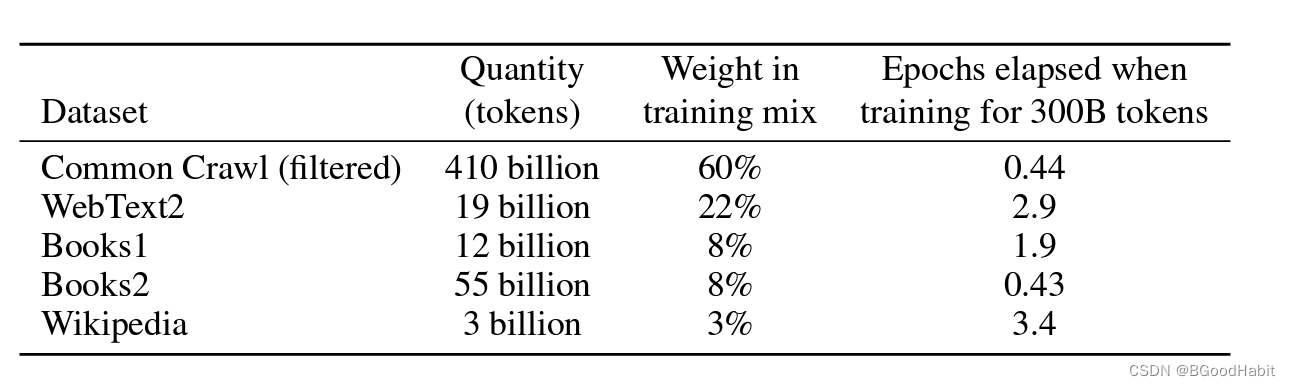
其中最主要数据来源是Common Crawl数据。
在GPT-3论文中,作者给出了一些一些比较有意思的试验发现。
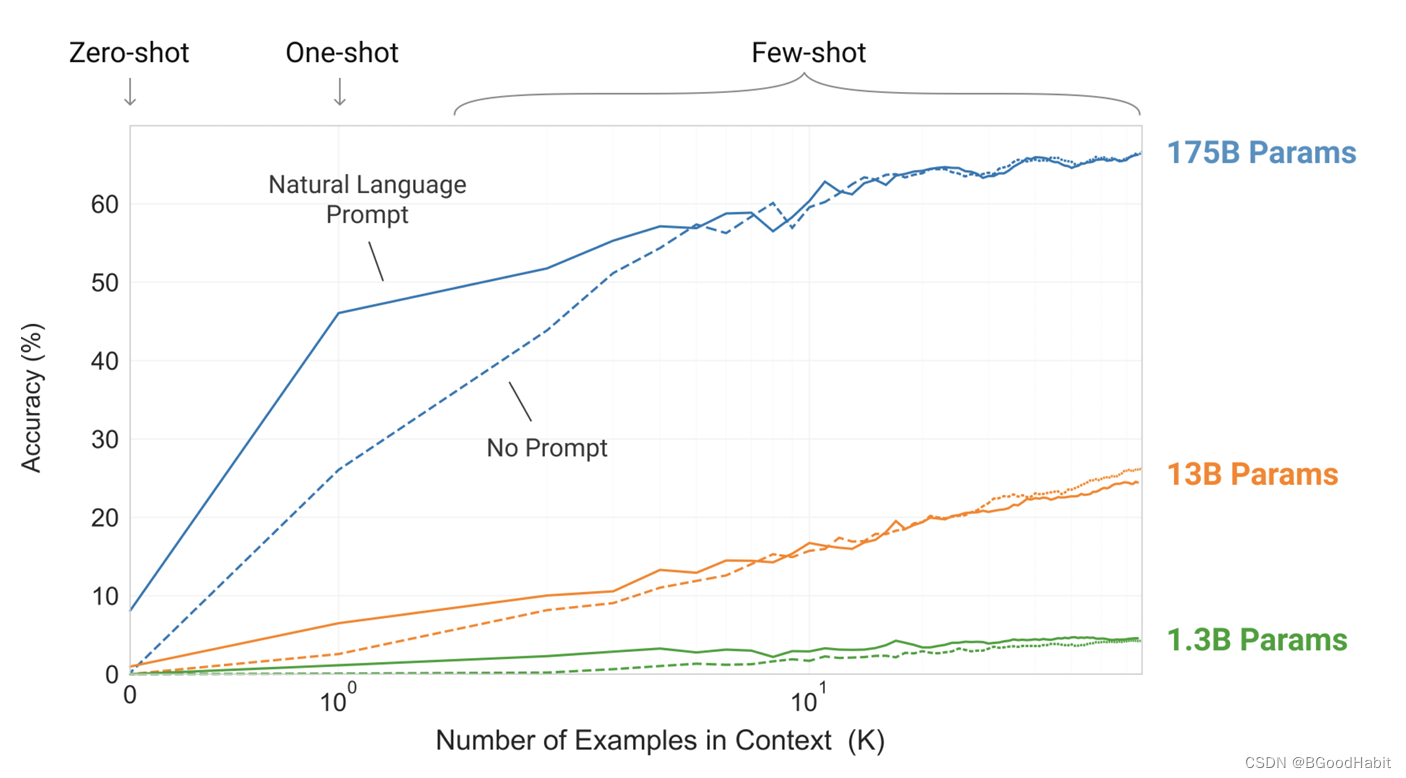
-
模型越大,对于in-context learning效果越明显,如下图所示:
-
模型越大,对于few-shot学习效果增速更快,如下图所示:
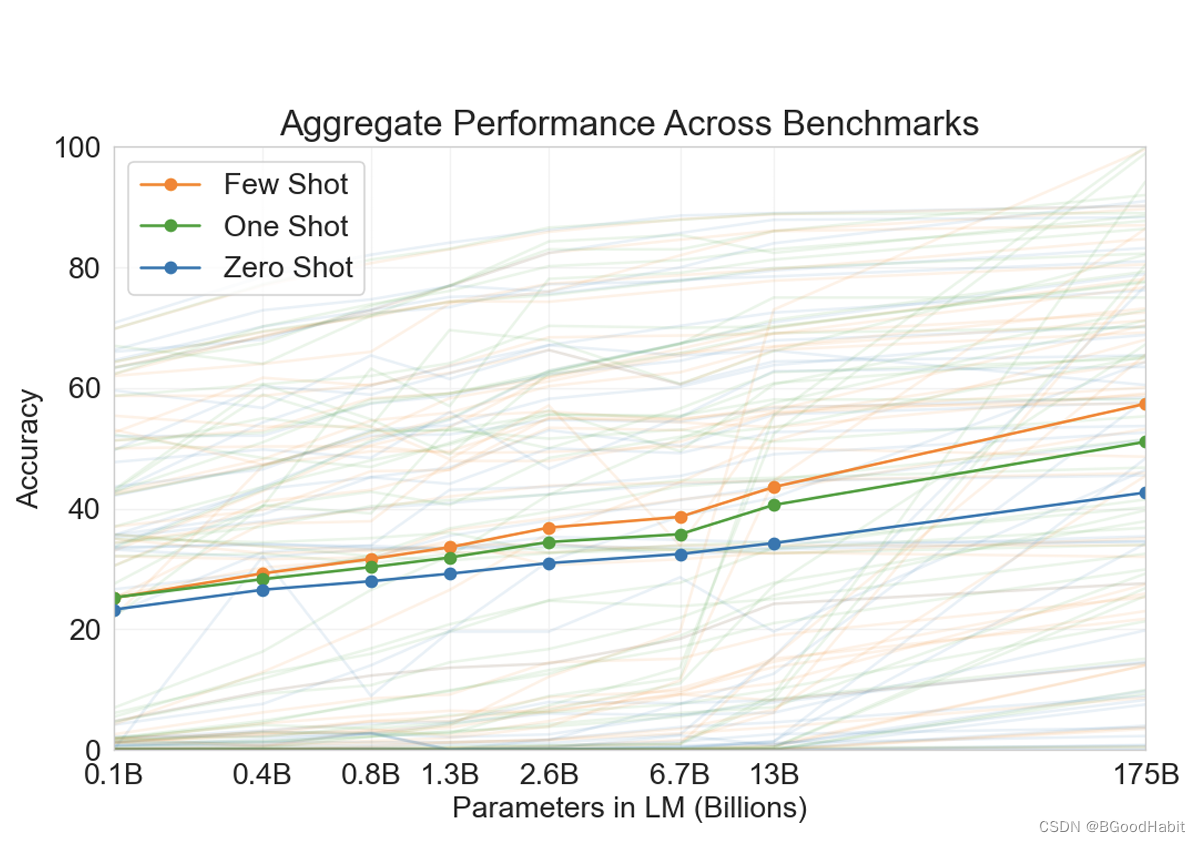
如下是对few-shot, one-shot, zero-shot学习的一个示例图:

few-shot学习通过给模型一些例子进行推测,但不更新模型的参数,few-shot学习最主要的优点是可以减少了对任务特定数据的需求,并降低了从大而狭窄的微调数据集中学习过于狭隘分布。
数据清洗(Common Crawl Filtering):
数据主要来自网上数据,所以需要对数据质量进行清洗,论文作者给出了几个方案:
-
生成一个自动过滤低质量文本器,训练一个能够判断文档是高质量还是低质量文本的分类器
(正样本是:WebText,Wikiedia,and our web books corpu,负样本: unfiltered Common Crawl)
特征使用Spark’s standard tokenizer and HashingTF。
基于帕累托分布采样如下: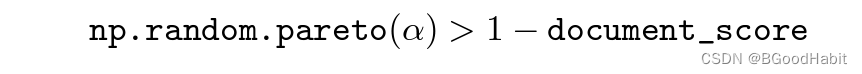
其中a=9。 -
为了加强模型的鲁棒性避免模型过拟合,作者将文档与其它文档重合度高的进行删除,使用spark中的MinHashLSH进行判别,同时将WebText内容从CommonCrawl库中删除。
2.4 InstructGPT (GPT-3.5孪生模型)
Training language models to follow instructions with human feedback
在openAI的官网里面,写了这一段内容:
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
所以可以看出chatgpt(gpt-3.5)与InstructGPT是一对孪生姐妹模型,训练方式和模型结构完全一致,只是在采集训练数据的时候不一样。
相比上述的GPT-1,GPT-2, GPT-3,论文摘要里就指出无监督的大语言模型给出的结果存在不真实以及对用户无用的回答等,所以在InstructGPT用不同任务的有监督数据对GPT-3进行fine-tune,同时用用户的反馈基于强化学习对模型进一步fine-tune。论文指出经过fine-tune只有1.3B参数InstructGPT比175B参数的GPT-3效果好,虽然参数少了100倍多。作者给出的结论是:基于用户反馈对大模型进行fine-tune是一个很用潜力值得研究的方向。
如下图是各模型的对比结果:
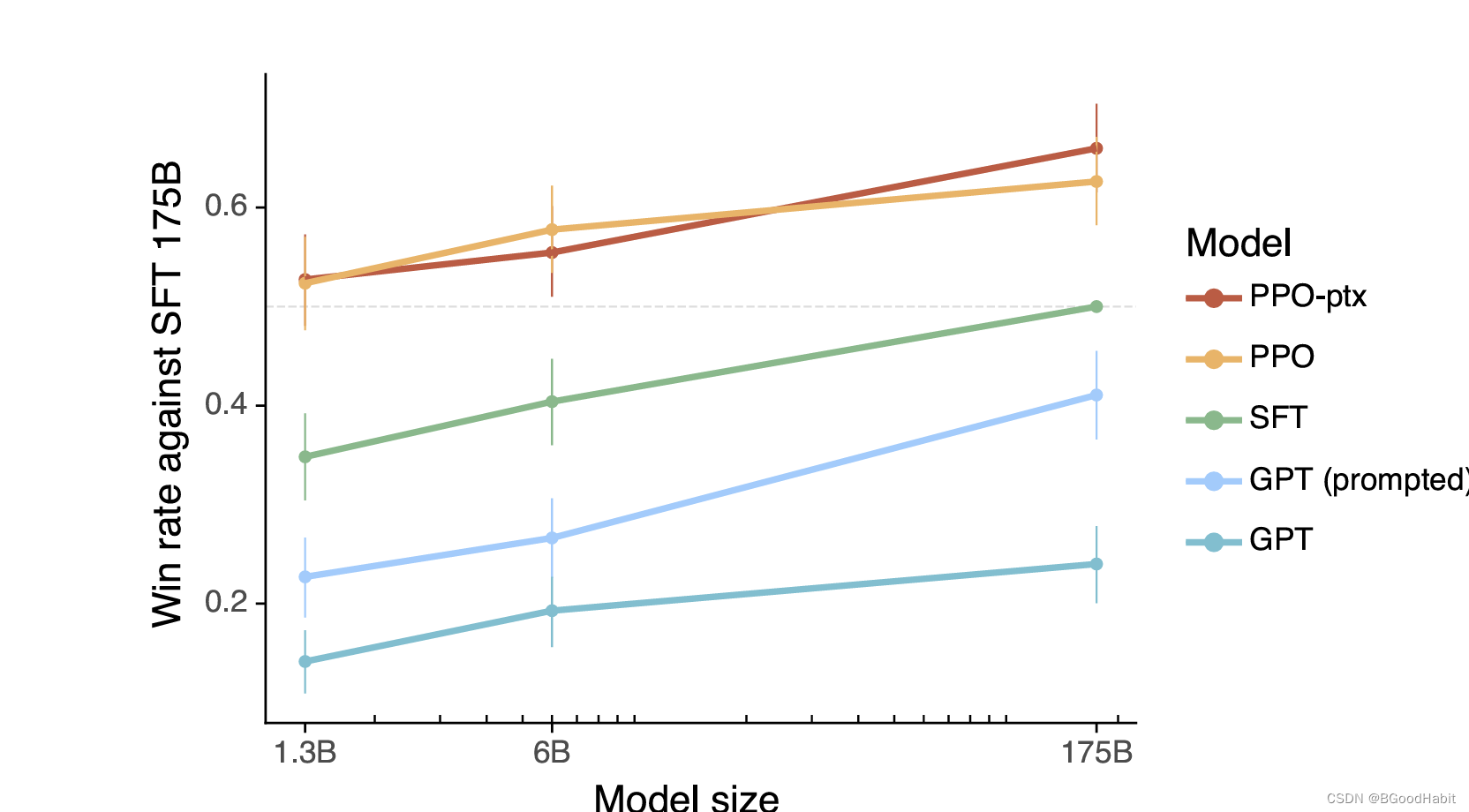
其中GPT, GPT(prompted)都是基于GPT-3作为baseline,SFT (175B的GPT-3进行Supervised Fine-Tune)。PPO-ptx (InstructGPT),PPO (无pretrain)。
如下是论文给出的训练模型流程步骤说明:
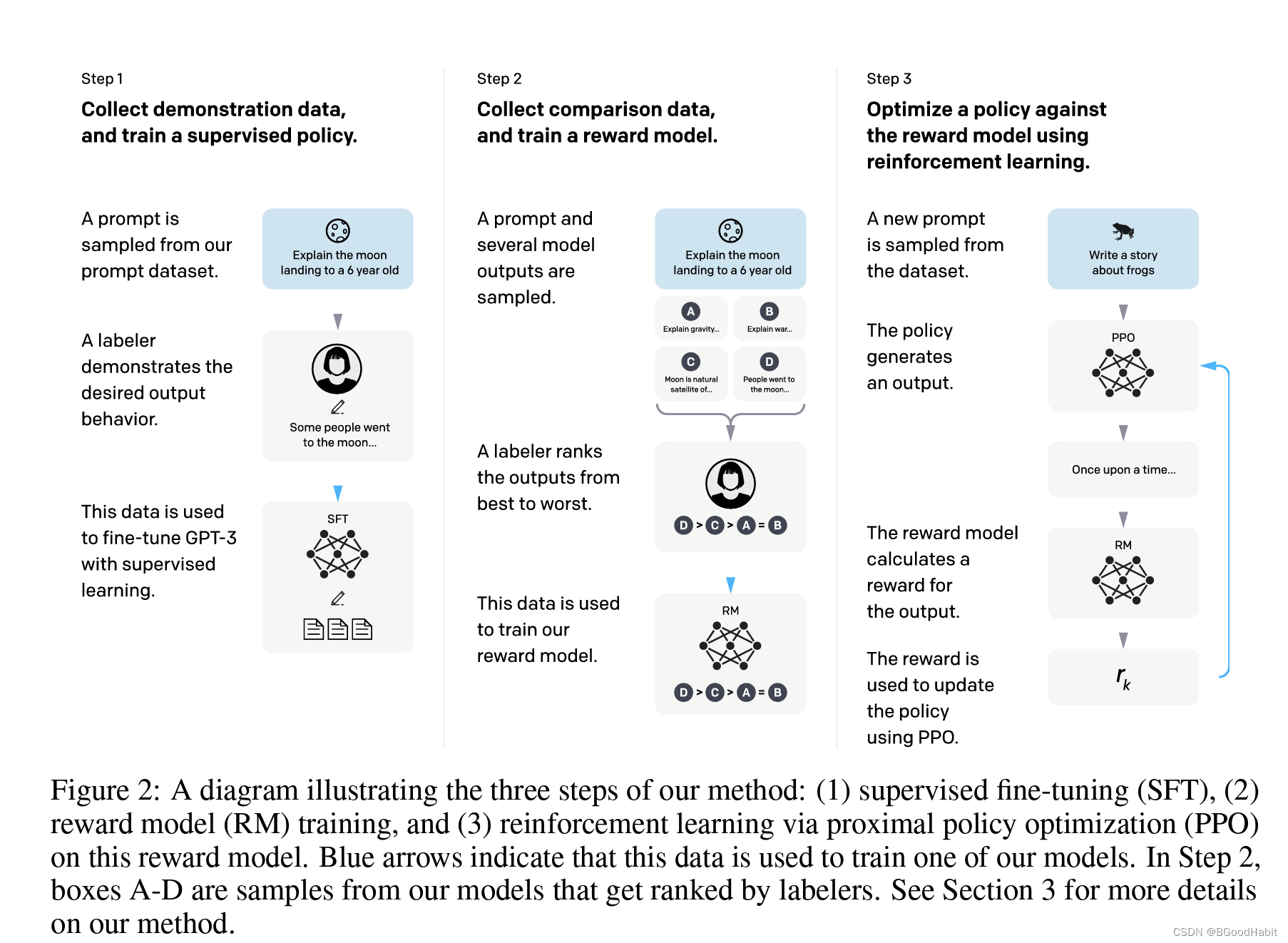
论文也给出了试验中的一些发现和总结如下:
-
InstructGPT比GPT-3在答案的真实性上有提高
-
通过修改我们的RLHF(Reinforcement Learning with Human Feedback)微调,可以最小化在公共自然语言处理数据集上的性能退化
-
尽管instructions与在RLHF微调阶段的分布不一样,InstructGPT也表现出很强的范化能力,这表明模型能够根据"给的instruction"自己产生出一些概念。
-
InstructGPT也会犯一些小的错误
训练InstructGPT的流程如下:
Step 1:用人工标注的数据在预训练GPT-3上进行fine-tune。
Step 2:对多个模型输出的结果(选择模型个数K=4,K=9),用标注人员对其模型产出结果排序,然后训练一个奖励模型预测两两对比的效果,具体一点的奖励模型的损失函数如下:
l
o
s
s
(
θ
)
=
−
1
(
2
k
)
E
(
x
,
y
w
,
y
l
)
∼
D
[
l
o
g
(
σ
(
r
θ
(
x
,
y
w
)
−
r
θ
(
x
,
y
l
)
)
)
]
loss(\theta)=-\frac{1}{(^k_2)}E_{(x,y_w,y_l)} ∼D[log(\sigma(r_{\theta}(x,y_w)-r_{\theta}(x,y_l)))]
loss(θ)=−(2k)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
其中
r
θ
(
x
,
y
)
r_{\theta}(x,y)
rθ(x,y)是奖励模型对于prompt x以及基于
θ
\theta
θ参数的模型y,对于pair对
y
θ
y_{\theta}
yθ以及
y
w
y_w
yw,其中
y
w
y_w
yw是更高的排序输出。D是基于人对比出来的数据集。
Step 3:使用PPO (Proximal Policy Optimization) 算法优化策略。

从论文研究中,作者给出了一些工作结论如下:
- 提升模型对齐的能力相对于预训练而言是适度的。作者还指出,RLHF(Reinforcement Learning from Human Feedback)使语言模型对用户更有帮助方面非常有效,尤其是相对于模型尺寸增加超过100倍。这表明目前增加对现有语言模型的对齐性投资相对于培训更大模型而言更具成本效益。
- 试验也表面,InstructGPT能够将“遵循指令“范化到没有进行监督学习过的任务中。比如,能够在非英语任务以及编程任务进行学习。这是非常重要的,因为在每个任务中都获得人类反馈数据是十分昂贵的。需要更多的研究去学习当一个模型的能力越来越强的时候,如何提升模型的范化能力。
- 论文验证了来自研究的对齐技术。在机器学习和人工智能领域,"对齐技术"通常指的是一系列方法和策略,旨在确保训练出的模型的行为与人类期望一致,以及符合一定的价值观和规范。这是为了使机器学习模型更好地适应实际应用场景和用户需求。对齐研究历来相对抽象,主要集中在理论结果、小规模合成领域或在公共NLP数据集上训练ML模型。论文中的工作为在17个真实世界客户中投入生产使用的AI系统的对齐研究提供了基础。这使得对这些技术的有效性和局限性有了一个重要的反馈循环。
2.4.1 对齐技术
通常对齐技术是将模型产出的结果更加符合人的偏好。在论文工作中,给出的对齐尝试如下:
- 直接基于标注者标注结果对模型进行fine-tune,但是发现标注者在很多标注样本中表现出了不一致的结论。
- 基于标签的说明,然后让标注者根据说明准则选择一个他们偏好的一个结果。然后大家会集中一个聊天室中,关于边缘问题进行回答说明。
- 训练数据是由OpenAI客户通过OpenAI API Playground发送给模型的提示确定的,因此在隐性地对齐于客户认为有价值的内容
- penAI的客户并不能代表所有潜在或当前语言模型用户,更不能代表所有受语言模型使用影响的个人和群体。在这个项目的大部分时间里,使用OpenAI API的用户是从等待列表中选择的。等待列表的初始种子是OpenAI的员工,使最终的用户群体偏向整个网络群体。
总而言之,设置一个公平、透明,并且合适的问责机制的对齐过程是十分困难的。这篇论文的目标是展示这种对齐技术可以与特定人类参考群体在特定应用中保持一致。
2.5 GPT-4
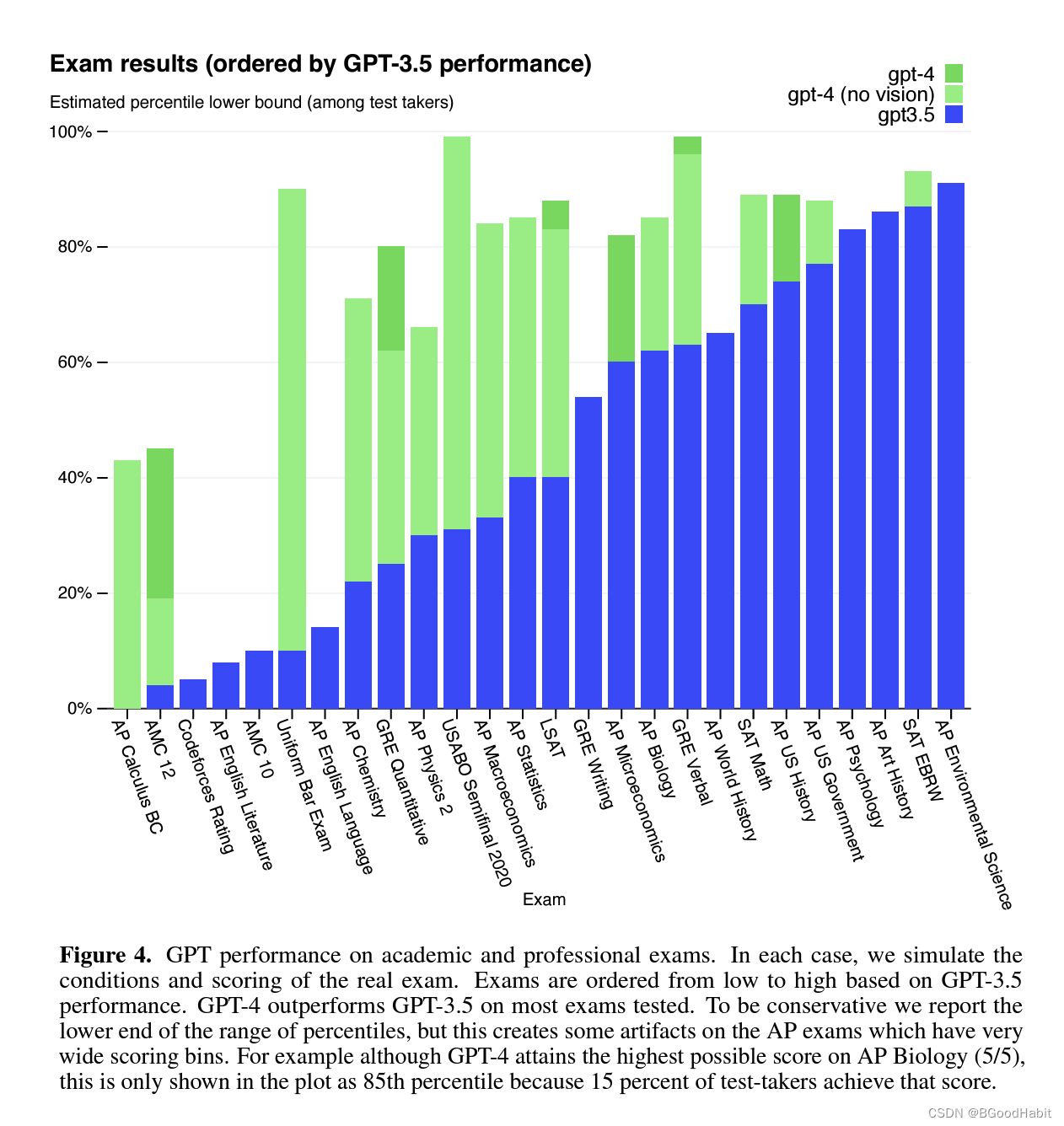
GPT-4 Technical Report 升级GPT-4没有在训练数据集以及模型结构和大小上公开,但是作为一个多模态模型,可以接收文本和图片信息然后产出文本信息。从论文试验结果看出GPT-4在很多的测试任务中,都比GPT-3.5效果好,如下是一个试验数据对比:
在GPT-4中,作者给出了用GPT-4基础版与GPT-4经过强化学习后的性能在基准测试中的比较。基础模型的平均分数为73.7%,而经过强化学习后的模型的平均分数为74.0%,发现经过强化学习训练并未显著改变基础模型的能力 (在GPT-3.5中RLHF却效果显著啊),试验数据如下: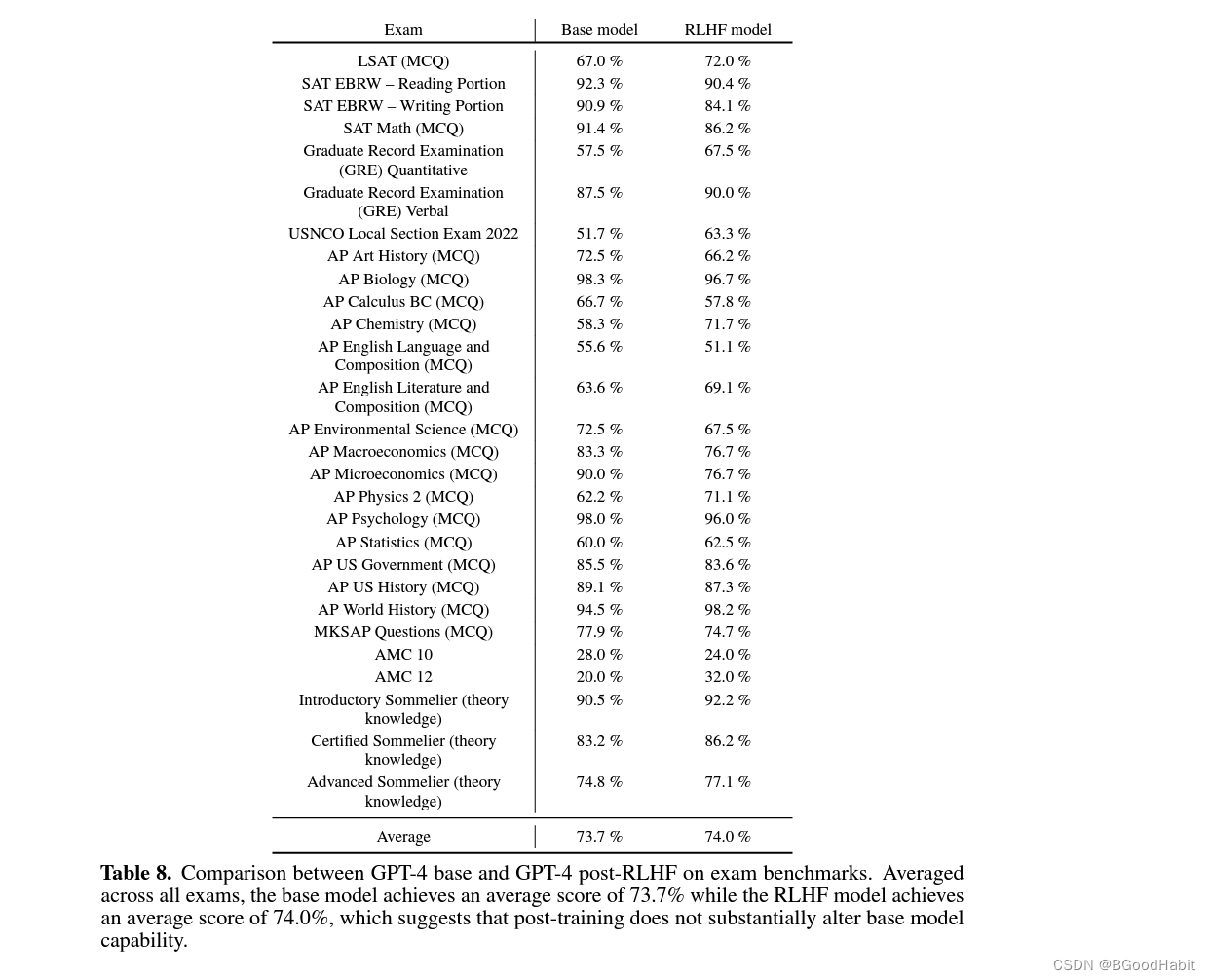
GPT-4显示出了很强的图片理解能力,如下例子所示:

也能够很好的解读pdf内容:

3 总结
| 模型 | 发表年份 | 模型参数 | 训练数据 | 主要改进点 |
|---|---|---|---|---|
| GPT-1 | 2018 | 1.3B | 40GB | 引入了Transformer模型,并使用自回归生成的方式进行预训练 |
| GPT-2 | 2019 | 1.5B | 40GB | 增加了模型规模,引入了更多的参数,提高训练文本的质量 |
| GPT-3 | 2020 | 175B | 数十TB | 在规模上进一步提升,引入了更多的参数,并采用了更多的数据进行训练 |
| GPT-3.5 | 2022 | 175B | 数十TB | 引入用户反馈的强化学习(RLHF)进行微调 |
| GPT-4 | 2023 | 未公开 | 未公开 | 未公开 |
4 参考
How ChatGPT actually works
How does Chat GPT work?
Proximal Policy Optimization (PPO)
Chatbots to ChatGPT in a Cybersecurity Space
Scaling Laws for Neural Language Models
Emergent Abilities of Large Language Models
Proximal Policy Optimization Algorithms



![[UI5 常用控件] 07.SplitApp,SplitContainer](https://img-blog.csdnimg.cn/direct/a77ffd635cea4e7288af2840a7d5cbfd.png)