机器学习100天,今天讲的是:K 折交叉验证!
《机器学习100天》完整目录:目录
机器学习中,我们常会遇到一个问题,就是超参数的选择,超参数就是机器学习算法中的调优参数,比如上一节 K 近邻算法中的 K 值。K 折交叉验证就是帮助我们选择最优的超参数。
首先,介绍一下简单交叉验证。简单交叉验证就是将原始数据集随机划分成训练集和验证集两部分。例如将样本按照 70%~30% 的比例分成两部分,70% 的样本用于训练模型;30% 的样本用于模型验证。
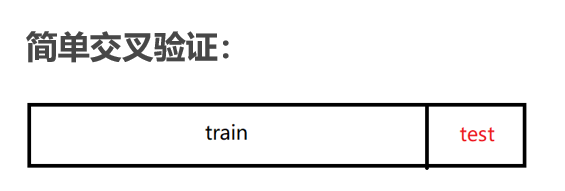
简单交叉验证有两个缺点:(1)数据都只被所用了一次,没有被充分利用;(2)验证集上的效果与原始分组有很大关系。
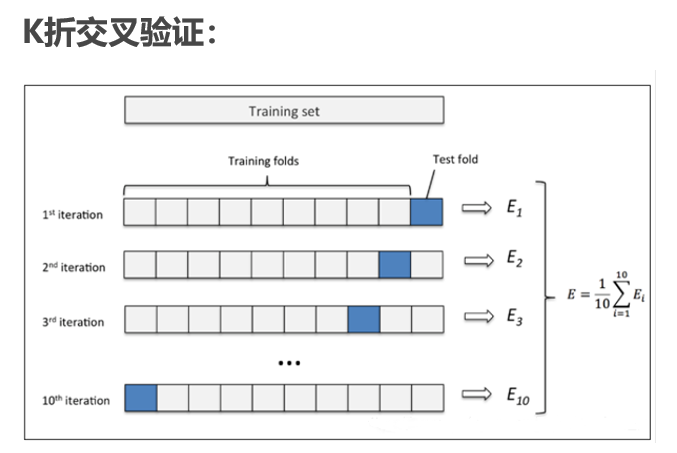
K 折交叉验证是简单交叉验证的升级。如下图所示,它的做法是:
- 1、首先,将全部样本划分成 K 个大小相等的子集,例如 k=10;
- 2、依次遍历这 K 个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;
- 3、最后把 K 次评估指标的平均值作为最终的评估指标。
需要特别注意的是