原文链接:https://arxiv.org/abs/2312.14919
1. 引言
多模态融合时,由于不同模态有不同的过拟合和泛化能力,联合训练不同模态可能会导致弱模态的不充分利用,甚至会导致比单一模态方法性能更低。
目前的相机-激光雷达融合方法多基于Lift-Splat,即基于深度估计投影图像特征到BEV,再与激光雷达特征融合。这高度依赖深度估计的质量。本文发现深度估计不能为这些模型带来帮助,因为实验表明当深度估计被替换为激光雷达提供的深度,或是完全移除时,模型的性能相同。这表明深度估计是不必要的,可以将Lift-Splat方法替换为更有效的投影机制。
本文提出Lift-Attend-Splat方法,绕过单目深度估计,使用Transformer选择和融合相机与激光雷达特征。相比基于深度估计的方法,本文的方法能更好地利用相机,且能提高性能。
3. Lift-Splat中的单目深度估计
Lift-Splat使用单目深度估计将图像特征投影到BEV:
Proj
Lift-Splat
=
Splat
(
F
′
c
a
m
⊗
D
)
\text{Proj}_\text{Lift-Splat}=\text{Splat}(F'^{cam}\otimes D)
ProjLift-Splat=Splat(F′cam⊗D)
其中 F ′ c a m ∈ R C c × H × W F'^{cam}\in\mathbb{R}^{C_c\times H\times W} F′cam∈RCc×H×W为从图像特征 F c a m ∈ R C × H × W F^{cam}\in\mathbb{R}^{C\times H\times W} Fcam∈RC×H×W得到的上下文特征, D ∈ R N D × H × W D\in\mathbb{R}^{N_D\times H\times W} D∈RND×H×W为在预定义深度区间上的归一化分布,Splat表示将点投影到 z = 0 z=0 z=0平面上的过程。得到的特征图会与激光雷达特征图拼接或使用门控注意力融合。注意此处将深度估计视为分类问题,从下游任务学习而无显示深度监督。
Lift-Splat深度预测通常较差:通过比较BEVFusion中预测的深度与激光雷达深度图,本文发现深度预测结果不能精确反映场景结构,与激光雷达的深度图明显不同。
促进深度预测不能提高检测性能:进一步探索提高深度估计效果能否提高检测性能。引入激光雷达深度作为深度监督(交叉熵损失)。实验表明,这样做确实可以提高深度估计的效果,但检测性能却随着增大深度损失的权重而降低。这表明模型不能利用更精确的深度估计。本文还进行了两个实验:使用预训练的深度预测模块,以及直接使用激光雷达点云以绕过深度估计模块。前者同样能提高深度估计精度,但降低检测性能;后者和基准方案的性能相当,尽管深度估计的指标全部接近0。
移除深度估计不影响检测性能:上述实验表明基于Lift-Splat的方法不能利用精确的深度。完全移除单目深度估计,将投影公式变为:
Proj
no-depth
=
Splat
(
F
′
c
a
m
⊗
1
)
\text{Proj}_\text{no-depth}=\text{Splat}(F'^{cam}\otimes 1)
Projno-depth=Splat(F′cam⊗1)
其中 1 1 1与 D D D的大小相同,其所有值都是1。实验表明,这一方法不会降低性能,这表明深度估计不是该方法的关键部分。这可能是由于激光雷达的存在,使得单目深度的重要性大大降低,因为激光雷达的深度信息更加精确,模型容易抑制错误的投影位置。因此,依赖单目深度估计是不必要的,且会导致相机的不充分利用。
4. 无单目深度估计的相机-激光雷达融合
本文使用简单的Transformer,绕过单目深度估计得到BEV表达。全局Transformer有较大的计算量,因此本文利用几何关系来限制注意力的范围,因为相机特征仅影响其相应射线上的位置。具体来说,本文在图像列与激光雷达BEV网格极射线之间使用交叉注意力,可以为激光雷达特征学习到最相关的图像特征。
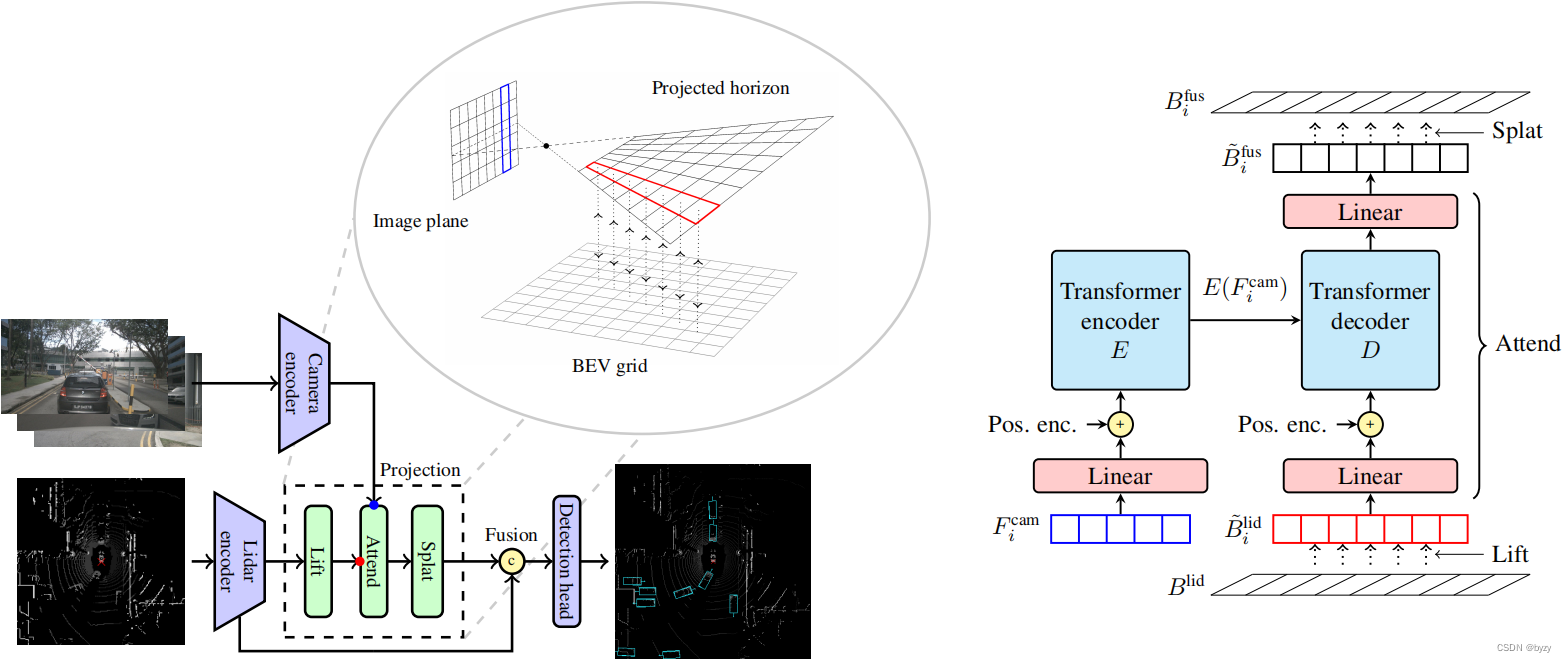
除了投影方式外,本文的方法与Lift-Splat相似,如上图所示。模型包含相机与激光雷达主干、投影与融合模块、以及检测头。
投影水平面:对每个相机,本文考虑穿过图像中心的水平线及其相应的水平面,称为投影水平面。可以使用齐次坐标表达点
x
∈
R
4
x\in\mathbb{R}^4
x∈R4的集合,且存在
u
∈
R
u\in\mathbb R
u∈R满足
C
x
∼
(
u
,
h
/
2
,
1
)
Cx\sim(u,h/2,1)
Cx∼(u,h/2,1)
其中 C C C为 3 × 4 3\times4 3×4相机投影矩阵(内外参), h h h为图像高度。注意该平面不与BEV平面严格平行,取决于相机外参。在投影水平面上,通过追踪水平线和特征列边缘交点对应的相机射线,并预先设置深度区间,划分为规则的网格 G ∈ R N D × W G\in\mathbb{R}^{N_D\times W} G∈RND×W,其中每行对应图像特征的一列,如图所示。
投影水平面与BEV网格的对应关系:通过沿 z z z轴投影,容易定义投影水平面与BEV平面的对应关系。通过一个平面网格中心向另一个平面投影并进行特征的双线性采样,可以将激光雷达特征从BEV网格转换到相机投影水平面(称为“Lift”),或是反过来将图像投影水平面的特征转换到BEV(称为“Splat”)。
Lift-Attend-Splat:本文的投影模块如上右图所示,可以分为3步:(i)将BEV激光雷达特征
B
lid
B^\text{lid}
Blid提升到相机
i
i
i的投影水平面上,得到“提升的”激光雷达特征
B
~
i
lid
\tilde B_i^\text{lid}
B~ilid;(ii)将“提升的”激光雷达特征与图像的相应列通过Transformer编码器-解码器进行注意力交互,产生投影水平面上的融合特征
B
~
i
fus
\tilde B_i^\text{fus}
B~ifus;(iii)将得到的特征splat回BEV,得到
B
i
fus
B_i^\text{fus}
Bifus。在注意力步骤,图像各列的特征会被Transformer编码器
E
E
E编码,然后作为键与值输入到Transformer解码器
D
D
D中,查询为视锥激光雷达特征。可将上述步骤写为:
B
i
fus
=
Splat
i
(
D
(
Lift
i
(
B
lid
)
,
E
(
F
i
cam
)
)
)
B_i^\text{fus}=\text{Splat}_i(D(\text{Lift}_i(B^\text{lid}),E(F_i^\text{cam})))
Bifus=Splati(D(Lifti(Blid),E(Ficam)))
最后,使用简单的融合模块,将来自不同相机的投影特征相加,与激光雷达特征拼接,并通过卷积层得到最终的BEV特征。对所有相机的所有图像列,使用共享的Transformer权重。
注意力vs深度预测:使用深度估计时,图像特征会被投影到BEV的多个位置,但由于深度分布经过了归一化,会导致沿深度分散的投影特征强度过低。而本文的方法可以使同一图像特征对多个BEV网格有相同的贡献,因为注意力权重是沿键(即像素高度)而非查询(射线深度)归一化的。此外,本文方法可以获取激光雷达特征,从而确定投影位置。
5. 实验
5.1 3D目标检测
本文冻结激光雷达主干,与基于Lift-Splat的方法比较。实验表明本文方法有更高的性能,说明本文方法能更好地利用相机特征。
将物体按照大小和距离分组,发现主要的性能提升位于远距离物体和小物体。这些情况正好属于单目深度估计困难的地方。即使远处或小物体含有的激光雷达点云较少,本文的方法也能有效利用图像特征。
5.2 定性分析
可视化本文方法最后一层交叉注意力图(所有注意力头平均)以及BEVFusion深度估计结果(具体过程见附录B.2),以观察图像特征被投影到BEV的什么位置。本文方法主要将图像特征放置在真实边界框附近,这说明可以有效利用激光雷达的上下文,将图像特征投影到最相关的位置。与BEVFusion相比,本文方法特征的分布更加集中。这是因为没有沿射线归一化权重,有更强的灵活性。对于投影到边界框外部的图像特征,融合模块可以抑制其激活。
进一步使用显著性图观察图像的哪个像素最被关注。给定物体查询索引
i
i
i和概率
z
z
z时,计算概率最大类别的logit对图像
I
j
I_j
Ij的梯度,可以得到显著性:
∂
z
i
,
c
^
∂
I
∣
I
j
,
c
^
=
arg max
c
z
i
,
c
\left.\frac{\partial z_{i,\hat c}}{\partial I}\right|_{I_j},\hat{c}=\argmax_cz_{i,c}
∂I∂zi,c^
Ij,c^=cargmaxzi,c
这样可以可视化单个像素对特定物体最终预测的贡献。可视化表明,当使用相机和激光雷达训练时,相比仅使用相机训练,模型倾向于选择相机特征的不同位置(物体上部),且离自车越近、越大的物体现象越明显。这可能是激光雷达的存在使模型能选择与激光雷达特征最互补的图像特征。BEVFusion中,无论是单一模态还是多模态训练,模型都倾向于选择物体周边分布更广泛的像素。
5.3 时间特征聚合
可以融合不同时刻的BEV特征,即时间特征聚合(TFA)。步骤如下:(i)保存过去时刻的BEV特征;(ii)进行自车运动补偿,使用双线性插值,与当前帧对齐;(iii)与当前帧BEV特征拼接,并通过 3 × 3 3\times3 3×3卷积。
训练时,使用预训练的主干网络并冻结,结果表明时间特征聚合能大幅提高性能。
5.4 消融实验
- 比较不同的融合方式(相加融合、拼接+卷积融合、门控sigmoid块),各方式性能接近。
- 增加投影时注意力阶段的Transformer解码器层数,可以略微提高性能。
- 增加训练时时间特征聚合时的帧数,也能提高性能。
补充材料
A. Lift-Splat中的单目深度
A.1 从激光雷达计算真实深度
将激光雷达点云投影到图像上,选择每个像素内最近的激光雷达点,其深度作为该像素深度。对于无激光雷达点、或是深度位于范围外的像素,不考虑其真实深度。作为监督时,进一步将深度值转化为深度区间的独热向量 D g t D^{gt} Dgt。
A.2 深度图的可视化
对于预测的深度分布图,使用其期望深度进行可视化。
A.3 使用激光雷达作为深度预测的监督
对存在真实深度的像素,将深度分布预测视为分类任务,使用交叉熵损失:
L
depth
=
−
1
N
∑
n
=
1
N
log
(
D
n
⋅
D
n
g
t
)
L_\text{depth}=-\frac 1 N\sum_{n=1}^N\log(D_n\cdot D^{gt}_n)
Ldepth=−N1n=1∑Nlog(Dn⋅Dngt)
B. 详细的实验结果
B.2 详细的定性结果
为得到5.2节所述的注意力可视化结果,首先按下面的方法计算图像到BEV的注意力图 Attn cam i → bev ∈ R H × W × N × M \text{Attn}^{\text{cam}_i\rightarrow \text{bev}}\in\mathbb{R}^{H\times W\times N\times M} Attncami→bev∈RH×W×N×M:
取各Transformer解码器最后一层各注意力头的注意力图,计算平均值得到
Attn
cam
i
→
frustum
∈
R
H
×
W
×
D
×
W
′
\text{Attn}^{\text{cam}_i\rightarrow \text{frustum}}\in\mathbb{R}^{H\times W\times D\times W'}
Attncami→frustum∈RH×W×D×W′,其中
D
×
W
′
D\times W'
D×W′为视锥维度。然后将视锥注意力权重投影到BEV下,得到
Attn
cam
i
→
bev
\text{Attn}^{\text{cam}_i\rightarrow \text{bev}}
Attncami→bev。给定相机图像
I
i
I_i
Ii,通过投影边界框建立二值掩膜
Mask
(
i
)
∈
{
0
,
1
}
H
×
W
\text{Mask}^{(i)}\in\{0,1\}^{H\times W}
Mask(i)∈{0,1}H×W。然后将掩膜内的图像特征投影到BEV网格下:
Attn
(
bev
)
=
max
i
,
h
,
w
Attn
h
,
w
cam
i
→
bev
⋅
Mask
h
,
w
(
i
)
\text{Attn}^{(\text{bev})}=\max_{i,h,w}\text{Attn}^{\text{cam}_i\rightarrow \text{bev}}_{h,w}\cdot\text{Mask}^{(i)}_{h,w}
Attn(bev)=i,h,wmaxAttnh,wcami→bev⋅Maskh,w(i)
对于Lift-Splat投影的可视化,与BEVFusion类似,但将 I i I_i Ii替换为 Mask ( i ) \text{Mask}^{(i)} Mask(i)作为投影的输入。通过深度分布将二值掩膜提升为点云 P ∈ R H × W × N D × 3 P\in\mathbb{R}^{H\times W\times N_D\times 3} P∈RH×W×ND×3,然后将点投影到 z = 0 z=0 z=0平面,并使用最大池化,这可以保证大型物体的权重不会过分超过小型物体。
B.3 集成与测试时数据增广
使用加权框融合(WBF)方法融合各模型/增广数据的结果。首先对各模型,进行所有增广数据结果的WBF;然后对所有模型的结果再次进行WBF。







![[leetcode] 22. 括号生成](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)
