一、缓冲区
“缓冲区”这个概念相信大家或多或少都听说过,大家其实在C语言阶段就已经接触到“缓冲区”这个东西,但是相信大家在C语言阶段并没有真正弄懂缓冲区到底是个什么东西,也相信大家在C语言阶段也因为缓冲区的问题写出过各种bug。
其实这也不奇怪,因为“缓冲区”这个概念其实已经不是语言层面的东西了,而是系统层面的东西。所以今天我们就要来好好的认识一下这个让我们即熟悉又陌生的“缓冲区”。
1.1、什么是缓冲区?
“缓冲区”我们简单的理解就是一个数据暂存库,当我们要将数据从一个地方传送到另一个地方的时,可以先将数据暂存到这个暂存库中,等时机到了再将数据传送到目标地点。
这就好比我们生活中的快递站,当我们要把一个东西送给另一个人时,就可以先将数据放到快递站,快递站到了时间就会发货,以送往目的地。
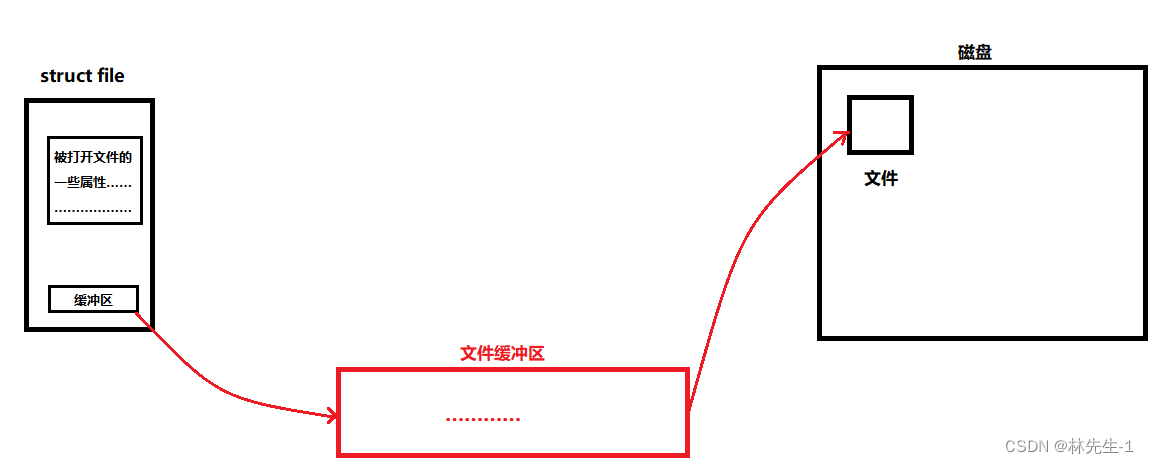
而我们的操作系统会为每一个被打开的文件创建一个缓冲区。我们知道,我们创建的文件最终都是要被存储在磁盘中的,而我们要对一个文件进行增删查改操作时,一定要先将文件加载到内存,这时候操作系统为了管理被打开的文件,就要为被打开的文件创建一个struct file结构体对象,这个结构体对象中有很多关于管理这个文件的属性,包括文件的大小、文件的创建时间、文件名、文件的操作方法集、文件的权限、等等……
而其中就有一个缓冲区,当我们要要向文件中写入数据时,就可以先将数据写入到这个缓冲区中,等到了“一定时间”后,操作系统就会将我们写入到缓冲区中的数据统一写入到磁盘中。
而这个struct file是一个内存中的结构体,所以缓冲区的本质其实就是一个内存块。
结构大致如下图所示:
1.2、为什么要有缓冲区
那为什么要有有这么一个缓冲区夹在内存和磁盘中间呢?为什么我们不能直接将数据写入磁盘呢?
这是因为冯诺依曼体系结构:cpu不直接跟外设打交道,cpu是通过内存和外设打交道的,磁盘也属于外设,所以cpu不直接跟磁盘打交道。因为相对于cpu来说磁盘等外设的运行速度实在是太慢了,与cpu的速度相差太多,如果cpu直接跟外设打交道,cpu不然就要等待外设,这就会大大的降低cpu执行的效率。
所以我们我们每次向文件中写入一点东西就直接写入磁盘中,那必定就要求cpu每次都要执行拷贝任务,向磁盘中写入,这样速度就慢了。
所以我们才需要一个缓冲区,先将要写入磁盘的数据暂存起来,等到某一时间后再统一写入到磁盘中,这其实是减少了cpu与磁盘交互的次数从而提高效率。
而将数据从缓冲区中写入到磁盘中称之为缓冲区的刷新,缓冲区的刷新一般有一下5种形式:
1、无缓冲(立即刷新)
2、行缓冲(行刷新)
3、全缓冲(缓冲区满了,再刷新)
4、强制刷新
5、进程退出,自动刷新
无缓冲我这里找不到对应的场景。
行缓冲就是缓冲一行,具体到语法层面就是如果我们在打印的字符串中添加了‘\n’,那就算一行了,那就会将这一行刷新:

比如上面的代码,如果我们加上两个'\n',运行的时候就会全都刷新出来:

而如果我们只在hello后面加上‘\n’,那执行的时候,就会只打印出hello:


那后面的内容呢?答案是:存储在缓冲区之中。
全缓冲就是缓冲区满了,必须刷新了。
强制刷新一般是我们使用一些系统调用来强制刷新缓冲区,例如我们以前是用过的fflush,例如下面这个例子:
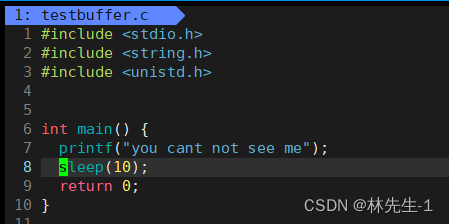
上面的代码,如果我们直接运行,一开始是看不到打印的信息的:

只有等时间到了,进程退出的时候自动刷新才能看得见:

如果我们想要让信息立即刷新出来就可以调用fflush:


1.3、语言缓冲区和内核缓冲区
我们上面所谈到的“缓冲区”其实是“内核级缓冲区”,但在我们的语言层面其实还有一个“语言级缓冲区”。
想要讲清楚内核级缓冲区和语言级缓冲区,我们得要从一个奇怪的例子入手:

执行上面的代码,如果我们正常执行,它就是在显示器上按顺序打印出我们所写的内容:

这个没什么问题,但如果我们在执行的时候加上个重定向操作,其结果就有一丢丢奇怪了:

我们会发现代码里面写在最后的write的内容竟然输出到了文件的最开头。
而如果我们再在代码的最后面加上一个fork的话,又会发生什么呢?

如果正常运行的话,那它和不带fork的代码的执行结果是一样的:
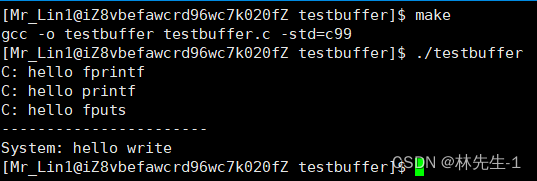
但如果我们在执行的时候加上一个重定向,那结果就会变得非常奇怪了:

我们会发现一个,这里出了系统调用的打印会打印到文件的最前面之外,C库函数的打印都打了两次!
想要解释这样的现象,我们就得要慢慢分析了:
1、首先有一个告知的结论是:我们直接向显示器上打印的时候,显示器文件的默认刷新方式是行刷新,所以我们前面的例子中才会出现只要有一个'\n'就会刷新一次的现象。而我们重定向就是向磁盘文件中写入的时候,磁盘文件的刷新方式是是全缓冲,也就是默认等缓冲区写满再刷新,但默认全缓冲不代表一定得等缓冲区写满才能更新,也有可能强制刷新或者是进程退出了自动刷新。
2、我们上面所写的打印信息并不足以将缓冲区写满,所以在fork执行后,数据依旧在缓冲区里面,没有被刷新。
3、而我们在fork创建子进程之后,子进程会进程父进程的文件描述符表和数据:

如上图,所以两个进程的1号文件描述符都指向了log.txt的struct flie,也就是说两个进程都会重定向到log.txt中。
而我们在代码中所写的各种C语言接口的打印,其实并没有直接将数据写入到struct file中的内核文件缓冲区中,而是写入到了C语言给我们提供的一个语言缓冲区中:

所以我们的数据其实是存在两份的,最后当父子进程无论哪个先退出,都会发生“写时拷贝”并刷新缓冲区,将数据写入到内核文件缓冲区中,所以我们代码中C库函数打印的信息,其实是向内核缓冲区中写入了两次的。
而系统调用write的数据只写入了一次,这足以说明,系统调用使用的并非是C语言缓冲区,而是内核缓冲区,它是直接将数据写入到内核缓冲区中的。
二、模拟实现C标准文件操作库
有了上面的这些理论,我们再通过实践来感受一下,缓冲区与C语言标准文件操作库的关系。
我们来模拟实现一个简易的Cstdio库。
我们毕竟不是要实现一个多么完善的stdio文件操作库,只是简单的模拟一下,懂个原理就行了,所以我们就只模拟实现三个接口,分别是fopen、fwrite、fflush、fclose。
首先我们要知道,在C语言中大多的文件操作接口的返回值都是一个FILE*指针,这说明C语言中使用FILE这个结构体来管理被打开的文件的,所以我们还需要在我们自己的stdio头文件中包装一个自己的FILE结构体,而这个结构体中的成员我们今天也不要封装得太复杂,大致像下面这样简单一点就行了:

然后就是声明一下我们自己要实现的一些文件操作接口,模拟库中的即可:

2.1、模拟实现fopen
打开文件的方式第一步一定是先判断文件的打开方式,这里直接用if语句做条件判断即可,判断完了打开方式后,真正打开文件的工作一定是要交给系统调用的:

2.2、模拟实现fflush
然后我们要先来实现fflush,因为无论是close文件或是,向文件中写数据,都需要刷新缓冲区,所以我们要先实现一下fflush。
刷新的本质其实就是将缓冲区内的数据拷贝到内核文件缓冲区中,也就是写入到内核缓冲区中的中,而write正是直接写入到内核缓冲区中的,所以我们需要做的就是调用write将buffer中的数据写入就行了:

2.3、模拟实现fclose
关闭文件就更简单了,我们只需要在退出前先刷新缓冲区,然后在调用系统调用close关闭文件,最后再讲FILE结构体释放就行了:

2.4、模拟实现fwrite
实现write我们,使用内存拷贝函数,将传过来的数据拷贝到我们的buffer缓冲区中即可,但最后还需要额外判断是否s后面是否包含‘\n’,如果有我们还需要将缓冲区刷新,即行刷新:

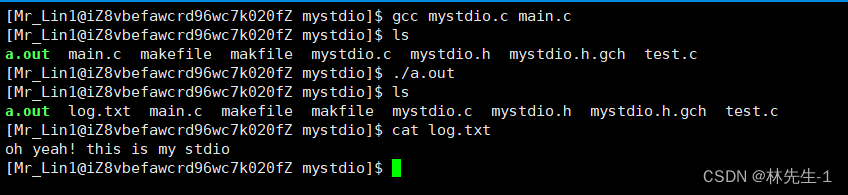
测试一下:





![[leetcode] 22. 括号生成](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)