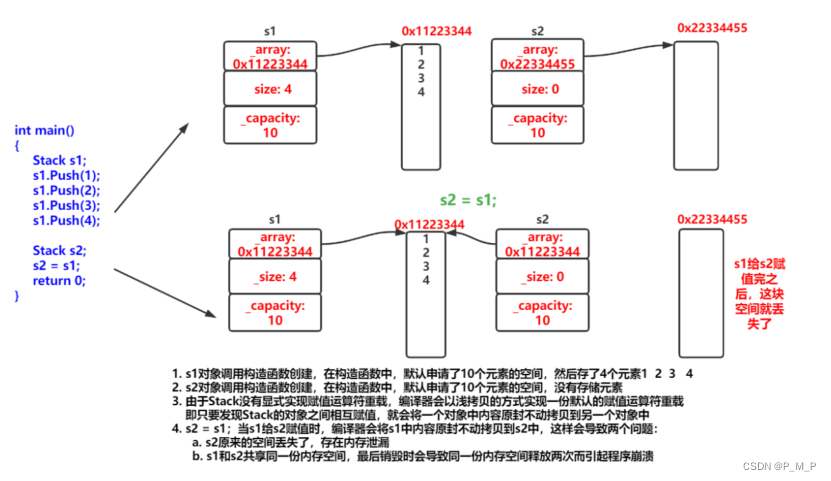
作者于2023年8月新开专栏——《文本挖掘和知识发现》,主要结合Python、大数据分析和人工智能分享文本挖掘、知识图谱、知识发现、图书情报等内容。这些内容也是作者《文本挖掘和知识发现(Python版)》书籍的部分介绍,本书预计2024年上市,采用通俗易懂和图文并茂的形式藐视,会更加系统地介绍文本挖掘和知识发现,共计20章节内容,涵盖上百个案例。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲解如何实现威胁情报实体识别,利用BiLSTM-CRF算法实现对ATT&CK相关的技战术实体进行提取。这篇文章将详细讲解通过自定义情感词典(大连理工词典)实现情感分析和情绪分类的过程,并与SnowNLP进行对比,为后续深度学习和自然语言处理(情感分析、实体识别、实体对齐、知识图谱构建、文本挖掘)结合做基础,希望对您有所帮助~
文章目录
- 一.大连理工中文情感词典
- 二.七种情绪计算
- 三.七种情绪词云可视化
- 1.基本用法
- 2.统计七种情绪特征词
- 3.词云分析
- 四.自定义词典情感分析
- 五.SnowNLP情感分析
- 六.总结


本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,为小宝赚点奶粉钱,但更多博客尤其基础性文章,还是会继续免费分享,该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
代码下载地址:
- https://github.com/eastmountyxz/Text-Mining-Knowledge-Discovery
- https://github.com/eastmountyxz/Sentiment-Analysis
本文参考了作者YX学生的学习思路,以及哈工大邓旭东老的方法,再次非常感激,向他们学习。
前文赏析:
- [文本挖掘和知识发现] 01.红楼梦主题演化分析——文献可视化分析软件CiteSpace入门
- [文本挖掘和知识发现] 02.命名实体识别之基于BiLSTM-CRF的威胁情报实体识别万字详解
- [文本挖掘和知识发现] 03.基于大连理工情感词典的情感分析和情绪计算
一.大连理工中文情感词典
情感分析 (Sentiment Analysis)和情绪分类 (Emotion Classification)都是非常重要的文本挖掘手段。情感分析的基本流程如下图所示,通常包括:
- 自定义爬虫抓取文本信息;
- 使用Jieba工具进行中文分词、词性标注;
- 定义情感词典提取每行文本的情感词;
- 通过情感词构建情感矩阵,并计算情感分数;
- 结果评估,包括将情感分数置于0.5到-0.5之间,并可视化显示。

目前中国研究成熟的词典有大连理工大学情感词汇本体库、知网的 HowNet 情感词典及TW大学中文情感极性词典等。本文选择的基础词典是大连理工大学情感词汇本体库,此词典将情感分为“乐”“好”“怒”“哀”“惧”“恶”“惊”7 个大类和 21 个小类,其情感词的初始情感强度被设置为 1、3、5、7、9 五个等级,较其他词典而言,强度划分得更为细致。情感词的情感极性有中性、褒义、贬义 3 类,分别对应值 0、1、2。为便于计算机作情感计算,文中将代表贬义的极性值2 修改为-1。词汇的情感值公式为:

中文情感词汇本体库是大连理工大学信息检索研究室在 林鸿飞教授 的指导下经过全体 教研室成员的努力整理和标注的一个中文本体资源。该资源从不同角度描述一个中文词汇或 者短语,包括词语词性种类、情感类别、情感强度及极性等信息。中文情感词汇本体的情感分类体系是在国外比较有影响的 Ekman 的 6 大类情感分类体 系的基础上构建的。在 Ekman 的基础上,词汇本体加入情感类别“好”对褒义情感进行了 更细致的划分。最终词汇本体中的情感共分为 7 大类 21 小类。
构造该资源的宗旨是在情感计算领域,为中文文本情感分析和倾向性分析提供一个便捷 可靠的辅助手段。中文情感词汇本体可以用于解决多类别情感分类的问题,同时也可以用于 解决一般的倾向性分析的问题。如下图所示,该词典共包括27466个词语,包含词语、词性种类、词义数、词义序号、情感分类、强度、极性、辅助情感分类、强度和极性。

注意,在情感词典中,一个情感词可能对应多个情感,情感分类用于刻画情感词的主要情感分类,辅助情感为该情感词在具有主要情感分类的同时含有的其他情感分类。

情感分类按照论文《情感词汇本体的构造》所述,情感分为 7 大类 21 小类。情感强度分为 1、3、5、7、9 五档,9 表示强度最大,1 为强度最小。情感分类如下表所示:

情感词汇本体中的词性种类一共分为 7 类,分别是名词(noun)、动词(verb)、形容词 (adj)、副词(adv)、网络词语(nw)、成语(idiom)、介词短语(prep)。同时,每个词在每一类情感下都对应了一个极性。其中,0代表中性,1代表褒义,2代表贬 义,3代表兼有褒贬两性。最后给出否定词和程序副词,否定词会将情感强度乘以-1,程度副词代表不同级别的情感倾向。


二.七种情绪计算
首先,我们的数据集如下图所示,是《庆余年》电视剧的评论,共计220条。

第一步,调用Pandas读取数据。
# coding: utf-8
import pandas as pd
#获取数据集
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())
输出结果如下图所示:

第二步,导入大连理工大学中文情感词典。
# coding: utf-8
import pandas as pd
#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())
#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中
# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))
df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()
下图展示了我们导入的词典。

第三步,统计七种情绪分布情况。
# coding: utf-8
import pandas as pd
#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())
#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中
# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))
df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()
#-------------------------------------七种情绪的运用-------------------------------
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []
#df.iterrows()功能是迭代遍历每一行
for idx, row in df.iterrows():
if row['情感分类'] in ['PA', 'PE']:
Happy.append(row['词语'])
if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:
Good.append(row['词语'])
if row['情感分类'] in ['PC']:
Surprise.append(row['词语'])
if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:
Sad.append(row['词语'])
if row['情感分类'] in ['NI', 'NC', 'NG']:
Fear.append(row['词语'])
if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:
Disgust.append(row['词语'])
if row['情感分类'] in ['NAU']: #修改: 原NA算出来没结果
Anger.append(row['词语'])
#正负计算不是很准 自己可以制定规则
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')
print(Anger)
比如输出Anger生气的情绪词语,如下图所示。用Spyder集成环境打开可以看到情感特征词的具体分布情况。

第四步,增加中文分词和自定义停用词典的代码。
#---------------------------------------中文分词---------------------------------
import jieba
import time
#添加使用者词典和停用词
jieba.load_userdict("user_dict.txt") #自定义词典
stop_list = pd.read_csv('stop_words.txt',
engine='python',
encoding='utf-8',
delimiter="\n",
names=['t'])['t'].tolist()
def txt_cut(juzi):
return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1
部分停用词如下所示,它们没有意义,对情感也没有影响,所以需要进行过滤。

第五步,计算七种情绪特征词的出现频率。
情绪包括anger、disgust、fear、sadness、surprise、good、happy。
#---------------------------------------中文分词---------------------------------
import jieba
import time
#添加自定义词典和停用词
#jieba.load_userdict("user_dict.txt")
stop_list = pd.read_csv('stop_words.txt',
engine='python',
encoding='utf-8',
delimiter="\n",
names=['t'])
#获取重命名t列的值
stop_list = stop_list['t'].tolist()
def txt_cut(juzi):
return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1
#---------------------------------------情感计算---------------------------------
def emotion_caculate(text):
positive = 0
negative = 0
anger = 0
disgust = 0
fear = 0
sad = 0
surprise = 0
good = 0
happy = 0
wordlist = txt_cut(text)
#wordlist = jieba.lcut(text)
wordset = set(wordlist)
wordfreq = []
for word in wordset:
freq = wordlist.count(word)
if word in Positive:
positive+=freq
if word in Negative:
negative+=freq
if word in Anger:
anger+=freq
if word in Disgust:
disgust+=freq
if word in Fear:
fear+=freq
if word in Sad:
sad+=freq
if word in Surprise:
surprise+=freq
if word in Good:
good+=freq
if word in Happy:
happy+=freq
emotion_info = {
'length':len(wordlist),
'positive': positive,
'negative': negative,
'anger': anger,
'disgust': disgust,
'fear':fear,
'good':good,
'sadness':sad,
'surprise':surprise,
'happy':happy,
}
indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']
return pd.Series(emotion_info, index=indexs)
#测试
text="""
原著的确更吸引编剧读下去,所以跟《诛仙》系列明显感觉到编剧只看过故事大纲比,这个剧的编剧完整阅读过小说。
配乐活泼俏皮,除了强硬穿越的台词轻微尴尬,最应该尴尬的感情戏反而入戏,
故意模糊了陈萍萍的太监身份、太子跟长公主的暧昧关系,
整体观影感受极好,很期待第二季拍大东山之役。玩弄人心的阴谋阳谋都不狗血,架空的设定能摆脱历史背景,
服装道具能有更自由的发挥空间,特别喜欢庆帝的闺房。以后还是少看国产剧,太长了,
还是精短美剧更适合休闲,追这个太累。王启年真是太可爱了。
"""
res = emotion_caculate(text)
print(res)
统计结果为disgust特征词6个,good特征词6个,开心特征词1个。
length 83
positive 7
negative 6
anger 0
disgust 6
fear 0
sadness 0
surprise 0
good 6
happy 1
dtype: int64
进一步提取特征词,我们可以看到刚才那个句子的特征词如下所示(详见后续完整代码)。其中,disgust(恶)包括“阴谋”、“玩弄”等词语,good(好)包括“极好”、“喜欢”等词语,happy(乐)包括“摆脱”词语。

第六步,计算《庆余年》自定义数据集的七种情绪分布情况。
# coding: utf-8
import pandas as pd
import jieba
import time
#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())
#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中
# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))
df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()
#-------------------------------------七种情绪的运用-------------------------------
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []
#df.iterrows()功能是迭代遍历每一行
for idx, row in df.iterrows():
if row['情感分类'] in ['PA', 'PE']:
Happy.append(row['词语'])
if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:
Good.append(row['词语'])
if row['情感分类'] in ['PC']:
Surprise.append(row['词语'])
if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:
Sad.append(row['词语'])
if row['情感分类'] in ['NI', 'NC', 'NG']:
Fear.append(row['词语'])
if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:
Disgust.append(row['词语'])
if row['情感分类'] in ['NAU']: #修改: 原NA算出来没结果
Anger.append(row['词语'])
#正负计算不是很准 自己可以制定规则
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')
print(Anger)
#---------------------------------------中文分词---------------------------------
#添加自定义词典和停用词
#jieba.load_userdict("user_dict.txt")
stop_list = pd.read_csv('stop_words.txt',
engine='python',
encoding='utf-8',
delimiter="\n",
names=['t'])
#获取重命名t列的值
stop_list = stop_list['t'].tolist()
def txt_cut(juzi):
return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1
#---------------------------------------情感计算---------------------------------
def emotion_caculate(text):
positive = 0
negative = 0
anger = 0
disgust = 0
fear = 0
sad = 0
surprise = 0
good = 0
happy = 0
anger_list = []
disgust_list = []
fear_list = []
sad_list = []
surprise_list = []
good_list = []
happy_list = []
wordlist = txt_cut(text)
#wordlist = jieba.lcut(text)
wordset = set(wordlist)
wordfreq = []
for word in wordset:
freq = wordlist.count(word)
if word in Positive:
positive+=freq
if word in Negative:
negative+=freq
if word in Anger:
anger+=freq
anger_list.append(word)
if word in Disgust:
disgust+=freq
disgust_list.append(word)
if word in Fear:
fear+=freq
fear_list.append(word)
if word in Sad:
sad+=freq
sad_list.append(word)
if word in Surprise:
surprise+=freq
surprise_list.append(word)
if word in Good:
good+=freq
good_list.append(word)
if word in Happy:
happy+=freq
happy_list.append(word)
emotion_info = {
'length':len(wordlist),
'positive': positive,
'negative': negative,
'anger': anger,
'disgust': disgust,
'fear':fear,
'good':good,
'sadness':sad,
'surprise':surprise,
'happy':happy,
}
indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']
#return pd.Series(emotion_info, index=indexs), anger_list, disgust_list, fear_list, sad_list, surprise_list, good_list, happy_list
return pd.Series(emotion_info, index=indexs)
#测试 (res, anger_list, disgust_list, fear_list, sad_list, surprise_list, good_list, happy_list)
text = """
原著的确更吸引编剧读下去,所以跟《诛仙》系列明显感觉到编剧只看过故事大纲比,这个剧的编剧完整阅读过小说。
配乐活泼俏皮,除了强硬穿越的台词轻微尴尬,最应该尴尬的感情戏反而入戏,
故意模糊了陈萍萍的太监身份、太子跟长公主的暧昧关系,
整体观影感受极好,很期待第二季拍大东山之役。玩弄人心的阴谋阳谋都不狗血,
架空的设定能摆脱历史背景,服装道具能有更自由的发挥空间,
特别喜欢庆帝的闺房。以后还是少看国产剧,太长了,还是精短美剧更适合休闲,追这个太累。王启年真是太可爱了。
"""
#res, anger, disgust, fear, sad, surprise, good, happy = emotion_caculate(text)
res = emotion_caculate(text)
print(res)
#---------------------------------------情感计算---------------------------------
start = time.time()
emotion_df = weibo_df['review'].apply(emotion_caculate)
end = time.time()
print(end-start)
print(emotion_df.head())
#输出结果
output_df = pd.concat([weibo_df, emotion_df], axis=1)
output_df.to_csv('庆余年220_emotion.csv',encoding='utf_8_sig', index=False)
print(output_df.head())
输出结果如下图所示:

对应的矩阵数据如下图所示:

第七步,如果我们想获取某种情绪的结果,则可以通过下面的代码实现。
#显示fear、negative数据集
fear_content = output_df.sort_values(by='fear',ascending=False)
print(fear_content)
print(fear_content.iloc[0:5]['review'])
negative_content = output_df.sort_values(by='negative',ascending=False)
print(negative_content)
print(negative_content.iloc[0:5]['review'])
输出结果如下图所示:

三.七种情绪词云可视化
当我们获取了某个语料的情绪特征词之后,通常还会和词云结合起来进行可视化分析。首先,简单给出一个词云可视化的代码,接着结合该案例来进行分析。
1.基本用法
词云分析主要包括两种方法:
- 调用WordCloud扩展包画图(兼容性极强,之前介绍过)
- 调用PyEcharts中的WordCloud子包画图(本文推荐新方法)
PyEcharts绘制词云的基础代码如下:
# coding=utf-8
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 数据
words = [
('背包问题', 10000),
('大整数', 6181),
('Karatsuba乘法算法', 4386),
('穷举搜索', 4055),
('傅里叶变换', 2467),
('状态树遍历', 2244),
('剪枝', 1868),
('Gale-shapley', 1484),
('最大匹配与匈牙利算法', 1112),
('线索模型', 865),
('关键路径算法', 847),
('最小二乘法曲线拟合', 582),
('二分逼近法', 555),
('牛顿迭代法', 550),
('Bresenham算法', 462),
('粒子群优化', 366),
('Dijkstra', 360),
('A*算法', 282),
('负极大极搜索算法', 273),
('估值函数', 265)
]
# 渲染图
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape='diamond') # SymbolType.ROUND_RECT
.set_global_opts(title_opts=opts.TitleOpts(title='WordCloud词云'))
)
return c
# 生成图
wordcloud_base().render('词云图.html')
输出结果如下图所示,出现词频越高显示越大。

核心代码为:
add(name, attr, value, shape=“circle”, word_gap=20, word_size_range=None, rotate_step=45)
- name -> str: 图例名称
- attr -> list: 属性名称
- value -> list: 属性所对应的值
- shape -> list: 词云图轮廓,有’circle’, ‘cardioid’, ‘diamond’, ‘triangleforward’, ‘triangle’, ‘pentagon’, ‘star’可选
- word_gap -> int: 单词间隔,默认为20
- word_size_range -> list: 单词字体大小范围,默认为[12,60]
- rotate_step -> int: 旋转单词角度,默认为45
2.统计七种情绪特征词
我们先统计七种情绪特征词出现的次数,然后写入CSV文件中。
# coding: utf-8
import pandas as pd
import jieba
import time
import csv
#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())
#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中
# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))
df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()
#-------------------------------------七种情绪的运用-------------------------------
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []
#df.iterrows()功能是迭代遍历每一行
for idx, row in df.iterrows():
if row['情感分类'] in ['PA', 'PE']:
Happy.append(row['词语'])
if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:
Good.append(row['词语'])
if row['情感分类'] in ['PC']:
Surprise.append(row['词语'])
if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:
Sad.append(row['词语'])
if row['情感分类'] in ['NI', 'NC', 'NG']:
Fear.append(row['词语'])
if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:
Disgust.append(row['词语'])
if row['情感分类'] in ['NAU']: #修改: 原NA算出来没结果
Anger.append(row['词语'])
#正负计算不是很准 自己可以制定规则
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')
print(Anger)
#---------------------------------------中文分词---------------------------------
#添加自定义词典和停用词
#jieba.load_userdict("user_dict.txt")
stop_list = pd.read_csv('stop_words.txt',
engine='python',
encoding='utf-8',
delimiter="\n",
names=['t'])
#获取重命名t列的值
stop_list = stop_list['t'].tolist()
def txt_cut(juzi):
return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1
#---------------------------------------情感计算---------------------------------
#文件写入
c = open("Emotion_features.csv", "a+", newline='', encoding='gb18030')
writer = csv.writer(c)
writer.writerow(["Emotion","Word","Num"])
#情感统计
def emotion_caculate(text):
positive = 0
negative = 0
anger = 0
disgust = 0
fear = 0
sad = 0
surprise = 0
good = 0
happy = 0
anger_list = []
disgust_list = []
fear_list = []
sad_list = []
surprise_list = []
good_list = []
happy_list = []
wordlist = txt_cut(text)
#wordlist = jieba.lcut(text)
wordset = set(wordlist)
wordfreq = []
for word in wordset:
freq = wordlist.count(word)
tlist = []
if word in Positive:
positive+=freq
if word in Negative:
negative+=freq
if word in Anger:
anger+=freq
anger_list.append(word)
tlist.append("anger")
tlist.append(word)
tlist.append(freq)
writer.writerow(tlist)
if word in Disgust:
disgust+=freq
disgust_list.append(word)
tlist.append("disgust")
tlist.append(word)
tlist.append(freq)
writer.writerow(tlist)
if word in Fear:
fear+=freq
fear_list.append(word)
tlist.append("fear")
tlist.append(word)
tlist.append(freq)
writer.writerow(tlist)
if word in Sad:
sad+=freq
sad_list.append(word)
tlist.append("sad")
tlist.append(word)
tlist.append(freq)
writer.writerow(tlist)
if word in Surprise:
surprise+=freq
surprise_list.append(word)
tlist.append("surprise")
tlist.append(word)
tlist.append(freq)
writer.writerow(tlist)
if word in Good:
good+=freq
good_list.append(word)
tlist.append("good")
tlist.append(word)
tlist.append(freq)
writer.writerow(tlist)
if word in Happy:
happy+=freq
happy_list.append(word)
tlist.append("happy")
tlist.append(word)
tlist.append(freq)
writer.writerow(tlist)
emotion_info = {
'length':len(wordlist),
'positive': positive,
'negative': negative,
'anger': anger,
'disgust': disgust,
'fear':fear,
'good':good,
'sadness':sad,
'surprise':surprise,
'happy':happy,
}
indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']
#return pd.Series(emotion_info, index=indexs), anger_list, disgust_list, fear_list, sad_list, surprise_list, good_list, happy_list
return pd.Series(emotion_info, index=indexs)
#---------------------------------------情感计算---------------------------------
start = time.time()
emotion_df = weibo_df['review'].apply(emotion_caculate)
end = time.time()
print(end-start)
print(emotion_df.head())
#输出结果
output_df = pd.concat([weibo_df, emotion_df], axis=1)
output_df.to_csv('庆余年220_emotion.csv',encoding='utf_8_sig', index=False)
print(output_df.head())
#结束统计
c.close()
输出结果如下图所示:

3.词云分析
接着通过Pandas获取不同情绪的特征词及数量,代码如下所示。
# coding: utf-8
import csv
import pandas as pd
#读取数据
f = open('Emotion_features.csv')
data = pd.read_csv(f)
print(data.head())
#统计结果
groupnum = data.groupby(['Emotion']).size()
print(groupnum)
print("")
#分组统计
for groupname,grouplist in data.groupby('Emotion'):
print(groupname)
print(grouplist)
输出结果如下图所示:
Emotion Word Num
0 good 人心 1
1 good 极好 1
2 good 活泼 1
3 disgust 强硬 1
4 disgust 尴尬 2
Emotion
anger 2
disgust 208
fear 9
good 254
happy 39
sad 42
surprise 11
dtype: int64
anger
Emotion Word Num
133 anger 气愤 1
382 anger 报仇 3
disgust
Emotion Word Num
3 disgust 强硬 1
4 disgust 尴尬 2
8 disgust 模糊 1
.. ... ... ...
558 disgust 紧张 1
560 disgust 紧张 1
561 disgust 刺激 1
[208 rows x 3 columns]
fear
Emotion Word Num
93 fear 鸿门宴 1
111 fear 吓人 1
148 fear 可怕 1
170 fear 没头苍蝇 1
211 fear 厉害 1
290 fear 刀光剑影 1
292 fear 忌惮 1
342 fear 无时无刻 1
559 fear 紧张 1
good
Emotion Word Num
0 good 人心 1
1 good 极好 1
.. ... ... ...
但是我们会发现统计的结果分布不均匀,所以扩展情感词库是非常必要的。接下来我们以good、disgust、sad和happy作为示例进行词云对比。最终代码如下所示:
# coding: utf-8
import csv
import pandas as pd
import operator
#------------------------------------统计结果------------------------------------
#读取数据
f = open('Emotion_features.csv')
data = pd.read_csv(f)
print(data.head())
#统计结果
groupnum = data.groupby(['Emotion']).size()
print(groupnum)
print("")
#分组统计
for groupname,grouplist in data.groupby('Emotion'):
print(groupname)
print(grouplist)
#生成数据 word = [('A',10), ('B',9), ('C',8)] 列表+Tuple
i = 0
words = []
counts = []
while i<len(data):
if data['Emotion'][i] in "sad": #相等
k = data['Word'][i]
v = data['Num'][i]
n = 0
flag = 0
while n<len(words):
#如果两个单词相同则增加次数
if words[n]==k:
counts[n] = counts[n] + v
flag = 1
break
n = n + 1
#如果没有找到相同的特征词则添加
if flag==0:
words.append(k)
counts.append(v)
i = i + 1
#添加最终数组结果
result = []
k = 0
while k<len(words):
result.append((words[k], int(counts[k]*5))) #注意:因数据集较少,作者扩大5倍方便绘图
k = k + 1
print(result)
#------------------------------------词云分析------------------------------------
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
# 渲染图
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", result, word_size_range=[5, 200], shape=SymbolType.ROUND_RECT)
.set_global_opts(title_opts=opts.TitleOpts(title='情绪词云图'))
)
return c
# 生成图
wordcloud_base().render('情绪词云图.html')
输出结果如下图所示:
[(‘可惜’, 5), (‘大失所望’, 1), (‘白搭’, 1), (‘情感’, 1), (‘失望’, 10), (‘鹤唳华亭’, 5), (‘引人深思’, 1), (‘不行’, 5), (‘难受’, 4), (‘艰苦’, 2), (‘俏皮话’, 1), (‘无语’, 2), (‘回忆’, 1), (‘悲剧’, 1), (‘江河日下’, 1), (‘战乱’, 2), (‘不忍’, 1)]
由于数据集较少,作者将次数扩大了5倍,这种情况建议大家进行归一化处理。具体怎么做?这里不再详细讲解。

最终四个情绪Sad | Happy | Good | Disgust 对比图如下图所示:

四.自定义词典情感分析
下面我们进行基于大连理工自定义词典的情感分析。核心模块是load_sentiment_dict(self,dict_path),功能如下:
- 调用大连理工词典,选取其中要用的列
- 将情感极性转化一下,并计算得出真正的情感值(强度×极性(转后))
- 找到情感词所属的大类
- 分词 => 情感词间是否有否定词/程度词+前后顺序 => 情感分数累加
完整代码如下:
# coding: utf-8
import sys
import gzip
from collections import defaultdict
from itertools import product
import jieba
import csv
import pandas as pd
class Struct(object):
def __init__(self, word, sentiment, pos,value, class_value):
self.word = word
self.sentiment = sentiment
self.pos = pos
self.value = value
self.class_value = class_value
class Result(object):
def __init__(self,score, score_words,not_word, degree_word ):
self.score = score
self.score_words = score_words
self.not_word = not_word
self.degree_word = degree_word
class Score(object):
# 七个情感大类对应的小类简称: 尊敬
score_class = {'乐':['PA','PE'],
'好':['PD','PH', 'PG','PB','PK'],
'怒':['NA' ],
'哀':['NB','NJ','NH', 'PF'],
'惧':['NI', 'NC', 'NG'],
'恶':['NE', 'ND', 'NN','NK','NL'],
'惊':['PC']
}
# 大连理工大学 -> ICTPOS 3.0
POS_MAP = {
'noun': 'n',
'verb': 'v',
'adj': 'a',
'adv': 'd',
'nw': 'al', # 网络用语
'idiom': 'al',
'prep': 'p',
}
# 否定词
NOT_DICT = set(['不','不是','不大', '没', '无', '非', '莫', '弗', '毋',
'勿', '未', '否', '别', '無', '休'])
def __init__(self, sentiment_dict_path, degree_dict_path, stop_dict_path ):
self.sentiment_struct,self.sentiment_dict = self.load_sentiment_dict(sentiment_dict_path)
self.degree_dict = self.load_degree_dict(degree_dict_path)
self.stop_words = self.load_stop_words(stop_dict_path)
def load_stop_words(self, stop_dict_path):
stop_words = [w for w in open(stop_dict_path).readlines()]
#print (stop_words[:100])
return stop_words
def remove_stopword(self, words):
words = [w for w in words if w not in self.stop_words]
return words
def load_degree_dict(self, dict_path):
"""读取程度副词词典
Args:
dict_path: 程度副词词典路径. 格式为 word\tdegree
所有的词可以分为6个级别,分别对应极其, 很, 较, 稍, 欠, 超
Returns:
返回 dict = {word: degree}
"""
degree_dict = {}
with open(dict_path, 'r', encoding='UTF-8') as f:
for line in f:
line = line.strip()
word, degree = line.split('\t')
degree = float(degree)
degree_dict[word] = degree
return degree_dict
def load_sentiment_dict(self, dict_path):
"""读取情感词词典
Args:
dict_path: 情感词词典路径. 格式请看 README.md
Returns:
返回 dict = {(word, postag): 极性}
"""
sentiment_dict = {}
sentiment_struct = []
with open(dict_path, 'r', encoding='UTF-8') as f:
#with gzip.open(dict_path) as f:
for index, line in enumerate(f):
if index == 0: # title,即第一行的标题
continue
items = line.split('\t')
word = items[0]
pos = items[1]
sentiment=items[4]
intensity = items[5] # 1, 3, 5, 7, 9五档, 9表示强度最大, 1为强度最小.
polar = items[6] # 极性
# 将词性转为 ICTPOS 词性体系
pos = self.__class__.POS_MAP[pos]
intensity = int(intensity)
polar = int(polar)
# 转换情感倾向的表现形式, 负数为消极, 0 为中性, 正数为积极
# 数值绝对值大小表示极性的强度 // 分成3类,极性:褒(+1)、中(0)、贬(-1); 强度为权重值
value = None
if polar == 0: # neutral
value = 0
elif polar == 1: # positive
value = intensity
elif polar == 2: # negtive
value = -1 * intensity
else: # invalid
continue
#key = (word, pos, sentiment )
key = word
sentiment_dict[key] = value
#找对应的大类
for item in self.score_class.items():
key = item[0]
values = item[1]
#print(key)
#print(value)
for x in values:
if (sentiment==x):
class_value = key # 如果values中包含,则获取key
sentiment_struct.append(Struct(word, sentiment, pos,value, class_value))
return sentiment_struct, sentiment_dict
def findword(self, text): #查找文本中包含哪些情感词
word_list = []
for item in self.sentiment_struct:
if item.word in text:
word_list.append(item)
return word_list
def classify_words(self, words):
# 这3个键是词的序号(索引)
sen_word = {}
not_word = {}
degree_word = {}
# 找到对应的sent, not, degree; words 是分词后的列表
for index, word in enumerate(words):
if word in self.sentiment_dict and word not in self.__class__.NOT_DICT and word not in self.degree_dict:
sen_word[index] = self.sentiment_dict[word]
elif word in self.__class__.NOT_DICT and word not in self.degree_dict:
not_word[index] = -1
elif word in self.degree_dict:
degree_word[index] = self.degree_dict[word]
return sen_word, not_word, degree_word
def get2score_position(self, words):
sen_word, not_word, degree_word = self.classify_words(words) # 是字典
score = 0
start = 0
# 存所有情感词、否定词、程度副词的位置(索引、序号)的列表
sen_locs = sen_word.keys()
not_locs = not_word.keys()
degree_locs = degree_word.keys()
senloc = -1
# 遍历句子中所有的单词words,i为单词的绝对位置
for i in range(0, len(words)):
if i in sen_locs:
W = 1 # 情感词间权重重置
not_locs_index = 0
degree_locs_index = 0
# senloc为情感词位置列表的序号,之前的sen_locs是情感词再分词后列表中的位置序号
senloc += 1
#score += W * float(sen_word[i])
if (senloc==0): # 第一个情感词,前面是否有否定词,程度词
start = 0
elif senloc < len(sen_locs): # 和前面一个情感词之间,是否有否定词,程度词
# j为绝对位置
start = previous_sen_locs
for j in range(start,i): # 词间的相对位置
# 如果有否定词
if j in not_locs:
W *= -1
not_locs_index=j
# 如果有程度副词
elif j in degree_locs:
W *= degree_word[j]
degree_locs_index=j
# 判断否定词和程度词的位置:1)否定词在前,程度词减半(加上正值);不是很 2)否定词在后,程度增强(不变),很不是
if ((not_locs_index>0) and (degree_locs_index>0 )):
if (not_locs_index < degree_locs_index ):
degree_reduce = (float(degree_word[degree_locs_index]/2))
W +=degree_reduce
#print (W)
score += W * float(sen_word[i]) # 直接添加该情感词分数
#print(score)
previous_sen_locs = i
return score
#感觉get2score用处不是很大
def get2score(self, text):
word_list = self.findword(text) ##查找文本中包含哪些正负情感词,然后分别分别累计它们的数值
pos_score = 0
pos_word = []
neg_score = 0
neg_word=[]
for word in word_list:
if (word.value>0):
pos_score = pos_score + word.value
pos_word.append(word.word)
else:
neg_score = neg_score+word.value
neg_word.append(word.word)
print ("pos_score=%d; neg_score=%d" %(pos_score, neg_score))
#print('pos_word',pos_word)
#print('neg_word',neg_word)
def getscore(self, text):
word_list = self.findword(text) ##查找文本中包含哪些情感词
# 增加程度副词+否定词
not_w = 1
not_word = []
for notword in self.__class__.NOT_DICT: # 否定词
if notword in text:
not_w = not_w * -1
not_word.append(notword)
degree_word = []
for degreeword in self.degree_dict.keys():
if degreeword in text:
degree = self.degree_dict[degreeword]
#polar = polar + degree if polar > 0 else polar - degree
degree_word.append(degreeword)
# 7大类找对应感情大类的词语,分别统计分数= 词极性*词权重
result = []
for key in self.score_class.keys(): #区分7大类
score = 0
score_words = []
for word in word_list:
if (key == word.class_value):
score = score + word.value
score_words.append(word.word)
if score > 0:
score = score + degree
elif score<0:
score = score - degree # 看分数>0,程度更强; 分数<0,程度减弱?
score = score * not_w
x = '{}_score={}; word={}; nor_word={}; degree_word={};'.format(key, score, score_words,not_word, degree_word)
print (x)
result.append(x)
#key + '_score=%d; word=%s; nor_word=%s; degree_word=%s;'% (score, score_words,not_word, degree_word))
return result
if __name__ == '__main__':
sentiment_dict_path = "sentiment_words_chinese.tsv"
degree_dict_path = "degree_dict.txt"
stop_dict_path = "stop_words.txt"
#文件读取
f = open('庆余年220.csv',encoding='utf8')
data = pd.read_csv(f)
#文件写入
c = open("Result.csv", "a+", newline='', encoding='gb18030')
writer = csv.writer(c)
writer.writerow(["no","review","score"])
#分句功能 否定词程度词位置判断
score = Score(sentiment_dict_path, degree_dict_path, stop_dict_path )
n = 1
for temp in data['review']:
tlist = []
words = [x for x in jieba.cut(temp)] #分词
#print(words)
words_ = score.remove_stopword(words)
print(words_)
#分词->情感词间是否有否定词/程度词+前后顺序->分数累加
result = score.get2score_position(words_)
print(result)
tlist.append(str(n))
tlist.append(words)
tlist.append(str(result))
writer.writerow(tlist)
n = n + 1
#句子-> 整句判断否定词/程度词 -> 分正负词
#score.get2score(temp)
#score.getscore(text)
c.close()
输出结果如下图所示,每条评论对应一个情感分析分数,总体效果较好,差评和好评基本能区分,但是有些“白瞎”、“烂”、“难受”、“尴尬”这些特征词没有识别,应该和大连理工情感词典有关。所以我们在情感分析时,是否可以考虑融合多个特征词典呢?

同时,情感分析通常需要和评论时间结合起来,并进行舆情预测等,建议读者尝试将时间结合。比如王树义老师的文章《基于情感分类的竞争企业新闻文本主题挖掘》。我们可以和时间结合绘制相关的趋势图,如果某一天出现很多评论,可以计算该天所有评论的情感分数,求其平均值即可。最后,情感分析的分数最好进行归一化处理,也可以进行评价,比如抓取数据的分为5星评分,则可假设0-0.2位一星,0.2-0.4位二星,0.4-0.6为三星,0.6-0.8为四星,0.8-1.0为五星,这样我们可以计算它的准确率,召回率,F值,从而评论我的算法好坏。

最后第五部分我用SnowNLP情感分析,并绘制相应的情感分布图,方便大家对比。
五.SnowNLP情感分析
SnowNLP是一个常用的Python文本分析库,是受到TextBlob启发而发明的。由于当前自然语言处理库基本都是针对英文的,而中文没有空格分割特征词,Python做中文文本挖掘较难,后续开发了一些针对中文处理的库,例如SnowNLP、Jieba、BosonNLP等。注意SnowNLP处理的是unicode编码,所以使用时请自行decode成unicode。
Snownlp主要功能包括:
- 中文分词(算法是Character-Based Generative Model)
- 词性标注(原理是TnT、3-gram 隐马)
- 情感分析
- 文本分类(原理是朴素贝叶斯)
- 转换拼音、繁体转简体
- 提取文本关键词(原理是TextRank)
- 提取摘要(原理是TextRank)、分割句子
- 文本相似(原理是BM25)
安装和其他库一样,使用pip安装即可。

SnowNLP情感分析也是基于情感词典实现的,其简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。下面是简单的实例。
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
s1 = SnowNLP(u"我今天很开心")
print(u"s1情感分数:")
print(s1.sentiments)
s2 = SnowNLP(u"我今天很沮丧")
print(u"s2情感分数:")
print(s2.sentiments)
s3 = SnowNLP(u"大傻瓜,你脾气真差,动不动就打人")
print(u"s3情感分数:")
print(s3.sentiments)
输出结果如下所示,当负面情感特征词越多,比如“傻瓜”、“差”、“打人”等,分数就会很低,同样当正免情感词多分数就高。
s1情感分数:
0.842040189791
s2情感分数:
0.648537121839
s3情感分数:
0.049546727538
而在真实项目中,通常需要根据实际的数据重新训练情感分析的模型,导入正面样本和负面样本,再训练新模型。
- sentiment.train(’./neg.txt’, ‘./pos.txt’)
- sentiment.save(‘sentiment.marshal’)
下面的代码是对《庆余年》电视剧部分评论进行情感分析。在做情感分析的时候,很多论文都是将情感区间从[0, 1.0]转换为[-0.5, 0.5],这样的曲线更加好看,位于0以上的是积极评论,反之消极评论。最终代码如下:
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
import codecs
import os
import pandas as pd
#获取情感分数
f = open('庆余年220.csv',encoding='utf8')
data = pd.read_csv(f)
sentimentslist = []
for i in data['review']:
s = SnowNLP(i)
print(s.sentiments)
sentimentslist.append(s.sentiments)
#区间转换为[-0.5, 0.5]
result = []
i = 0
while i<len(sentimentslist):
result.append(sentimentslist[i]-0.5)
i = i + 1
#可视化画图
import matplotlib.pyplot as plt
import numpy as np
plt.plot(np.arange(0, 220, 1), result, 'k-')
plt.xlabel('Number')
plt.ylabel('Sentiment')
plt.title('Analysis of Sentiments')
plt.show()
绘制图形如下所示,注意它表示每一条评论的情感分布趋势,我们同样可以绘制时间分布的情感趋势图。
最后推荐大家阅读作者前文系列:
- [Pyhon大数据分析] 四.微博话题抓取及情文本挖掘和情感分析
六.总结
写到这里,这篇情感分析的文章就讲解完毕,希望对您有所帮助,尤其是想写文本挖掘论文的读者。后续还会分享深度学习和自然语言处理结合的文章。如果文章对您有所帮助,将是我写作的最大动力。作者将源代码上传至github,大家可以直接下载。你们的支持就是我撰写的最大动力,加油~
- 情感分析下载地址:https://github.com/eastmountyxz/Sentiment-Analysis
最后,作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域,指导大家撰写简单的学术论文,一起加油!感谢这些年遇到很多以前进步的博友,共勉~
(By:Eastmount 2024-02-04 写于省图书馆 http://blog.csdn.net/eastmount/ )
参考文献:
[1] 大连理工大学中文情感词汇本体库(含情绪分析代码) - 邓旭东老师
[2] [Pyhon大数据分析] 四.微博话题抓取及情文本挖掘和情感分析
[3] https://github.com/liuhuanyong/SentimentWordExpansion
[4] 感谢学生YX强势指导
[5] 王树义老师的文章《基于情感分类的竞争企业新闻文本主题挖掘》