概念辨析:
人工智能包含机器学习,机器学习包含深度学习
机器学习
机器学习约等于:looking for Function
深度学习:Function就是一个类神经网络
如果输出是一个数值就就叫回归
如果输出是几种类别就是分类
自监督学习为机器学习的一种
跑代码平台
- google Colab
- kaggle
Different types of Function(机器学习的任务)
- Regression:The function outputs is a scalar.
- classification:Given option, the function outputs the correct one
- structured learning:create something with structure(image, document)
how to look for function
- function with unknown parameter
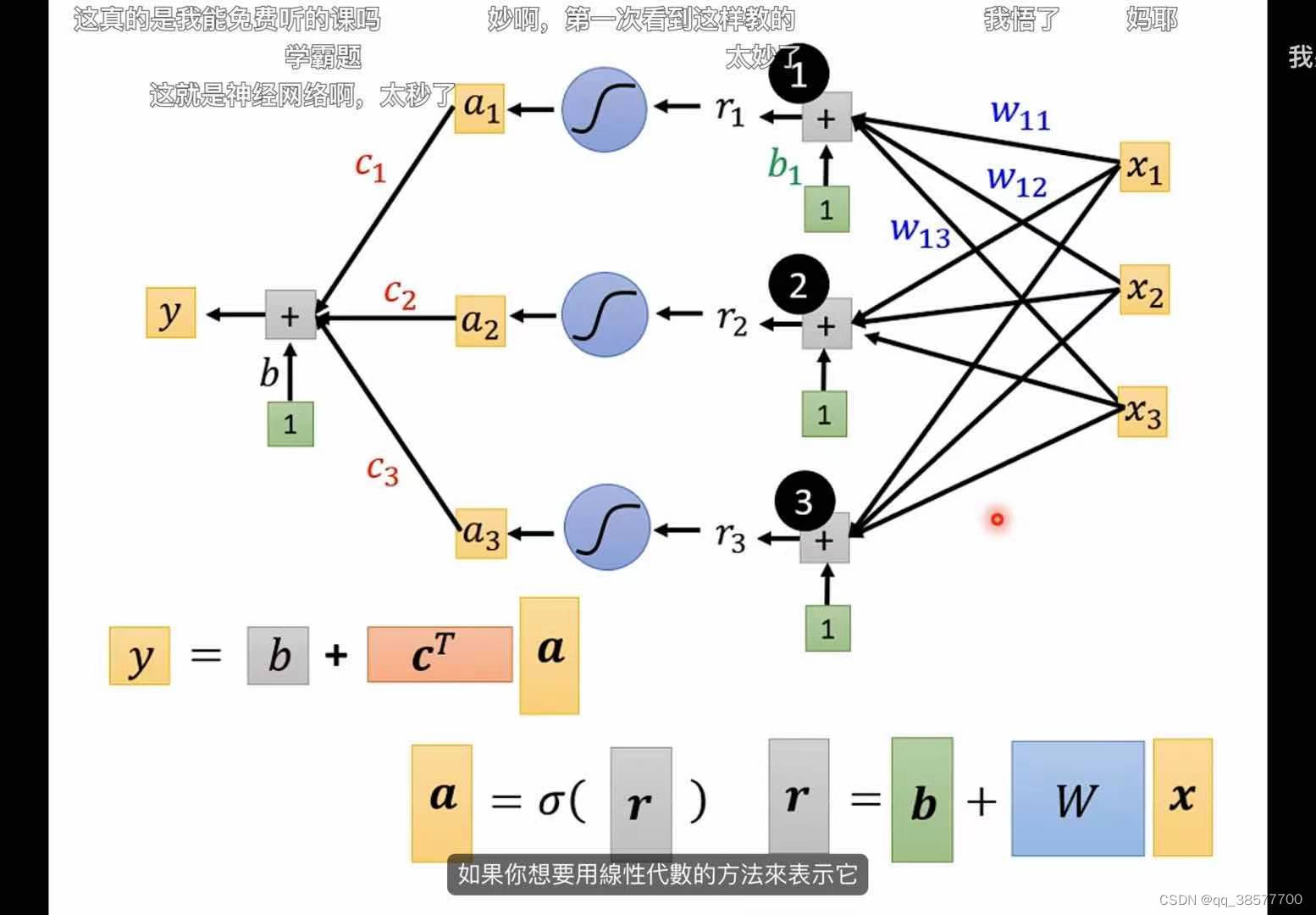
y =b + wx 其中y是结果,x是已经知道的数据,w和b是未知的参数
Model:就是带有未知参数的function
feature:已经知道的数据
w:weight
b:bias - Define loss from Training Data
loss is a function of parameters,其中参数是b和w
loss:评估function里面的参数好还是不好(评估实际与预测之间的差距)
MAE:mean absolute error
MSE:mean Square error - Optimization:寻找W*,b* ,W*,b* 等于让损失函数最佳的w,b
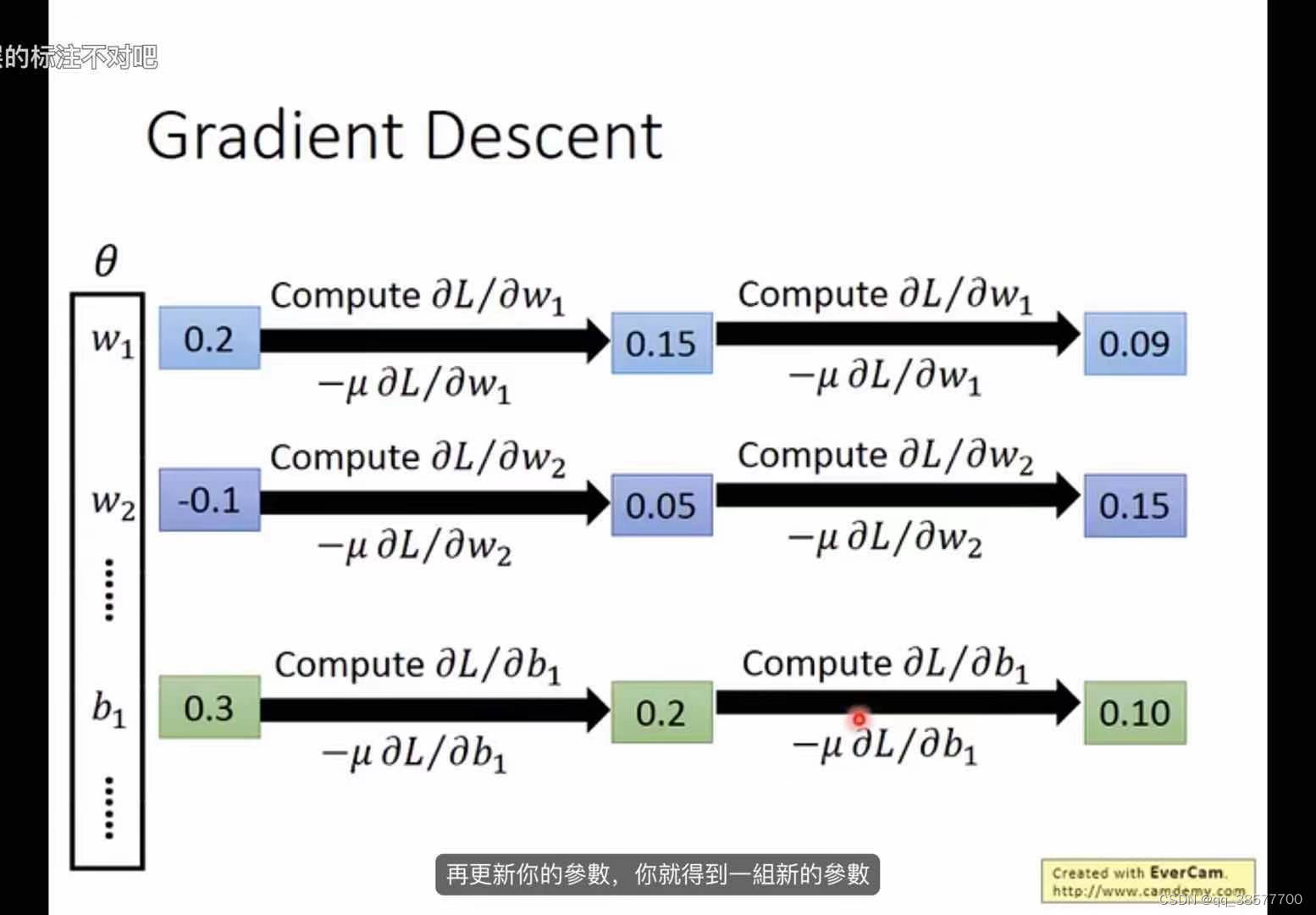
Gradient decent:梯度下降法
函数沿负梯度方向下降最快1,选取初始w 2,计算∂L/∂w,如果是负的,增大w,反正相反 3,自己设计一个学习率,会影响w的更新
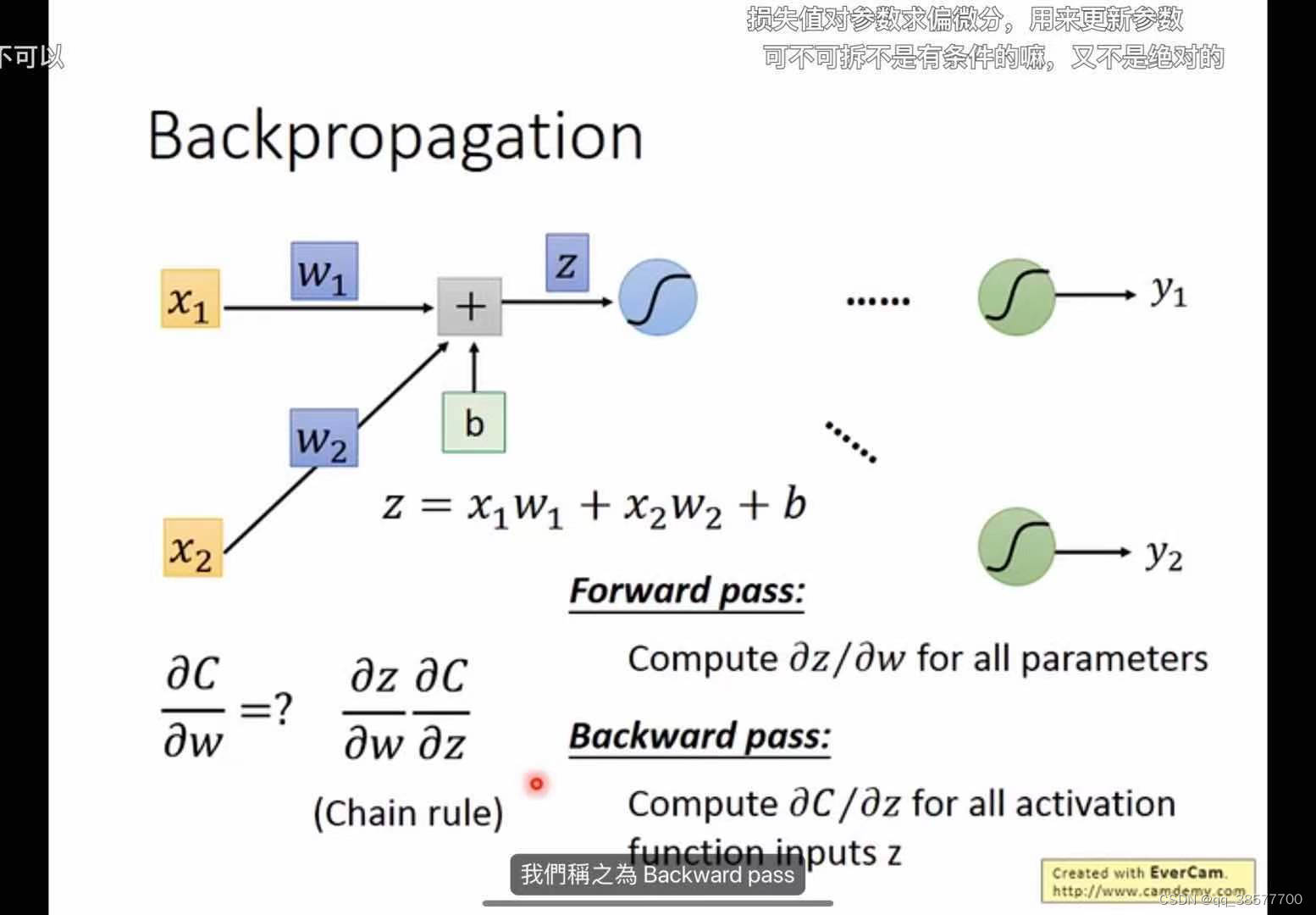
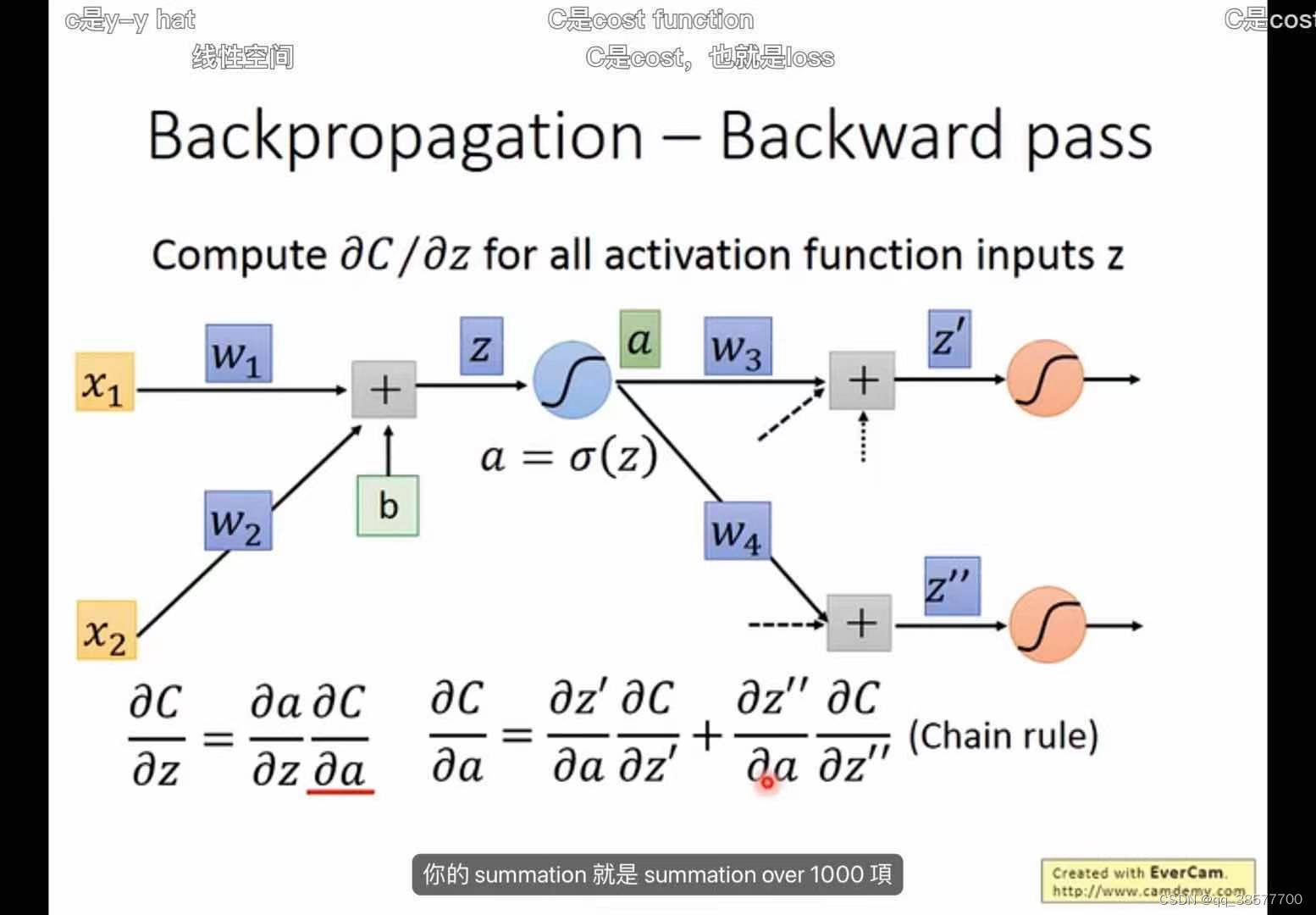
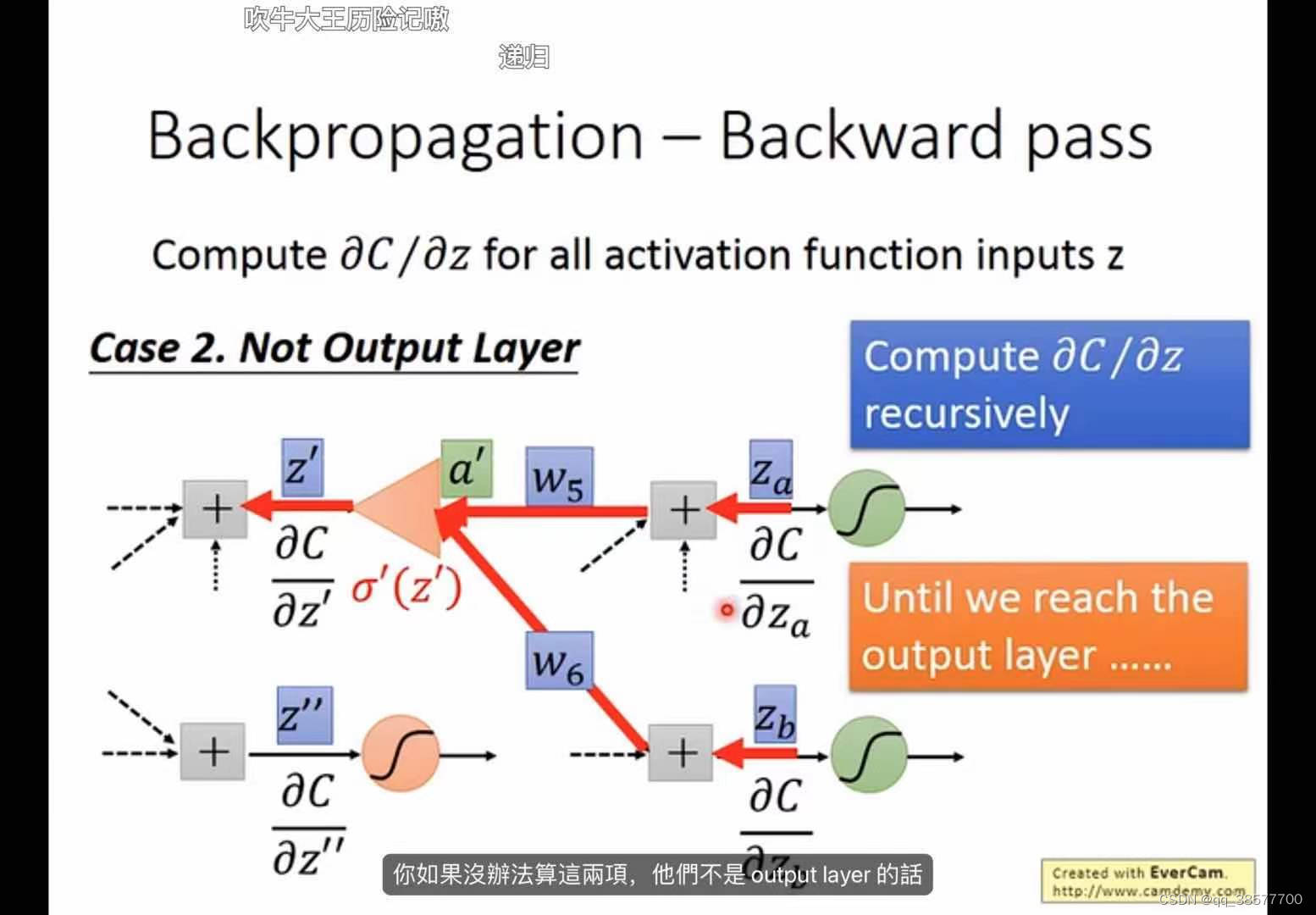
反向传播算法
linear models have severe limitation:Model Bias
为了解决线性模型的缺点,我们提出了Piecewise linear
piecewise linear = constant + sum of a set of function
只要有足够多的function,曲线就可以无限趋近piecewise linear
- function如何表示
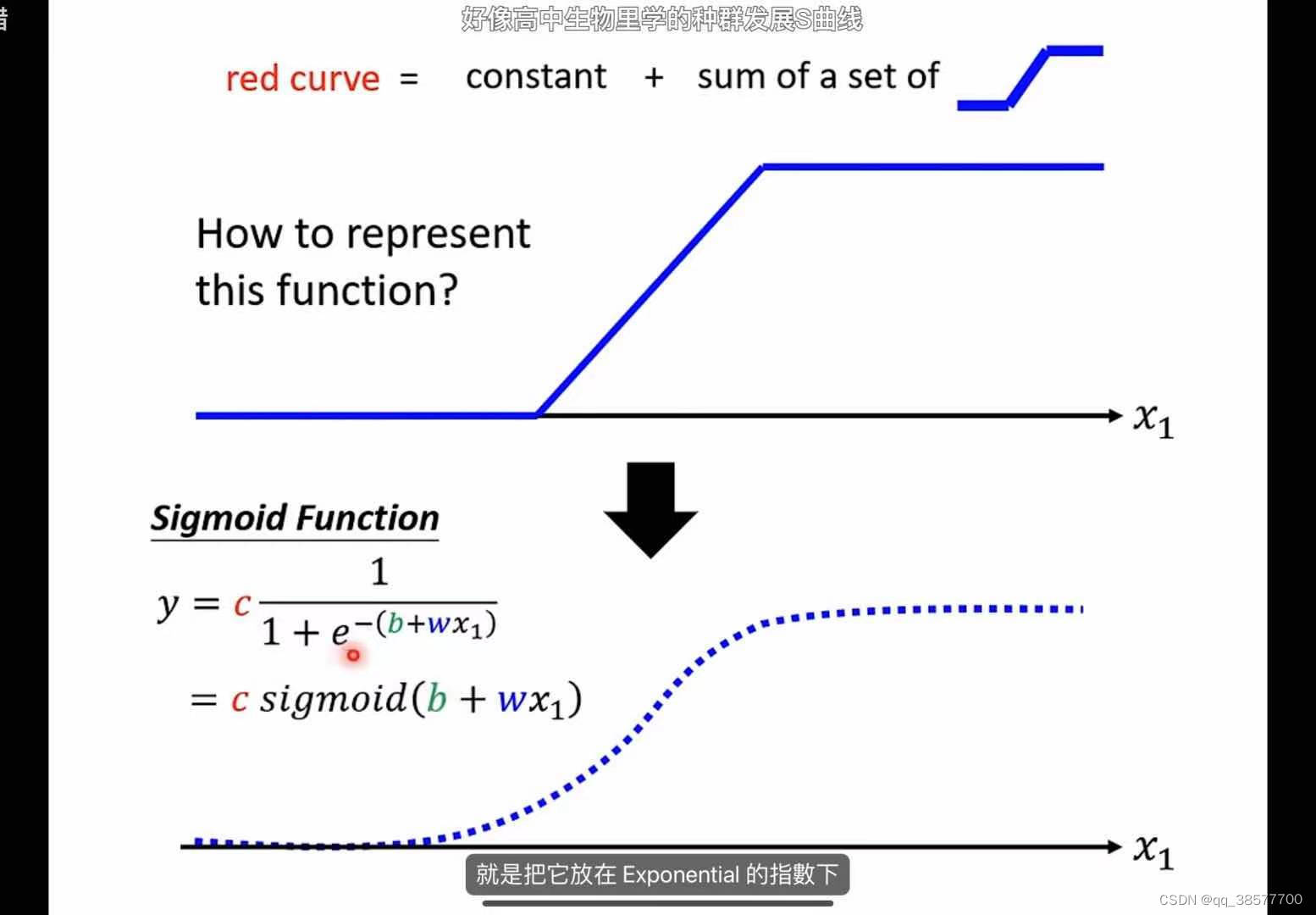
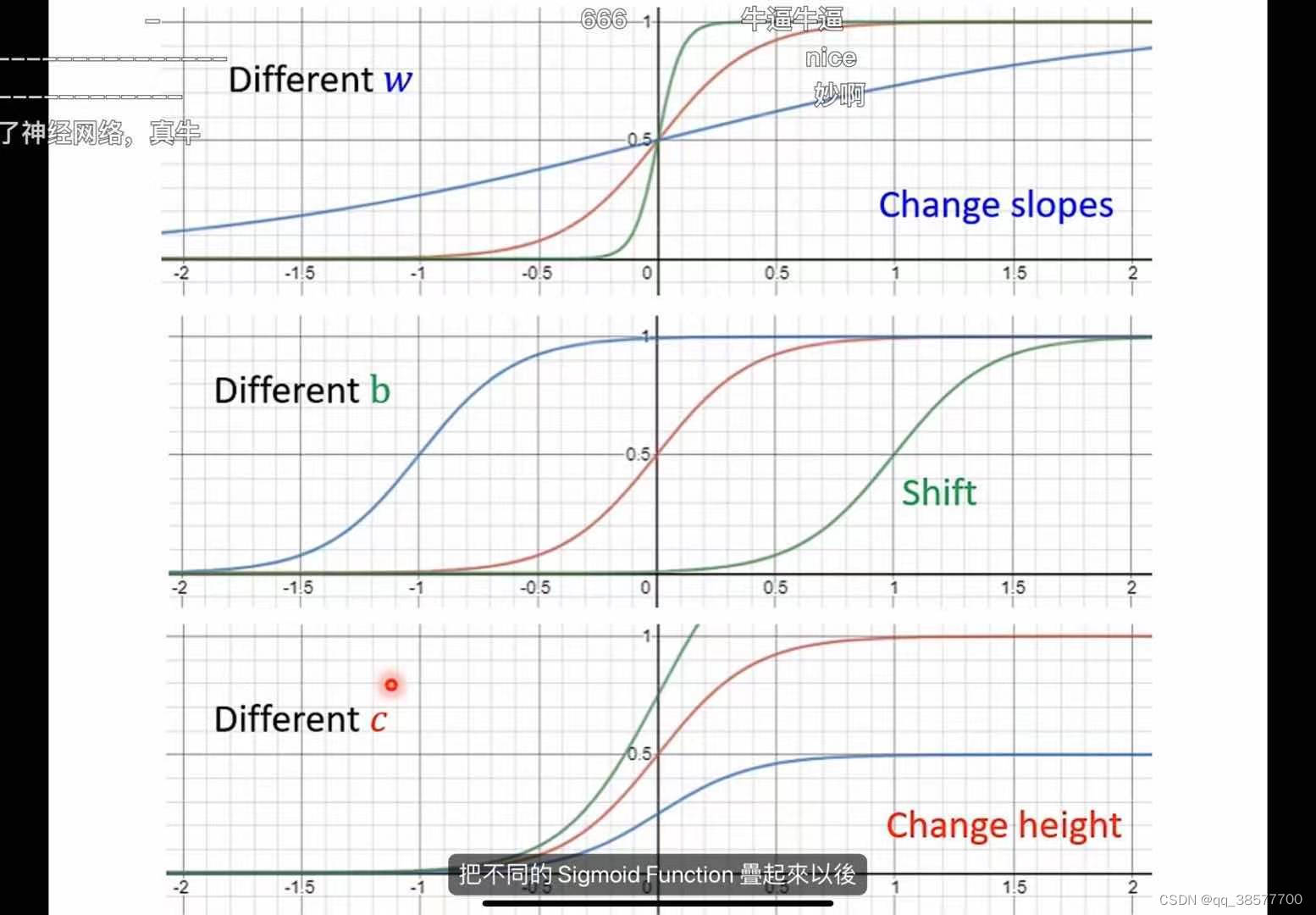

其中n为学习率


两个Relu可以叠加成一个hard sigmoid
过拟合(overfitting)和欠拟合
- 欠拟合:训练误差很大,测试样本的特性没有学到,或者是模型过于简单无法拟合或区分样本
- 过拟合:训练误差很小,测试误差.就是太过贴近于训练数据的特征了,在训练集上表现非常优秀,近乎完美的预测/区分了所有的数据,但是在新的测试集上却表现平平,不具泛化性,拿到新样本后没有办法去准确的判断。
怎么把神经元链接起来
- fully connect feedforward network
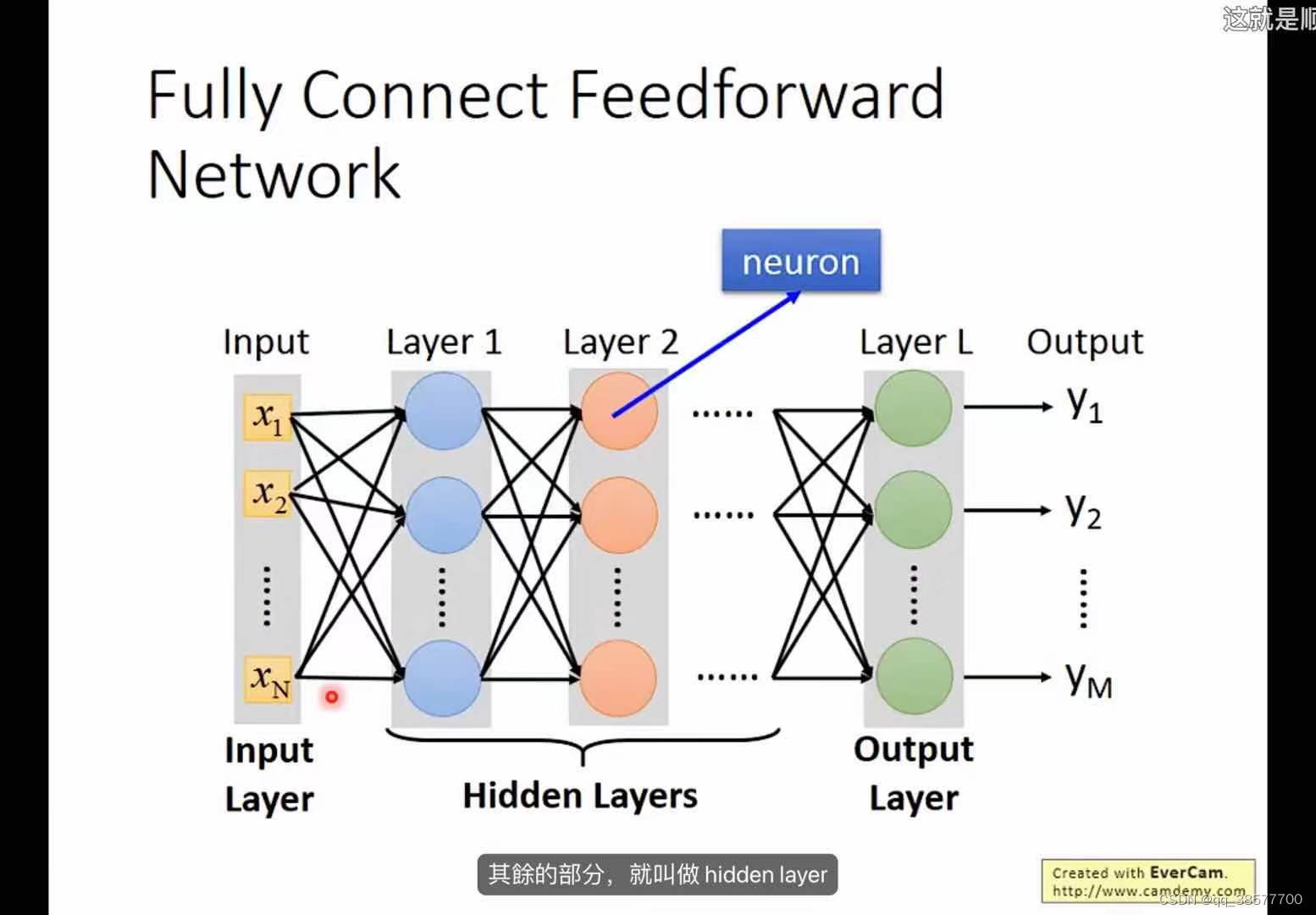
深度学习
-
training
-
backpropagation

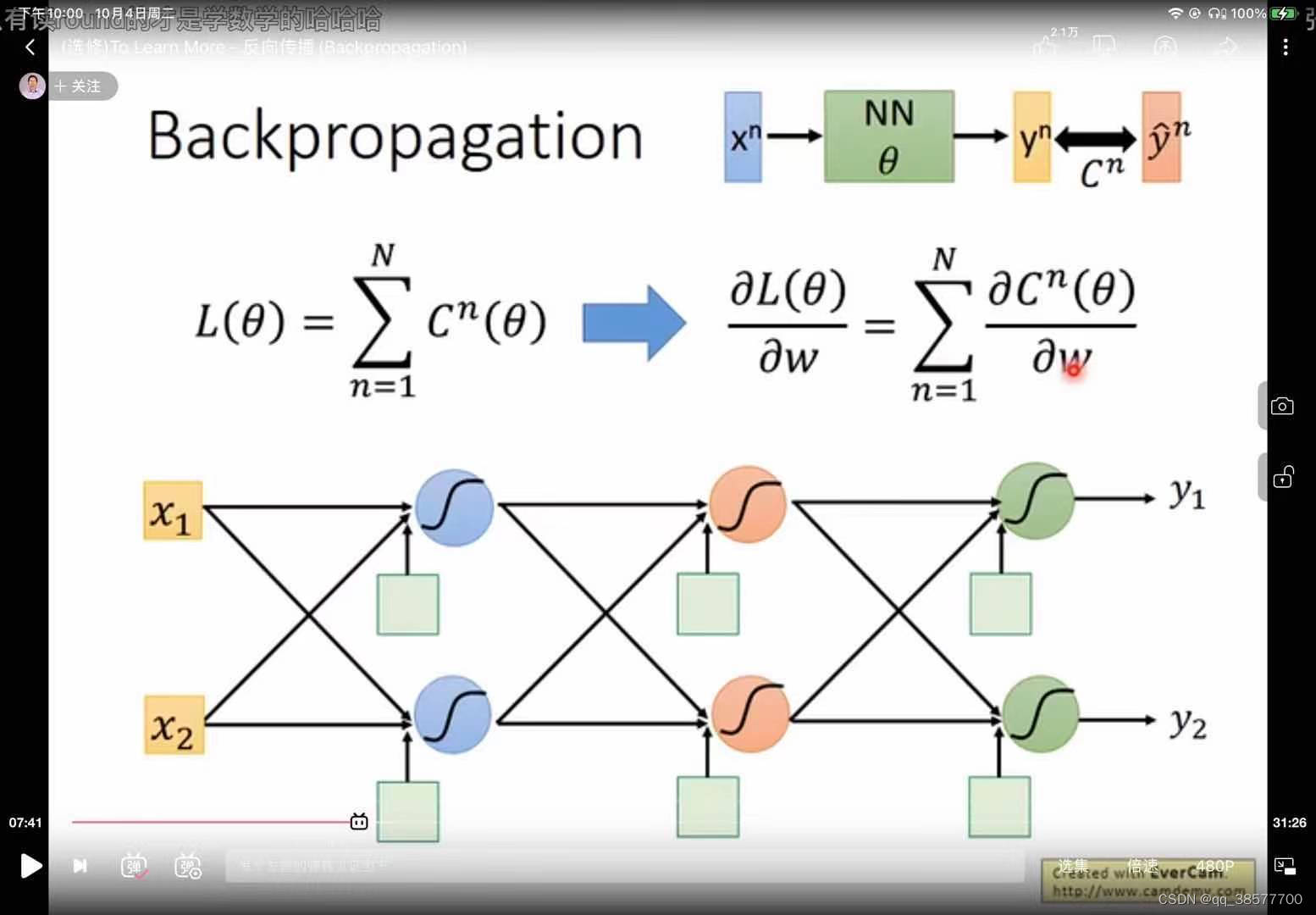
在线性回归中,loss function is convex(凸起的)没有local optimal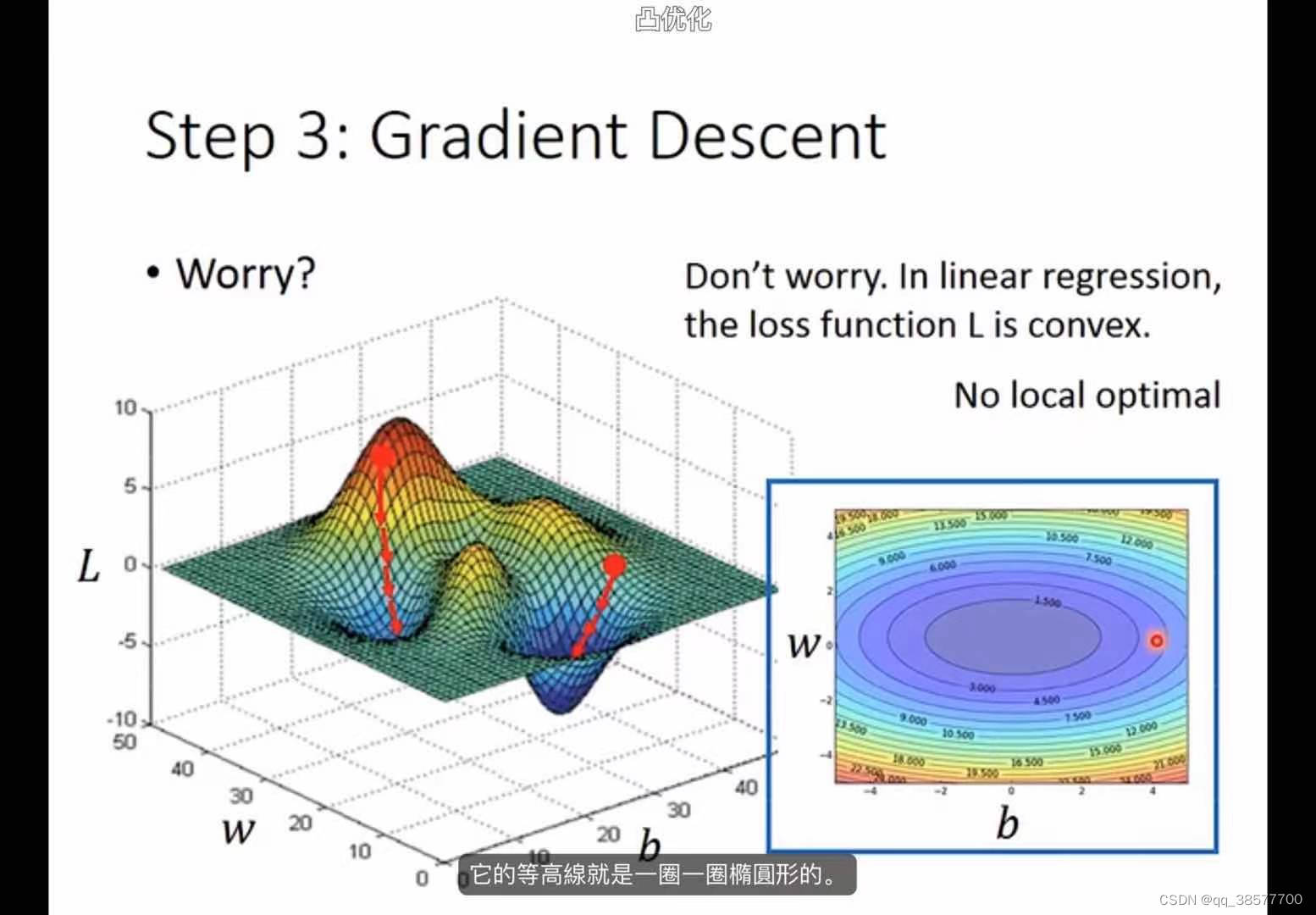

正则化

w越小说明函数对变化不明感,如果有噪音影响的话,平滑的函数就会有较小的影响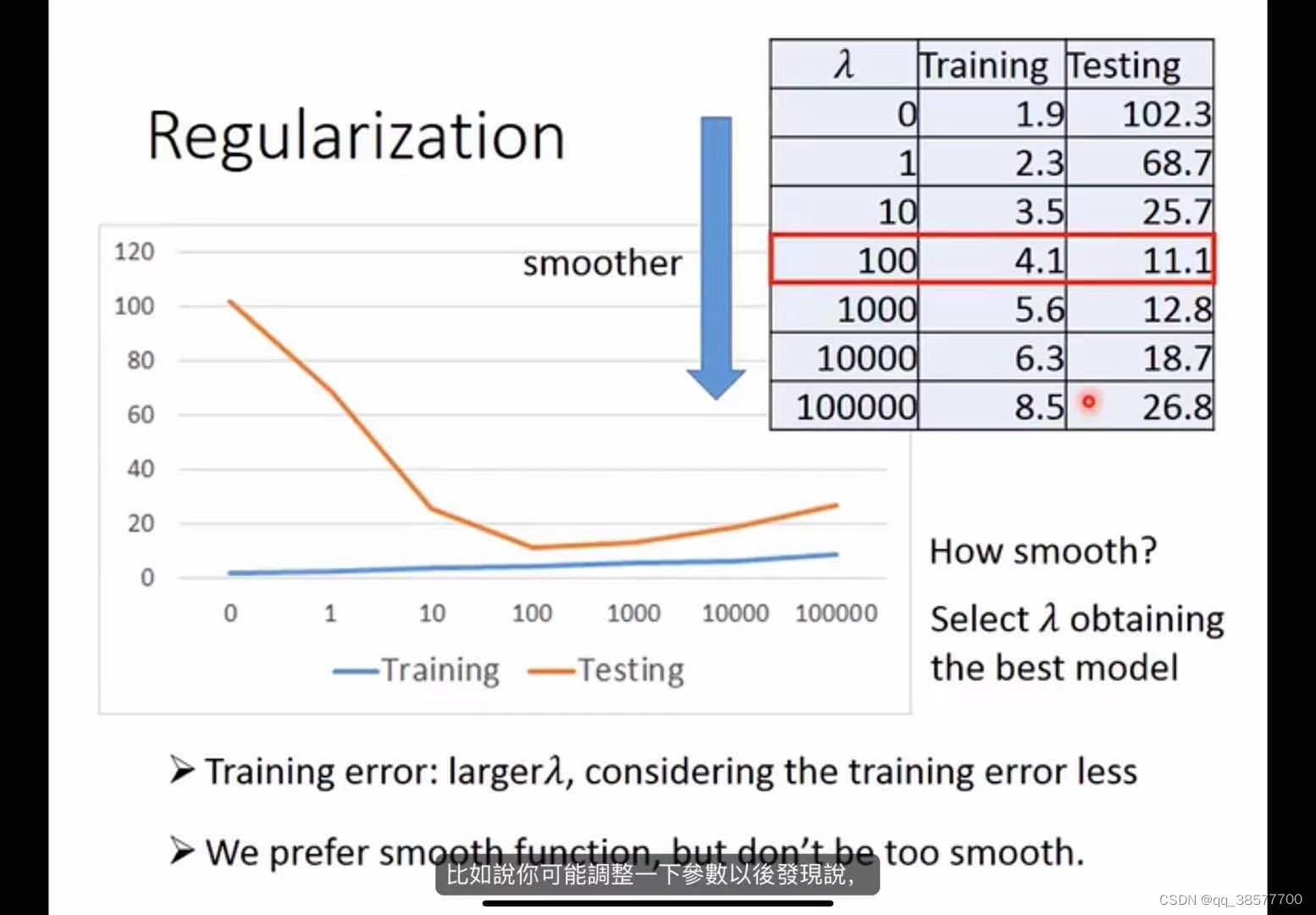
分类问题

贝叶斯
所谓贝叶斯公式,是指当分析样本大到接近总体数时,样本中事件发生的概率将接近于总体中事件发生的概率。是概率统计中的应用所观察到的现象对有关概率分布的主观判断(即先验概率)进行修正的标准方法
高斯分布
高斯的详解(我没太看懂为什么)哈哈
最大似然估计
https://blog.csdn.net/linweieran/article/details/101521979

可以不同的类一起分享同一个方差矩阵,方差矩阵的大小和输入数据特征的平方成正比,当输入数据特别大的时候,需要的model参数就会变多,参数多,变化就大,很容易overfitting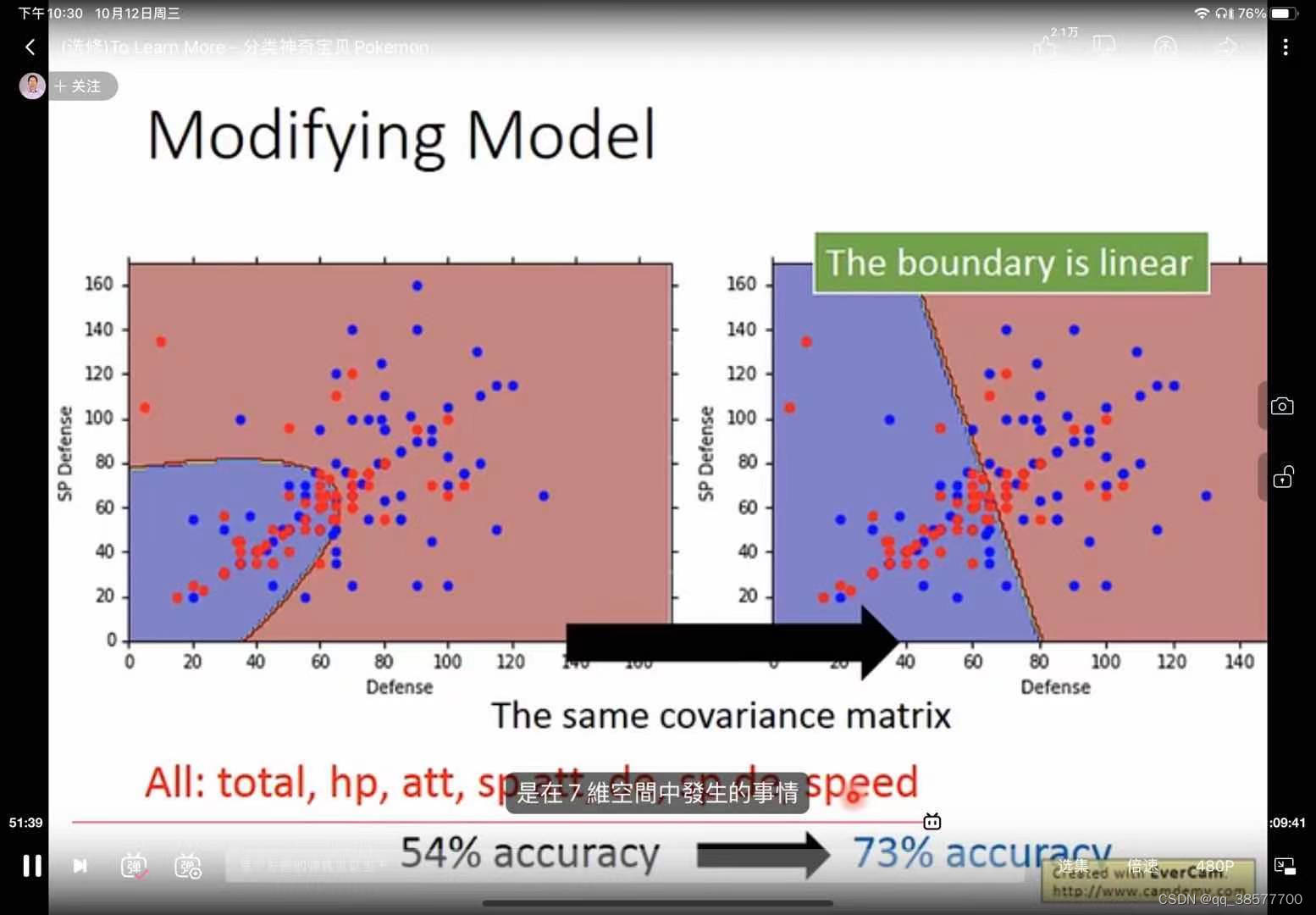






L是产生这么多数据的最大可能行

交叉熵对由于实际输出的可能性与我们认为 的可能性之间区别而产生不匹配,而产生的输出不确定性的一个指标。
这里表示为q和p分布的相似程度,交叉熵越高表示,相似程度越低

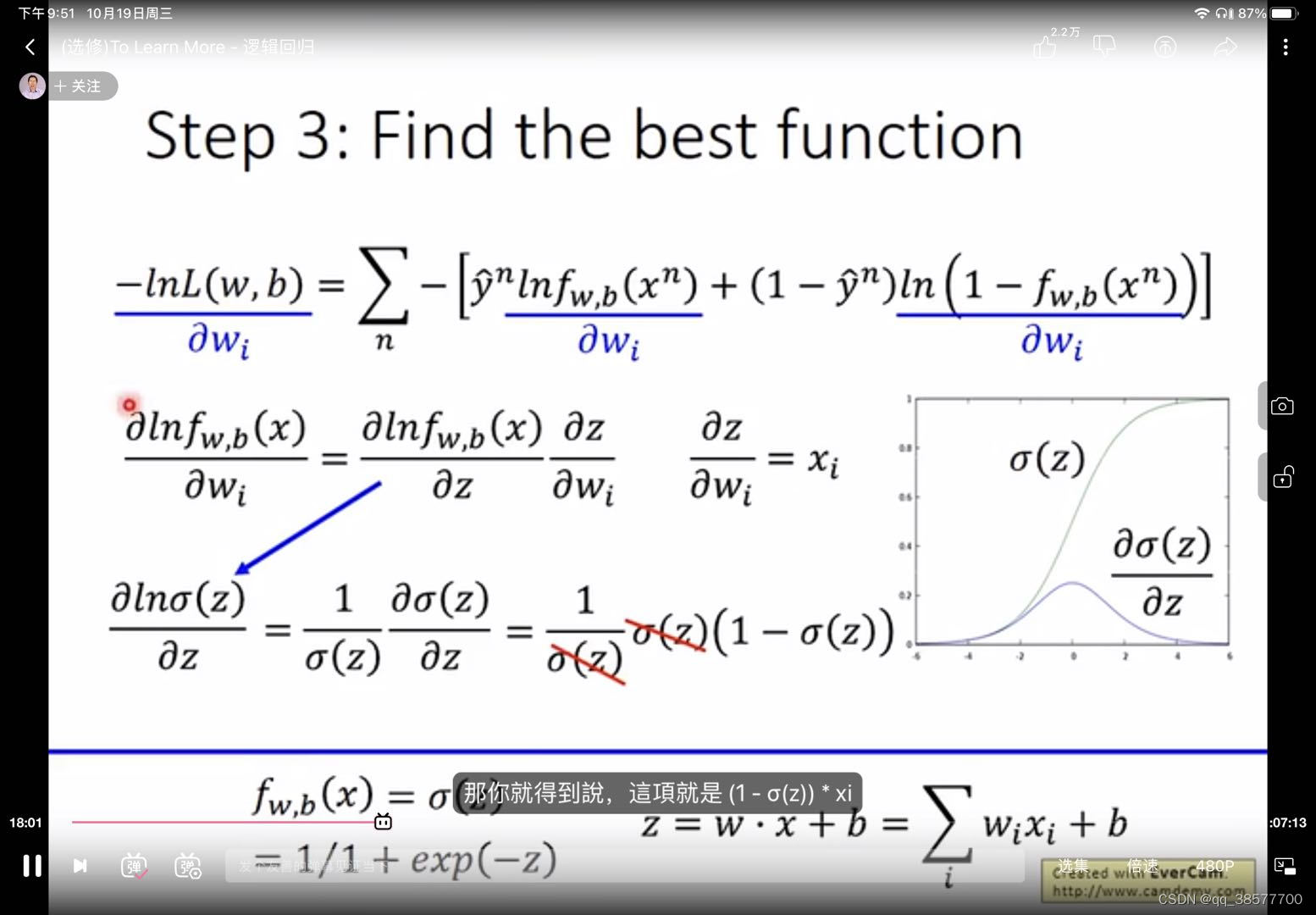

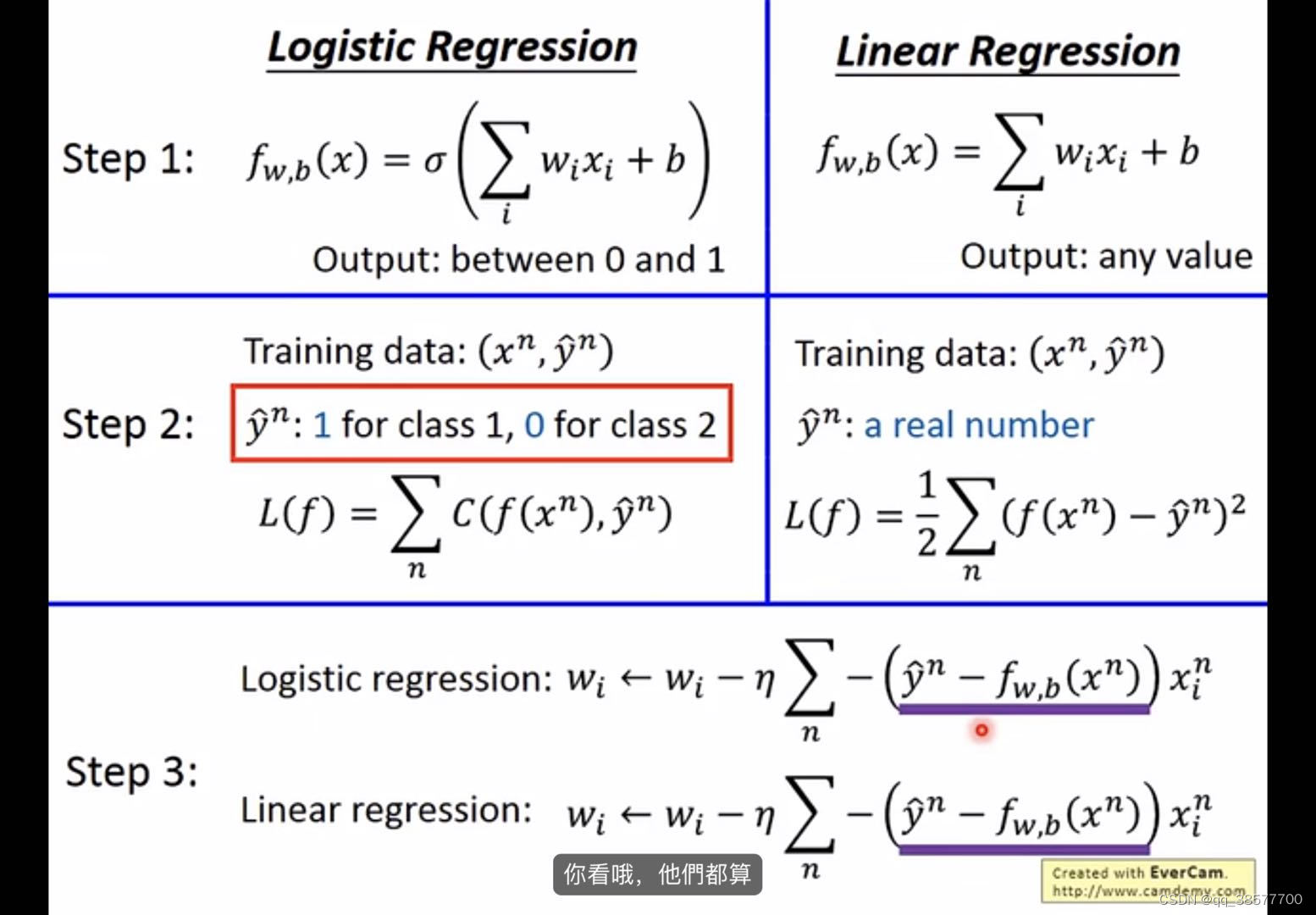
线性回归没有用sigmoid,所以没有梯度更新很慢的问题,可以使用MSE,但是逻辑回归可以用,但是gradient更新很慢,也不容易得到好的结果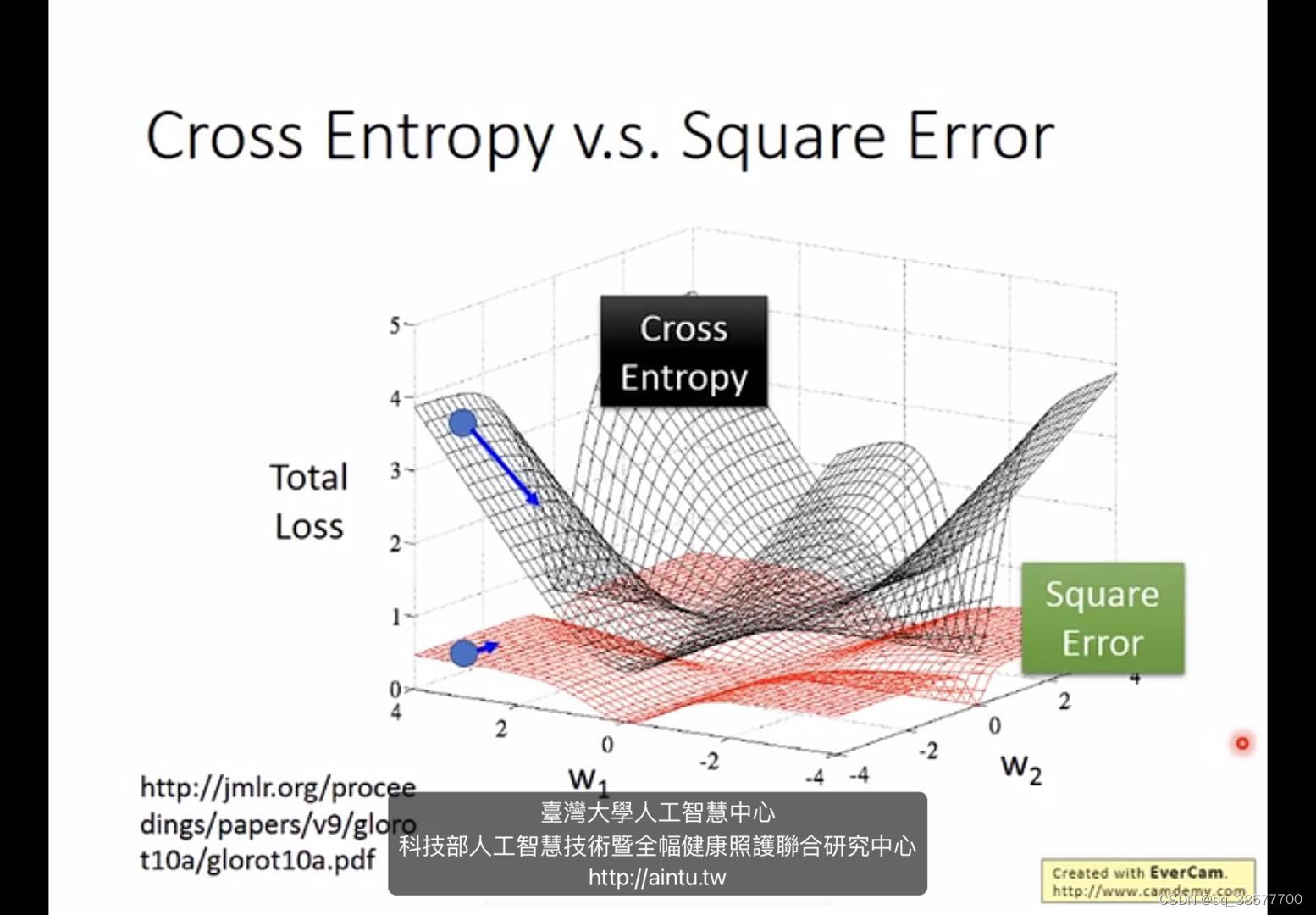
生成模型和判别模型
生成模型求得P(Y,X),对于未见示例X,你要求出X与不同标记之间的联合概率分布,然后大的获胜
判别模型由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻法、感知机、决策树、逻辑回归、最大熵、SVM、AdaBoost和条件随机场等。
- 生成模型受数据量的影响很小,但是判别模型会随着数据量的增加,模型的准确率会提高
- 生成模型可以一定程度忽视掉label noise
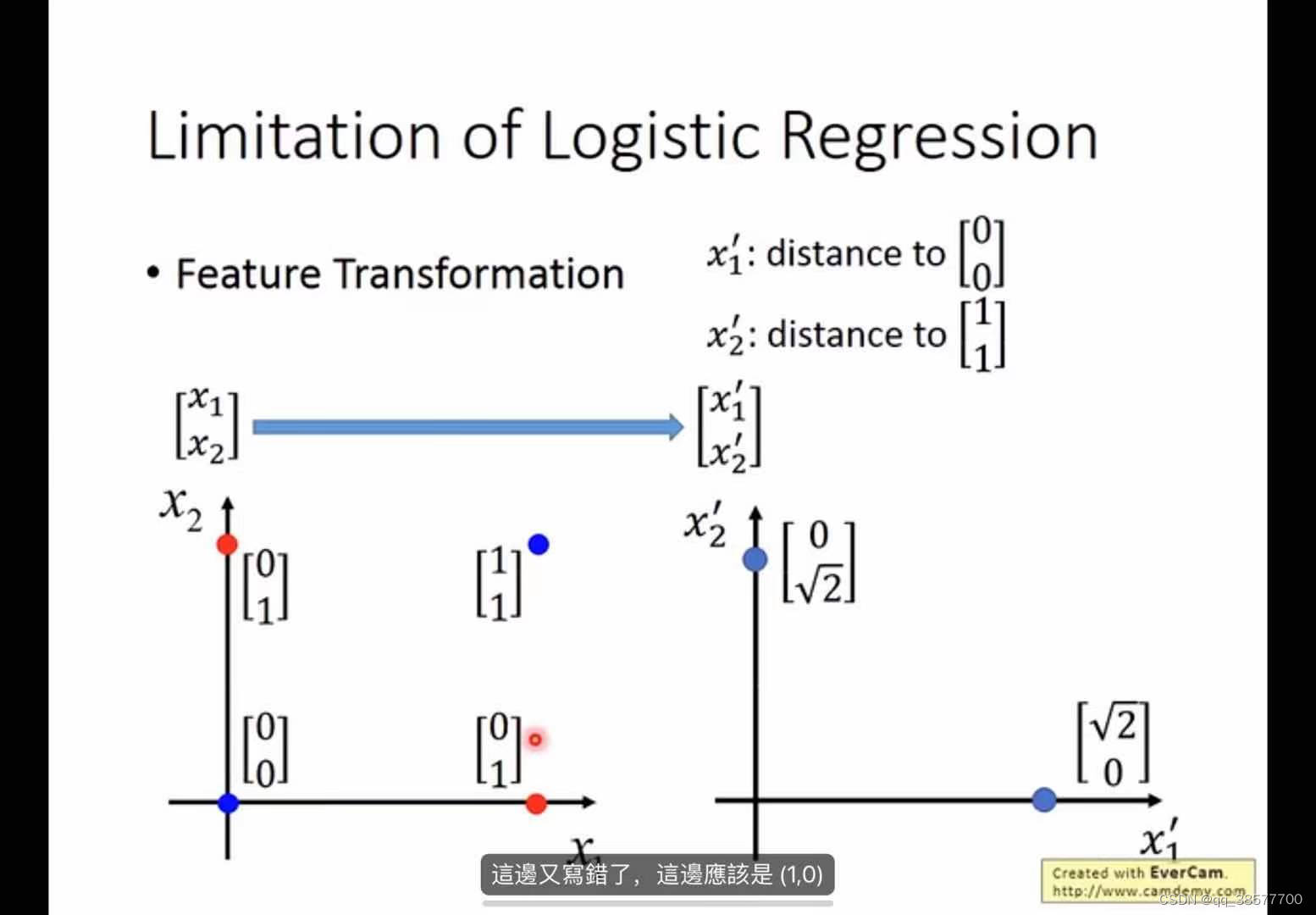
逻辑回归不能解决非线性问题,所以对特征做了feature transformation,但是这步是人为做的,怎么可以让机器实现这个呢,所有就有了级联逻辑回归模型
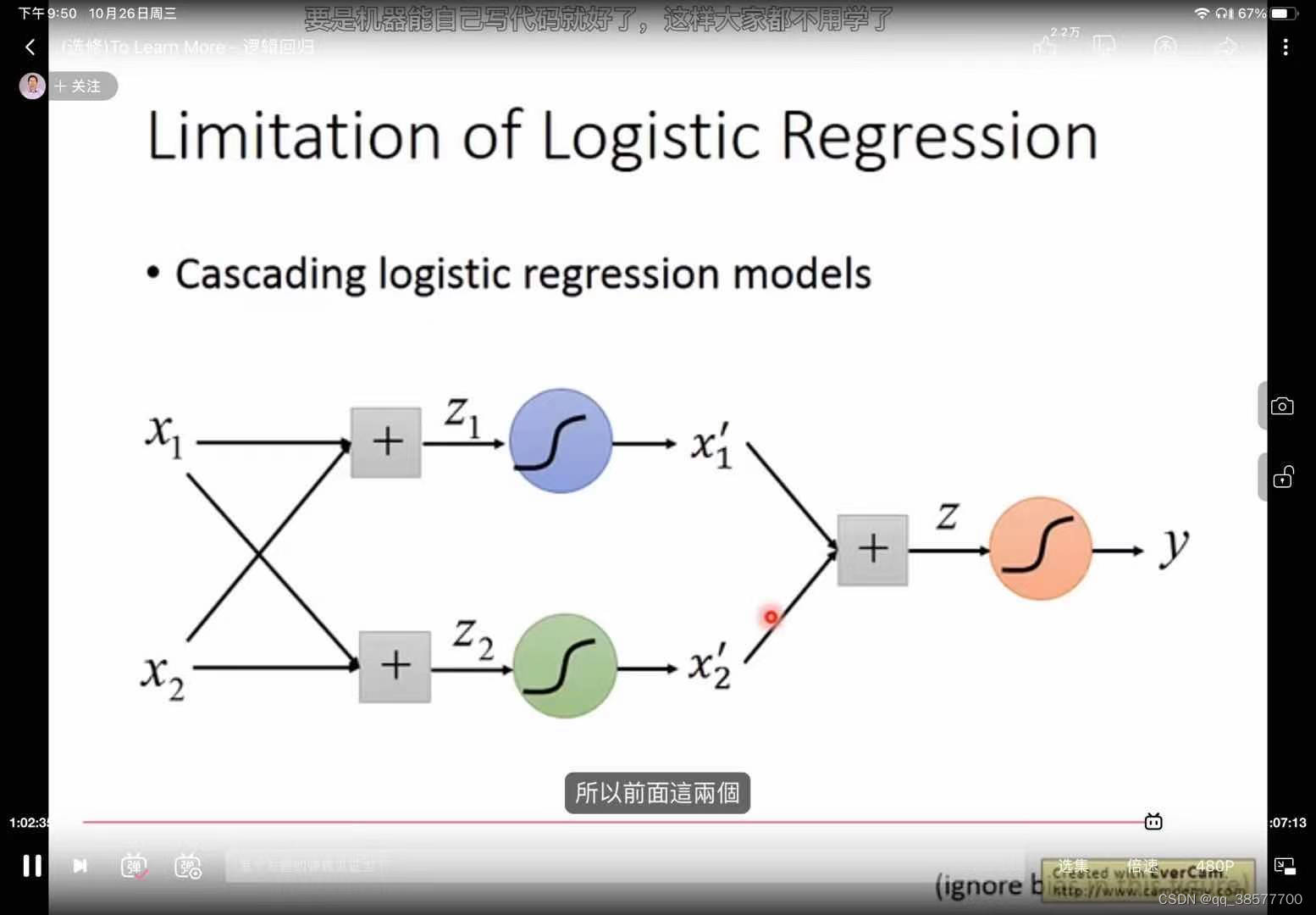
![Bandit算法学习[网站优化]03——Softmax 算法](https://note-image-1307786938.cos.ap-beijing.myqcloud.com/typora/image-20230105155120598.png)