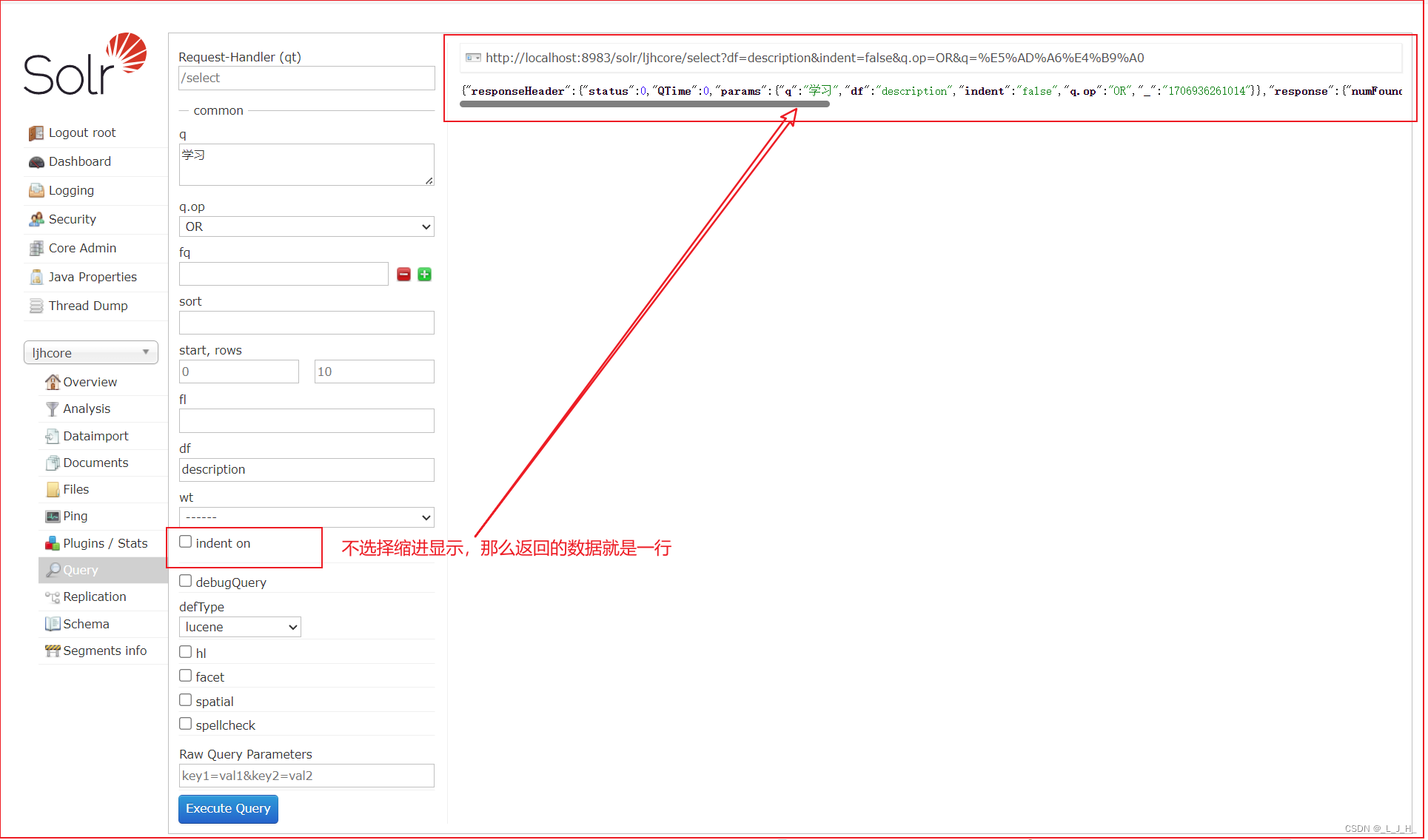
他往黑夜里去了,我陪他
——24.2.4
一、set集合
1.为什么使用集合?
通过特性来分析:
列表可修改、支持重复元素且有序
元组、字符串不可修改、支持重复元素且有序
局限在于:它们都支持重复元素
当场景需要对内容进行去重处理,列表、元组、字符串就不方便了
而集合最主要的特点是不支持重复元素(自带去重功能),并且内容无序
2.集合的定义
基本语法:
# 定义集合字面量
{元素,元素,……元素}
# 定义集合变量
变量名称 = {元素,元素,……元素}
# 定义空集合
变量名称 = set()
和列表、元组、字符串等定义基本相同
列表使用:[]
元组使用:()
字符串使用:""
集合使用:{}
#定义集合
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set_empty = set() #定义空集合
print(f"my_set的内容是:{my_set},类型是:{type(my_set)}")
print(f"my_set的内容是:{my_set_empty},类型是:{type(my_set_empty)}")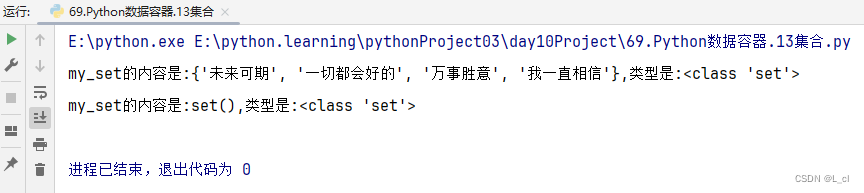
3.集合的使用
集合的常用操作——修改
首先,因为集合是无序的,所以集合不支持:下标索引访问
但是集合和列表一样,是允许修改的,集合的修改方法如下:
①添加新元素
语法:集合.add(元素)
功能:将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
#添加新元素
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set.add("苦难是花开的伏笔")
print(f"my_set添加元素后的结果是{my_set}")
②移除元素
语法:集合.remove(元素)
功能:将指定元素,从集合内删除
结果:集合本身被修改,移除了元素
#移除指定元素
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set.remove("未来可期")
print(f"my_set删除元素万事胜意后的结果是:{my_set}")
③从集合中随机取出元素
语法:集合.pop()
功能:从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
#随机取出一个元素
my_set = {"一切都会好的","万事胜意","未来可期"}
element = my_set.pop()
print(f"集合被取出元素是:{element},取出元素后的集合是:{my_set}")
④清空集合
语法:集合.clear()
功能:清空集合
结果:集合本身被清空
#清空集合,clear
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set.clear()
print(f"集合被清空后的结果是:{my_set}")
⑤求出2个集合的差集
语法:集合1.difference(集合2)
功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
#取出2个集合的差集
my_set1 = {"一切都会好的","万事胜意","未来可期"}
my_set2 = {"一切都会好的","万事胜意","未来可期","我一直相信","苦难是花开的伏笔"}
my_set3 = my_set2.difference(my_set1)
print(f"集合2有而集合1没有的元素是:{my_set3}")
⑥消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素
结果:集合1被修改,集合2不变
#消除两个集合的差集
my_set1 = {"一切都会好的","万事胜意","未来可期"}
my_set2 = {"一切都会好的","万事胜意","我一直相信","苦难是花开的伏笔"}
my_set1.difference_update(my_set2)
print(f"集合2是:{my_set2}")
print(f"集合1是:{my_set1}")
⑦两个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
#两个集合合并成一个集合
set1 = {1,2,3,4,7}
set2 = {2,5,6,7,8}
set3 = set1.union(set2)
print(f"集合1是:{set1}")
print(f"集合2是:{set2}")
print(f"集合3是:{set3}")
⑧统计集合中的元素数量
语法:len(集合名)
功能:统计集合中有几个元素
结果:得到集合中的元素个数
#统计集合中的元素数量len()
my_set = {"一切都会好的","万事胜意","我一直相信","苦难是花开的伏笔"}
num = len(my_set)
print(f"my_set中共有:{num}个元素")
⑨集合的遍历
集合不支持下标索引,所以不能使用while循环
但是可以使用for循环
#集合的遍历,for循环
set1 = {1,2,3,4,7}
for i in set1:
print(f"集合中的元素有{i}")
⑩总结
# 演示数据容器集合的使用
#定义集合
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set_empty = set() #定义空集合
print(f"my_set的内容是:{my_set},类型是:{type(my_set)}")
print(f"my_set的内容是:{my_set_empty},类型是:{type(my_set_empty)}")
#添加新元素
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set.add("苦难是花开的伏笔")
print(f"my_set添加元素后的结果是:{my_set}")
#移除指定元素
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set.remove("未来可期")
print(f"my_set删除元素万事胜意后的结果是:{my_set}")
#随机取出一个元素
my_set = {"一切都会好的","万事胜意","未来可期"}
element = my_set.pop()
print(f"集合被取出元素是:{element},取出元素后的集合是:{my_set}")
#清空集合,clear
my_set = {"一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信"}
my_set.clear()
print(f"集合被清空后的结果是:{my_set}")
#取出2个集合的差集
my_set1 = {"一切都会好的","万事胜意","未来可期"}
my_set2 = {"一切都会好的","万事胜意","未来可期","我一直相信","苦难是花开的伏笔"}
my_set3 = my_set2.difference(my_set1)
print(f"集合2有而集合1没有的元素是:{my_set3}")
#消除两个集合的差集
my_set1 = {"一切都会好的","万事胜意","未来可期"}
my_set2 = {"一切都会好的","万事胜意","我一直相信","苦难是花开的伏笔"}
my_set1.difference_update(my_set2)
print(f"集合2是:{my_set2}")
print(f"集合1是:{my_set1}")
#两个集合合并成一个集合
set1 = {1,2,3,4,7}
set2 = {2,5,6,7,8}
set3 = set1.union(set2)
print(f"集合1是:{set1}")
print(f"集合2是:{set2}")
print(f"集合3是:{set3}")
#统计集合中的元素数量len()
my_set = {"一切都会好的","万事胜意","我一直相信","苦难是花开的伏笔"}
num = len(my_set)
print(f"my_set中共有:{num}个元素")
#集合的遍历,for循环
set1 = {1,2,3,4,7}
for i in set1:
print(f"集合中的元素有{i}")
4.集合的特点
①可以容纳多个数据
②可以容纳不同类型的数据(混装)
③数据是无序存储的(不支持下标索引)
④不允许重复数据存在
⑤可以修改(增加或删除元素等)
⑥支持for循环
5.练习——信息去重
有如下列表对象:
my_list = ["一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信","苦难是花开的伏笔","一切都会好的","我一直相信"]
要求:
①定义一个空集合
②通过for循环遍历列表
③在for循环中将列表的元素添加至集合
④最终得到元素去重后的集合对象,并打印输出
#定义一个空集合
my_set = set()
#for循环遍历链表
my_list = ["一切都会好的","万事胜意","未来可期","我一直相信","一切都会好的","万事胜意","未来可期","我一直相信","苦难是花开的伏笔","一切都会好的","我一直相信"]
for i in my_list:
#添加元素到集合内部
my_set.add(i)
#最终打印出来
print(f"通过for循环遍历去重后的链表为:{my_set}")
二、dict字典
1.为什么使用字典?
使用字典,可以通过用一个key数据取出对应的value数据的值
2.字典的定义
字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:
#定义字典字面量
{key:value,key:value,……,key:value}
#定义字典变量
my_dict = {key:value,key:value,……,key:value}
#定义空字典
my_dict = {} # 空字典定义方式1
my_dict = dict() # 空字典定义方式2
# 定义字典
my_dict1 = {"张三":27,"李四":19,"王五":23}
# 定义空字典
my_dict2 = {}
my_dict3 = dict()
print(f"字典1的内容是:{my_dict1},类型:{type(my_dict1)}")
print(f"字典2的内容是:{my_dict2},类型:{type(my_dict2)}")
print(f"字典3的内容是:{my_dict3},类型:{type(my_dict3)}")
# 定义重复key的字典
my_dict4 = {"张三":99,"李四":81,"张三":27}
print(f"重复字典为:{my_dict4}")
3.字典数据的获取
字典同集合一样,不可以使用下标索引
但是字典可以通过key值来取得对应的value
语法:字典[key]可以取到对应的value
# 从字典中基于key获取value
my_dict1 = {"张三":27,"李四":19,"王五":23}
print(my_dict1["张三"])
print(my_dict1["李四"])
print(my_dict1["王五"])
age1 = my_dict1["张三"]
print(f"张三的年纪为:{age1}")
4.字典的嵌套
字典的key和value可以是任意数据类型(key不可为字典)
那么,就表明,字典是可以嵌套的
# 定义嵌套字典
stu_score_dict = {
"王里宏":{"语文":77,"数学":66,"英语":33},
"周杰论":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
print(f"学生的考试信息为:{stu_score_dict}")
![]()
5.从嵌套字典中获取数据
# 定义嵌套字典
stu_score_dict = {
"王里宏":{"语文":77,"数学":66,"英语":33},
"周杰论":{"语文":88,"数学":86,"英语":55},
"林俊节":{"语文":99,"数学":96,"英语":66}
}
print(f"学生的考试信息为:{stu_score_dict}")
# 从嵌套字典中获取数据
score = stu_score_dict["周杰论"]["数学"]
print(f"周杰论的数学信息是:{score}")
6.字典的常用操作
1.新增元素
语法:字典[key] = value
结果:字典被修改,新增了元素
#新增元素
my_dict = {"张三":99,"李四":85,"王五":77}
my_dict["小明"] = 67
print(f"字典经过更新元素后的结果是:{my_dict}")
![]()
2.更新元素
语法:字典[key] = value
结果:字典被修改,元素被更新
注意:字典key不可以重复,所以对已存在的key执行上述操作,就是更新value的值
#更新元素
my_dict = {"张三":99,"李四":85,"王五":77}
my_dict["张三"] = 87
print(f"字典经过更新元素后的结果是:{my_dict}")
![]()
3.删除元素
语法:字典.pop(key)
结果:获得指定key的value,同时字典被修改,指定key的数据被删除
#删除元素
my_dict = {"张三":99,"李四":85,"王五":77}
score = my_dict.pop("王五")
print(f"字典中被移除一个元素后结果是:{my_dict},王五的考试分数是:{score}")
![]()
4.清空元素
语法:字典名.clear
#清空元素
my_dict.clear()
print(f"字典被清空后是:{my_dict}")
5.获取全部的key
语法:字典.keys(),结果:得到字典中的全部key
#获取全部的key
my_dict = {"张三":99,"李四":85,"王五":77}
keys = my_dict.keys()
print(f"字典中的key值有:{keys}")![]()
6.遍历字典
获取全部的key,通过全部的key对字典进行遍历
语法: for key in keys/字典名:
#获取全部的key
my_dict = {"张三":99,"李四":85,"王五":77}
keys = my_dict.keys()
print(f"字典中的key值有:{keys}")
#遍历字典
for key in keys:
print(f"字典的key是{key}")
print(f"字典的value是{my_dict[key]}")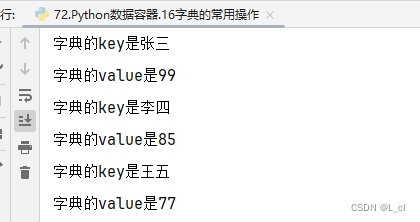
7.统计字典内的元素数量
语法:len(字典名)
#统计字典内的元素数量
num = len(my_dict)
print(f"字典内的元素数量是:{num}")
7.字典的特点
①可以容纳多个数据
②可以容纳不同类型的数据
③每一份数据是KeyValue键值对
④可以通过key获取到value,key不可重复(重复会覆盖)
⑤不支持下标索引
⑥可以修改(增加或删除更新元素等)
⑦支持for循环,不支持while循环
8.练习——升职加薪
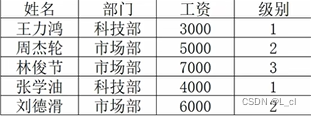
有如下员工信息,请使用字典完成数据的记录
并通过for循环,对所有级别为1级的员工,级别上升一级,薪水增加1000元
# 演示字典的课后练习,升职加薪,对所有级别为1级的员工,级别上升1级,薪水增加1000元
# 组织字典记录数据
info_dict = {
"王力鸿":{
"部门":"科技部",
"工资":3000,
"级别":1
},
"周杰轮":{
"部门": "市场部",
"工资": 5000,
"级别": 2
},
"林俊节":{
"部门": "市场部",
"工资": 7000,
"级别": 3
},
"张学油":{
"部门": "科技部",
"工资": 4000,
"级别": 1
},
"刘德滑":{
"部门": "市场部",
"工资": 6000,
"级别": 2
}
}
print(f"员工在升值加薪之前的结果:{info_dict}")
# for循环遍历字典
for i in info_dict:
#if条件判断符合条件员工
if info_dict[i]["级别"] == 1:
#升职加薪操作
#获取到员工的信息字典
employee_info_dict = info_dict[i]
#修改员工信息
employee_info_dict["级别"] = 2 #级别+1
employee_info_dict["工资"] += 1000 #工资+1000
#将员工信息更新回info_dict
info_dict[i] = employee_info_dict
# 输出结果
print(f"对员工进行升职加薪后的结果是:{info_dict}")