Hive架构

- 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)
- 元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore。
- Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
- 驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
Hive运行原理
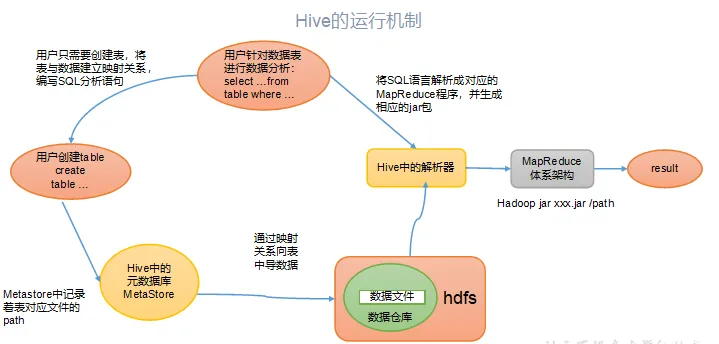
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
其实,还可以这样理解:Hive要做的就是将SQL翻译成MapReduce程序代码。实际上,Hive内置了很多Operator,每个Operator完成一个特定的计算过程,Hive将这些Operator构造成一个有向无环图DAG,然后根据这些Operator之间是否存在shuffle将其封装到map或者reduce函数中,之后就可以提交给MapReduce执行了。
内部表与外部表
不同点
1 外部表不会加载数据到Hive,减少数据传输、数据还能共享。
共享的理解就是:当我们删除一个内部表时,Hive 也会删除这个表中数据。内部表不适合和其他工具共享数据。
2 Hive创建内部表时,会将数据移动到数据仓库指向的路径。
创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
场景选择
在公司中绝大多数场景都是外部表。
自己使用的临时表,才会创建内部表。
Hive分区与分桶
Hive分区
是按照数据表的某列或者某些列分为多区,在hive存储上是hdfs文件,也就是文件夹形式。现在最常用的跑T+1数据,按当天时间分区的较多。
把每天通过sqoop或者datax拉取的一天的数据存储一个区,也就是所谓的文件夹与文件。在查询时只要指定分区字段的值就可以直接从该分区查找即可。创建分区表的时候,要通过关键字 partitioned by (column name string)声明该表是分区表,并且是按照字段column name进行分区,column name值一致的所有记录存放在一个分区中,分区属性name的类型是string类型。
当然,可以依据多个列进行分区,即对某个分区的数据按照某些列继续分区。
向分区表导入数据的时候,要通过关键字partition((column name="xxxx")显示声明数据要导入到表的哪个分区
设置分区的影响
- 首先是hive本身对分区数有限制,不过可以修改限制的数量。
set hive.exec.dynamic.partition=true;
set hive.exec.max.dynamic.partitions=1000;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.parallel.thread.number=264;- hdfs对单个目录下的目录数量或者文件数量也是有限制的,也是可以修改的;
- NN的内存肯定会限制,这是最重要的,如果分区数很大,会影响NN服务,进而影响一系列依赖于NN的服务。所以最好合理设置分区规则,对小文件也可以定期合并,减少NN的压力。
Hive的分桶
在分区数量过于庞大以至于可能导致文件系统崩溃时,我们就需要使用分桶来解决问题
分桶是相对分区进行更细粒度的划分。分桶则是指定分桶表的某一列,让该列数据按照哈希取模的方式随机、均匀地分发到各个桶文件中。因为分桶操作需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段) 要使用关键字clustered by 指定分区依据的列名,还要指定分为多少桶:
create table test(id int,name string) cluster by (id) into 5 buckets .......
insert into buck select id ,name from p cluster by (id)Hive分区分桶区别
- 分区是表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助。
- 不同于分区对列直接进行拆分,桶往往使用列的哈希值对数据打散,并分发到各个不同的桶中从而完成数据的分桶过程。
- 分区和分桶最大的区别就是分桶随机分割数据库,分区是非随机分割数据库。
函数
本环节不再介绍简单的函数,比如:'if' ,'is not null' ,'=='等等这类的函数。
内置函数
(1) NVL
给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL
select nvl(column, 0) from xxx;(2)行转列
| 函数 | 描述 |
| CONCAT(string A/col, string B/col…) | 返回输入字符串连接后的结果,支持任意个输入字符串 |
| CONCAT_WS(separator, str1, str2,...) | 第一个参数间的分隔符,如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间。 |
| COLLECT_SET(col) | 将某字段的值进行去重汇总,产生array类型字段 |
| COLLECT_LIST(col) | 函数只接受基本数据类型,它的主要作用是将某字段的值进行不去重汇总,产生array类型字段。 |
(3)列转行(一列转多行)
Split(str, separator): 将字符串按照后面的分隔符切割,转换成字符array。
EXPLODE(col):
将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW
用法:
LATERAL VIEW udtf(expression) tableAlias AS columnAlias解释:lateral view用于和split, explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
lateral view首先为原始表的每行调用UDTF,UDTF会把一行拆分成一或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
准备数据源测试
| movie | category |
| 《功勋》 | 记录,剧情 |
| 《战狼2》 | 战争,动作,灾难 |
SQL
SELECT movie,category_name
FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name ;测试结果
《功勋》 记录
《功勋》 剧情
《战狼2》 战争
《战狼2》 动作
《战狼2》 灾难窗口函数
(1)OVER()
定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
(2)CURRENT ROW(当前行)
语法
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据(3)UNBOUNDED(无边界)
UNBOUNDED PRECEDING 前无边界,表示从前面的起点
unbounded perceding/following
UNBOUNDED FOLLOWING后无边界,表示到后面的终点SQL案例:由起点到当前行的聚合
select
sum(money) over(partition by user_id order by pay_time rows between UNBOUNDED PRECEDING and current row)
from or_order;SQL案例:当前行和前面一行做聚合
select
sum(money) over(partition by user_id order by pay_time rows between 1 PRECEDING and current row)
from or_order;SQL案例:当前行和前面一行和后一行做聚合
select
sum(money) over(partition by user_id order by pay_time rows between 1 PRECEDING AND 1 FOLLOWING )
from or_order;SQL案例:当前行及后面所有行
select
sum(money) over(partition by user_id order by pay_time rows between current row and UNBOUNDED FOLLOWING )
from or_order;(4)LAG(col,n,default_val)
往前第n行数据,没有的话default_val
(5)LEAD(col,n, default_val)
往后第n行数据,没有的话default_val
SQL案例:查询用户购买明细以及上次的购买时间和下次购买时间
select
user_id,,pay_time,money,
lag(pay_time,1,'1970-01-01') over(PARTITION by name order by pay_time) prev_time,
lead(pay_time,1,'1970-01-01') over(PARTITION by name order by pay_time) next_time
from or_order;(6)FIRST_VALUE(col,true/false)
当前窗口下的第一个值,第二个参数为true,跳过空值。
(7)LAST_VALUE (col,true/false)
当前窗口下的最后一个值,第二个参数为true,跳过空值。
SQL案例:查询顾用户每个月第一次的购买时间 和 每个月的最后一次购买时间。
select
FIRST_VALUE(pay_time)
over(
partition by user_id,month(pay_time) order by pay_time
rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING
) first_time,
LAST_VALUE(pay_time)
over(partition by user_id,month(pay_time) order by pay_time rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING
) last_time
from or_order;(8)NTILE(n)
把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。(用于将分组数据按照顺序切分成n片,返回当前切片值)
SQL案例:查询前25%时间的订单信息
select * from (
select User_id,pay_time,money,
ntile(4) over(order by pay_time) sorted
from or_order
) t
where sorted = 1;4个By
(1)Order By
全局排序,只有一个Reducer。
(2)Sort By
分区内有序。
(3)Distrbute By
类似MR中Partition,进行分区,结合sort by使用。
(4) Cluster By
当Distribute by和Sorts by字段相同时,可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
在生产环境中Order By用的比较少,容易导致OOM。
在生产环境中Sort By+ Distrbute By用的多。
排序函数
(1)RANK()
排序相同时会重复,总数不会变
1
1
3
3
5(2)DENSE_RANK()
排序相同时会重复,总数会减少
1
1
2
2
3(3)ROW_NUMBER()
会根据顺序计算
1
2
3
4
5Hive 优化
首先要这样优化的原理,再去适当去调节参数和选择方案。
1. 表的优化
(1) 小表、大表Join
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的概率;再进一步,可以使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。
(2) 大表Join大表
a. 空key过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。
b. 空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。
(3) MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
设置自动选择Mapjoin
set hive.auto.convert.join = true; 默认为true
大表小表的阈值设置(默认25M以下认为是小表):
set hive.mapjoin.smalltable.filesize=25000000;(4) Group By
Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
(5) 开启Map端聚合
// 是否在Map端进行聚合,默认为True
set hive.map.aggr = true
// 在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
// 有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true对数据倾斜负载均衡的理解
会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
(6) Count(Distinct) 去重统计
由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换,但是需要注意group by造成的数据倾斜问题。
(7) 笛卡尔积
尽量避免笛卡尔积,join的时候不加on条件,或者无效的on条件,Hive只能使用1个reducer来完成笛卡尔积。
(8) 行列过滤
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤
2. 合理设置Map及Reduce数
首先理清楚Map数是越多越好吗?
逻辑:如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当作一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。
保证每个map处理接近128m的文件块是不是就可以了?
逻辑:比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时
复杂文件增加Map数
原理:文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
computeSliteSize(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M调整maxSize最大值。让maxSize最大值低于blocksize就可以增加map的个数。
小文件进行合并,减少map数
在map执行前合并小文件,减少map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;Map-Reduce的任务结束时合并小文件的设置
// 在map-only任务结束时合并小文件,默认true
SET hive.merge.mapfiles = true;
// 在map-reduce任务结束时合并小文件,默认false
SET hive.merge.mapredfiles = true;
// 合并文件的大小,默认256M
SET hive.merge.size.per.task = 268435456;
//当输出文件的平均大小小于该值时,启动一个独立的map-reduce任务进行文件merge
SET hive.merge.smallfiles.avgsize = 16777216;3. 合理设置Reduce数
同样考虑是不是越多越好?
过多的启动和初始化reduce也会消耗时间和资源。有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题。
(1)数据量设置
// 每个Reduce处理的数据量默认是256MB
hive.exec.reducers.bytes.per.reducer=256000000
// 每个任务最大的reduce数,默认为1009
hive.exec.reducers.max=1009
// 计算reducer数的公式
N=min(hive.exec.reducers.max,总输入数据量/hive.exec.reducers.bytes.per.reducer)(2)文件配置
mapreduce.job.reduces = 154. 并行执行
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。不过,在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。建议在数据量大,sql很长的时候使用,数据量小,sql比较的小开启有可能还不如之前快。
//打开任务并行执行,默认为false
set hive.exec.parallel=true;
//同一个sql允许最大并行度,默认为8。
set hive.exec.parallel.thread.number=16;5. JVM重用
JVM来执行map和Reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM重用可以使得JVM实例在同一个job中重新使用N次。
缺点是,开启JVM重用将一直占用使用到的task插槽,以便进行重用,直到任务完成后才能释放。
set mapreduce.job.jvm.numtasks=106. 列式存储
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性地设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
7. 压缩(选择快的)
// 启用中间数据压缩
set hive.exec.compress.intermediate=true
// 启用最终数据压缩
set mapreduce.map.output.compress=true
// 设置压缩方式
set mapreduce.map.outout.compress.codec=
org.apache.hadoop.io.compress.DefaultCodec
org.apache.hadoop.io.compress.GzipCodec
org.apache.hadoop.io.compress.BZip2Codec
org.apache.hadoop.io.compress.Lz4CodecHive数据倾斜
Hive数据倾斜表现
就是单说hive自身的MR引擎:发现所有的map task全部完成,并且99%的reduce task完成,只剩下一个或者少数几个reduce task一直在执行,这种情况下一般都是发生了数据倾斜。说白了就是Hive的数据倾斜本质上是MapReduce的数据倾斜。
Hive数据倾斜的原因
在MapReduce编程模型中十分常见,大量相同的key被分配到一个reduce里,造成一个reduce任务累死,其他reduce任务闲死。查看任务进度,发现长时间停留在99%或100%,查看任务监控界面,只有少量的reduce子任务未完成。
- key分布不均衡。
- 业务问题或者业务数据本身的问题,某些数据比较集中。
(1)join小表:其中一个表是小表,但是key比较集中,导致的就是某些Reduce的值偏高。
(2)空值或无意义值:如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。
(3)group by:维度过小。
(4)distinct:导致最终只有一个Reduce任务。
Hive数据倾斜解决
- group by代替distinct 要统计某一列的去重数时,如果数据量很大,count(distinct)就会非常慢,原因与order by类似,count(distinct)逻辑导致最终只有一个Reduce任务。
- 对1再优化:group by配置调整
(1)map端预聚合
(2)group by时,combiner在map端做部分预聚合,可以有效减少shuffle数据量。
(3)checkinterval:设置map端预聚合的行数阈值,超过该值就会分拆job。
hive.map.aggr=true //默认
hive.groupby.mapaggr.checkinterval=100000 // 默认(4)倾斜均衡配置 Hive自带了一个均衡数据倾斜的配置项。
其实现方法是在group by时启动两个MR job。第一个job会将map端数据随机输入reducer,每个reducer做部分聚合,相同的key就会分布在不同的reducer中。第二个job再将前面预处理过的数据按key聚合并输出结果,这样就起到了均衡的效果。
hive.groupby.skewindata=false // 默认- join基础优化
(1) Hive在解析带join的SQL语句时,会默认将最后一个表作为大表,将前面的表作为小表,将它们读进内存。如果表顺序写反,如果大表在前面,引发OOM。不过现在hive自带优化。
(2) map join:特别适合大小表join的情况,大小表join在map端直接完成join过程,没有reduce,效率很高。
(3)多表join时key相同:会将多个join合并为一个MR job来处理,两个join的条件不相同,就会拆成多个MR job计算。
- sort by代替order by
将结果按某字段全局排序,这会导致所有map端数据都进入一个reducer中,在数据量大时可能会长时间计算不完。使用sort by,那么还是会视情况启动多个reducer进行排序,并且保证每个reducer内局部有序。为了控制map端数据分配到reducer的key,往往还要配合distribute by一同使用。如果不加distribute by的话,map端数据就会随机分配到reducer。
- 单独处理倾斜key
一般来讲倾斜的key都很少,我们可以将它们抽样出来,对应的行单独存入临时表中,然后打上随机数前缀,最后再进行聚合。或者是先对key做一层hash,先将数据随机打散让它的并行度变大,再汇集。其实办法一样。

![[Angular 基础] - Angular 渲染过程 组件的创建](https://img-blog.csdnimg.cn/direct/ae6669b1941641fdb35724349183c360.png)
![[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--强化学习、模仿学习、机器人](https://img-blog.csdnimg.cn/direct/94a059d47b7345caab5f15c18a675253.jpeg#pic_center)



![龙龙送外卖pta[代码+讲解]](https://img-blog.csdnimg.cn/direct/0a9f9eeadd694c509554edfa1c927a2a.png)