十、消息队列服务器——RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、 安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
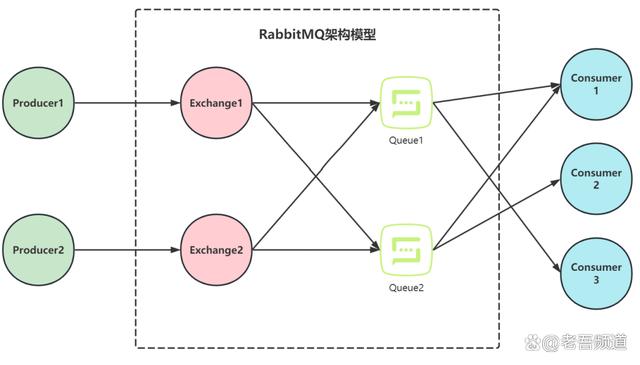
- Channel:网络信道,读写都是在Channel中进行(NIO的概念),包括对MQ进行的一些操作(例如clear queue等)都是在Channel中进行,客户端可建立多个Channel,每个Channel代表一个会话任务
- Message:由properties(有消息优先级、延迟等特性)和Body(消息内容)组成
- Exchange:Routing and Filter7、Binding:把Exchange和Queue进行Binding8、Routing key:路由规则
- Binding:把Exchange和Queue进行Binding
- Routing key:路由规则
- 优点:
- 解除业务系统之间的耦合,降低系统之间的依赖关系
- 实现消息的异步处理,无需同步等待
- 削峰填谷,将流量从高峰期引到低谷期进行处理
- 缺点:
- 增加了系统的复杂度,带入了幂等、重复消费、消息丢失的问题
- 系统的可用性比原先要低,MQ挂了以后,整个系统也会崩溃.
- 消费端数据一致性问题
- 使用场景
- 消息订阅
- 日志采集
- 埋点
- 订单
基于消息的模型,关心的是“通知”,而非“处理”.
在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦.
为了保证库存肯定有,可以将队列大小设置成库存数量,或者采用其他方式解决。
四种交换机(Exchange)
- i. 直连交换机,Direct exchange:带路由功能的交换机,根据routing_key(消息发送的时候需要指定)直接绑定到队列,⼀个交换机也可以通过过个routing_key绑定多个队列。
- ii. 扇形交换机,Fanout exchange:⼴播消息。
- iii. 主题交换机,Topic exchange:发送到主题交换机上的消息需要携带指定规则的routing_key,主题交换机会根据这个规则将数据发送到对应的(多个)队列上。
- iv. ⾸部交换机,Headers exchange:⾸部交换机是忽略routing_key的⼀种路由⽅式。路由器和交换机路由的规则是通过Headers信息来交换的,这个有点像HTTP的Headers。将⼀个交换机声明成⾸部交换机,绑定⼀个队列的时候,定义⼀个Hash的数据结构,消息发送的时候,会携带⼀组hash数据结构的信息,当Hash的内容匹配上的时候,消息就会被写⼊队列。
1. 在RabbitMQ集群中的节点只有两种类型:内存节点/磁盘节点,单节点系统只运行磁盘类型的节点。而在集群中,可以选择配置部分节点为内存节点。
2. 内存节点将所有的队列,交换器,绑定关系,用户,权限,和vhost的元数据信息保存在内存中。
3. 磁盘节点将这些信息保存在磁盘中,但是内存节点的性能更高,为了保证集群的高可用性,必须保证集群中有两个以上的磁盘节点,来保证当有一个磁盘节点崩溃了,集群还能对外提供访问服务
两种模式
主从模式:默认的集群模式、(高性能)
- 内存节点的性能只能体现在资源管理上,比如增加或删除队列(queue),虚拟主机(vrtual hosts),交换机(exchange)等,发送和接受message速度同磁盘节点一样。
- rabbitmq集群中可以共享user,vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务。
- 消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。
## 消费流程
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点,从中取消息。
## 故障处理
该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;
这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
镜像模式:高可用性
消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用
搭建注意
- 各节点之间使用“–link”连接,此属性不能忽略。
- 各节点使用的 erlang cookie 值必须相同,此值相当于“秘钥”的功能,用于各节点的认证。
- 整个集群中必须包含一个磁盘节点。
问题
如何保证MQ中消息不会丢失?
- RabbitMQ允许将消息标记为持久化,这意味着消息将会被写入磁盘而不是仅保存在内存中。这样,在消息发送到队列之后,即使RabbitMQ服务器发生故障或重启,消息也能够存储在磁盘上,并在恢复后仍然可用。
- 生产者发生异常没有把消息成功发送给MQ,MQ成功接收到消息之后发生宕机了,消息未被成功,消费消费端要设置签收机制为手动签收,只有当消息最终被处理,才告诉MQ已经消费,此时MQ再去删除这条消息。
- 消息预取(Message Prefetch):RabbitMQ允许消费者一次从队列中获取多个消息,并将它们存储在本地缓冲区中。这样可以提高消费者的效率,并减少消费者与RabbitMQ服务器之间的通信次数。
/*消息持久化方法?
1.声明交换机Exchange的时候设置 durable=true;
2.声明队列Queue的时候设置 durable=true;
3.发送消息的时候设置消息的 deliveryMode = 2;*/
//public TopicExchange(String name, boolean durable, boolean autoDelete)
return new TopicExchange(EXCHANGE_NAME,true,false);
//durable:是否将队列持久化 true表示需要持久化 false表示不需要持久化
return new Queue(QUEUE_NAME, false);
new MessageProperties() --> DEFAULT_DELIVERY_MODE = MessageDeliveryMode.PERSISTENT --> deliveryMode = 2;
如何解决消息堆积?
- 启动多个消费者微服务
- 优化消费者处理消息的能力,提高消费消息的性能
- 调整RabbitMQ的队列容量
- 设置过期时间,让一些不是那么重要的消息到达指定时间之后就丢弃
- 将无法被消费的消息放到死信队列(DLQ)中
如何解决消息被重复消费?
- 生产者发送消息的时候带上一个全局唯一的id,消费者拿到消息后,先根据这个id去 Redis 里查一下,之前有没消费过,没有消费过就处理,并且写入这个id到 Redis,如果消费过了,则不处理。
- 基于数据库的唯一键
- 消费者端幂等性:设计消费者端的处理逻辑具有幂等性。即无论消息被处理多次,最终结果都保持一致。这样,即使消息被重复消费,也不会对最终结果产生影响。
RabbitMQ 中 vhost 的作用是什么?
vhost:每个 RabbitMQ 都能创建很多 vhost,我们称之为虚拟主机,每个虚拟主机其实都是 mini 版的RabbitMQ,它拥有自己的队列,交换器和绑定,拥有自己的权限机制,主要是为了隔离,vhost 不仅消除了为基础架构中的每一层运行一个RabbitMq服务器的需要, 童谣避免为每一层创建不同的集群.
RabbitMQ 集群中唯一一个磁盘节点崩溃了会发生什么情况?
如果唯一磁盘的磁盘节点崩溃了,
唯一磁盘节点崩溃了,集群是可以保持运行的,但你不能更改任何东西。
RabbitMQ 每个节点是其他节点的完整拷贝吗?为什么?
不是,原因有以下两个:
-
存储空间的考虑:如果每个节点都拥有所有队列的完全拷贝,这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据;
-
性能的考虑:如果每条消息都需要完整拷贝到每一个集群节点,那新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟
rabbitMQ节点的关闭顺序?
在关闭 RabbitMQ 集群时,应该先关闭从节点,然后再关闭主节点。这是因为从节点的状态是依赖于主节点的,如果先关闭主节点,可能会导致从节点无法正常工作。
十一、分布式应用程序协调服务——ZooKeeper
ZooKeeper 是一个开源的分布式协调框架,它的定位是为分布式应用提供一致性服务,是整个大数据体系的管理员。ZooKeeper 会封装好复杂易出错的关键服务,将高效、稳定、易用的服务提供给用户使用。
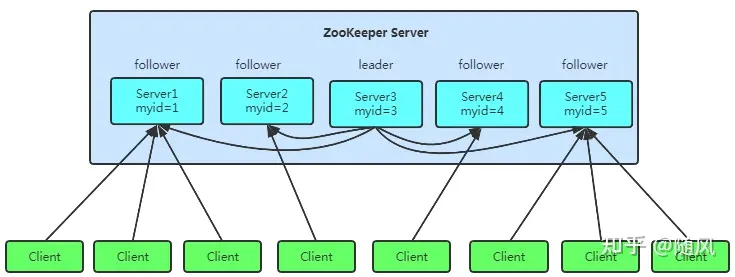
特点
- 集群:Zookeeper是一个领导者(Leader),多个跟随者(Follower)组成的集群。
- 高可用性:集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序进行:来自同一个Client的更新请求按其发送顺序依次执行。
- 数据更新原子性:一次数据更新要么成功,要么失败。
- 实时性:在一定时间范围内,Client能读到最新数据。
- 从
设计模式角度来看,zk是一个基于观察者设计模式的框架,它负责管理跟存储大家都关心的数据,然后接受观察者的注册,数据反生变化zk会通知在zk上注册的观察者做出反应。
Zookeeper 有三种部署模式:
单机部署:一台集群上运行;
集群部署:多台集群运行;
伪集群部署:一台集群启动多个 Zookeeper 实例运行。
Zookeeper 保持主从节点的同步?
Zookeeper 的核心是原子广播机制,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
为什么要有主节点?
在分布式环境中,有些业务逻辑只需要集群中的某一台机器进行执行,其他的机器可以共享这个结果,这样可以大大减少重复计算,提高性能
ZooKeeper文件系统
ZooKeeper文件系统(ZooKeeper File System,ZFS)是ZooKeeper提供的一种类似于文件系统的数据模型,可以帮助用户通过树形节点结构,对ZooKeeper中的数据进行管理和访问。
在ZFS中,数据存储以节点(ZNode)的形式组织,每个ZNode可以保存一个Byte数组,同时也可以是一个目录节点,包含了子节点的信息。用户可以通过ZFS的API接口,对节点进行创建、读取、更新和删除等操作。
ZFS的根节点是"/“,通过这个节点,用户可以访问整个ZooKeeper文件系统。节点名字可以是任何的字符串,但是不能重复,节点名字可以有多级,中间用”/ "隔开。例如,/myapp/config是一个典型的ZFS节点路径。
ZNode节点四种类型:
- 持久节点(persistent):这是最常见的节点类型,一旦创建,将一直存在于ZooKeeper的目录结构中,直到显式删除。
- 临时节点(ephemeral):临时节点是指在创建客户端会话期间存在的节点。当客户端会话结束(由于某种原因)时,节点将被自动删除。临时节点非常有用,它们可以用于表示客户端会话是否处于特定状态。
- 有序节点(sequential):有序节点还可以与上述两种节点类型结合使用,这样可以创建名称自动带有序增量的节点。有序节点用于排序构造出一种递增的节点名称集合。
- 临时顺序节点(ephemeral sequential):这是一种组合节点类型,是临时节点和顺序节点的组合。这种节点将在客户端会话期间存在,并带有一个顺序号。当会话终止时,顺序号将自动从数据库中删除。
监听通知流程
- 在main线程中创建Zookeeper客户端,这时就会创建两个线程,一个负责网络连接通信(connet),一个负责监听(listener)。
- 通过connect线程将注册的监听事件发送给Zookeeper。
- 在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中。
- Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程。
- listener线程内部调用了process()方法。
- ZooKeeper 支持watch(观察)的概念。客户端可以在每个znode节点上设置一个观察。如果被观察服务端的znode结点有变更,那么watch就会被触发,这个watch所属的客户端将接收到一个通知包被告知结点已经发生变化,把相应的事件通知给设置过Watcher的Client端。
应用场景
1. 数据发布/订阅
当某些数据由几个机器共享,且这些信息经常变化数据量还小的时候,这些数据就适合存储到ZK中。
- 数据存储:将数据存储到 Zookeeper 上的一个数据节点。
- 数据获取:应用在启动初始化节点从 Zookeeper 数据节点读取数据,并在该节点上注册一个数据变更 Watcher
- 数据变更:当变更数据时会更新 Zookeeper 对应节点数据,Zookeeper会将数据变更通知发到各客户端,客户端接到通知后重新读取变更后的数据即可。
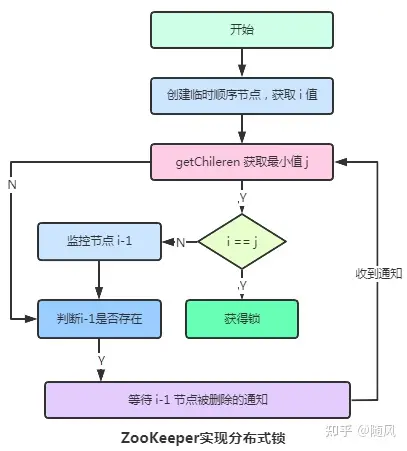
2. 分布式锁
主要是避免了羊群效应,临时节点已经预先存在,所有想要获得锁的线程在它下面创建临时顺序编号目录节点,编号最小的获得锁,用完删除,后面的依次排队获取。
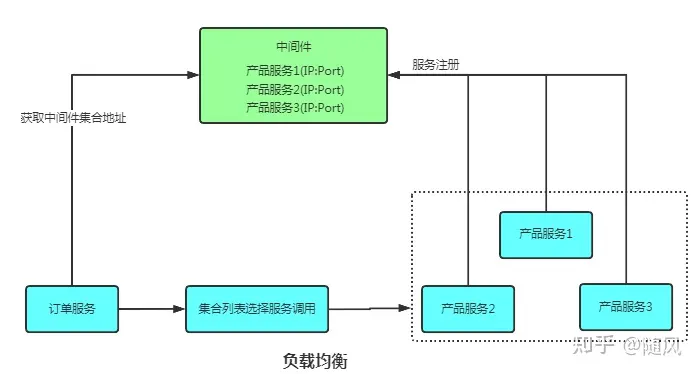
3. 负载均衡
- 多个服务注册
- 客户端获取中间件地址集合
- 从集合中随机选一个服务执行任务
利用 zk 创建一个全局唯一的路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。
-
Leader选举
利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /Master 节点,最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很轻易的在分布式环境中进行集群选举了。
就是动态Master选举。这就要用到 EPHEMERAL_SEQUENTIAL类型节点的特性了,这样每个节点会
自动被编号。允许所有请求都能够创建成功,但是得有个创建顺序,每次选取序列号最小的那个机器作为Master 。
## ZooKeeper集群节点个数一定是奇数个
在节点数量是奇数个的情况下, zookeeper集群总能对外提供服务(即使损失了一部分节点);如果节点数量是偶数个,会存在zookeeper集群不能用的可能性(脑裂成两个均等的子集群的时候)。