文章目录
- 布隆过滤器
- 1. 原理
- 2. 结构和操作
- 3. 特点和应用场景
- 4. 缺点和注意事项
- 应用-redis插件布隆过滤器使用详细过程
- 安装以及配置
- springboot项目使用redis布隆过滤器
- 下面是布隆过滤器的一些基础命令
- 扩展
布隆过滤器
Bloom 过滤器是一种概率型数据结构,用于快速判断一个元素是否属于一个集合。它以较小的空间占用和高效的查询时间著称。下面将对 Bloom 过滤器进行详细阐述。
1. 原理
Bloom 过滤器基于哈希函数和位数组实现。它的核心思想是使用多个哈希函数将元素映射到位数组中,并将对应的位设置为1。当查询一个元素时,通过对该元素进行相同的哈希计算,检查对应的位是否都为1。如果其中有任何一位为0,则可以确定该元素不在集合中;如果所有位都为1,则该元素可能在集合中,但并不确定,存在一定的概率误判。
2. 结构和操作
- 位数组(Bit Array):Bloom 过滤器使用一个固定长度的位数组来表示集合,并初始化为全0。每个元素通过多个哈希函数映射到位数组上的多个位置。
- 哈希函数(Hash Function):Bloom 过滤器使用多个独立的哈希函数,每个哈希函数可以将一个元素映射到位数组的不同位置。常用的哈希函数包括 MurmurHash、FnvHash、SHA 等。
- 添加元素(Add Element):当向 Bloom 过滤器中添加一个元素时,将该元素经过多个哈希函数的计算得到的位置对应的位设置为1。
- 查询元素(Query Element):当查询一个元素时,通过多个哈希函数计算出对应的位置,并检查这些位置上的位是否都为1。如果有任何一位为0,则可以确定该元素不在集合中;如果所有位都为1,则该元素可能在集合中。
3. 特点和应用场景
- 空间效率高:Bloom 过滤器使用位数组表示集合,所需的内存空间相对较小,与集合大小无关。
- 查询效率高:由于只需计算多个哈希函数并检查位数组上的位,查询时间较短,通常为常数时间复杂度。
- 概率误判:Bloom 过滤器在判断一个元素不在集合中时,永远是准确的;但在判断一个元素在集合中时,存在一定的概率误判。误判率取决于哈希函数的个数和位数组的大小。
- 应用场景:Bloom 过滤器适用于需要快速判断元素是否属于一个大规模集合的场景,如网页爬虫中的 URL 去重、缓存穿透的防护、垃圾邮件过滤等。
4. 缺点和注意事项
- 无法删除元素:Bloom 过滤器的位数组一旦被置为1,就无法撤销。因此,无法从 Bloom 过滤器中删除元素。
- 哈希函数选择:选择合适的哈希函数和哈希函数的数量非常重要。哈希函数应具有较低的冲突率,并且应该尽量使用独立性较强的哈希函数。
- 误判率:误判率取决于哈希函数的个数和位数组的大小。通过调整这些参数可以降低误判率,但也会增加空间占用和查询时间。
- 适用范围:Bloom 过滤器适用于对查询时间和空间占用有较高要求,而对概率误判可以接受的场景。在对精确性要求较高的情况下,Bloom 过滤器可能不适用。
总而言之,Bloom 过滤器是一种高效的概率型数据结构,通过位数组和多个哈希函数实现快速的集合元素判断。它在一些特定的应用场景中具有很大的优势,但需要注意选择合适的哈希函数和参数设置,以及理解概率误判的特性。
应用-redis插件布隆过滤器使用详细过程
安装以及配置
布隆过滤器有很多,我这里用的redis提供的布隆过滤器,这次使用的是用docker安装的redis以及配置布隆过滤器
1. 首先下载布隆过滤器这个插件
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
下载以后解压备用一会等着放到redis中
2.docker安装redis
首先创建文件夹以及配置文件,用于挂在redis启动的后容器中的文件,方便我们在容器外部操作redis的配置
创建文件夹
mkdir data ##创建文件
touch redis.conf ## 创建文件
在创建完文件夹以后将我们第一步中下载并解压好的布隆过滤器的文件夹放到我们创建的data文件夹下

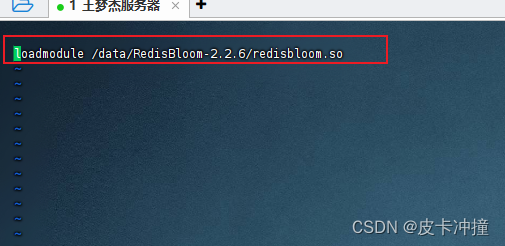
在我们创建的redis.conf文件中添加一行配置loadmodule /data/RedisBloom-2.2.6/redisbloom.so
随后直接使用dokcer run命令进行启动,如果没有安装redis则进行下载
docker run -p 6379:6379 --name redis -v /root/redis/data:/data -v /root/redis/redis.conf:/etc/redis/redis.conf --restart=always --network host -d redis:5.0.7 redis-server /etc/redis/redis.conf
这个命令是用于在 Docker 中运行 Redis 容器,并进行一些配置。下面是对每个参数的解释:
-p 6379:6379: 将 Docker 容器的端口 6379 映射到主机的端口 6379,以便可以从主机访问 Redis 服务。--name redis: 指定容器的名称为 “redis”。-v /root/redis/data:/data: 将主机的/root/redis/data目录挂载到容器的/data目录,用于持久化保存 Redis 数据。-v /root/redis/redis.conf:/etc/redis/redis.conf: 将主机的/root/redis/redis.conf配置文件挂载到容器的/etc/redis/redis.conf,使用该配置文件作为 Redis 的配置。--restart=always: 设置容器在退出时自动重新启动。--network host: 使用主机网络模式,容器将共享主机的网络栈。-d: 在后台运行容器。redis:5.0.7: 指定使用的 Redis 镜像及其版本号。redis-server /etc/redis/redis.conf: 在容器中执行的命令,即启动 Redis 服务器,并使用指定的配置文件。
执行上述操作redis容器如果启动没有问题那么我们的布隆过滤器的插件和redis都安装并启动成功了,如果没有启动成功可以通过docker logs 查看一下redis的启动过程中出现什么问题
下面连接redis执行下面的代码查看否布隆过滤器安装成功
bf.add user test
解释一下:bf.add 是安装布隆过滤器后才可以使用的命令,这是添加一个key的命令,user是过滤器的名字,而tese就是我们要去添加的key
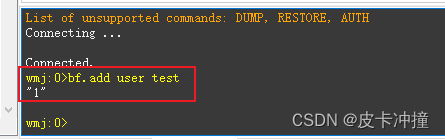
这是添加成功的标识。
springboot项目使用redis布隆过滤器
上面我们把布隆过滤器安装成功了,那么下面介绍一下在项目中如何应用这个过滤器如何通过代码来去和过滤器交互
我这里使用的redis的过滤器所以用到的依赖直接使用的spring-data-redis这个就可以了
<!--redis的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
引入依赖以后我们配置封装一个用于调用过滤器的工具类
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.data.redis.core.script.RedisScript;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
@Component
public class RedisBloomUtil {
@Autowired
private RedisTemplate redisTemplate;
// 初始化一个布隆过滤器
public Boolean tryInitBloomFilter(String key, long expectedInsertions, double falseProbability) {
Boolean keyExist = redisTemplate.hasKey(key);
if(keyExist) {
return false;
}
RedisScript<Boolean> script = new DefaultRedisScript<>(bloomInitLua(), Boolean.class);
RedisSerializer stringSerializer = redisTemplate.getStringSerializer();
redisTemplate.execute(script, stringSerializer, stringSerializer, Collections.singletonList(key), falseProbability+"", expectedInsertions+"");
return true;
}
// 添加元素
public Boolean addInBloomFilter(String key, Object arg) {
RedisScript<Boolean> script = new DefaultRedisScript<>(addInBloomLua(), Boolean.class);
return (Boolean) redisTemplate.execute(script, Collections.singletonList(key), arg);
}
@Transactional
// 批量添加元素
public Boolean batchAddInBloomFilter(String key, Object... args) {
RedisScript<Boolean> script = new DefaultRedisScript<>(batchAddInBloomLua(), Boolean.class);
return (Boolean) redisTemplate.execute(script, Collections.singletonList(key), args);
}
// 查看某个元素是否是存在
public Boolean existInBloomFilter(String key, Object arg) {
RedisScript<Boolean> script = new DefaultRedisScript<>(existInBloomLua(), Boolean.class);
return (Boolean) redisTemplate.execute(script, Collections.singletonList(key), arg);
}
// 批量查看元素是否存在
public List batchExistInBloomFilter(String key, Object... args) {
RedisScript<List> script = new DefaultRedisScript(batchExistInBloomLua(), List.class);
List<Long> results = (List) redisTemplate.execute(script, Collections.singletonList(key), args);
List<Boolean> booleanList = results.stream().map(res -> res == 1 ? true : false).collect(Collectors.toList());
return booleanList;
}
private String bloomInitLua() {
return "redis.call('bf.reserve', KEYS[1], ARGV[1], ARGV[2])";
}
private String addInBloomLua() {
return "return redis.call('bf.add', KEYS[1], ARGV[1])";
}
private String batchAddInBloomLua() {
StringBuilder sb = new StringBuilder();
sb.append("for index, arg in pairs(ARGV)").append("\r\n");
sb.append("do").append("\r\n");
sb.append("redis.call('bf.add', KEYS[1], arg)").append("\r\n");
sb.append("end").append("\r\n");
sb.append("return true");
return sb.toString();
}
private String existInBloomLua() {
return "return redis.call('bf.exists', KEYS[1], ARGV[1])";
}
private String batchExistInBloomLua() {
StringBuilder sb = new StringBuilder();
sb.append("local results = {}").append("\r\n");
sb.append("for index, arg in pairs(ARGV)").append("\r\n");
sb.append("do").append("\r\n");
sb.append("local exist = redis.call('bf.exists', KEYS[1], arg)").append("\r\n");
sb.append("table.insert(results, exist)").append("\r\n");
sb.append("end").append("\r\n");
sb.append("return results;");
return sb.toString();
}
}
下面是布隆过滤器的一些基础命令
在 Redis 中,可以使用 RedisBloom 模块来实现布隆过滤器。RedisBloom 是一个开源模块,提供了一系列命令来操作布隆过滤器。下面是 RedisBloom 模块中常用的命令集合:
-
BF.ADD:向布隆过滤器中添加一个元素。
BF.ADD <key> <item> -
BF.EXISTS:检查一个元素是否存在于布隆过滤器中。
BF.EXISTS <key> <item> -
BF.MADD:向布隆过滤器中批量添加多个元素。
BF.MADD <key> <item> [item ...] -
BF.MEXISTS:批量检查多个元素是否存在于布隆过滤器中。
BF.MEXISTS <key> <item> [item ...] -
BF.INFO:获取布隆过滤器的信息,包括容量、误判率等。
BF.INFO <key> -
BF.RESERVE:创建一个新的布隆过滤器,并指定容量和误判率。
BF.RESERVE <key> <error_rate> <capacity> -
BF.COUNT:统计布隆过滤器中已添加的元素数量。
BF.COUNT <key> -
BF.DEBUG:调试命令,用于打印布隆过滤器内部的一些调试信息。
BF.DEBUG <subcommand> [arguments ...]
我上面提供的工具类就是封装的这些命令。
扩展
关于布隆过滤器我们在使用的是注意点,就是在我上面说到的测试一下是否安装成功时使用的添加数据的命令,bf.add 过滤器名称 key,但是我并没有创建那个名字为user的过滤器,是因为这是程序帮我创建了一个叫做user的过滤器,这个过滤器的配置都是一些基础的配置,比如初始容量是100 错误率是0.01也就是百分之一的错误率,这个过滤明显不能满足我们的需要因为过滤器的工作原理就是通过多个哈希函数对key进行计算然后记录下来,那么容量就决定了在计算的过程中发生碰撞的概率大小了,所以我们在使用的时候一定要去手动创建过滤器以确保满足自己的需要。



![【C++入门到精通】C++的IO流(输入输出流) [ C++入门 ]](https://img-blog.csdnimg.cn/direct/686178f7f6ea4d23a2e3953d816d3215.png)



![[开源]基于野火指南者的MQTT框架+FreeRTOS移植(使用板载esp8266模块)](https://img-blog.csdnimg.cn/img_convert/0f5cd8ce06b632951e6a6e4f79fa31e1.png)