上一篇已经对赛题进行详细分析了,而且大方向和基本的模型已经确定完毕,数据集都已经找到了,现在最重要的就是要分析风暴数据集以及建立时序预测模型,使用气候模型预测的数据,评估气候变化对未来极端天气事件频率和强度的影响。来看极端天气频率是否会上升,以及如何利用历史气象数据来支撑我们的模型效果。

对于每个时序预测模型都有各自特点最优的使用场景,但是一般来说大部分时间序列数据都呈现出季节变化(Season)和循环波动(Cyclic)。对于在这些数据基础之上进行的建模一般最优是采用季节性时序预测SARIMA模型。当然此篇文章我将尽力让大家了解并熟悉SARIMA模型算法框架,保证能够理解通畅以及推演顺利的条件之下,尽量不使用过多的数学公式和专业理论知识。以一篇文章快速了解并实现该算法,以效率最高的方式熟练使用此方法。

博主专注建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。参与过十余次数学建模大赛,三次美赛获得过二次M奖一次H奖,国赛二等奖。希望各位以后遇到建模比赛可以艾特一下我,我可以提供免费的思路和部分源码,以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路。博主紧跟各类数模比赛,另外再向大家推荐一下笔者精心打造的专栏。此专栏的目的就是为了让零基础快速使用各类数学模型以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全可运行代码。希望有需求的小伙伴不要错过笔者精心打造的文章。
一文速学-数学建模常用模型
一、数据预处理
我们需要对数据集进行细化处理,也就是减少地理维度空间,按照经度纬度来划分一块区域,因为地理区域存在多样性,所以我们首先挑选一块区域只包含宾夕法尼亚州范围内数据进行分析。
def LAT_df(storm_df):
# Define the latitude and longitude range for Pennsylvania
lat_min_pa, lat_max_pa = 39.0, 42.0 # Approximate latitude range for Pennsylvania
lon_min_pa, lon_max_pa = -80.5, -75.0 # Approximate longitude range for Pennsylvania
# Filter the DataFrame for entries within Pennsylvania's latitude and longitude range
pa_storm_data = storm_df[
(storm_df['LATITUDE'] >= lat_min_pa) & (storm_df['LATITUDE'] <= lat_max_pa) &
(storm_df['LONGITUDE'] >= lon_min_pa) & (storm_df['LONGITUDE'] <= lon_max_pa)
]
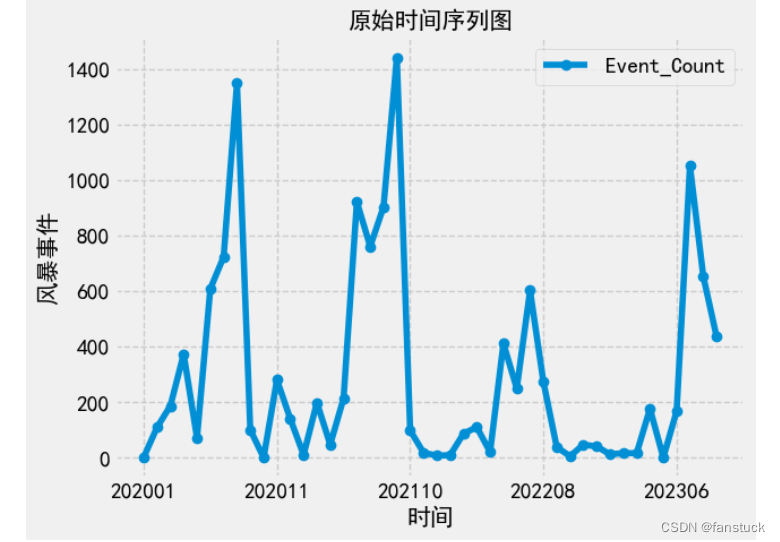
return pa_storm_data因为存在每个季节性波动,固选择四年的数据作为预览,根据时间月颗粒度进行分组统计,最后可视化展示数据:
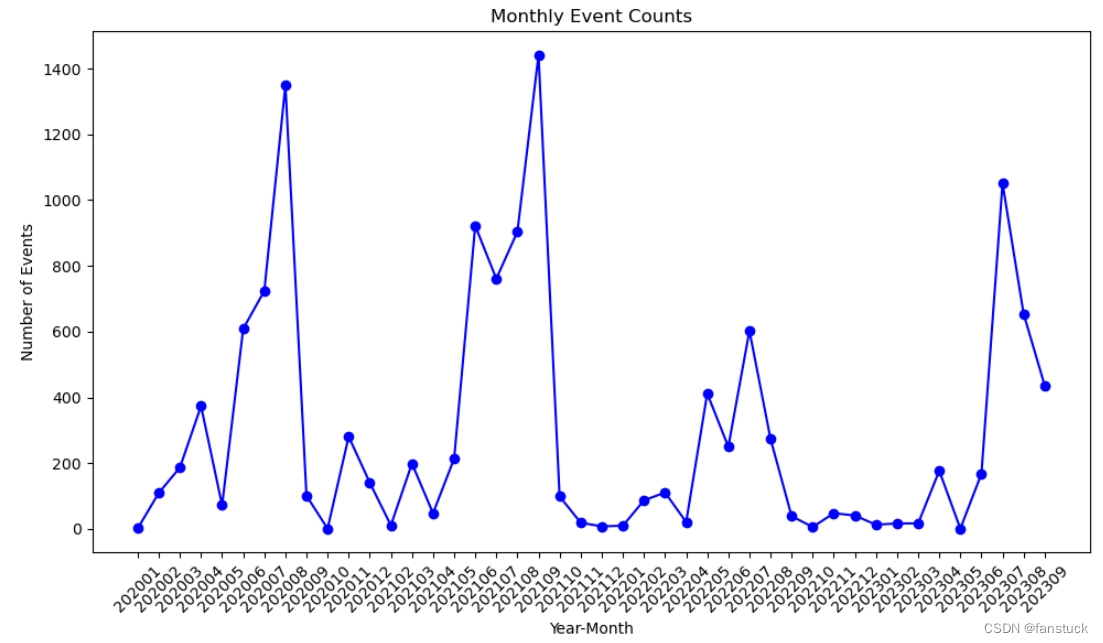
我们可以清楚的发现数据是存在季节性波动的,固数据处理部分我们就得出了结论,进而给我们挑选SARIMA模型有了合适的理由。
二、SARIMA模型建模
SARIMA模型建模步骤如下所示:
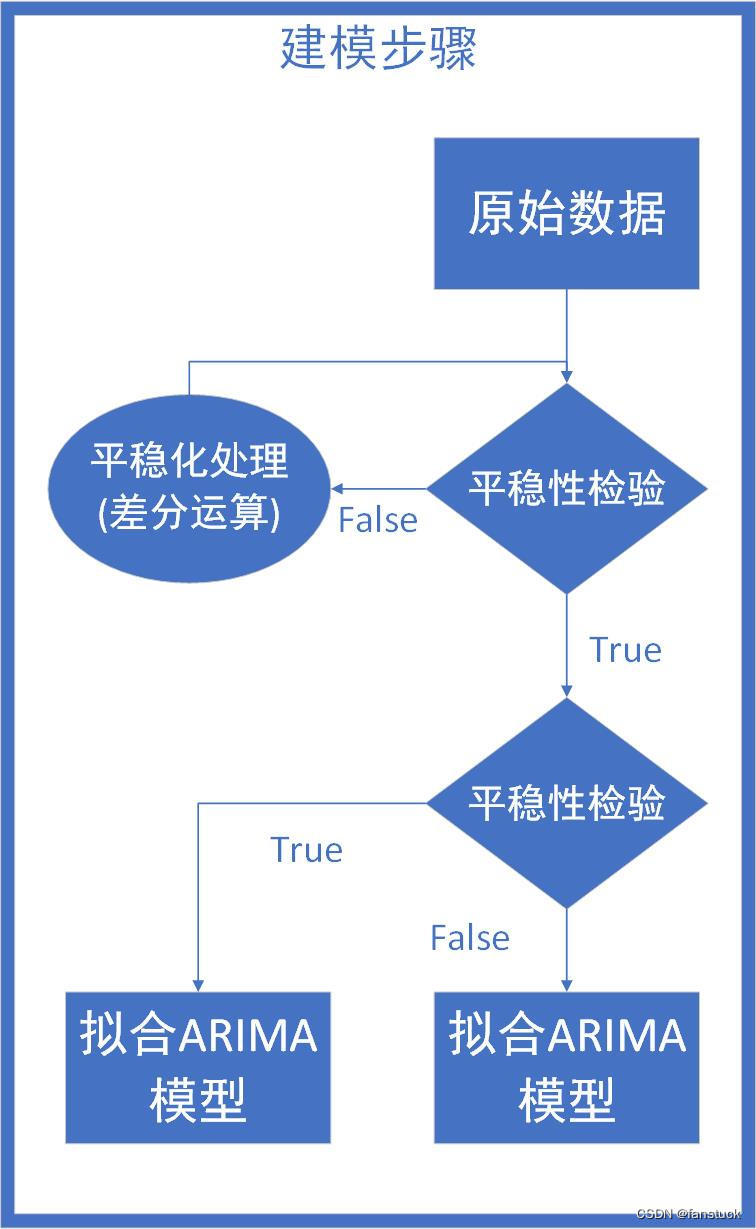
一文速学数模-季节性时序预测SARIMA模型详解+Python实现
大家对SARIMA模型不熟悉的推荐去看本博主的博客,时间紧迫暂时不给大家讲解模型原理。

1.数据预处理
根据建模步骤我们首先对时间序列数据进行平稳性校验和季节性差分等操作。如果数据不平稳,需要进行差分操作使其变为平稳时间序列。同时,如果数据具有季节性,需要对其进行季节性差分,消除季节性影响。
我们先导入相应模块:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
from matplotlib.pylab import rcParams
import pmdarima as pm
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf # 画图定阶
from statsmodels.tsa.stattools import adfuller # ADF检验
from statsmodels.stats.diagnostic import acorr_ljungbox # 白噪声检验
import warnings
import itertools
warnings.filterwarnings("ignore") # 选择过滤警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签季节性分析
还需要再检验,同时可以使用seasonal_decompose()进行分析,将时间序列分解成长期趋势项(Trend)、季节性周期项(Seansonal)和残差项(Resid)这三部分。
from statsmodels.tsa.seasonal import seasonal_decompose
# 分解数据查看季节性 freq为周期
# 推断频率参数
ts_decomposition = seasonal_decompose(df_evel_timese['Event_Count'], period=12)
ts_decomposition.plot()
plt.show() 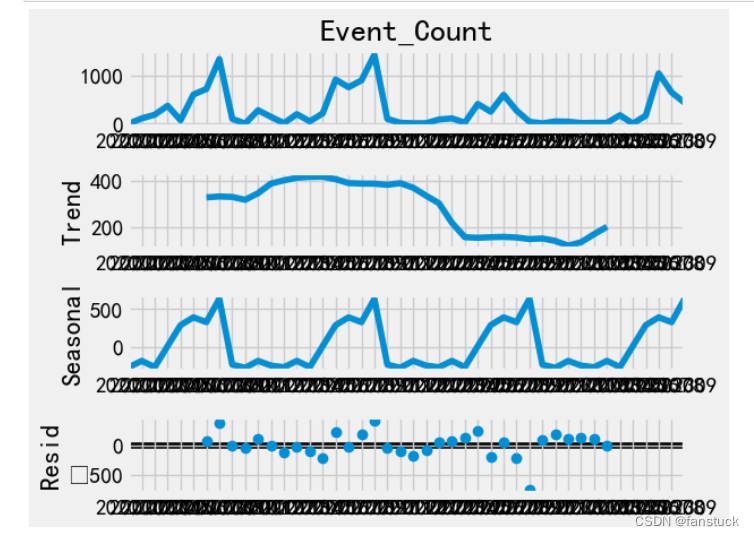
ADF检验
ARIMA模型要求时间序列是平稳的。所谓平稳性,其基本思想是:决定过程特性的统计规律不随着时间的变化而变化。由平稳性的定义:对于一切t,s,Y{t}和Y{s}的协方差对于时间的依赖之和时间间隔|t-s|有关,而与实际的时刻t和s无关。因此,平稳过程可以简化符号,其中Cov为自协方差函数,Corr为自相关函数。
关于严宽平稳我之前写自回归模型(AR)已经写的很清楚了。如果通过时间序列图来用肉眼观看的话可能会存在一些主观性。ADF检验(又称单位根检验)是一种比较常用的严格的统计检验方法。
ADF检验主要是通过判断时间序列中是否含有单位根:如果序列平稳,就不存在单位根;否则,就会存在单位根。
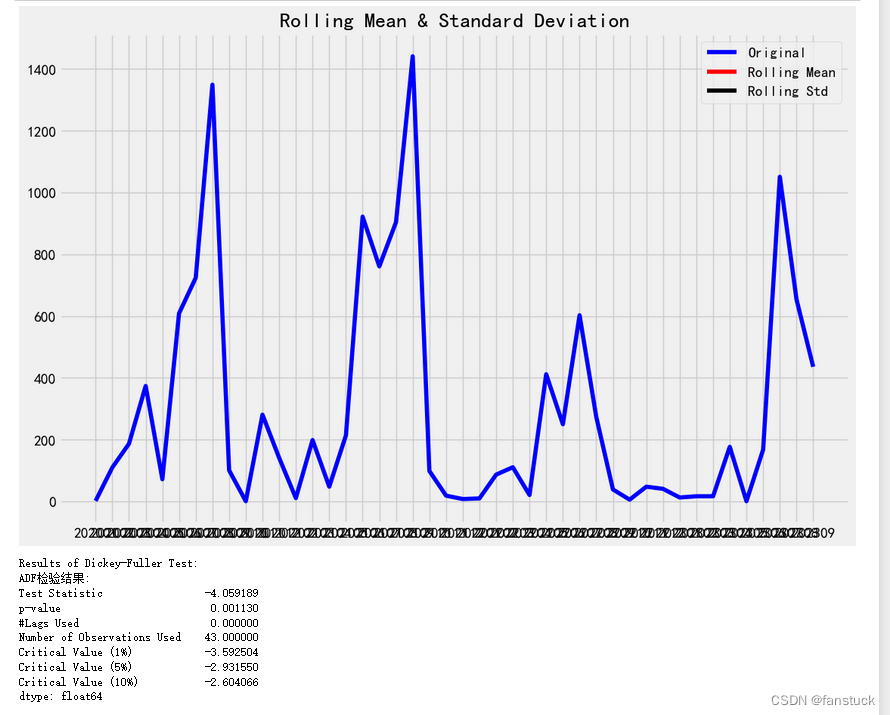
ADF检验结果提供了关于时间序列是否具有单位根,即是否是非平稳的信息。这里是对结果的分析:
-
Test Statistic (-4.059189): 这是ADF检验的统计值,用于比较临界值来决定是否拒绝原假设。原假设是时间序列具有单位根,即是非平稳的。
-
p-value (0.001130): p值用于衡量测试统计量的显著性。在这个案例中,p值小于0.05,意味着你可以在95%的置信水平下拒绝原假设,即时间序列是平稳的。
-
#Lags Used (0.000000): 在进行ADF检验时使用的滞后阶数。这表示在计算ADF统计量时,考虑了0个滞后期。
-
Number of Observations Used (43.000000): 在检验中使用的观察数,不包括用于计算滞后的观察值。
-
Critical Value (1%, -3.592504): 在1%的显著性水平下,拒绝原假设的临界值。你的测试统计量比这个值更负,因此在1%的显著性水平下,你可以拒绝原假设。
-
Critical Value (5%, -2.931550) 和 (10%, -2.604066): 这些是在5%和10%的显著性水平下,拒绝原假设的临界值。你的测试统计量同样比这些值更负,意味着在这些显著性水平下也可以拒绝原假设。
结论
基于ADF检验的结果,测试统计量远小于所有临界值,且p值远小于0.05,因此我们有足够的证据拒绝原假设,认为时间序列是平稳的。这意味着时间序列不具有单位根,变化不依赖于时间。这是进行时间序列分析和建模的一个重要前提,例如在应用ARIMA模型之前确保时间序列的平稳性。
2.SARIMA建模
在确定SARIMA模型的参数后,需要进行模型检验,以检查模型是否符合预期。检验方法包括残差序列的自相关函数和偏自相关函数的图形分析,Ljung-Box检验、Shapiro-Wilk检验等方法。如果模型不符合预期,则需要调整模型参数,重新拟合模型,直到得到满意的结果。
白噪声检验
接下来,对d阶差分后的的平稳序列进行白噪声检验,如果平稳序列是非白噪声序列,那么说明它不是由随机噪声组成的。这意味着序列中存在一些内在的结构或模式,这些结构或模式可以被进一步分析和建模,以便进行预测或其他目的。白噪音在我写AR模型的时候同样也写了这也不再补充。
我们可以通过Ljung-Box检验,是时间序列分析中检验序列自相关性的方法。LB检验的Q统计量为:
![]()
def whiteNoiseCheck(data):
result = acorr_ljungbox(data, lags=1)
temp = result.iloc[:,1].values[0]
#print(result.iloc[:,1].values[0])
print('白噪声检验结果:', result)
# 如果temp小于0.05,则可以以95%的概率拒绝原假设,认为该序列为非白噪声序列;否则,为白噪声序列,认为没有分析意义
print(temp)
return result
ifwhiteNoise = whiteNoiseCheck(df_evel_timese_diff2)-
lb_stat (8.733887): 这是Ljung-Box统计量,用于检验数据中是否存在自相关性。较大的统计量值可能表明存在自相关性。
-
lb_pvalue (0.003123): 这是Ljung-Box检验的p值,用于判断统计量的显著性。p值小于显著性水平(通常是0.05)时,我们拒绝时间序列是白噪声的原假设,即存在自相关性。
分析
-
由于p值为0.003123,远小于0.05的常用显著性水平,我们有足够的证据拒绝时间序列是白噪声的原假设。
拟合SARIMA模型需要确定其参数。SARIMA模型有三个重要的参数:p、d和q,分别代表自回归阶数、差分阶数和移动平均阶数;另外还有季节性参数P、D和Q,分别代表季节性自回归阶数、季节性差分阶数和季节性移动平均阶数。根据经验和统计方法,可以通过观察样本自相关函数ACF和偏自相关函数PACF,选取最佳的p、d、q和P、D、Q参数,使得残差序列的自相关函数和偏自相关函数均值为0。
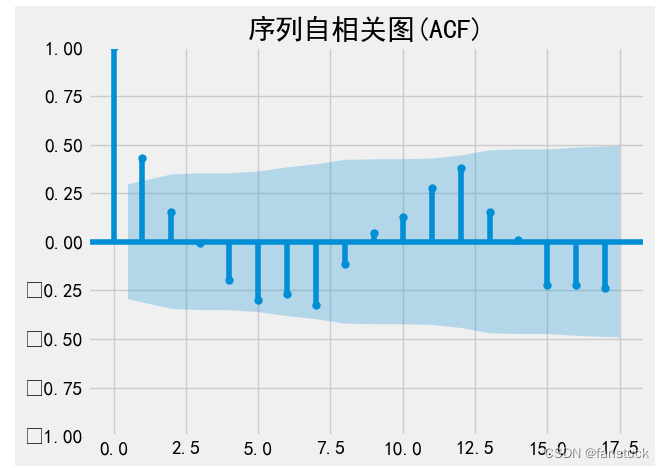
AR模型:自相关系数拖尾,偏自相关系数截尾;
MA模型:自相关系数截尾,偏自相关函数拖尾;
ARMA模型:自相关函数和偏自相关函数均拖尾。
3.模型预测
在完成模型的拟合和检验后,可以使用该模型进行预测。预测方法包括基于历史数据的单步预测和基于当前数据的多步预测。在进行预测时,需要使用已知数据进行模型参数的估计,并将预测结果与真实值进行比较,以评估预测结果的准确性。
这里使用了pmdarima.auto_arima()方法。这个方法可以帮助我们自动确定的参数,直接输入数据,设置auto_arima()中的参数则可。
之前我们是通过观察ACF、PACF图的拖尾截尾现象来定阶,但是这样可能不准确。实际上,往往需要结合图像拟合多个模型,通过模型的AIC、BIC值以及残差分析结果来选择合适的模型。
1、构建模型
将数据分为训练集data_train和测试集data_test 。
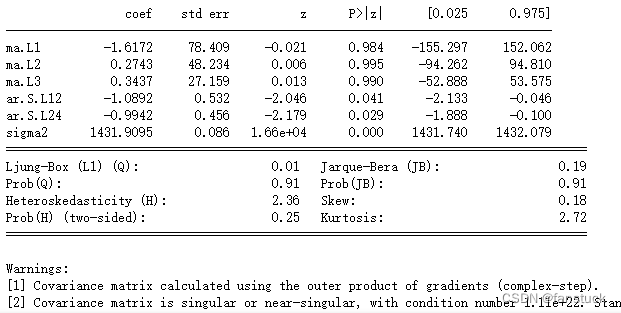
季节周期为12个时间点。下面的系数表显示了模型中每个系数的点估计值、标准误、z统计量和对应的p值。此外,还列出了残差方差的点估计值和Ljung-Box检验和Jarque-Bera检验的结果。Ljung-Box检验用于检验残差是否存在自相关,Jarque-Bera检验用于检验残差是否符合正态分布假设。该模型中,残差的Ljung-Box检验p值为0.83,表明残差不存在显著自相关;而Jarque-Bera检验的p值为0.00,表明残差不符合正态分布假设。此外,模型的拟合效果还可以通过AIC、BIC和HQIC来评价,这些信息也包含在结果汇总表中。
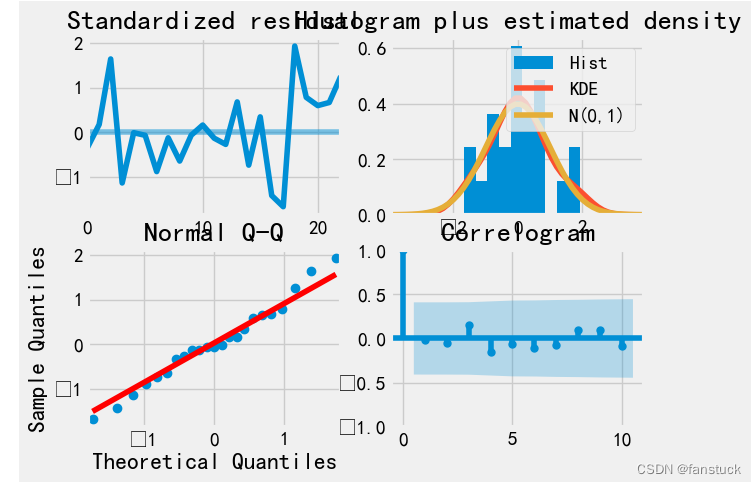
2.预测分析
# 画图观测实际与测试的对比
test_predict = data_test.copy()
for x in range(len(test_predict)):
test_predict.iloc[x] = pred_list[x]
# 模型评价
eval_result = forecast_accuracy(test_predict.values, data_test.values)
print('模型评价结果\n', eval_result)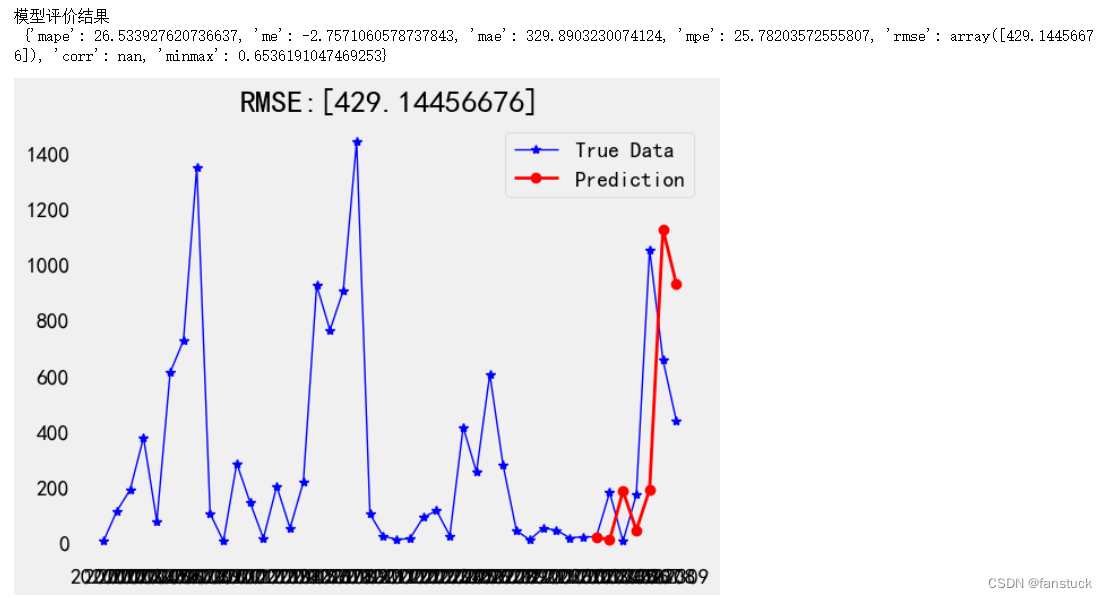
实在太累了这几天都是2点睡觉,思路数据都是开源没收一分钱!!希望大家支持一下!到这里建模就结束了,接下来就是进行损失评估模型建模:估算不同类型和强度的极端天气事件可能导致的经济损失!你们的关注和点赞就是我写作的动力!!!想要了解更多的欢迎联系博主再向大家推荐一下笔者精心打造的专栏。此专栏的目的就是为了让零基础快速使用各类数学模型以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码.
好了那么我们抓紧时间开始做!!待会更新~~

![[开源]基于野火指南者的MQTT框架+FreeRTOS移植(使用板载esp8266模块)](https://img-blog.csdnimg.cn/img_convert/0f5cd8ce06b632951e6a6e4f79fa31e1.png)