算法学习——华为机考题库3(HJ21 - HJ30)
HJ21 简单密码
描述
现在有一种密码变换算法。
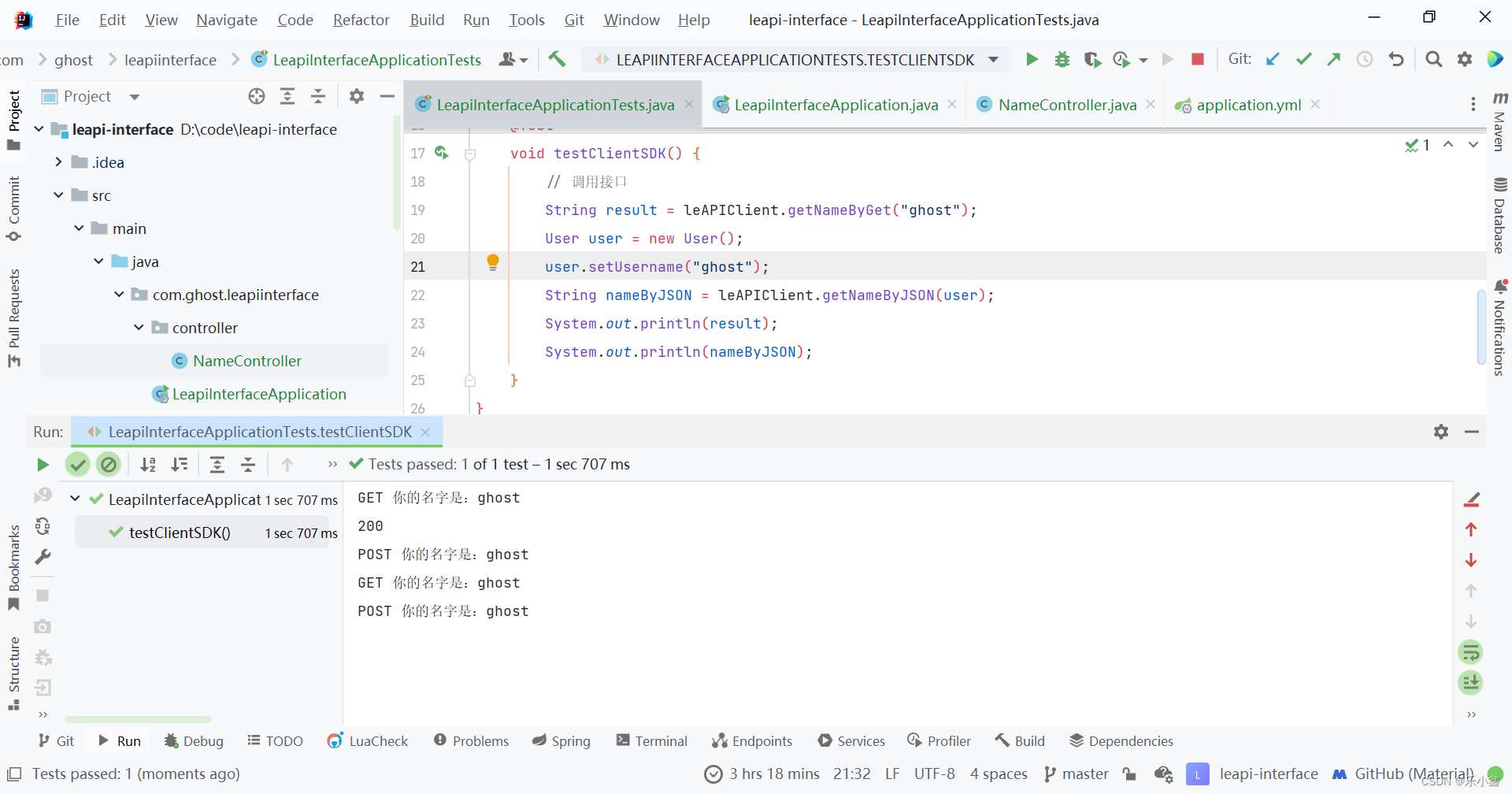
九键手机键盘上的数字与字母的对应: 1–1, abc–2, def–3, ghi–4, jkl–5, mno–6, pqrs–7, tuv–8 wxyz–9, 0–0,把密码中出现的小写字母都变成九键键盘对应的数字,如:a 变成 2,x 变成 9.
而密码中出现的大写字母则变成小写之后往后移一位,如:X ,先变成小写,再往后移一位,变成了 y ,例外:Z 往后移是 a 。
数字和其它的符号都不做变换。
数据范围: 输入的字符串长度满足 1≤n≤100
输入描述:
输入一组密码,长度不超过100个字符。
输出描述:
输出密码变换后的字符串
示例

代码描述
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
string tmp;
string result;
map<char,char> myMap;
for(char i = '0' ; i<= '9' ; i++)
myMap[i] = i;
for(char i = 'A' ; i<= 'Z' ; i++)
{
myMap[i] = 'a' + 1 + i - 'A';
if(i=='Z') myMap[i] = 'a';
}
for(char i = 'a' ; i<= 'o' ; i++)
{
char num = (i - 'a' )/3 + 2 + '0';
myMap[i] = num;
}
for(char i = 'p' ; i<= 's' ; i++)
myMap[i] = '7';
for(char i = 't' ; i<= 'v' ; i++)
myMap[i] = '8';
for(char i = 'w' ; i<= 'z' ; i++)
myMap[i] = '9';
cin >> tmp;
for(int i=0 ; i < tmp.size() ; i++)
{
result += myMap[tmp[i]];
}
cout<<result;
}
// 64 位输出请用 printf("%lld")
HJ22 汽水瓶
描述
某商店规定:三个空汽水瓶可以换一瓶汽水,允许向老板借空汽水瓶(但是必须要归还)。
小张手上有n个空汽水瓶,她想知道自己最多可以喝到多少瓶汽水。
**数据范围:**输入的正整数满足 1≤n≤100
注意:本题存在多组输入。输入的 0 表示输入结束,并不用输出结果。
输入描述:
输入文件最多包含 10 组测试数据,每个数据占一行,仅包含一个正整数 n( 1<=n<=100 ),表示小张手上的空汽水瓶数。n=0 表示输入结束,你的程序不应当处理这一行。
输出描述:
对于每组测试数据,输出一行,表示最多可以喝的汽水瓶数。如果一瓶也喝不到,输出0。
示例

代码解析
#include <iostream>
using namespace std;
int main() {
int num =0 ;
int result = 0;
while (cin>>num) {
if(num == 0) return 0;
result = 0;
while(num/3 > 0)
{
result += num/3;
num = num%3 + num/3;
// cout<<result<<' '<<num<<endl;
if(num <= 1) break;
if(num == 2)
{
result++;
break;
}
}
cout<<result<<endl;
}
}
// 64 位输出请用 printf("%lld")
HJ23 删除字符串中出现次数最少的字符
描述
实现删除字符串中出现次数最少的字符,若出现次数最少的字符有多个,则把出现次数最少的字符都删除。输出删除这些单词后的字符串,字符串中其它字符保持原来的顺序。
**数据范围:**输入的字符串长度满足 1≤n≤20 ,保证输入的字符串中仅出现小写字母
输入描述:
字符串只包含小写英文字母, 不考虑非法输入,输入的字符串长度小于等于20个字节。
输出描述:
删除字符串中出现次数最少的字符后的字符串。
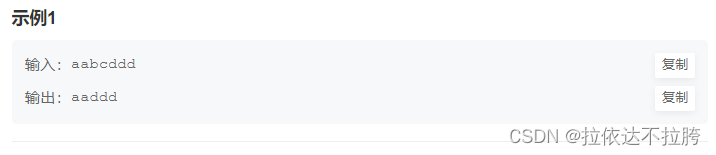
示例
代码解析
#include <algorithm>
#include <iostream>
#include <map>
#include <set>
#include <utility>
#include <vector>
using namespace std;
static bool cmp(pair<char,int> p1 , pair<char,int>p2)
{
return p1.second < p2.second;
}
int main() {
map<char, int> myMap;
set<char> mySet;
string tmpStr;
cin>>tmpStr;
for(int i=0 ; i<tmpStr.size() ; i++)
myMap[tmpStr[i]]++;
vector<pair<char,int>> myVec(myMap.begin(),myMap.end());
sort(myVec.begin(),myVec.end() , cmp);
auto it = myVec.begin();
int charNum = (*it).second;
for(auto it:myVec)
if(charNum == it.second) mySet.insert(it.first);
// for(auto it:mySet)
// cout<<it<<' ';
// cout<<endl;
for(auto it = tmpStr.begin() ; it != tmpStr.end() ; )
{
// cout<<*it<<' ';
if(mySet.find(*it) != mySet.end() )
tmpStr.erase(it);
else it++;
}
cout<<tmpStr;
}
// 64 位输出请用 printf("%lld")
HJ24 合唱队
描述

通俗来说,能找到一个同学,他的两边的同学身高都依次严格降低的队形就是合唱队形。
例子:
123 124 125 123 121 是一个合唱队形
123 123 124 122不是合唱队形,因为前两名同学身高相等,不符合要求
123 122 121 122不是合唱队形,因为找不到一个同学,他的两侧同学身高递减。
你的任务是,已知所有N位同学的身高,计算最少需要几位同学出列,可以使得剩下的同学排成合唱队形。
注意:不允许改变队列元素的先后顺序 且 不要求最高同学左右人数必须相等
数据范围: 1≤n≤3000
输入描述:
用例两行数据,第一行是同学的总数 N ,第二行是 N 位同学的身高,以空格隔开
输出描述:
最少需要几位同学出列
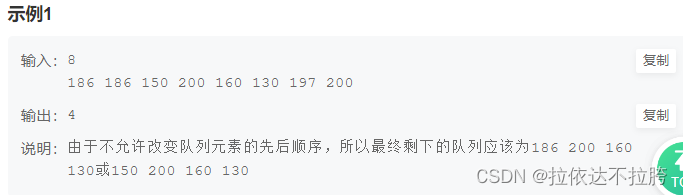
示例
代码解析
#include <algorithm>
#include <iostream>
#include <vector>
using namespace std;
int main() {
int N , tmp;
vector<int> student;
cin>>N;
while (N--)
{
cin>>tmp;
student.push_back(tmp);
}
vector<int> dp_up(student.size(),0);
vector<int> dp_down(student.size(),0);
for(int i=0 ; i<student.size() ;i++)
{
for(int j=0 ; j < i ;j++)
{
if(student[i] > student[j]) dp_up[i] = max(dp_up[i] , dp_up[j] + 1);
}
}
reverse(student.begin(), student.end());
for(int i=0 ; i<student.size() ;i++)
{
for(int j=0 ; j < i ;j++)
{
if(student[i] > student[j]) dp_down[i] = max(dp_down[i] , dp_down[j] + 1);
}
}
int result = 0;
for(int i=0 ; i<student.size() ;i++)
{
if(result < dp_up[i] + dp_down[student.size() -1- i] + 1) result = dp_up[i] + dp_down[student.size() -1 - i] + 1;
}
cout<<student.size() - result;
}
// 64 位输出请用 printf("%lld")
HJ25 数据分类处理
描述
信息社会,有海量的数据需要分析处理,比如公安局分析身份证号码、 QQ 用户、手机号码、银行帐号等信息及活动记录。
采集输入大数据和分类规则,通过大数据分类处理程序,将大数据分类输出。
数据范围: 1≤I,R≤100 ,输入的整数大小满足 0≤val≤2 31 −1
输入描述:
一组输入整数序列I和一组规则整数序列R,I和R序列的第一个整数为序列的个数(个数不包含第一个整数);整数范围为0~(2^31)-1,序列个数不限
输出描述:
从R依次中取出R,对I进行处理,找到满足条件的I:
I整数对应的数字需要连续包含R对应的数字。比如R为23,I为231,那么I包含了R,条件满足 。
按R从小到大的顺序:
(1)先输出R;
(2)再输出满足条件的I的个数;
(3)然后输出满足条件的I在I序列中的位置索引(从0开始);
(4)最后再输出I。
附加条件:
(1)R需要从小到大排序。相同的R只需要输出索引小的以及满足条件的I,索引大的需要过滤掉
(2)如果没有满足条件的I,对应的R不用输出
(3)最后需要在输出序列的第一个整数位置记录后续整数序列的个数(不包含“个数”本身)
序列I:15,123,456,786,453,46,7,5,3,665,453456,745,456,786,453,123(第一个15表明后续有15个整数)
序列R:5,6,3,6,3,0(第一个5表明后续有5个整数)
输出:30, 3,6,0,123,3,453,7,3,9,453456,13,453,14,123,6,7,1,456,2,786,4,46,8,665,9,453456,11,456,12,786
说明:
30----后续有30个整数
3----从小到大排序,第一个R为0,但没有满足条件的I,不输出0,而下一个R是3
6— 存在6个包含3的I
0— 123所在的原序号为0
123— 123包含3,满足条件
示例

代码解析
#include <cstddef>
#include <iostream>
#include <set>
#include <string>
#include <vector>
using namespace std;
int main() {
vector<string> result;
vector<string> I;
vector<int> R;
set<int> RSet;
int num = 0;
cin>>num;
string tmpStr;
while(num--) //输入I
{
cin>>tmpStr;
I.push_back(tmpStr);
}
cin>>num;
int tmpNum;
while (num--) //输入R
{
cin>>tmpNum;
RSet.insert(tmpNum);
}
for(auto it:RSet) //R 用set去重排序
R.push_back(it);
for(int i=0 ; i <R.size() ; i++) //挨个查找R
{
string tmpR = to_string(R[i]);
vector<string> tmp;
tmp.clear();
for(int j=0 ; j <I.size() ;j++) // 找每一个I中有没有当前R
{
if(I[j].find(tmpR) != -1)
{
tmp.push_back(to_string(j)); //找到保存I的下标和内容
tmp.push_back(I[j]);
}
}
if(tmp.size() > 0) //如果找到了,存到结果里
{
result.push_back(tmpR);
result.push_back(to_string(tmp.size()/2));
for(auto it:tmp)
result.push_back(it);
}
}
cout<<result.size()<<' ';
for(auto it:result)
cout<<it<<' ';
}
// 64 位输出请用 printf("%lld")