目录
哈希桶的实现
封装 unordered_map 和 unordered_set
封装代码
HashTable.h
MyUnorderedMap.h
MyUnorderedSet.h
哈希桶,又叫开散列法。开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。具体如下图例:
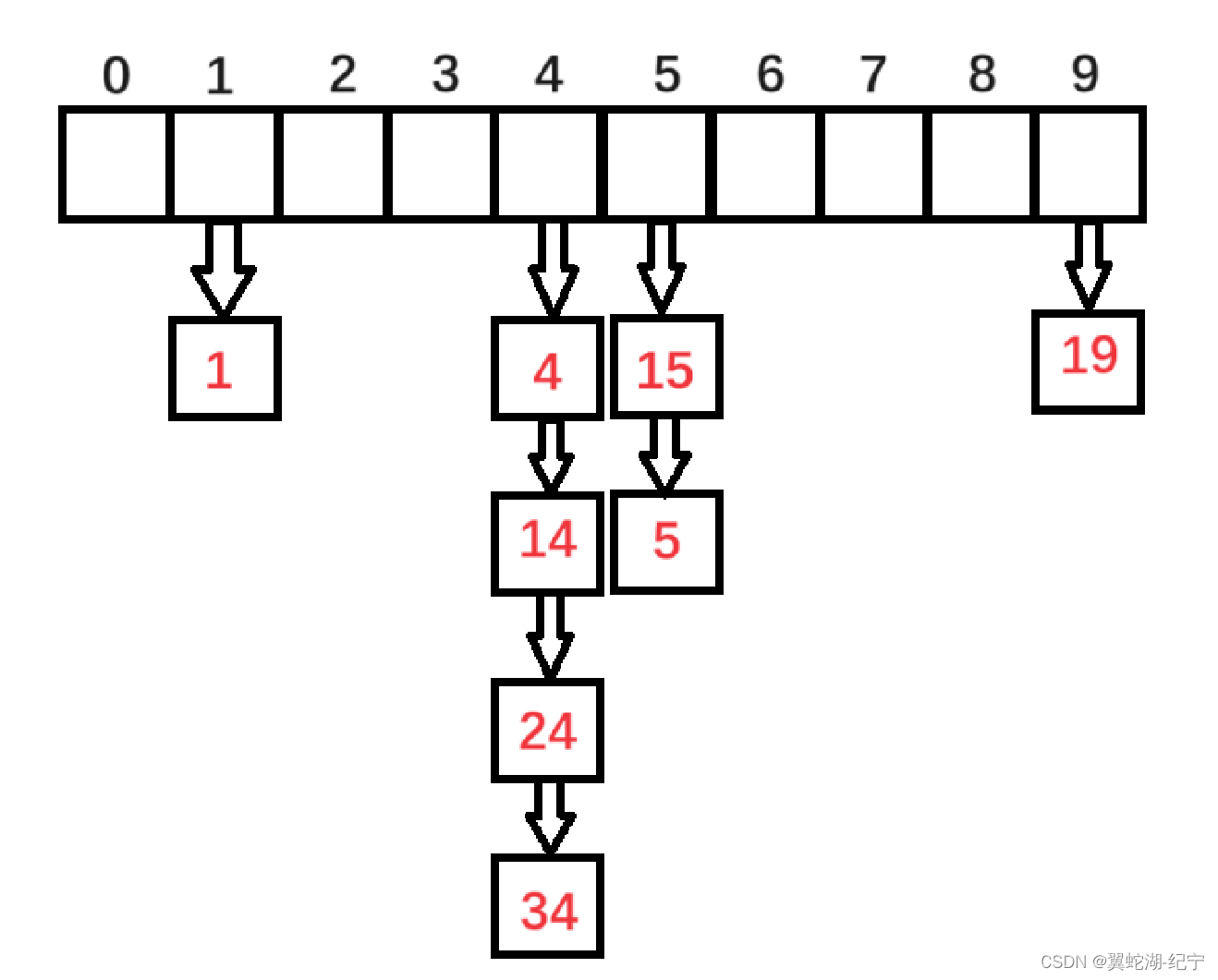
哈希桶的实现原理
首先,思路是用 vector 来作为基础容器,里面存储的数据类型是一个结构器结点类型,结点中存储模板类型的数据和 _next 指针。当要插入数据的时候,先根据这个数据利用除留余数法计算出它的 hashi,然后再头插到对应 vector 的位置。
一般设置哈希桶的负载因子为1,当哈希桶的负载因子恰好等于 1 的时候,就要进行扩容。哈希表的扩容必须要异地扩容并且将原哈希桶中的数据再次挨个插入到新的哈希桶中,最后将这个哈希桶的数据与原来的哈希桶交换。当然,析构函数也要自己来写,因为必须将所有结点挨个释放!
哈希表的查找。哈希表的查找效率是非常高的,几乎接近于 O(1)。先计算出要查找数据的 hashi,再根据以 hashi 为头结点的链表往下查找与之对应的数据,并返回找到位置的指针。如果找不到,就返回空指针。
哈希表的删除。 哈希表的删除也是查找的那一套思路,但需要记录一个prev指针,因为需要对prev指针和 next 指针进行链接。
封装 unordered_map 和 unordered_set
说实话这个封装,真是让人太头大了。
我就在这里介绍几个比较容易出错的点。
前置声明,可以解决相互依赖的问题,当定义在源文件靠上位置的类想使用靠下位置的类时,而编译器又只能向上,所以要在靠上位置的类前面声明一下。例如在迭代器类中想使用哈希表,就需要提前声明一下。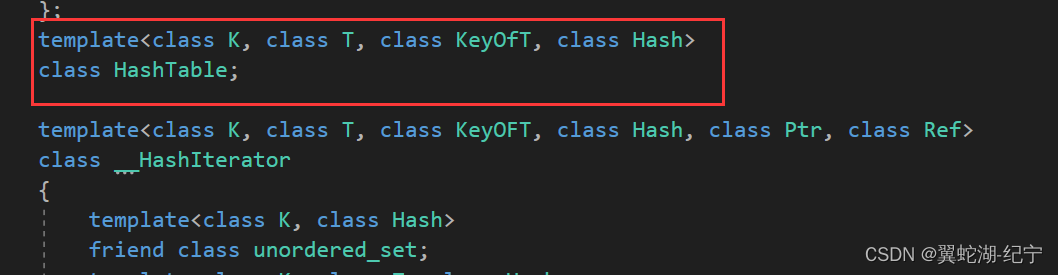
格式就是上图中写的:
模板参数列表
class 类名
一个类 A 想访问另一个类 B 的私有,需要在类 B 中友元声明 类 A,且友元声明的位置可以在任意位置(public private protected),这样,类 A 中就可以访问类 B 的私有了!

代码实现
(里面一些需要注意的点都在代码中注释标注)
HashTable.h
#pragma once
#include <iostream>
#include <vector>
#include <string>
using namespace std;
namespace Hash_backet
{
template<class T>
struct HashNode
{
HashNode(const T& data)
:_next(nullptr)
, _data(data)
{}
HashNode<T>* _next;
T _data;
};
template<class K>
struct HashOfi
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
struct HashOfi<string>
{
size_t operator()(const string& key)
{
size_t hashi = 0;
for (size_t i = 0; i < key.size(); i++)
{
hashi *= 31;
hashi += key[i];
}
return hashi;
}
};
template<class K, class T, class KeyOfT, class Hash>
class HashTable;
template<class K, class T, class KeyOFT, class Hash, class Ptr, class Ref>
class __HashIterator
{
template<class K, class Hash>
friend class unordered_set;
template<class K, class T, class Hash>
friend class unordered_map;
template<class K, class T, class KeyOfT, class Hash>
friend class HashTable;
typedef __HashIterator<K, T, KeyOFT, Hash, Ptr, Ref> self;
typedef HashNode<T> Node;
public:
__HashIterator(Node* node, HashTable<K, T, KeyOFT, Hash>* php)
:_node(node)
,_php(php)
{}
__HashIterator(Node* node, const HashTable<K, T, KeyOFT, Hash>* php)
:_node(node)
, _php(php)
{}
Hash ky;
KeyOFT kt;
const HashTable<K, T, KeyOFT, Hash>* _php;
self& operator++()
{
if (_node->_next)
{
_node = _node->_next;
}
else
{
size_t hashi = ky(kt(_node->_data)) % _php->_tables.size();
++hashi;
while (hashi < _php->_tables.size())
{
if (_php->_tables[hashi])
{
_node = _php->_tables[hashi];
break;
}
hashi++;
}
if (hashi == _php->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const self &it)
{
return _node != it._node;
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
private:
Node* _node;
};
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
typedef HashNode<T> Node;
public:
template<class K, class T, class KeyOFT, class Hash, class Ptr, class Ref>
friend class __HashIterator; // 后面要使用 __Iterator 的私有,因此要在类内友元声明
typedef __HashIterator<K, T, KeyOfT, Hash, T*, T&> iterator;
typedef __HashIterator<K, T, KeyOfT, Hash, const T*, const T&> const_iterator;
KeyOfT kt;
Hash ky;
HashTable()
{
_tables.resize(10);
}
iterator begin()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
return iterator(cur, this);
}
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}
const_iterator begin() const
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
return const_iterator(cur, this);
}
}
return end();
}
const_iterator end() const
{
return const_iterator(nullptr, this);
}
iterator Find(const K& key)
{
size_t hashi = ky(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kt(cur->_data) == key)
{
return iterator(cur,this);
}
cur = cur->_next;
}
return iterator(nullptr, this);
}
pair<iterator, bool> Insert(const T& data)
{
if (Find(kt(data))._node) //要使用_node 需要在前面进行友元声明
{
// 有元素,不允许插入
return make_pair(Find(kt(data)),false);
}
if (_n == _tables.size())
{
// 扩容,异地扩容,直接将结点挨个弄下去
HashTable<K, T, KeyOfT, Hash> newht;
size_t newsize = 2 * _tables.size();
newht._tables.resize(newsize);
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i]) // 顺序表元素数组结点不为空
{
// 将这个结点的结点全部拿下来,链接到新结点
Node* cur = _tables[i];
while (cur)
{
newht.Insert(cur->_data);
cur = cur->_next;
}
}
}
_tables.swap(newht._tables);
}
// 计算 hashi
size_t hashi = ky(kt(data)) % _tables.size();
// 头插
Node* newnode = new Node(data);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
_n++;
return make_pair(iterator(_tables[hashi], this),true);
}
bool Erase(const K& key)
{
size_t hashi = ky(key) % _tables.size();
Node* cur = _tables[hashi];
if (cur)
{
Node* prev = nullptr;
while (cur)
{
if (kt(cur->_data) == key)
{
if (cur == _tables[hashi])
{
_tables[hashi] = cur->_next;
}
else
{
Node* next = cur->_next;
prev->_next = next;
}
delete cur;
break;
}
prev = cur;
cur = cur->_next;
}
return true;
}
else
{
return false;
}
}
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
if (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
}
}
private:
vector<Node*> _tables;
size_t _n = 0;
};
}MyUnorderedMap.h
#pragma once
#include "HashTable.h"
namespace Hash_backet
{
template<class K, class T, class Hash = HashOfi<K>>
class unordered_map
{
public:
struct UnMapKeyOfT
{
const K& operator()(const pair<K, T>& kv)
{
return kv.first;
}
};
// 通过类域去访问HashTable 里面的 iterator,编译器其实是不能区分到底是 静态成员变量 还是 内嵌类型 的
// 前面加一个 typename,就相当于一个给编译器的声明,这是一个内嵌类型(保证编译的时候不会报错),等到实例化的时候,再找具体的类来替换
typedef typename Hash_backet::HashTable<K, pair<const K, T>, UnMapKeyOfT, Hash>::iterator iterator;
typedef typename Hash_backet::HashTable<K, pair<const K, T>, UnMapKeyOfT, Hash>::const_iterator const_iterator;
pair<iterator, bool> insert(const pair<K, T>& kv)
{
return _ht.Insert(kv);
}
T& operator[](const K& key)
{
return (_ht.insert(make_pair(key, T()))).first->second; // -> 可以得到 _data 的引用,相当于 first._node.second
}
const T& operator[](const K& key) const
{
return (_ht.insert(make_pair(key, T()))).first->second; // -> 可以得到 _data 的引用,相当于 first._node.second
}
iterator find(const K& key)
{
return _ht.Find(key);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin() const // const 放后面,表明调用这个成员函数的对象是用 const 来修饰的
{
return _ht.begin();
}
const_iterator end() const // const 放后面,表明调用这个成员函数的对象是用 const 来修饰的
{
return _ht.end();
}
private:
HashTable<K, pair<const K, T>, UnMapKeyOfT, Hash> _ht;
};
}
MyUnorderedSet.h
#pragma once
#include "HashTable.h"
namespace Hash_backet
{
template<class K, class Hash = HashOfi<K>>
class unordered_set
{
public:
struct UnSetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
// 通过类域去访问HashTable 里面的 iterator,编译器其实是不能区分到底是 静态成员变量 还是 内嵌类型 的
// 前面加一个 typename,就相当于一个给编译器的声明,这是一个内嵌类型(保证编译的时候不会报错),等到实例化的时候,再找具体的类来替换
typedef typename Hash_backet::HashTable<K, K, UnSetKeyOfT, Hash>::const_iterator iterator;
typedef typename Hash_backet::HashTable<K, K, UnSetKeyOfT, Hash>::const_iterator const_iterator;
pair<iterator, bool> insert(const K& key)
{
auto ret = _ht.Insert(key);
return pair<const_iterator, bool>(const_iterator(ret.first._node, ret.first._php), ret.second);
}
iterator find(const K& key)
{
auto ret = _ht.Find(key);
return iterator(ret._node, ret._php);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
const_iterator begin() const // 无论是 iterator 还是 const_iterator 都调用 HashTable 中 const 类型的end() 和 begin()
{
return _ht.begin();
}
const_iterator end() const
{
return _ht.end();
}
private:
HashTable<K, K, UnSetKeyOfT, Hash> _ht;
};
}