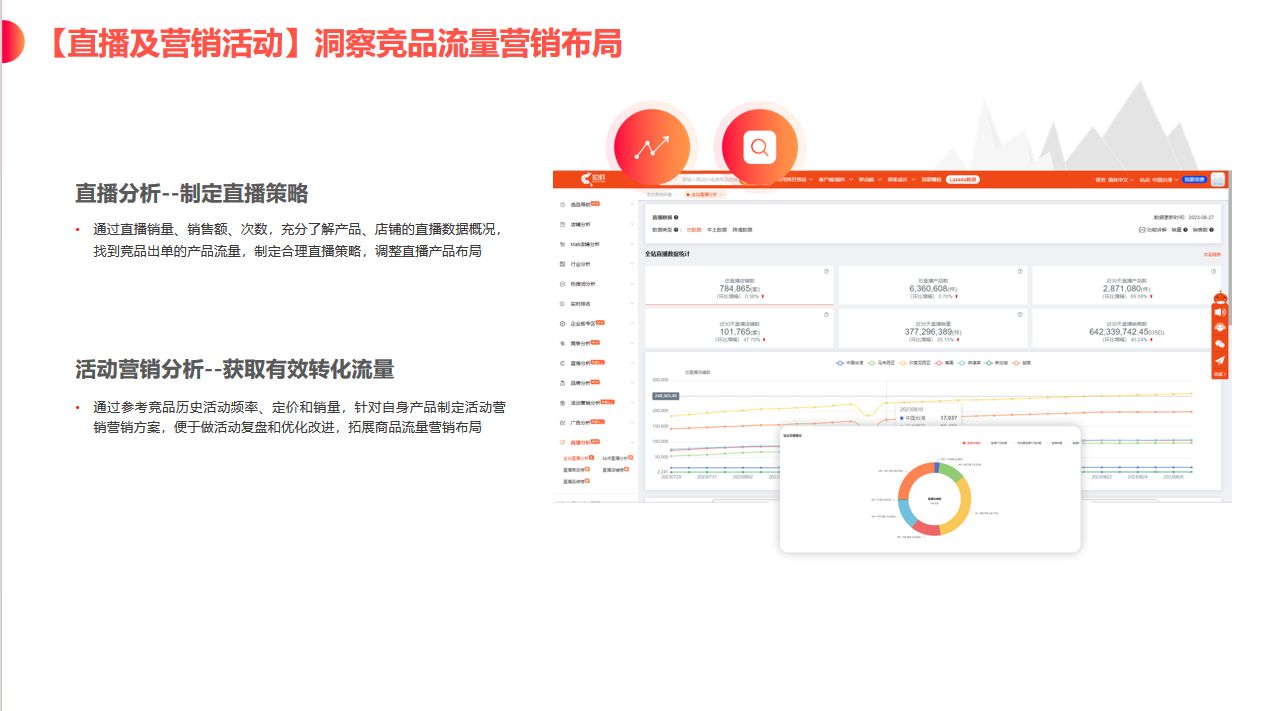
LLM(3) | 自注意力机制 (self-attention mechanisms)
self-attention 是 transformer 的基础, 而 LLMs 大语言模型也都是 transformer 模型, 理解 self-attention, 才能理解为什么 LLM 能够处理好上下文关联性。
本篇是对于 Must-Read Starter Guide to Mastering Attention Mechanisms in Machine Learning 的翻译。
文章目录
- LLM(3) | 自注意力机制 (self-attention mechanisms)
- 掌握机器学习中注意力机制的必读入门指南 Must-Read Starter Guide to Mastering Attention Mechanisms in Machine Learning
- 从基础知识到自注意力的工作原理, 快速参考指南, 了解这篇标志性论文及其多年后的实际应用 (From the basics to how self-attention works, a quick-reference guide to understanding the iconic paper and its practical applications years later)
- 机器学习中的 attention 是什么? (What is Attention in Machine Learning?)
- 注意力机制是如何工作的? 有哪些常见的机制? (How Does It Work and What Are the Common Mechanisms?)
- Soft Attention
- Hard Attention
- Self-Attention
- Global-Attention
- Local Attention
- 有什么好处? (What are the Benefits?)
- 什么时间、在哪里使用? (When and Where To Use)
- 总结
- 个人总结
掌握机器学习中注意力机制的必读入门指南 Must-Read Starter Guide to Mastering Attention Mechanisms in Machine Learning
从基础知识到自注意力的工作原理, 快速参考指南, 了解这篇标志性论文及其多年后的实际应用 (From the basics to how self-attention works, a quick-reference guide to understanding the iconic paper and its practical applications years later)
Originally inspired by the human mechanism of selectively focusing on certain aspects of information, attention mechanisms in machine learning models provide a way to weigh the importance of different elements in a given input. The concept first gained significant popularity and importance in the wake of the iconic paper “Attention is All You Need.”
受人类选择性关注(selectively focusing)信息的机制启发, 机器学习模型中的**注意力机制(attention mechanisms)**提供了一种衡量给定输入中不同元素重要性的方式。注意力机制(attention mechanisms) 这个概念是在标志性论文 “Attention is All You Need” 中首次获得重要的关注和重要性。
机器学习中的 attention 是什么? (What is Attention in Machine Learning?)
Attention is a mechanism in machine learning models that allows them to dynamically focus on specific parts of the input data, assigning varying levels of importance to different elements. It helps in resolving the limitations of fixed-length encoding in traditional neural networks, which can struggle to handle long sequences or complex patterns. By selectively focusing on certain elements of the input, attention mechanisms can improve the model’s overall performance in tasks like natural language processing, image recognition, and speech recognition.
注意力是机器学习模型中的一个机制, 允许他们动态的关注输入数据的特定部分, 对不同元素赋予不同的重要性。 传统神网络中存在固定长度编码(fixed-length encoding)的限制,在长序列、复杂模式下效果不好, 而注意力模型则解决了这个问题。通过选择性的关注输入的特定元素, attention 机制在自然语言处理、图像识别、语音识别等任务上, 可以提升模型的整体性能。
At its core, attention can be thought of as a way of assigning importance weights to different parts of the input, based on their relevance to the task at hand. For example, in natural language processing, attention can be used to determine which words in a sentence are most important for understanding its meaning, while in computer vision, attention can be used to focus on specific regions of an image that are most relevant for object detection or recognition.
核心层面, attention 可以被理解为:给输入的不同部分赋予不同的重要性权重的方法, 这是基于和手头任务的相关性来做到的。比如说, 在自然语言处理中, attention 可以被用于决定一个句子中的哪个单词对于理解(整个句子的)含义是最重要的, 而在计算机视觉中, attention 可以被用于关注图像上和目标检测、目标识别最相关的特定区域。
注意力机制是如何工作的? 有哪些常见的机制? (How Does It Work and What Are the Common Mechanisms?)
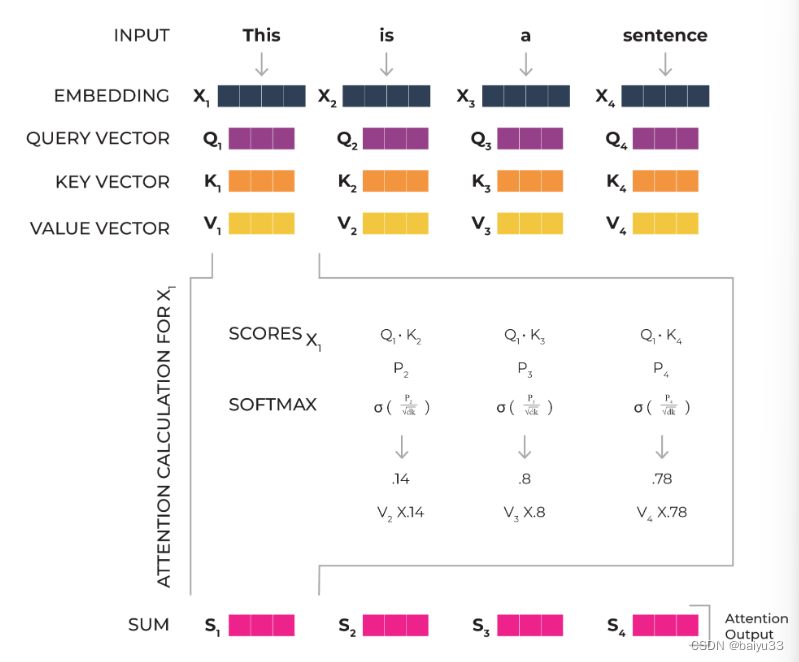
There are several common types of attention mechanisms used in machine learning, particularly in natural language processing tasks. These include soft attention, hard attention, self attention, global attention, and local attention. Let’s dive into each.
在机器学习中,尤其是自然语言处理任务中,有几种常见的注意力机制。具体包括: 软注意力机制(soft attention), 硬注意力机制(hard attention), 自注意力机制(self-attention), 全局注意力机制(global-attention), 局部注意力机制(local-attention)。
Soft Attention
Soft attention assigns continuous weights to input elements, allowing the model to attend to multiple elements simultaneously. Soft attention mechanisms are differentiable, which makes them easier to optimize using gradient-based techniques. These mechanisms have been widely adopted in various deep learning applications, such as neural machine translation, where the model learns to weigh the importance of each word in the input sentence when generating the target translation. Soft attention computes a weighted sum of input elements, where the weights are typically obtained by applying a softmax function to the attention scores.
软注意力机制,是给输入元素赋予了 连续的权重, 使模型能够同时关注(attend to)多个元素。 soft-attention 是可微分的, 这使得它们更容易使用基于梯度的技术进行优化。 这些机制在许多深度学习应用中广泛使用, 比如 NMT(neural machine translation, 神经机器翻译)里在生成目标翻译文本时, 模型学习给输入句子中的每个单词的重要性打分。 soft attention 计算输入元素的加权和, 其中权重通常是 attention 得分的 softmax 结果。
Hard Attention
Hard attention is an attention mechanism that selects a subset of input elements to focus on, while ignoring the rest. It works by learning to make discrete decisions on which input elements are most relevant for a given task. For instance, in image captioning, hard attention may select specific regions of the image that are most relevant for generating the caption. One of the main challenges with hard attention is that it is non-differentiable, which makes it difficult to optimize using gradient-based methods like backpropagation. To address this, researchers often resort to techniques like reinforcement learning or the use of surrogate gradients.
硬注意力(hard attention)是说, 选择输入元素中的一个子集, 没有选中的则被丢弃。它通过学习对于给定任务哪些输入元素最相关来做出离散决策。比如说在 image caption 任务中, hard attention 可以选择图像中和生成标题最相关的图像区域。 hard attention 的主要挑战之一是, 它是不可微的, 这使得使用像反向传播这样的梯度方法进行优化变得困难。 为了解决这个问题, 研究人员经常会采用强化学习 (reinforce-learning) 或者使用替代梯度 (surrogate gradients) 的技术。
Self-Attention
Self attention, also known as intra-attention, is an attention mechanism where the model attends to different parts of the input sequence itself, rather than attending to another sequence or a different modality. This mechanism surged in popularity through its use in the transformer architecture, which shows remarkable performance across various natural language processing tasks. In self attention, the model learns to relate different positions of the input sequence to compute a representation of the sequence. This allows the model to capture long-range dependencies and contextual information, leading to improved performance in tasks such as language modeling, machine translation, and text summarization.
自注意力 (self-attention), 也被叫做 “内部注意力” (intra-attention), 是说模型关注(attends)的是输入序列本身的不同部分, 而不是关注另一个序列或不同的模态。 这种机制在 transformer 架构中的应用中使它变得非常受欢迎, 在各种自然语言处理任务中表现出色。 在 self attention 中, 模型学习把输入序列中不同的位置之间建立联系, 从而计算出序列的一个表示。 这使得模型能够捕获长范围的依赖和上下文信息, 从而改善了语言模型、 机器翻译、 文本总结等任务的性能。
这段人工翻译的不够润,贴一段 ChatGPT4 的翻译:
自注意力,也称为内部注意力,是一种注意机制,模型关注的是输入序列本身的不同部分,而不是关注另一个序列或不同的模态。这种机制在transformer架构中的使用使其变得非常流行,该架构在各种自然语言处理任务中表现出色。在自我注意力中,模型学会了将输入序列的不同位置联系起来计算序列的表示。这使得模型能够捕捉长距离依赖性和上下文信息,从而提高了语言建模、机器翻译和文本摘要等任务的性能。
Global-Attention
Global attention mechanisms focus on all elements of the input sequence when computing attention weights. In this approach, the model computes a context vector by taking a weighted sum of all input elements, where the weights are determined by the attention scores. Global attention is widely used in sequence-to-sequence models, such as those used for machine translation, where the model must attend to all words in the input sentence to generate a coherent translation. One of the benefits of global attention is that it allows the model to capture long-range dependencies and global context, which can be crucial for understanding and generating complex structures.
全局注意力机制 (global attention) 是说, 在计算 attention 权重的时候, 关注输入序列的所有元素。 在这种方法中, 模型通过对所有输入元素进行加权求和来计算上下文向量, 其中权重由 attention 分数确定。 global attention 在 序列到序列 (sequence-to-sequence) 模型任务中广泛使用, 比如在机器翻译中使用的模型里, 模型必须关注输入序列中的所有单词来生成一个连贯 (coherent) 的翻译。 global attention 的一个好处是, 他可以帮助模型捕捉长距离的依赖关系 和 全局背景, 这对于理解和生成复杂结构至关重要。
Local Attention
Local attention mechanisms focus on a smaller, localized region of the input sequence when computing attention weights. Instead of attending to all input elements, the model learns to select a specific region or window around the current position, and computes attention weights only within that region. This can be advantageous in situations where the relevant information is located in a specific, local context, such as when processing time series data or text with strong locality properties. Local attention can also be computationally more efficient than global attention, as it reduces the number of attention computations required, making it suitable for applications with large input sequences or limited computational resources.
局部注意力机制 (local attention) 在计算 attention 权重时, 关注输入序列中较小的、 局部的区域。 local attention 模型不关注所有的输入, 而是学会选择当前位置周围的特定区域或窗口, 并仅在该区域内计算注意力权重。 这在模型情况下很有优势, 特别是当相关信息位于特定的本地环境中, 比如处理时间序列数据 或具有强烈局部性质的文本时。
local attention 在计算上也远比 global attention 更高效, 因为它减少(reduce)了所需的注意力计算次数, 适用于具有大量输入序列 或 有限计算资源的应用。
有什么好处? (What are the Benefits?)
Attention mechanisms have demonstrated a multitude of benefits in the realm of machine learning. One of the most notable advantages is the improved performance they bring to tasks such as natural language processing, image recognition, and speech recognition. By allowing the model to selectively focus on important elements, attention mechanisms enhance the accuracy and effectiveness of these tasks.
attention 机制在机器学习领域展示了许多好处 (multitude of benefits)。 其中最明显的优势之一是它们为自然语言处理、 图像识别, 以及语音识别等任务带来的性能提升。 通过允许模型有选择的关注重要元素, attention 机制提高了这些任务的准确性和有效性。
Moreover, attention helps overcome the limitations of fixed-length encoding, enabling models to work with longer input sequences and maintain relevant information. This ability is crucial when dealing with complex patterns or large amounts of data. Additionally, attention mechanisms often produce interpretable results, as the attention weights provide insights into which parts of the input the model considers important. This interpretability facilitates a deeper understanding of the model’s decision-making process, fostering trust and improving debugging efforts.
此外, attention 有助于克服固定长度编码 (fixed-length encoding) 的限制, 使模型能够处理更长的输入序列并保持相关信息。在处理复杂模式或大量数据时, 这种能力至关重要。 此外, attention 机制通常会产生可解释的结果, 因为注意力权重能够揭示模型认为输入的哪些部分是重要的。 这种可解释性有助于更深入的理解模型的决策过程, 增进信任并提升调试工作的效果。
Finally, attention mechanisms, particularly local attention, can improve computational efficiency by reducing the scope of the context that the model needs to consider. This reduction allows for faster processing times without sacrificing the quality of the output. Overall, attention mechanisms have contributed significantly to advancements in machine learning, leading to more robust, efficient, and interpretable models.
最后, 特别是 local attention 机制, 可以通过减少模型需要考虑的上下文范围来提高计算效率。 这种减少可以让处理速度更快, 而不会牺牲输出质量。 总的来说, attention 机制在机器学习的发展中发挥了重要作用, 使模型更加稳健、 高效和易于解释。
什么时间、在哪里使用? (When and Where To Use)
Attention mechanisms have proven valuable in a wide range of applications, but knowing when to use them is essential for optimizing their benefits. Here are some scenarios where incorporating attention mechanisms may be particularly advantageous:
注意力机制在各种应用中已经被证明是非常有价值的, 但关键是要知道何时使用它们以优化它们的好处。 以下是适合 attention 机制会带来明显好处的场景:
序列到序列的任务(Sequence-to-sequence tasks):
Attention is especially useful in sequence-to-sequence tasks, such as machine translation, speech recognition, and summarization. In these cases, attention allows the model to selectively focus on relevant parts of the input sequence, leading to better context-aware outputs.
attention 在序列到序列任务中尤其有用, 比如机器翻译, 语音识别, 摘要/总结。 在这些场景中, attention 使得模型选择性的关注输入序列中的相关部分, 提供更好的上下文相关的输出结果。
处理长序列(Handling long sequences):
When working with long input sequences or complex patterns, attention mechanisms can help overcome the limitations of traditional fixed-length encoding. By enabling the model to focus on specific elements, attention mechanisms can maintain critical information and improve overall performance.
当处理较长的输入序列, 或者复杂的输入模式时, attention 机制可以帮助克服传统的固定长度编码的问题。 通过使模型聚焦在特定元素上, attention 机制能够保持重要的信息, 并且提升整体的性能。
需要上下文感知来处理的任务(Tasks requiring context-aware processing):
Attention is beneficial in tasks that demand context-aware processing, such as natural language processing or image captioning. By weighing the importance of different elements within the input sequence, attention mechanisms allow models to make more informed decisions based on the broader context.
attention 对于需要上下文感知的计算是有好处的, 比如自然语言处理, image caption (图像描述)。通过对输入序列的不同部分赋予不同的重要性权重, attention 机制使得模型在广泛的上下文环境中做出更好的决策。
可解释性(Interpretability and explainability)
When it is essential to understand the decision-making process of a model, attention mechanisms can provide valuable insights. By highlighting which parts of the input the model focuses on, attention weights can offer a clearer understanding of how the model arrives at its conclusions.
当理解一个模型的决策过程是很重要的时候, attention 机制提供了有价值的权重。 通过高亮模型对于输入的哪部分着重处理, attention 权重可以提供模型是如何生成它的结论的清晰理解。
计算效率(Computational efficiency)
In cases where reducing computational requirements is a priority, local attention mechanisms can be employed. By focusing on a smaller, fixed-size window around the current element, local attention reduces the computational burden while still providing context-aware processing.
在减少计算开销的优先级比较高的情况下, local attention 机制可以派上用场。 通过关注一个小的、 当前元素周围固定长度的窗口, local attention 减少了计算开销, 同时保持了上下文感知的计算。
While attention mechanisms can be beneficial in these scenarios, it is essential to consider the specific requirements and constraints of the task at hand. Attention mechanisms can add complexity to a model, and in some cases, simpler architectures may suffice. Therefore, it is crucial to carefully evaluate the trade-offs between model complexity, computational demands, and the benefits of attention before incorporating these mechanisms into your machine learning models.
尽管 attention 机制在这些场景中很有用, 仔细思考手头上任务的特定需求和限制仍然是很重要的。 attention 机制会增加模型的复杂性, 并且在有些场景下, 更简单的架构就足够了。 因此, 在模型的复杂性、 计算开销、 使用 attention 带来的收益之间做出权衡是很重要的。
总结
Attention mechanisms have proved to be a valuable addition to the field of machine learning, enhancing model performance and interpretability in various tasks. By understanding the different types of attention and their benefits, researchers and practitioners can continue to push the boundaries of what machine learning models can achieve.
attention 机制被证明是机器学习领域里一个有价值的新鲜事物, 在多个任务上提升了模型的性能和可解释性。 通过理解不同类型的 attention 和它们的优点, 研究人员和参与这门可以继续推进机器学习模型能力的边界。
个人总结
- 论文 Attention Is All You Need 首次提出了 attension machanisms 注意力机制
- attention 机制解决了 fixed-length encoding 的限制
- 英文单词 attend 意思是 “关注”, attention 是它的名词形式
- attention 的几种类型:
- attention 是说对于输入的每个元素, 学习一个权重
- soft attention: 权重可微
- hard attention: 忽略掉一部分输入. 权重不可微。
- self attention: 对整个输入做分解, 对于分解出来的部分之间, 建立关注
- global attention: 所有输入都处理, 不过仍然要各自学习出不同的权重
- local attention: 只处理输入中的小部分的权重的学习
- attention 的好处
- 能处理长范围的依赖
- 能克服固定长度编码的限制
- 能减少计算量
- 给预测/生成的结果, 提供了可解释性
- 以上的特点, 使得能够处理大数据
- 没有提到 generative。