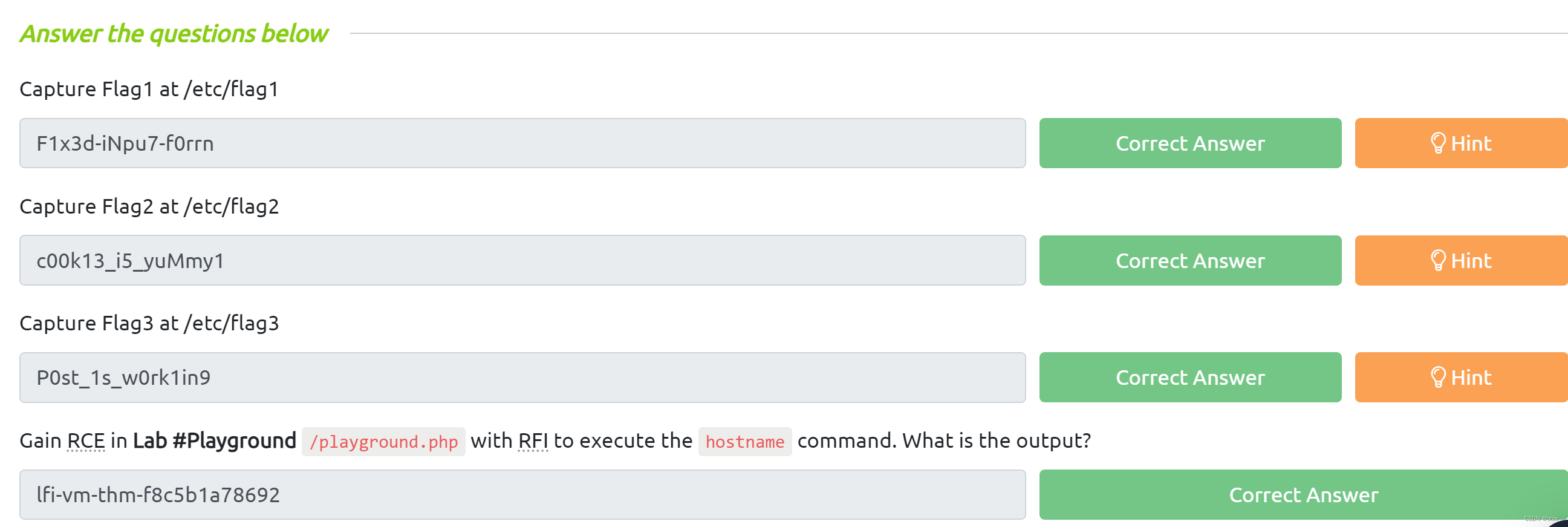
1、前言
《微调入门篇:大模型微调的理论学习》我们对大模型微调理论有了基本了解,这篇结合我们现实中常见的场景,进行大模型微调实操部分的了解和学习,之前我有写过类似的文章《实践篇:大模型微调增量预训练实践(二)》利用的MedicalGPT的源码在colab进行操作, 由于MedicalGPT代码比较难以理解,而且模型只能从hugging face上下载,对于一些国内服务器无法访问,我重构了代码,让训练代码更有可读性,并参考LLAMAFactory的项目,增加了modelscope上下载模型,轻松在国内服务器运行.
2、微调领域参考
从0到1太难了,正所谓站在巨人的肩膀创新,我们可以学习其他人在各个领域的一些落地实践,从中得到自己的一些思考,以下是在《垂直领域大模型更亲民》中提到过垂直领域的落地:
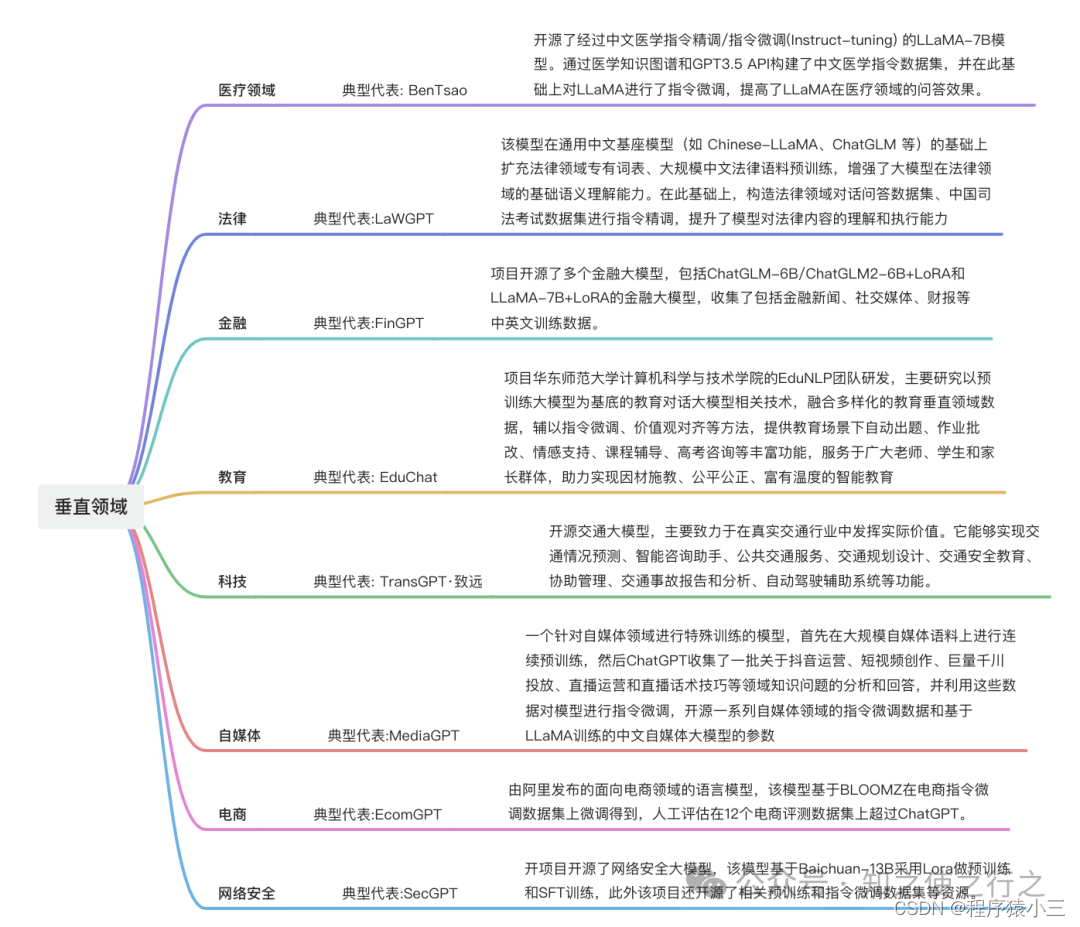
特别是医学、金融等民生行业,已经开始落地,我相信这些行业和大模型的结合会让大模型走得更远和更稳.
3、微调大模型的基本思路
按方法来分:
(1)、Continue PreTraining(增量预训练): 一般垂直大模型是基于通用大模型进行二次的开发。为了给模型注入领域知识,就需要用领域内的语料进行继续预训练。
(2)、SFT( Supervised Finetuning,有监督微调): 通过SFT可以激发大模型理解领域内的各种问题并进行回答的能力(在有召回知识的基础上)
(3)、RLHF(奖励建模、强化学习训练): 通过RLHF可以让大模型的回答对齐人们的偏好,比如行文的风格。
(4)、DPO(直接偏好优化)
按阶段来分的话:
一般来说, 垂直领域的现状就是大家积累很多电子数据,从现实出发,第一步可以先做增量训练.所以会把模型分成3个阶段:
(1)、第一阶段:(Continue PreTraining)增量预训练,在海量领域文档数据上二次预训练GPT模型,以注入领域知识.
(2)、第二阶段: SFT(Supervised Fine-tuning)有监督微调,构造指令微调数据集,在预训练模型基础上做指令精调,以对齐指令意图
(3)、第三阶段 : RLHF和DPO二选一
RLHF(Reinforcement Learning from Human Feedback)基于人类反馈对语言模型进行强化学习,分为两步:RM(Reward Model)奖励模型建模,构造人类偏好排序数据集,训练奖励模型,用来建模人类偏好,主要是"HHH"原则RL(Reinforcement Learning)强化学习,用奖励模型来训练SFT模型,生成模型使用奖励或惩罚来更新其策略,以便生成更高质量、更符合人类偏好的文.
DPO(Direct Preference Optimization)直接偏好优化方法,DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好,DPO相较于RLHF更容易实现且易于训练,效果更好
4、Pretraining阶段数据集准备
这是非常在微调中非常关键的一步,领域的核心就是构建高质量的数据集,那么如何准备数据: 网上已有、企业私有、+chatgpt扩充. 这一步的数据集相对比较简单,上面说过, pretraining就是注入专业知识,其实就是一些垂直文章的内容,比如书籍、博客等. MedicalGPT的pretraining数据类似:

5、微调模型选择
微调模型选择的宗旨主要有3个:
自己有什么样的资源
模型的开源性
模型的开放性和所需的资源
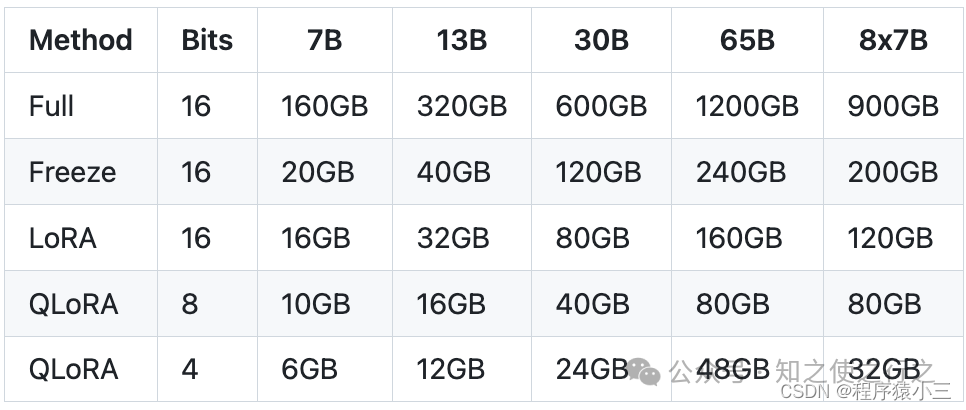
本人使用kaggle、clolab等免费GPU平台,综合下来,选择bloomz-560m模型进行微调测试.
6、kaggle上微调bloomz-560m
为了快速实验, 依然用的还是MedicalGPT中的数据集,也方面后续对比效果, 验证重构代码的准确性
# pretraining 训练
%cd /kaggle/working/autoorder
!git pull
!pip install -r algorithm/llm/requirements.txt
!pip install Logbook
import os
os.environ['RUN_PACKAGE'] = 'algorithm.llm.train.pretraining'
os.environ['RUN_CLASS'] = 'PreTraining'
print(os.getenv("RUN_PACKAGE"))
!python main.py \
--model_type bloom \
--model_name_or_path bigscience/bloomz-560m \
--train_file_dir /kaggle/working/MedicalGPT/data/pretrain \
--validation_file_dir /kaggle/working/MedicalGPT/data/pretrain \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--do_train \
--do_eval \
--use_peft True \
--seed 42 \
--max_train_samples 10000 \
--max_eval_samples 10 \
--num_train_epochs 0.5 \
--learning_rate 2e-4 \
--warmup_ratio 0.05 \
--weight_decay 0.01 \
--logging_strategy steps \
--logging_steps 10 \
--eval_steps 50 \
--evaluation_strategy steps \
--save_steps 500 \
--save_strategy steps \
--save_total_limit 13 \
--gradient_accumulation_steps 1 \
--preprocessing_num_workers 10 \
--block_size 512 \
--group_by_length True \
--output_dir outputs-pt-bloom-v1 \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--target_modules all \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--torch_dtype bfloat16 \
--device_map auto \
--report_to tensorboard \
--ddp_find_unused_parameters False \
--gradient_checkpointing True \
--cache_dir ./cache