目录
- 写在前面
- 1. 摘要
- 2. 相关知识
- 3. MCR方法
- 3.1 生成推理链
- 3.2 基于推理链的推理
- 4. 实验
- 4.1 实验设置
- 4.2 实验结果
- 5. 提及文献
写在前面
- 文章标题:Answering Questions by Meta-Reasoning over Multiple Chains of Thought
- 论文链接:【1】
- 代码链接:暂无
- 仅作个人学习记录用
1. 摘要
现代多跳问答系统(QA)通常将问题分解为一系列的推理步骤,称为思维链(CoT),然后得出最终答案。通常,多个链通过对最终答案的投票机制进行抽样和聚合,但中间步骤本身被丢弃。虽然这些方法提高了性能,但它们没有考虑跨链中间步骤之间的关系,也没有为预测答案提供统一的解释。本文介绍了多链推理(Multi-Chain Reasoning, MCR),一种促使大型语言模型在多条思维链上进行元推理的方法,而不是聚合它们的答案。MCR检查不同的推理链,混合它们之间的信息,并选择在生成解释和预测答案中最相关的事实。在7个多跳QA数据集上,MCR都优于基准模型。此外,分析表明,MCR的解释具有较高的质量,使人类能够验证其答案。
2. 相关知识
对于多跳问答,可以查看【论文笔记】Self-Prompted CoT:自发思维链框架 中的第一部分:1. 开放域 | 多跳 | 推理 | 问答。
对于CoT有关知识,可以查看【学习记录】Prompt Engineering:ICL、CoT 以及更多。
3. MCR方法
MCR方法是一种在多条推理链上进行元推理来回答问题的方法。重点是开放域问答,其中输入是一个问题 q q q ,回答它的证据是在语料库 C C C 中的一个或多个句子中找到的。当回答 q q q 需要多个推理步骤时,它可以用一个推理链来表示,记为 r r r。推理链是一个或多个中间问题-证据-答案三元组 ( q i , e i , a i ) (q_i, e_i, a_i) (qi,ei,ai) 的列表。证据 e i ∈ C e_i∈C ei∈C是一个与回答中间问题 q i q_i qi 相关的句子。
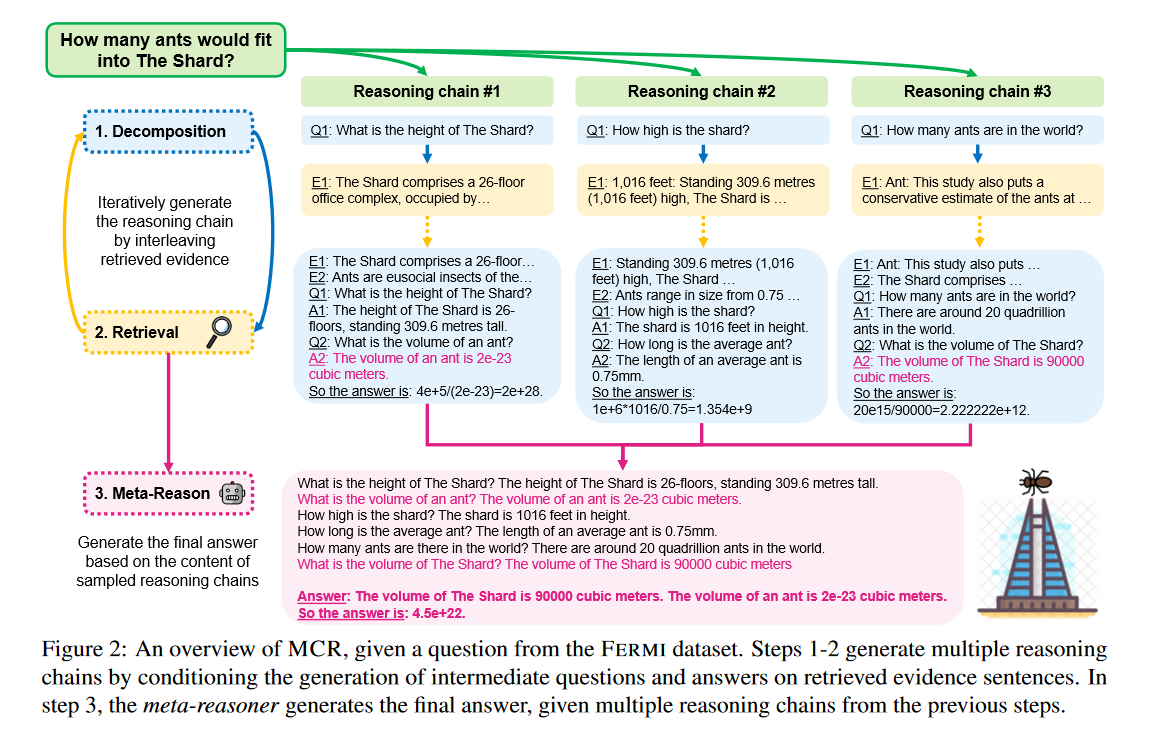
上图描述了在回答 “多少蚂蚁适合进入碎片大厦? " 时的MCR方法。
第一,作者首先使用一个 prompted LLM 来生成多条推理链, r ( 1 ) , . . . , r ( k ) r^{(1)},..., r^{(k)} r(1),...,r(k) (步骤1 ~ 2)。每个 r ( j ) r^{(j)} r(j) 是由生成的中间问题和检索到的上下文交织生成的(§3.1)。本文的主要贡献是步骤3:引入第二个 LLM ,在多个推理链上提示元推理,收集证据事实作为其解释并生成最终答案(§3.2)。
3.1 生成推理链

给定一个问题 q q q,本文使用:(1) 一个分解模型 和 (2) 一个检索器组件来生成它的推理链。本文的推理链生成过程在很大程度上是基于之前的研究工作(Press et al., 2022; Trivedi et al., 2022a)。上图描述了分解和提取的交替进行。在每一步中,分解模型根据原始问题 q q q 和前面的推理步骤生成一个中间问题 q i q_i qi。然后,检索器利用 q i q_i qi 检索相关证据 e i ∈ C e_i∈C ei∈C,将 e i e_i ei 和 q i q_i qi 反馈到分解模型(伴随着前面的步骤)中,生成中间答案 a i a_i ai。在答案生成过程中,作者将中间证据句前置到链的开始部分,而不是将它们交错起来,因为它提高了所有基线的准确性。对于分解提示,具体见论文中的 §D ,在此不再叙述。
3.2 基于推理链的推理
元推理模块是MCR的核心贡献。作者利用它们进行上下文生成,而不是为它们的预测答案采样多条链。这个context被输入到一个提示的 prompted LLM 中,以读取生成的链并对其进行推理以返回答案。
在 §3.1 中,将推理链定义为 ( q i , e i , a i ) (q_i, e_i, a_i) (qi,ei,ai) 三元组的列表。首先对多个链进行采样,并使用它们的所有中间问答对 ( q i , a i ) (q_i , a_i) (qi,ai) 作为我们的多链上下文(使用问题-证据对 ( q i , e i ) (q_i , e_i) (qi,ei) 的变式)。元推理模块从多个推理链(§ 3.2)中抽取出问答 ( q i , a i ) (q_i , a_i) (qi,ai)对的多链语境来回答问题。作者实验了一个备选的多链情境,由问题和检索到的证据 ( q i , e i ) (q_i , e_i) (qi,ei) (§3.1)组成。这个设定类似于过去的工作(Trivedi et al., 2022a),然而,句子是来自多个推理链的中间证据,而不仅仅是贪婪-解码链(greedy-decoded chain)。作者将这些变体 MCR - Ev 和 SCR - Ev 与 MCR 和 SCR 在QA对上的原因进行了比较。MCR - Ev 和 SCR - Ev 的示例提示在论文中的 §D 中列出。
本文第一张图展示了三个采样链(下部的粉红色方框)的多链上下文。接下来,向元推理模块输入多链语境和原始问题。该模型是一个LLM,在多链环境下进行QA的小样本提示。下图是FEVEROUS数据集(在论文 §D 中给出了充分的提示)元推理提示的一个示例。作者指导LLM在给定多链上下文的情况下"分步回答问题",其中每一行描述来自其中一条采样链的
(
q
i
,
a
i
)
(q_i , a_i)
(qi,ai) 对。接下来,追加问题和一个循序渐进的推理链,紧接着给出最终的答案。最后一环是对问题的解说。元推理模块是在数据集的基础上,用6 - 10个示例来提示的。

为元推理模块提供多思维链,使其能够跨链组合和聚合事实。此外,模型需要提取链条中最相关的事实作为其解释。这使得 MCR 比过去的多链方法更准确,更具有可解释性。
4. 实验
作者在7个多跳QA基准测试中将 MCR 与现有方法进行了比较。这些涵盖了广泛的推理技巧,包括常识、作文、比较和事实验证。当使用两种不同的LLM和检索器进行实验时,MCR 在所有基准测试中始终优于现有方法。实验的设置在 §4.1 中描述,在 §4.2 中讨论主要结果。
4.1 实验设置
由于本文关注的是多跳问题(在开放域环境中),所有的数据集都需要多个推理步骤。遵循前期工作 (Khattab et al., 2022; Trivedi et al., 2022a),为了限制模型API调用的成本,作者从每个模型的开发集中随机抽取500 ~ 1000个实例进行评估。作者还在STRATEGYQA和FERMI的官方测试集上进行了评估,因为它们以隐式推理为目标,具有多个有效策略,并且它们的测试集评估代价是合理的。对于所有的数据集,我们确保在我们的任何提示中都不会出现评估问题。下表从每个数据集中都有示例问题。我们的多跳QA基准可以根据它们所需的推理技能进行分类:显式推理(Implicit Reasoning)与隐式推理(Explicit Reasoning)。

为了评估,作者使用F1-score来比较所有显式推理数据集的预测答案和黄金答案和二元选择数据集的精确匹配。在FERMI中,使用了Kalyan et al (2021) 的官方数量级评估。作者在论文中 §A 提供了关于评估的额外技术细节。
元推理模块:
- MCR:元推理模块被赋予5条推理链作为其多链语境(§ 3.2)。用贪婪解码的方法解码一条链,并采样另外四条温度 t = 0.7 t= 0.7 t=0.7 的推理链,这使得元推理模块在回答完整问题时可以审查不同的证据。
- SCR:单链推理(Single-Chain Reasoning, SCR)可以消除多链上下文的影响。在SCR中,元推理模块除了在上下文中只有贪婪解码的链外,还被给予与MCR相同的提示。这就将使用多条链的效果与从分解模型中分离出来的LLM产生最终答案的效果区分开来。
基准模型:
- SA:Self-Ask (Press et al., 2022) 返回由贪婪解码生成的单个推理链的答案。
- SC:Self-Consistency (Wang et al , 2023) 作为基线,包含多个推理链。它基于从分解模型中采样的多条链来返回多数答案。使用3、5和15个采样链的变体进行实验,与之前的工作一致。与MCR一样,使用贪婪解码生成的链以及 t = 0.7 t=0.7 t=0.7 时采样的额外链。
检索方式:检索方式与Press et al . (2022) 类似,本文的模型和基线使用基于Google Search的检索器,通过SerpAPI服务。然而,作者还包括使用开源检索器(Khattab and Zaharia, 2020)。由于本文的大部分数据集都包含了来自维基百科的证据,因此作者将其作为检索语料。因此,作者将搜索查询格式化为 ’ en.wikipedia.org q i q_i qi ’ ,其中维基百科域位于中间问题之前。返回谷歌检索到的排名前1的证据。检索到的证据既可以是句子,也可以是解析后的列表。继 Trivedi et al. (2022a) 之后,作者还检索了原问题 q q q 的证据。最后,将所有检索到的证据句前置到分解(§3.1)。
4.2 实验结果
实验设计与结果较多,分析较丰富,有空补充
5. 提及文献
[1] Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2022. Measuring and narrowing the compositionality gap in language models. ArXiv, abs/2210.03350.
[2] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022a. Interleaving retrieval with chain-of-thought reasoning for knowledgeintensive multi-step questions.
[3] O. Khattab, Keshav Santhanam, Xiang Lisa Li, David Leo Wright Hall, Percy Liang, Christopher Potts, and Matei A. Zaharia. 2022. Demonstrate-searchpredict: Composing retrieval and language models for knowledge-intensive nlp. ArXiv, abs/2212.14024.
[4] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations.
[5] Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over BERT. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, pages 39–48. ACM.