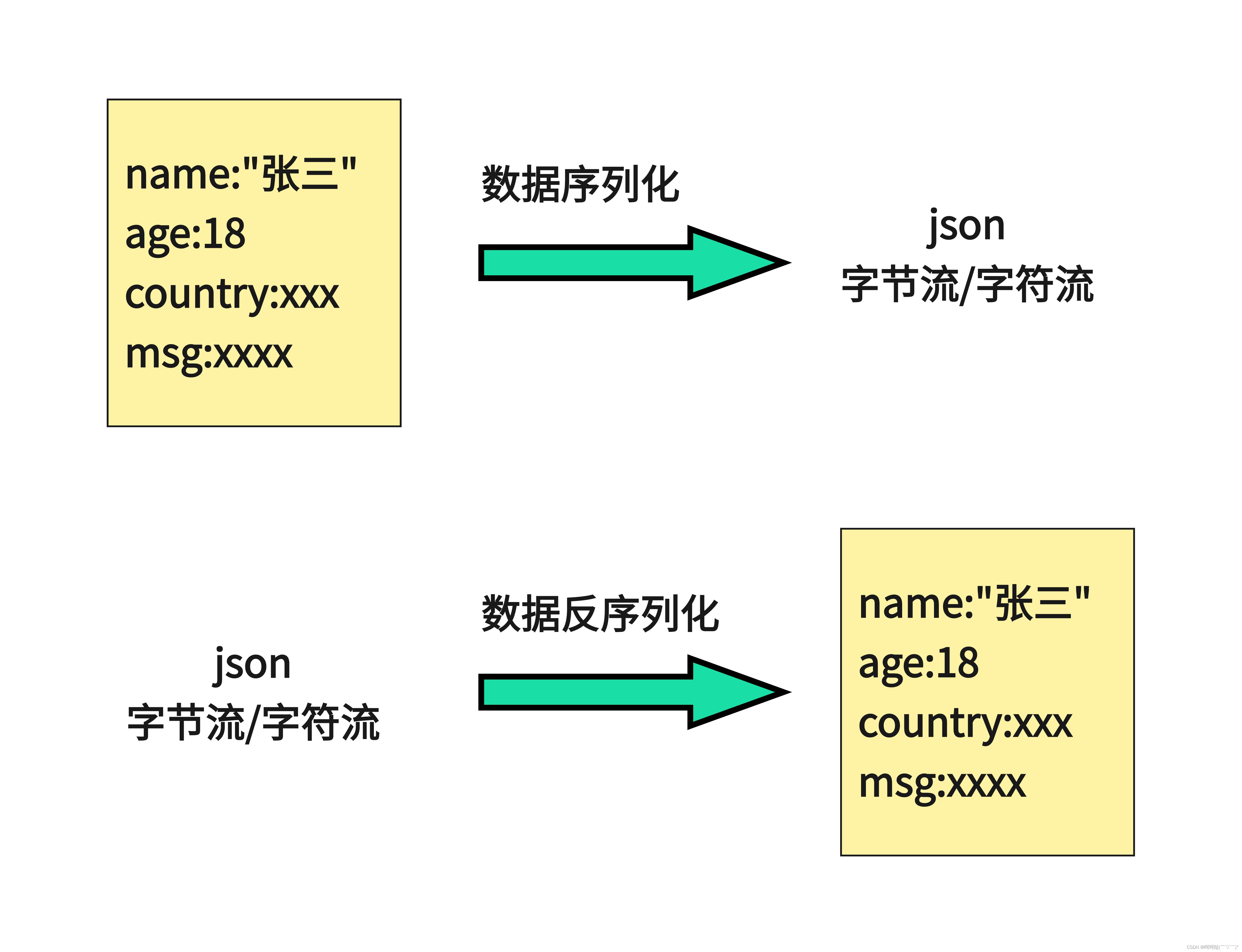
缓存相关问题
在这里我不得不说明,我写的博客都是我自己用心写的,我自己用心记录的,我写的很详细,所以会有点冗长,所以如果你能看的下去的化,会有所收获,我不想写那种copy的文章,因为对我来说没什么益处,我写的这篇博客,就是为了记录我缓存的相关问题,还有我自己的感悟,所以如果你有耐心看下去,我希望和你交朋友,如果你觉得我哪些地方写的不正确,你可能立马私信我,或者评论,希望你能参与到我的博客写作中来
缓存更新策略
缓存更新有三种策略

第一种,是类似redis这种缓存自己内置的内存淘汰机制
第二种,是redis的ttl,这个也很好理解
第三种,是我们再修改涉及到缓存的数据的时候,主动去更新相关缓存
可想而知,前两种,都不是可控的,我们实际上再项目中,我们应该都一起用,redis的内存淘汰做次要,还有ttl也做次要,主要我们要写的就是这个主动更新,这样才很好的保持一致性
主动更新策略
主动更新也有三种策略

看上去,有点难理解,其实很好理解后两种,就是依赖于别的服务,去进行缓存更新,第一种,是我们程序员自己去更新
像后两种,我就想起一个框架,SpringCache 这样的框架,你说它好吧,确实也挺好,能省写很多代码,但是他最大的缺点就在于,不灵活,不可控,总的来看,也没省多少代码,我认为不必去想后两种的方式,除非你公司要用,我门应该选择最可控的,也就是自己写!
缓存与数据一致性解决
当数据库发生更新的时候,我们有几个问题需要去考虑
到底是更新缓存,还是删除缓存
第一个问题就是到底是更新好,还是直接删除好,这里我们想想也是还是删除好,不能每次都去更新,这样多浪费资源啊
我们应该直接删除,然后下一个人来查询的时候,再去更新缓存
如何保证缓存与数据库同时失败和成功
单体项目: 加上事务@Transactional
分布式系统,利用tcc等分布式解决方案
我们到底是先删除缓存还是先更新数据库
这个问题很值得去研究一下,如果你想研究明白,就得去画个图,看看,那个比较好,我们先说结论,先更新数据库,一致性会比较好,我这里写的会写的十分详细,我认为这里很有意思,希望你能看下来,你会觉得先更新数据库会更合理一点
你可能会不服,但是你先听我讲,我把工作的线程叫做更新线程,
扰乱我们工作的,我叫他捣乱线程
假设我们先删除缓存
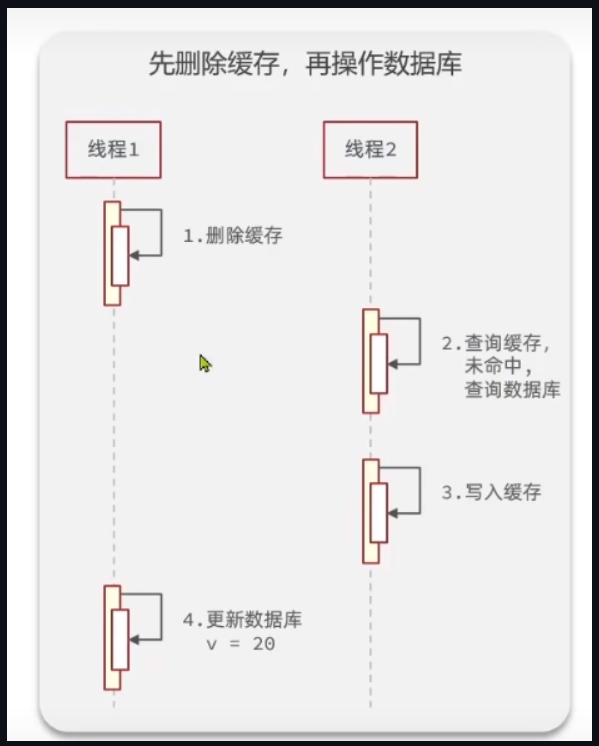
上面这个图就是会发生得到缓存是不一致的
我们来研究这个问题,就得分为三个时间点
第一: 如果是在删除缓存之前,
- 查询缓存,得到的就是旧数据
- 删除缓存 ,此时缓存为空
- 更新数据库
此时缓存为空,下一次查询的时候,得到正确的数据,这是正确的
第二: 如果我们在删除缓存之后,更新数据库之前,
- 更新线程先删除缓存
- 捣乱线程先查缓存,没有命中,查询数据库
- 捣乱线程写入缓存,此时的缓存是旧数据
- 最后再更新数据库
我们能看到,此时缓存中的数据和数据库不一致,出现一致性问题!
第三: 如果我们再更新数据库之后,来查的缓存,
此时的缓存直接就是空的,那么我们捣乱线程来查的化,会去数据库查到正确的数据,此时是正确的
总结来看,就是当删除缓存之后,更新数据库之前,来了一个查询,就会出现一致性问题,而且可想而知,如果并发量大的化,很容易出现这种问题,因为这两个操作中间的时间太久了,很容易出问题
假设我们先更新数据库
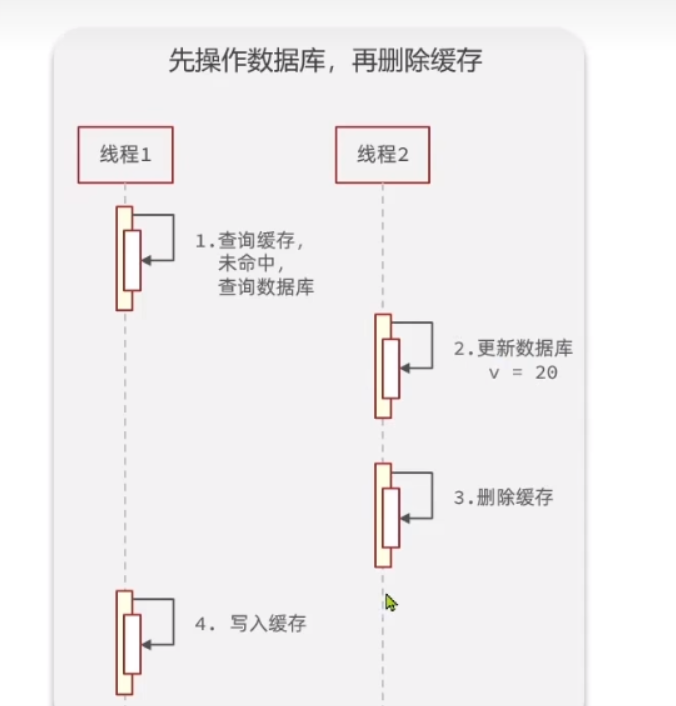
上面这个图就是有可能会发生错误的时机,这里你看到可能会有问题,为什么这里查缓存会直接查不到呢? 你想,
但是确实如果会出现一致性问题的化,有一个大前提,就是再更新数据库之前,我们的缓存就出错了或者失效
我们一步一步来看,假设没有这个前提,也就是说,如果缓存没有失效
第一: 再更新数据库之前,
- 查缓存,此时缓存是旧数据,
- 然后更新数据库
- 删除缓存
此时缓存是空的,那么下一次查询就可以得到正确的数据,没问题
第二: 我们再更新数据库之后,删除缓存之前
- 查缓存,得到的是旧数据
- 然后删除缓存
此时缓存还是空的,所以下一次查询还是正确的数据,没问题
第三: 我们在删除缓存之后,查数据,这个时候,肯定是得到新的数据,这也是没什么问题的
所以,综上所述,在我们更新的时候,假设缓存还存在,那么就不会出现一致性问题
那么你就想知道了,那么什么时候会出现一致性问题呢?
出现这个一致性问题,有两个前提
第一: 也是上面我们论证的,就是必须在更新数据库的时候,缓存突然失效了
第二: 我们并行过来的查缓存,必须写入缓存在删除缓存之后
你们可能会不是很理解我这里的化,那么就得出现我上面那个图了
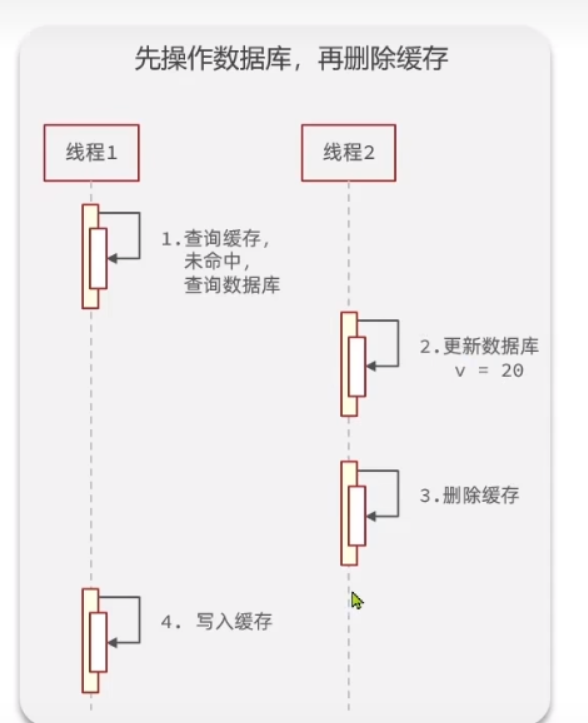
其实也很好理解,左边这个线程是来捣乱的那个线程,右边的线程是我们更新的线程
我上面的第二个前提说的就是,这里的第3步删除缓存必须在写入缓存之前
我们如何论证呢?
我们假设这里删除缓存在写入缓存之后,会发生什么事情
那么整体的流程就是这样,
- 捣乱线程先查缓存,因为缓存失效,没有命中,查数据库
- 我们的更新线程先去更新数据库
- 捣乱线程,写入缓存,此时的缓存是旧的
- 我们的更新线程删除缓存,此时缓存为空
我们捋了一下这个过程,会发现,此时依然是正确的,删除缓存在最后,得到的缓存就会变成空,没有一致性问题!
最终出现问题的时机!!!
我们继续来捋一下这里的过程
- 首先捣乱线程先查询缓存,此时由于缓存失效,所以未命中,查询数据库,此时的到的是旧数据
- 更新线程,更新数据库
- 更新线程删除缓存,此时缓存为空
- 捣乱线程写入缓存,此时写入的是旧数据
那么,就终于出现一致性问题了,此时得到的就是旧数据
最终比较
那么我想你看明白我想说的,就很明了了,为什么我们要去先更新数据库?
问题的关键就在于,哪种情况更容易出问题,那么先删除缓存,出问题的几率更大,而先更新数据库,出问题的几率很小,因为我们要满足两大前提
第一个前提是,更新数据库之前,缓存莫名其妙不见了
第二个前提是,捣乱线程写入缓存的时候,是在更新线程删除缓存之后
这个条件是很严苛的,所以最后的答案就是先更新数据库!
缓存穿透
什么是缓存穿透,很好理解,就是缓存没命中,数据库没命中,这样所以类似的查询全部达到数据库上,那么数据库就爆炸了
如果有一个黑客知道你有缓存穿透的问题的化,那么他就打很多的请求达到你这个系统里边,那么你系统就宕机了
解决办法,有两个,我比较能理解第一个,第二个不太了解,等我了解了,我再来更新这篇博客
缓存空对象
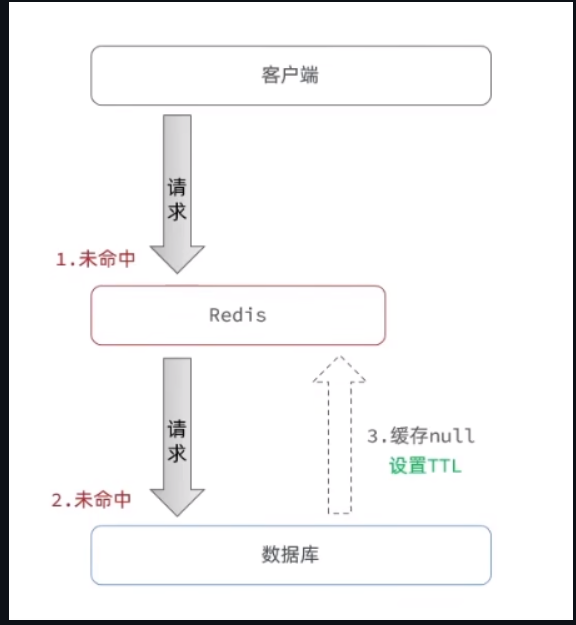
第一种,也是耳熟能祥的,也就是缓存一个空对象过来,他的解决思路其实也很好理解,不是说redis缓存中不了吗,那么我们就让他中缓存,如果说redis中,没查到,数据库中没查到,我们就设置一个空对象,
key是刚刚查询的key,只不过value是null,那么就算他有几亿次请求,也都是命中缓存,打不到数据库
缺点
你会觉得啊,这个解决很好啊,那么就可以杜绝所有缓存穿透的问题了,不对,只要黑客换个思路的化,那么一样会有问题
如果说黑客,知道你有设置空对象来防御缓存穿透,那么他就换个思路,既然你设置空对象,那么我让你把redis内存全都挤满空对象,那么你redis最后也是宕机,整个服务还是宕机!
所以,搞空对象会有内存占用,我们一般得设置ttl来防御此类情况发生
而且这里的ttl不能设置太久,如果设置太久一样会出现这个问题
总结来看缺点就是:
- 有额外的内存消耗,一般设置ttl
- 可能会造成短期的不一致,设置的ttl要合理,太久了不行
布隆过滤
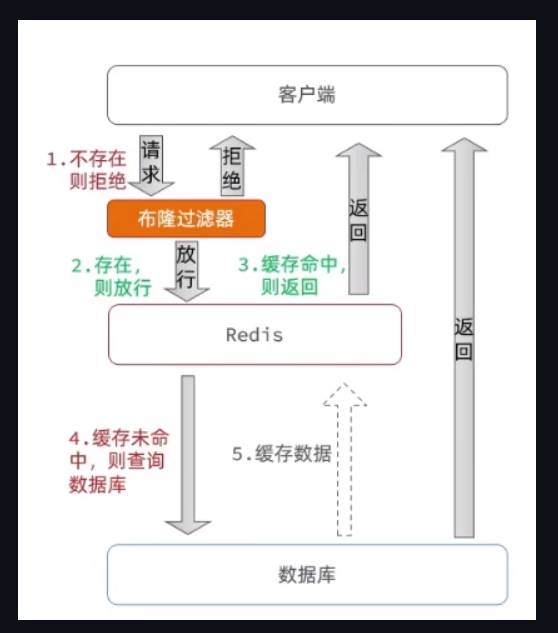
这里的布隆过滤器,我也不是很明白,他的判断依据是什么,但是我们能理解他的设计思路,就是再加一层来保存缓存,如果没有命中,就拦截
缓存空对象实战
接下来我们来实现缓存空对象,我们先来看原来的我这里的示例流程,我这的实战也是有些复杂,希望你不要那么着急,这里的数据库中的表,你可以随意写一个,只要能返回列表的,我这里的表是商铺数据
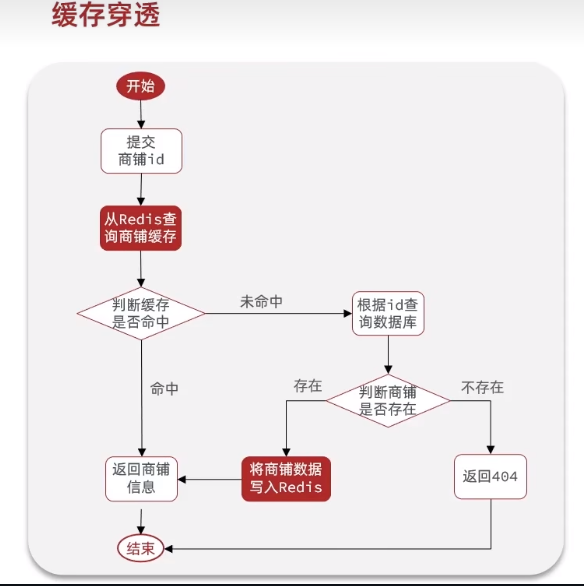
整体的流程我简单的概述一下,看下来就是很简单的缓存商户的信息,先是去判断缓存中是否有,如果没有就去查数据库
原先的代码
Controller
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
Shop shop = shopService.queryShopById(id);
return Result.ok(shop);
}
IShopService
public interface IShopService extends IService<Shop> {
/**
* 获取商户信息
* @param id
* @return
*/
Shop queryShopById(Long id);
}
实现类
/**
* 获取商户信息
* @param id
* @return
*/
@Override
public Shop queryShopById(Long id) {
//查redis
String shopKey = RedisConstants.CACHE_SHOP_KEY + id;
String shopJSON = redisCache.getCacheObject(shopKey);
//缓存有,直接返回
Shop shop = null;
if(StrUtil.isNotBlank(shopJSON)) {
shop = JSONUtil.toBean(shopJSON,Shop.class);
return shop;
}
//不存在就去查数据库
shop = getById(id);
//数据库没查到!
if(Objects.isNull(shop)) {
return null;
}
//存入缓存
redisCache.setCacheObject(shopKey,shop);
return shop;
}
问题复现
我数据库中,没有id为15的商铺数据,这里的示范数据,只要选你表中没有的进行测试
发送请求
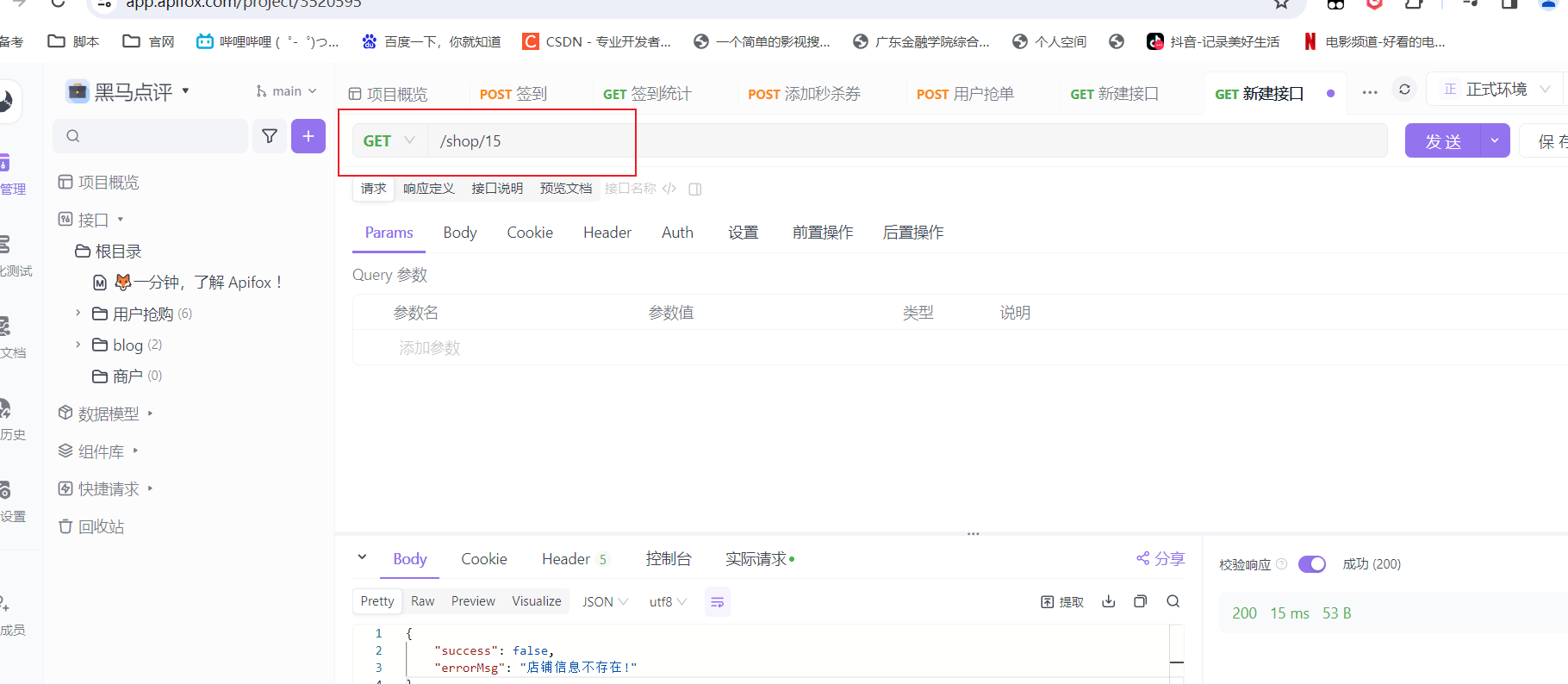
不断的发几次请求,看idea的sql是否有几段
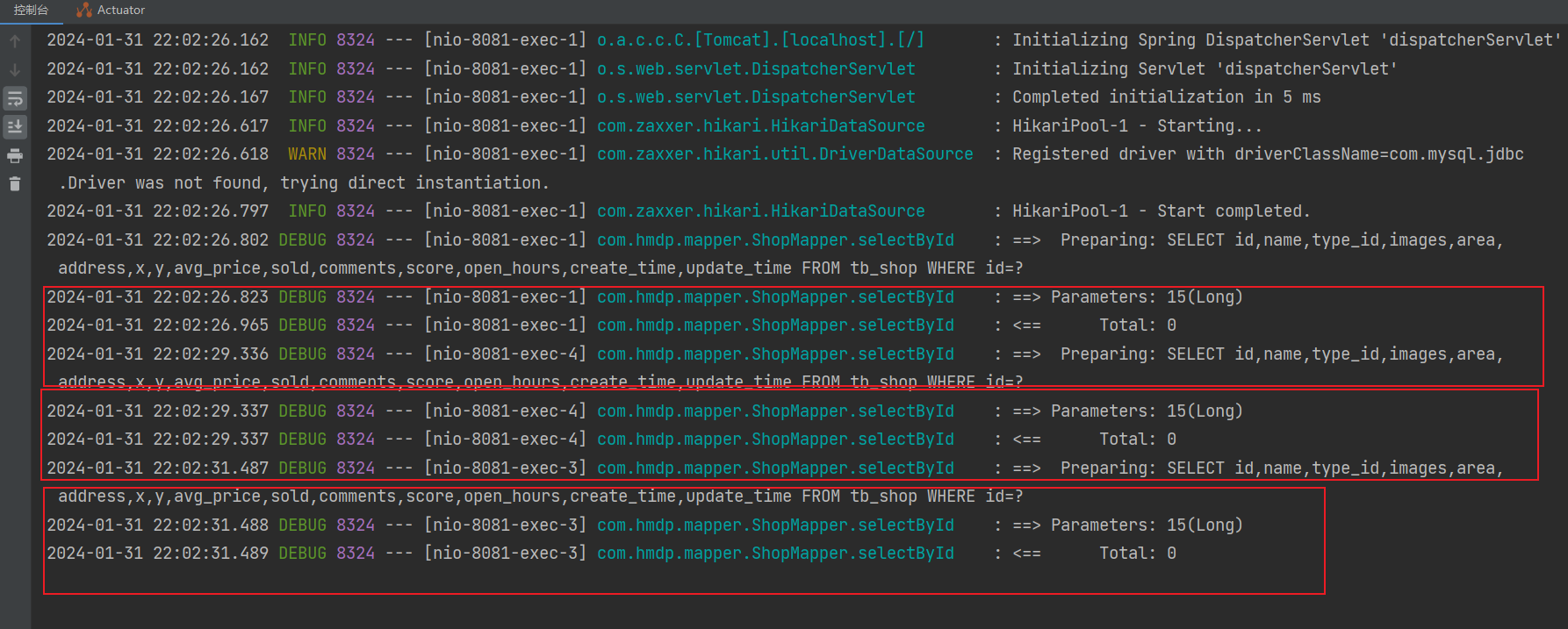
结果确实是重复的
代码
其他的都基本差不多,这里我就只贴出,service是实现类的改动代码
/**
* 获取商户信息
* @param id
* @return
*/
@Override
public Shop queryShopById(Long id) {
//查redis
String shopKey = RedisConstants.CACHE_SHOP_KEY + id;
String shopJSON = redisCache.getCacheObject(shopKey);
//缓存有,直接返回
Shop shop = null;
if(StrUtil.isNotBlank(shopJSON)) {
shop = JSONUtil.toBean(shopJSON,Shop.class);
return shop;
}
//判断是否是我们自己写的""
if(shopJSON != null) {
return null;
}
//不存在
shop = getById(id);
if(Objects.isNull(shop)) {
//导入空值,进入缓存
redisCache.setCacheObject(shopKey,"",RedisConstants.CACHE_NULL_TTL.intValue(), TimeUnit.MINUTES);
return null;
}
//存入缓存
redisCache.setCacheObject(shopKey,shop);
return shop;
}
改动的地方
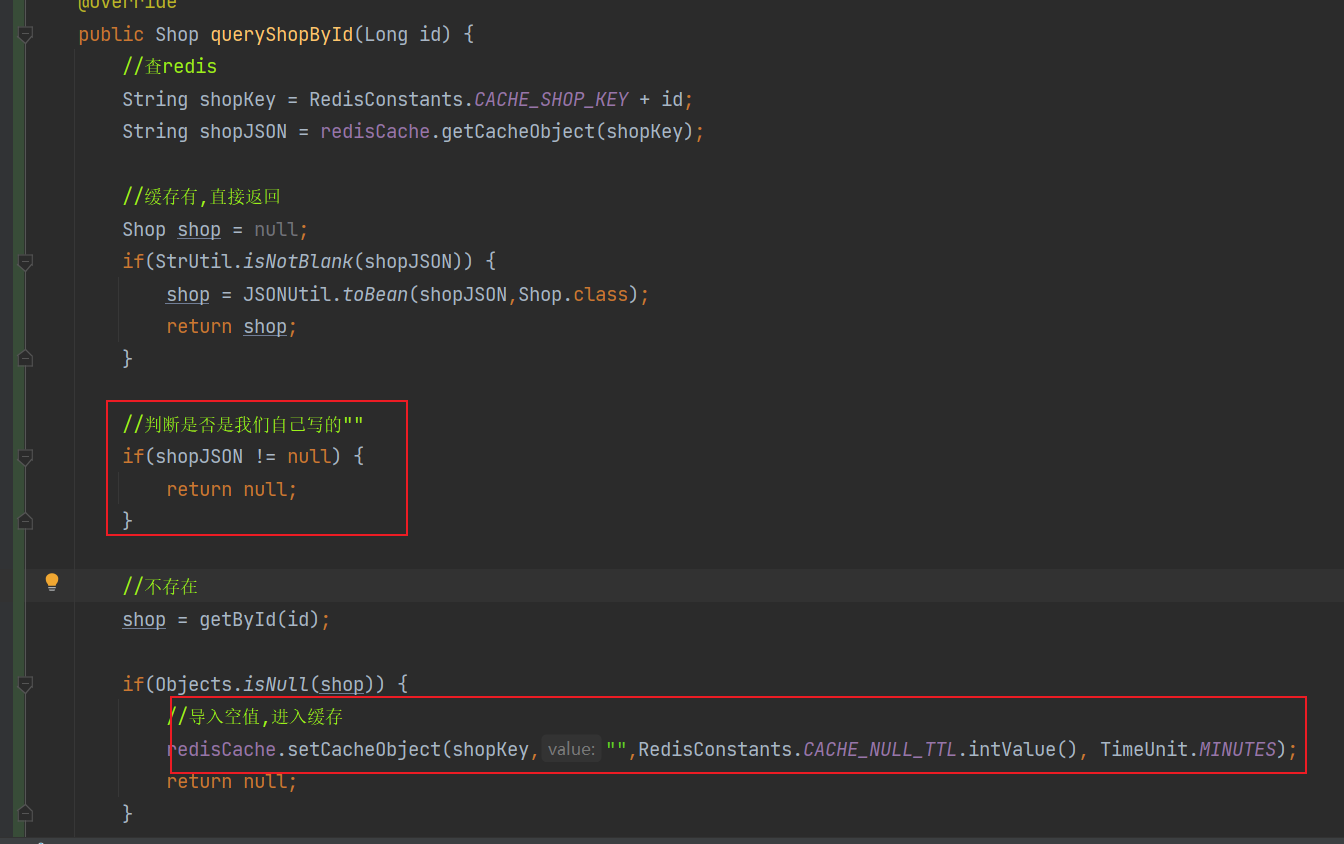
测试
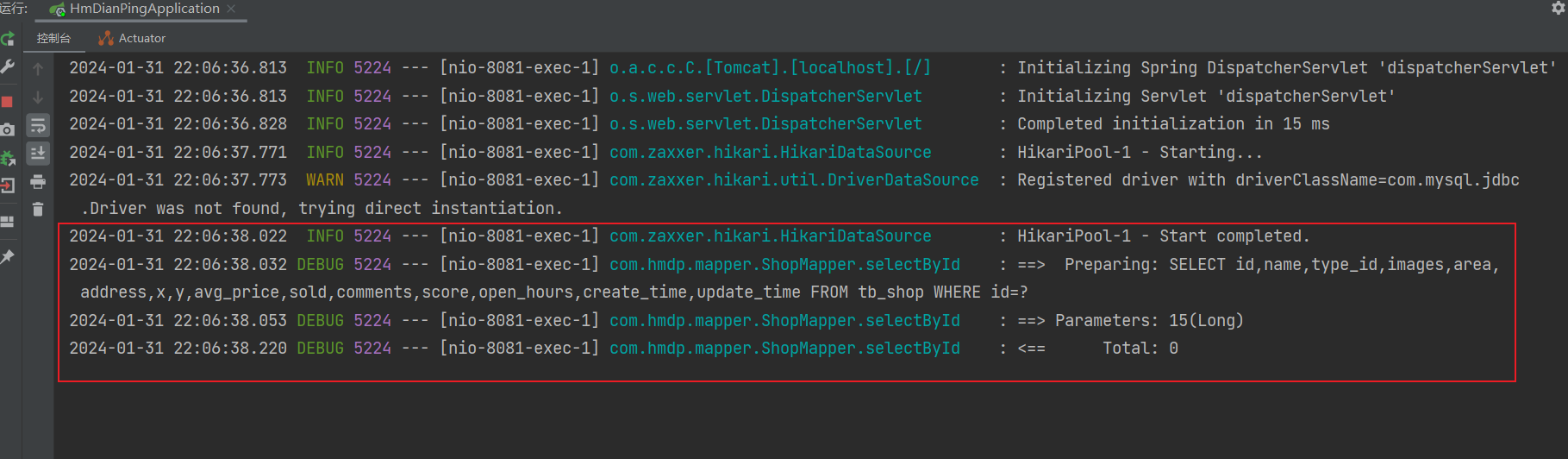
这里只会触发一次,不管请求多少次,但是ttl一过,还会发一次
缓存雪崩
缓存雪崩很好理解,什么是雪崩,就是突然很多雪突然松动,最后一起崩坏
所以缓存雪崩出现的原因就是,同一时间段,大量的缓存key同时失效,或者说redis宕机,那么大量请求打到数据库,数据库就爆炸了!
解决起来也不是特别难,主要是我们的系统得健壮一点,不能这么脆弱
解决方法
- 给不同的key的ttl添加随机值
- redis集群
- 给缓存添加降级限流的策略
- 给业务设置多级缓存
所以我们要么多搞点redis,多加几层缓存,这样的问题,也是很容易避免的
缓存击穿
缓存击穿,这里的击穿是由于热点key的问题,热点key突然集体失效,那么 高并发 + 缓存重建业务复杂 ,无数的请求打到数据库,那么数据库就爆炸了!
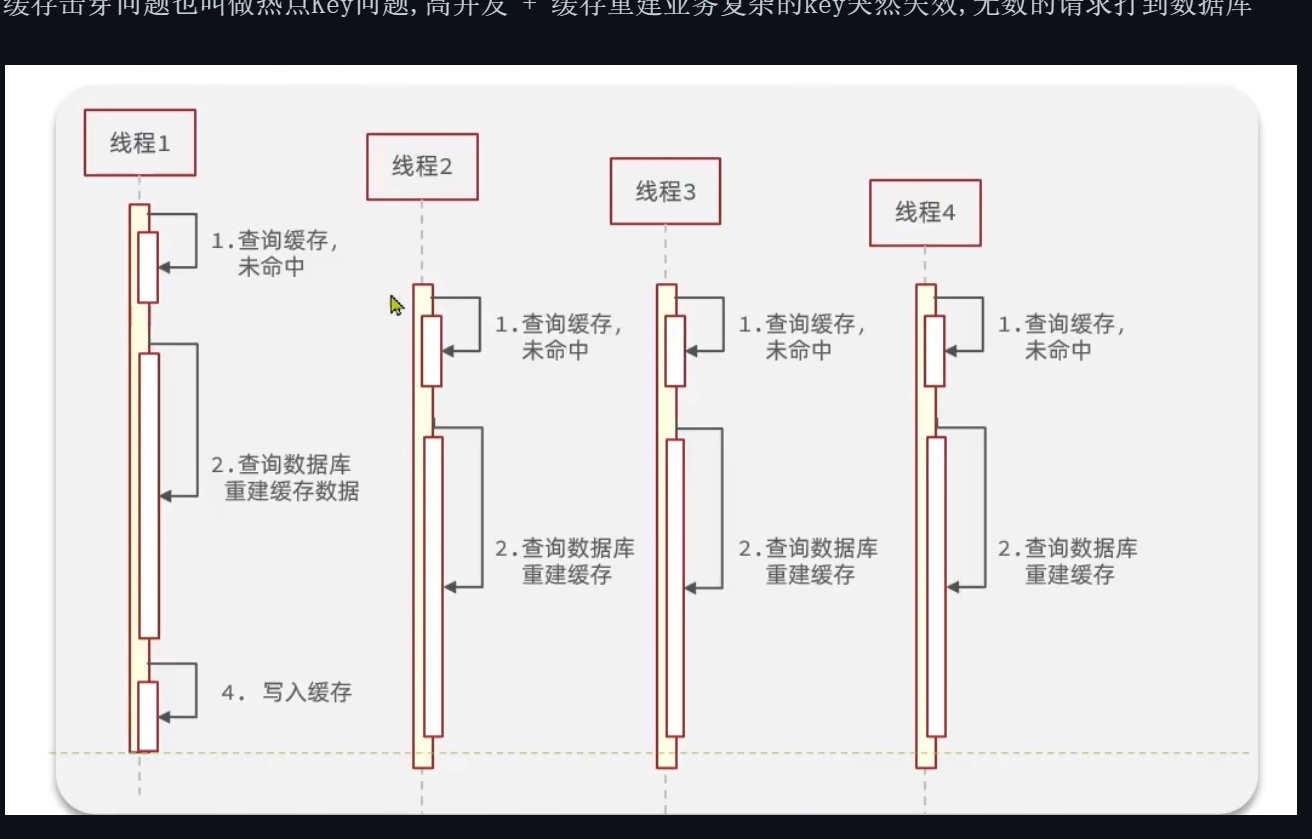
这里的缓存击穿,更形象的说,是一瞬间事,他的意思是在高并发的那一个瞬间,突然缓存失效,加上缓存重建要很久,所以就爆炸了
有两种解决方法
互斥锁
出现缓存击穿问题就在于,在那一瞬间有很多重建的请求,那么我们就消除那么多重建的请求不就的了,那么就很容易想到,加锁,当发现要重建的时候,第一个请求就加上锁,之后再来请求就获取锁失败,让他休眠一会,再重试
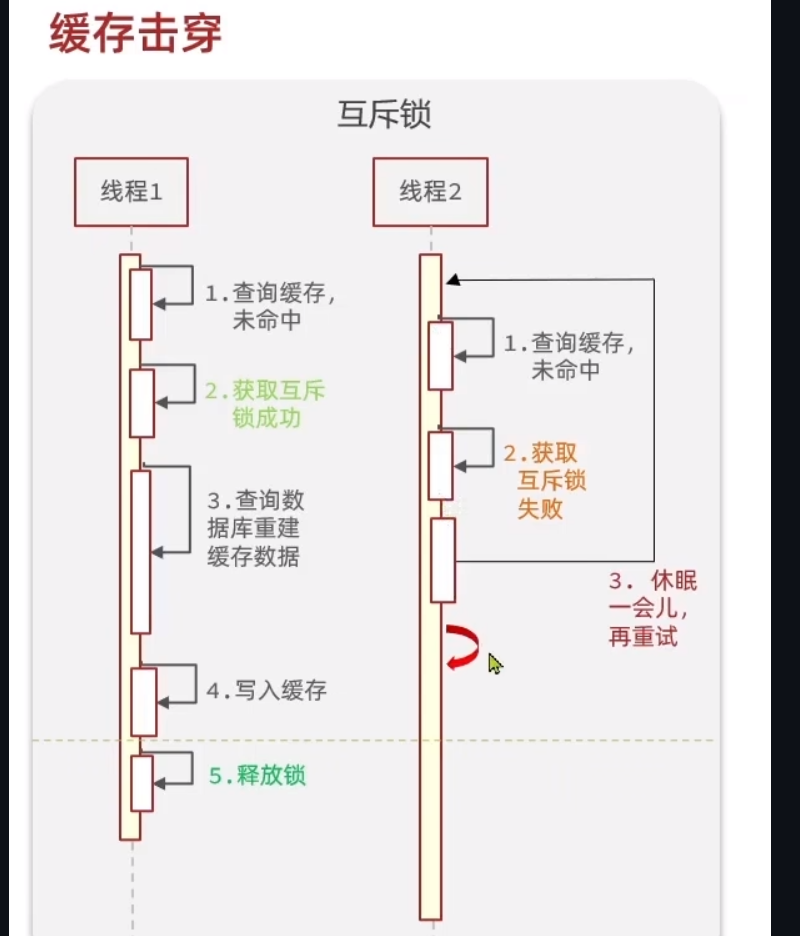
逻辑过期
逻辑过期的想法,还挺有想法的,就是设置一个逻辑过期的字段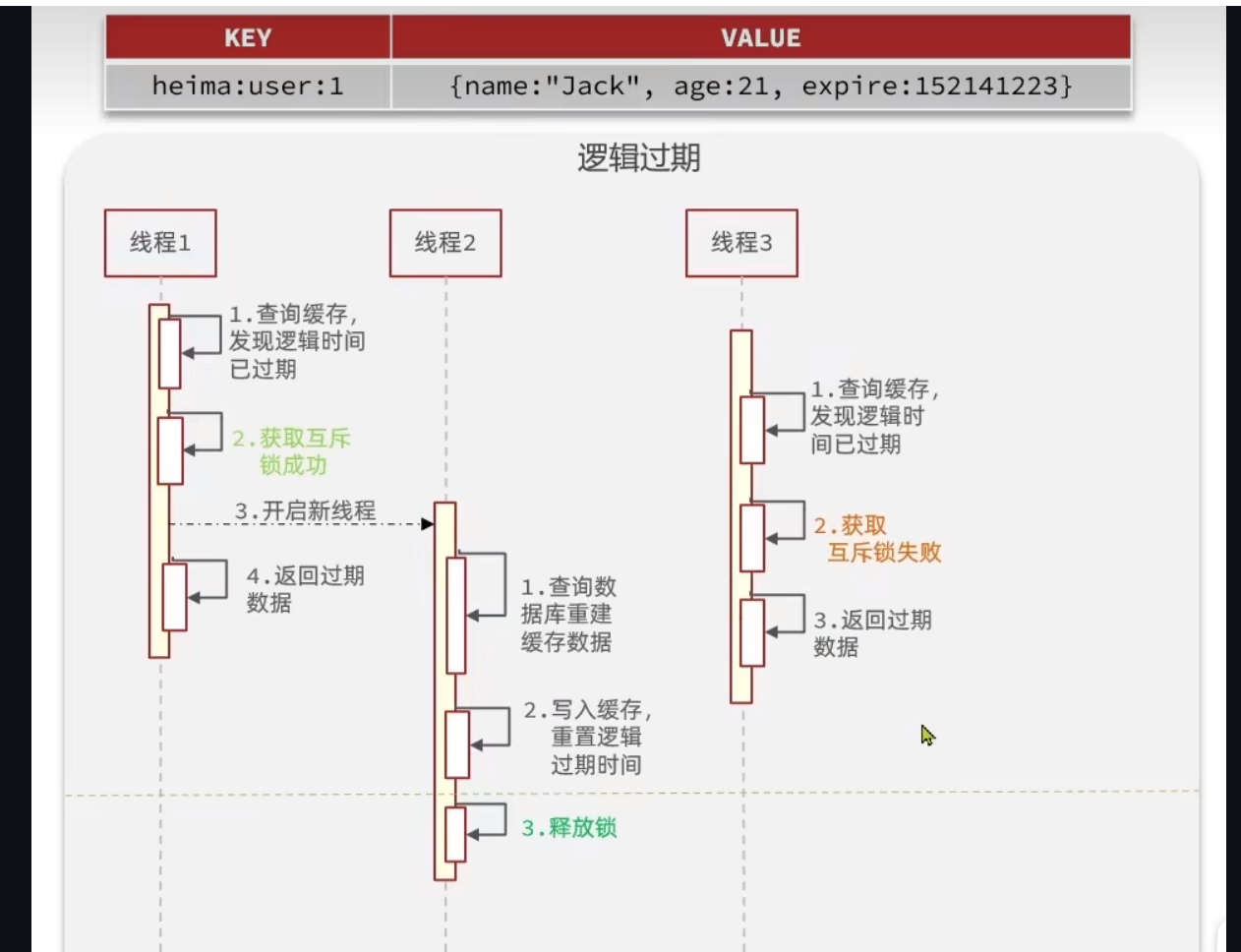
逻辑过期我认为他最大的好处就是,不用等,我们互斥锁的化,就会去等,性能不是特别好,那么这里就不用去等,但是这里就会有一致性问题,当然按理来说,这里的重建key的时间,要是不是很久的化,那么这里的一致性问题也不会那么大
这里就像一个悖论,你要性能好,一致性就会有瑕疵,你要一致性好,性能就没那么好,但是按理来说,以现在的要求来看,我觉得性能应该更追求一点,所以逻辑过期的市场会大一点
比较

互斥锁实战
接下来的实战,就是模拟高并发下的缓存击穿问题,会比较复杂,所以需要仔细看,但是如果你做完了我这个实验,会对缓存击穿的解决会理解很多,毕竟计算机是实操大于理论
我们先来看,如何复现缓存击穿问题,
在这里我得多说一句,我们一定要自己复现这些问题,因为如果你只是学习怎么解决的化,那永远是一知半解,所以我认为只有了解敌人,才能更好的打倒敌人!
问题复现
首先,就是高并发,第二就是缓存的key在高并发的哪一个瞬间失效了
所以我们得着手准备这两个方面
第一,高并发,我门用著名的压测工具,Jmeter来实现,Jmeter的使用,我这里就不多说了,你不愿意学,看着我的操作,也能直接用~
Jmeter
首先创建一个线程组,然后创建一个http请求,并且在这个请求下,打开结果树
创建一个http请求
写好我们要测试的接口
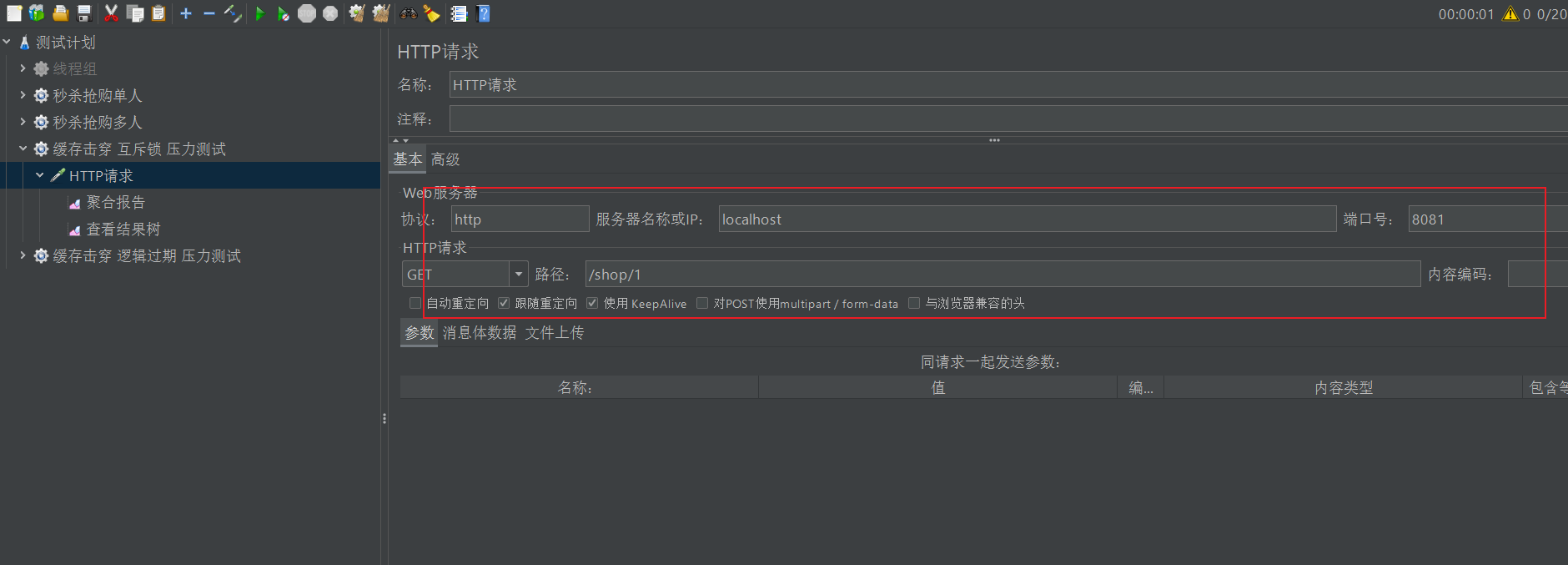
调出结果树
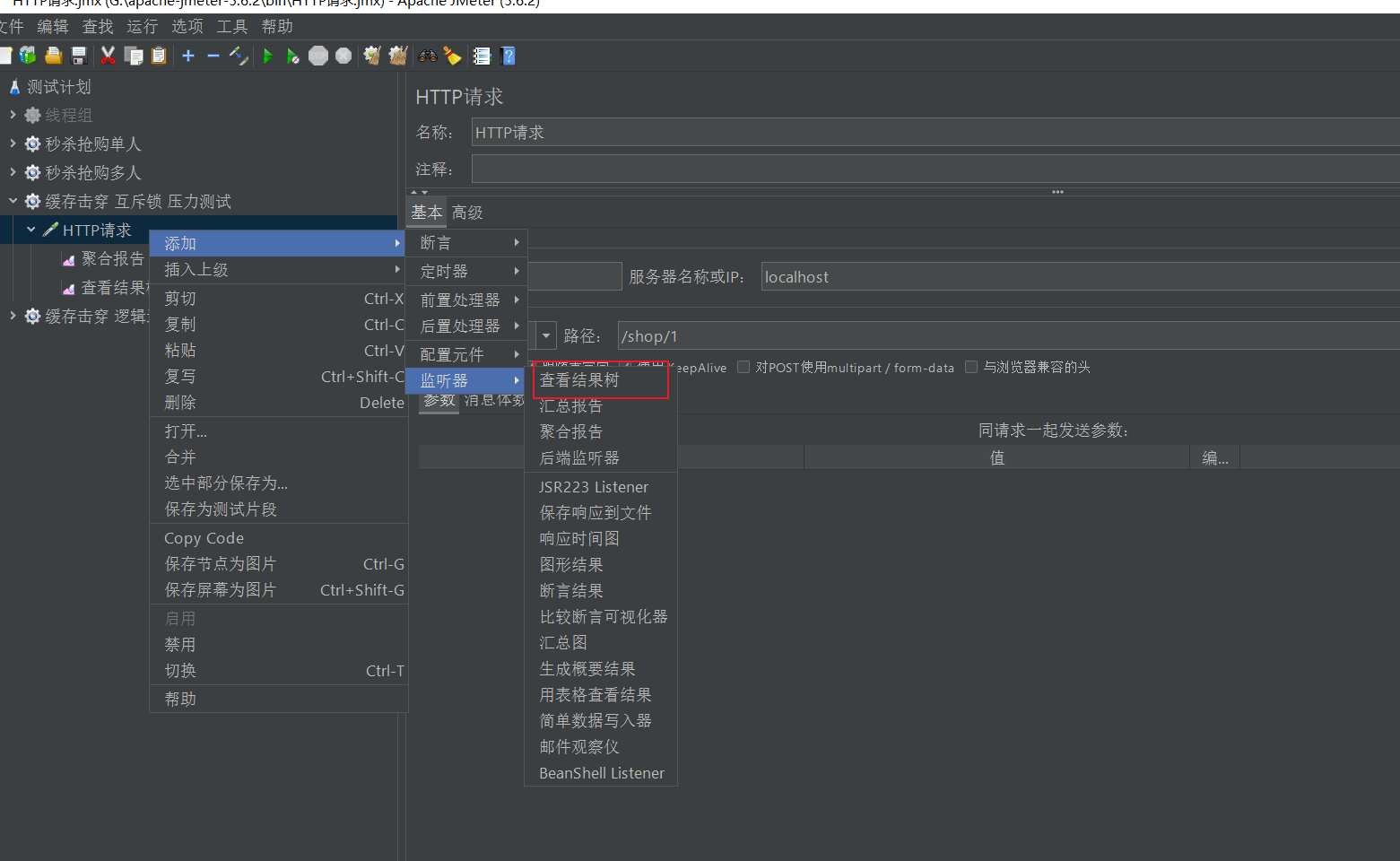
ok,jmeter准备就绪
出问题的代码
我这里的代码不是很复杂,是正常的缓存商户信息
- controller
@RestController
@RequestMapping("/shop")
public class ShopController {
@Resource
public IShopService shopService;
/**
* 根据id查询商铺信息
* @param id 商铺id
* @return 商铺详情数据
*/
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
Shop shop = shopService.queryShopById(id);
if(shop == null) {
return Result.fail("店铺信息不存在!");
}
return Result.ok(shop);
}
}
- 接口抽象类
public interface IShopService extends IService<Shop> {
/**
* 获取商户信息
* @param id
* @return
*/
Shop queryShopById(Long id);
}
实现类
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Autowired
private RedisCache redisCache;
@Autowired
private IShopTypeService shopTypeService;
/**
* 获取商户信息
* @param id
* @return
*/
@Override
public Shop queryShopById(Long id) {
Shop shop = null;
//出问题的代码,这个代码,也是从上面的缓存穿透继承过来的
shop = queryWithPassThrough(id);
return shop;
}
/**
* 解决缓存穿透 --> 缓存空对象
* @param id
* @return
*/
public Shop queryWithPassThrough(Long id) {
//查redis
String shopKey = RedisConstants.CACHE_SHOP_KEY + id;
String shopJSON = redisCache.getCacheObject(shopKey);
//缓存有,直接返回
Shop shop = null;
if(StrUtil.isNotBlank(shopJSON)) {
shop = JSONUtil.toBean(shopJSON,Shop.class);
return shop;
}
//判断是否是我们自己写的""
if(shopJSON != null) {
return null;
}
//不存在
shop = getById(id);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(Objects.isNull(shop)) {
//导入空值,进入缓存
redisCache.setCacheObject(shopKey,"",RedisConstants.CACHE_NULL_TTL.intValue(), TimeUnit.MINUTES);
return null;
}
String json = JSON.toJSONString(shop);
//存入缓存
redisCache.setCacheObject(shopKey,json);
return shop;
}
}
我这里再来简单说一下我这里的出问题的代码的逻辑,好让你理清楚
- 查商户的redis缓存
- 如果有,直接返回,(但是这里为了出问题,我这里把redis缓存清空)
- 如果没有,就进行缓存重建,重建的过程就是查数据库 + 存入redis
总体就是这么个流程
测试
我们有几个要注意的点,
第一,redis应该是没有这个shop的缓存的
第二我们要在心里知道,应该出现什么结果,这里应该出现的结果就是,再高并发的情况下,因为缓存重建化的时间有点久,所以会有很多请求打到数据库,所以我们得着眼观看idea中控制台的消息,如果出现很多sql打到数据库,说明问题出现了
启动!!!
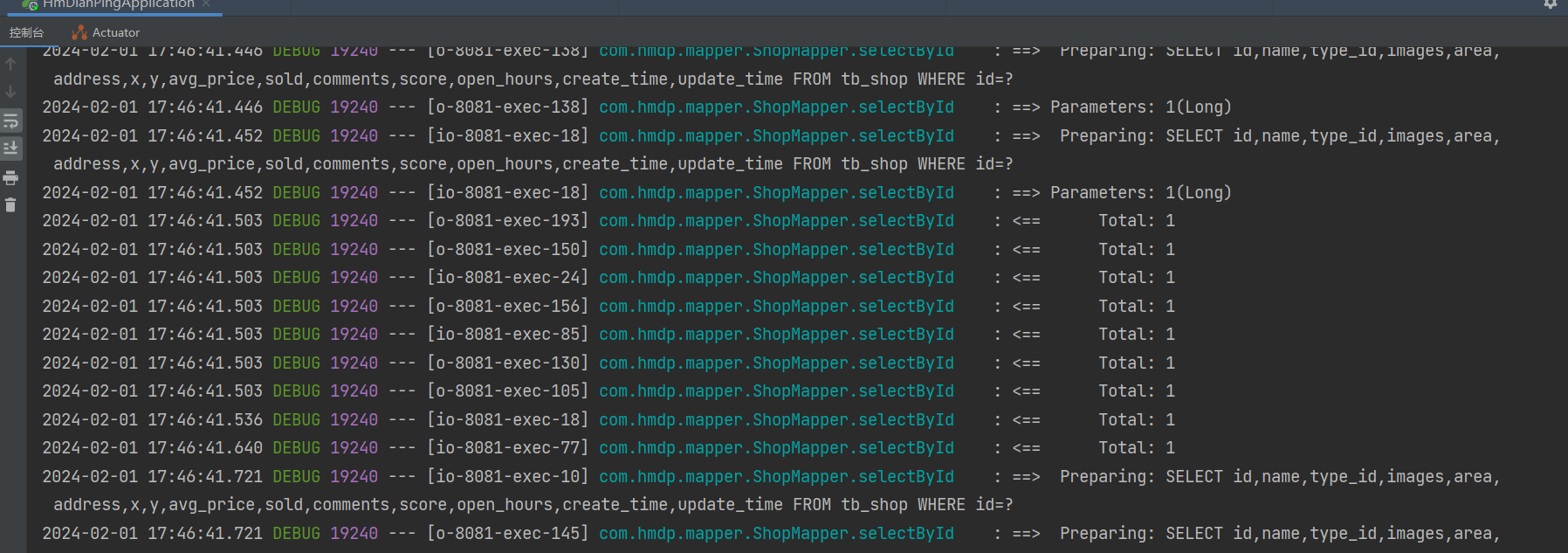
成功,问题出现了,我这里展现不权,实则有很多的请求,所以这就是高并发下,出现的这种缓存击穿问题
解决
为了解决这个问题,我们得考虑如何实现这个互斥锁,那么这个时候,你就会想,这还不简单?,直接再后端代码中,写一个锁的代码不就行了吗?
这就是你考虑的不周到了,如果是两个端的人都在请求这个接口呢?那不还是有问题,所以我们得把这个锁抽离出来,那么redis实现互斥锁,就呼之欲出了!
可能你想问,redis怎么实现互斥锁? 很简单,setnx,setnx这个命令是只有存在这个key的时候,才会set成功,如果不存在,就失败
所以,我们要设置锁,就setnx,如果setnx失败,那么久说明有人占用着锁
那么如何释放锁呢,也是很简答,直接删除这个key value,就相当于释放锁了
但是有一件事情我们必须注意!,那就是这里的锁,一定要设置过期时间,我们这种小测试还好,如果去到很大的体量的系统里边不设置过期时间,有可能会有死锁问题,或者其他异常,这里是给我们自己留一个后路
但是一件事情就是有利有弊,这里我们虽然溜了一个后路,但是由于这里设置了过期时间,后序还可能会出现其他问题,这里的问题也是后话了,我们先不考虑
准备
首先我们先封装获取锁 + 释放锁的代码
我这里把他封装在我的工具类里边了
/**
* 尝试获取锁
* @param pattern key
* @param value 值
* @param timeout 过期时间
* @param timeUnit 时间单位
* @param <T>
* @return
*/
public <T> boolean tryLock(String pattern,T value,Long timeout,TimeUnit timeUnit)
{
Boolean flag = redisTemplate.opsForValue().setIfAbsent(pattern, value, timeout, timeUnit);
return BooleanUtil.isTrue(flag);
}
/**
* 尝试获取锁
* @param pattern key
* @param value 值
* @param <T>
* @return
*/
public <T> boolean tryLock(String pattern,T value)
{
Boolean flag = redisTemplate.opsForValue().setIfAbsent(pattern, value, 2, TimeUnit.MINUTES);
return BooleanUtil.isTrue(flag);
}
/**
* 解锁
* @param pattern
*/
public void unlock(String pattern) {
//删除锁
redisTemplate.delete(pattern);
}
}
你想放在哪都行
这里我特意我设置了两个tryLock,一个是有写过期时间的,一个是默认写过期时间的,你应该也能看懂
改造代码
我们先来看到底该如何改造,这里我们来看一个流程图,看着流程图再去改造自己的代码
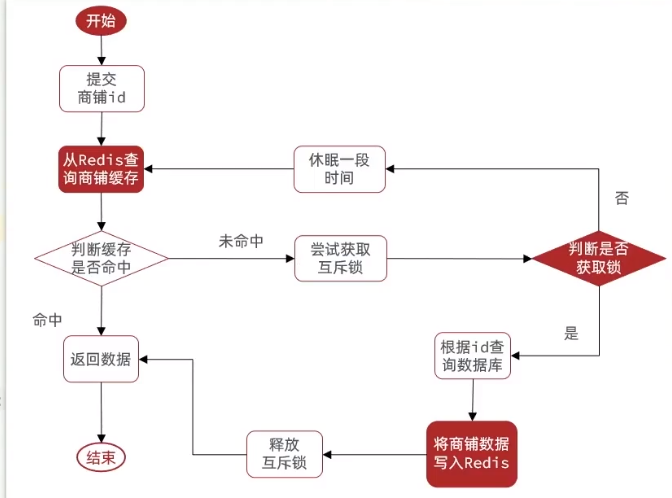
我们写这种比较复杂的业务代码的时候,还是有必要画一个流程图,这样我们的方向会更具体!
核心改造代码
/**
* 解决缓存击穿 --> 互斥锁
* @param id
* @return
*/
public Shop queryWithMutex(Long id) {
//查redis
String shopKey = RedisConstants.CACHE_SHOP_KEY + id;
String shopJSON = redisCache.getCacheObject(shopKey);
//缓存有,直接返回
Shop shop = null;
if(StrUtil.isNotBlank(shopJSON)) {
shop = JSONUtil.toBean(shopJSON,Shop.class);
return shop;
}
//判断是否是我们自己写的""
if(shopJSON != null) {
return null;
}
try {
//尝试第一次获取锁
boolean isLock = redisCache.tryLock(RedisConstants.LOCK_SHOP_KEY, "1");
//没有获取到锁,休眠一段时间
if(!isLock) {
//休眠
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//重试,递归,休眠一段时间,看是否能拿到缓存,还拿不到继续获取锁,看看自己能不能重建
return queryWithMutex(id);
}
//不存在
shop = getById(id);
if(Objects.isNull(shop)) {
//导入空值,进入缓存
redisCache.setCacheObject(shopKey,"",RedisConstants.CACHE_NULL_TTL.intValue(), TimeUnit.MINUTES);
return null;
}
//存入缓存
redisCache.setCacheObject(shopKey,JSON.toJSONString(shop));
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//释放锁
redisCache.unlock(RedisConstants.LOCK_SHOP_KEY);
}
return shop;
}
我这里再来解读一下这里的代码
- 首先是读缓存,如果有,直接返回缓存(但是这里我们为了测试,是把缓存删了的)
- 如果没有缓存,接下来,第一次获取锁
- 获取锁成功,便开始重建缓存,这里是正常的业务代码
- 获取锁失败,便睡几秒,然后递归调用这里的queryMutex(id)
我认为这里的递归调用自己还算是巧妙,我本来的想法是再去获取锁,写一个循环,这样完全是错误的
因为获取锁之后,还是去重建缓存,这里应该是去再去查缓存是否有,这样才对,所以我犯了这个错误的原因就是太像当然,应该想清楚自己应该干的事!
测试
这里是最终的测试
首先,redis得清空,不能有缓存
然后就是操作jmeter
这里的操作jmeter和我再问题复现的那里写的是一样的,所以我这里就不赘述了
/**
* 获取商户信息
* @param id
* @return
*/
@Override
public Shop queryShopById(Long id) {
Shop shop = null;
//缓存穿透
shop = queryWithMutex(id);
return shop;
}
调用我们新写的代码
redis也是空的

idea的控制台清空
启动!!!
结果
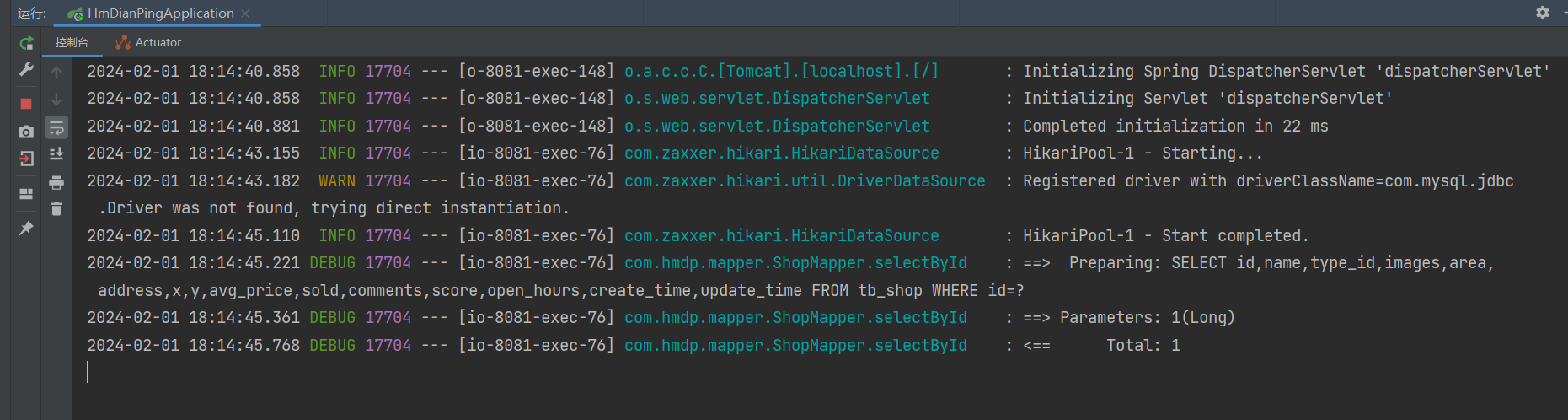
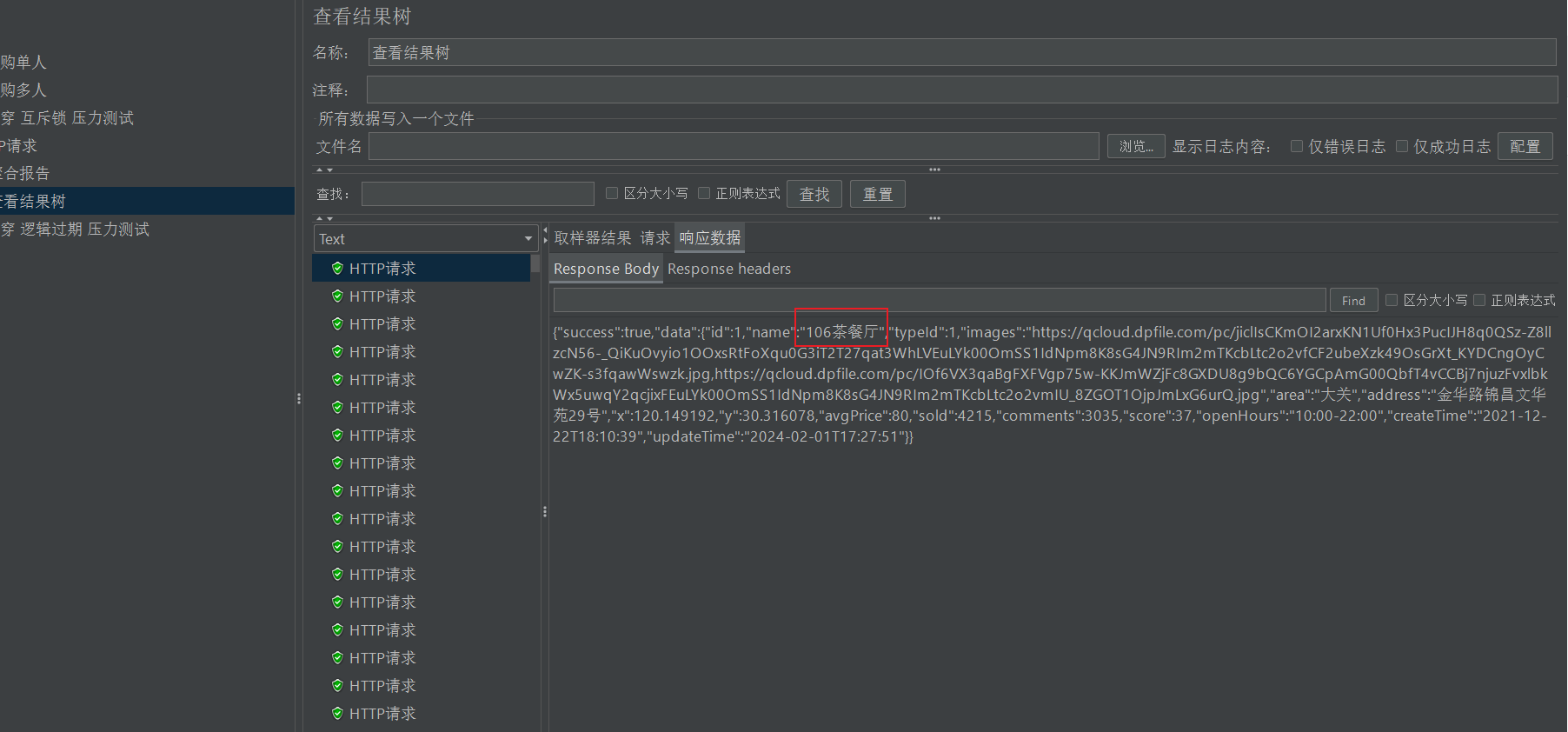
这里只出了一个sql,完美
结果树里边的结果也是对的
总结
总体,我们就从问题复现 + 问题实现了
那我们就来谈谈这里的互斥锁,当然了互斥锁,是能解决问题的,但是性能其实还是有点影响的,但是一致性倒是保证了,接下来我们的另外一个解决办法,逻辑过期,就是牺牲了一致性,换来了性能!
逻辑过期实战
这里的实战也是比较复杂,希望你能认真阅读下去,并实现
问题复现
我们这里的问题复现,就不再赘述了,我写在了互斥锁实战中的问题复现中了,希望你能自己复现出来了!
解决
为了解决这里的问题,既然我们要写逻辑过期的代码,就得考虑如何做逻辑过期
这里有个地方需要注意,我们不能直接在实体类上写新的字段,这样写的代码有侵入性,不太优雅,我们得自己写一个类来实现这里的逻辑过期字段,就是如下
@Data
@Builder
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
这里就一目了然了,我们要把data封装进来就行了
在真正写代码之前,我们还是来捋一下流程,做到心中有数
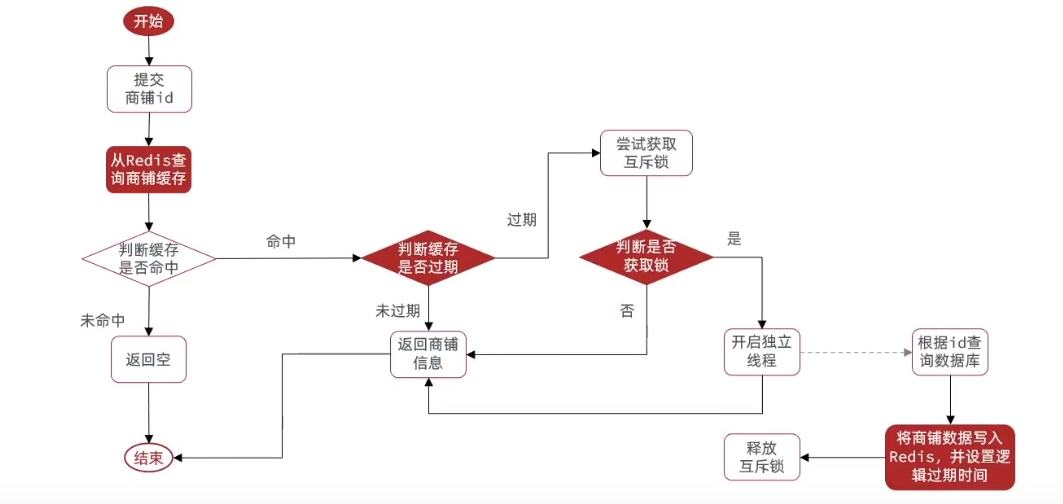
我们来看这里的流程
- redis查缓存**(这里我们为了测试,就有缓存,并且是已经逻辑过期的缓存)**
- 判断缓存是否命中,没有命中,就返回空
- 缓存命中,就判断缓存是否过期
- 如果未过期,返回信息
- 如果已经过期,获取锁
- 获取锁失败,就返回信息(这里还是旧的信息)
- 获取锁成功,开一个独立的线程,去处理逻辑过期,还是返回旧的信息
- 最后结束
所以我们整体的流程看下来,我们可以总结一个逻辑,
只有缓存命中了,并且逻辑过期了,而且获取锁成功了,才要去开一个独立的线程处理这里的逻辑过期的事务
你好好斟酌我这里的逻辑,其他的情况都是返回旧的数据,所以说,为什么逻辑过期会有一致性问题,关键就在此处!,这就是奥妙!
准备
除了要封装逻辑过期类之外,我们还要先设置一个缓存数据到redis中,这里存redis代码如下
public void saveShop2Redis(Long id,Long expireTime) {
Shop shop = getById(id);
RedisData data = RedisData.builder()
.data(shop)
.expireTime(LocalDateTime.now().plusSeconds(expireTime))
.build();
redisCache.setCacheObject(RedisConstants.CACHE_SHOP_KEY + id,JSON.toJSONString(data));
}
我们在测试类中,先装载一个缓存先,以便后面测试用
@SpringBootTest
class HmDianPingApplicationTests {
@Resource
private ShopServiceImpl shopService;
@Test
public void test() {
shopService.saveShop2Redis( 1L,30L);
}
}
核心代码
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
/**
* 解决缓存击穿 --> 逻辑过期
* @param id
* @return
*/
public Shop queryWithLogicExpire(Long id) {
//查redis
String shopKey = RedisConstants.CACHE_SHOP_KEY + id;
String shopJSON = redisCache.getCacheObject(shopKey);
//缓存没有,返回空,因为是热点数据
Shop shop = null;
//这里的未命中,包括了null和空串
if(StrUtil.isBlank(shopJSON)) {
return null;
}
//先查缓存是否逻辑过期
RedisData redisData = JSONUtil.toBean(shopJSON, RedisData.class);
shop = JSONUtil.toBean((JSONObject) redisData.getData(),Shop.class);
//如果过期了,就去获取锁
if(LocalDateTime.now().isAfter(redisData.getExpireTime())) {
boolean isLock = redisCache.tryLock(RedisConstants.LOCK_SHOP_KEY, "1");
//如果获取成功了,就去开启一个独立的线程
if(isLock) {
//开启一个独立线程,去解决问题
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
this.saveShop2Redis(id,30L);
} catch (Exception e) {
throw new RuntimeException();
} finally {
//释放锁
redisCache.unlock(RedisConstants.LOCK_SHOP_KEY);
}
});
}
}
//最后都是返回旧数据,牺牲一致性
return shop;
}
public void saveShop2Redis(Long id,Long expireTime) {
Shop shop = getById(id);
RedisData data = RedisData.builder()
.data(shop)
.expireTime(LocalDateTime.now().plusSeconds(expireTime))
.build();
redisCache.setCacheObject(RedisConstants.CACHE_SHOP_KEY + id,JSON.toJSONString(data));
}
我这里也来说明一下这里的代码,按照我上面分析的逻辑,只有说缓存命中 + 缓存过期 + 获取锁成功 才要去开启一个线程解决问题,在代码上也是体现了,就是这里的处理的逻辑我还得说一下
这里就是重新更新这里的key的逻辑过期时间
测试
这里的测试,有几个需要注意,我们得知道会出现的结果
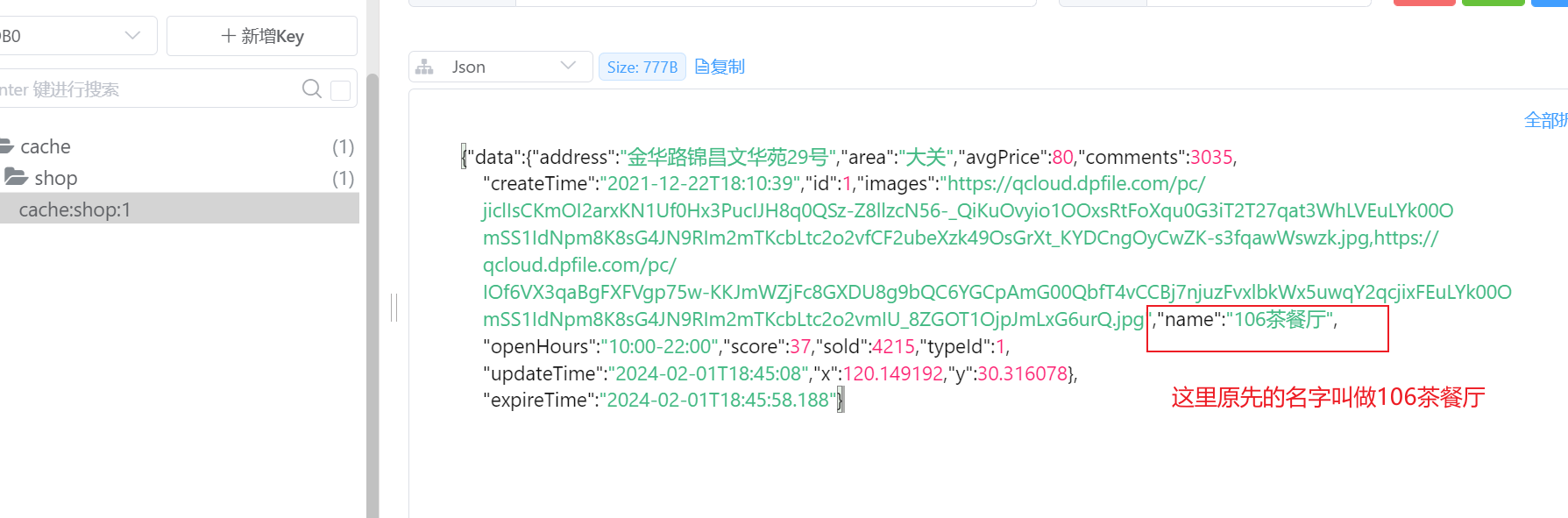
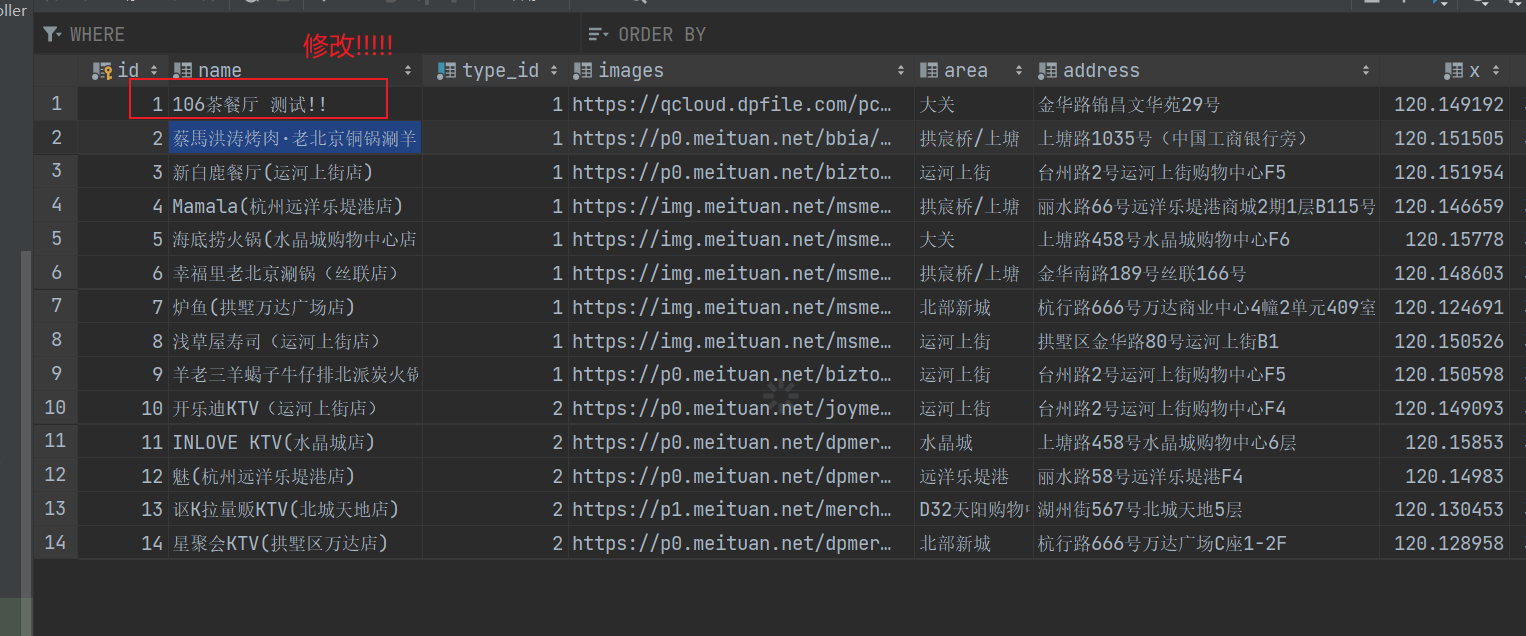
首先,我们得知道,这里一定会有一致性问题的,所以我们得注意一致性问题,为了特别看到这里的一致性问题,我们得在测试前,更改数据库中的信息,以产生区别
其次,redis中的数据必须先装载上去,并且是已经逻辑过期的,你自己想想也知道,如果不是的化,那么就没有测试的必要了
redis中的数据
我们得修改数据库中的数据
jmeter的修改,为了看效果,就不要那么多线程数改成200
idea控制台清空
启动!!!
结果
先看,idea控制台
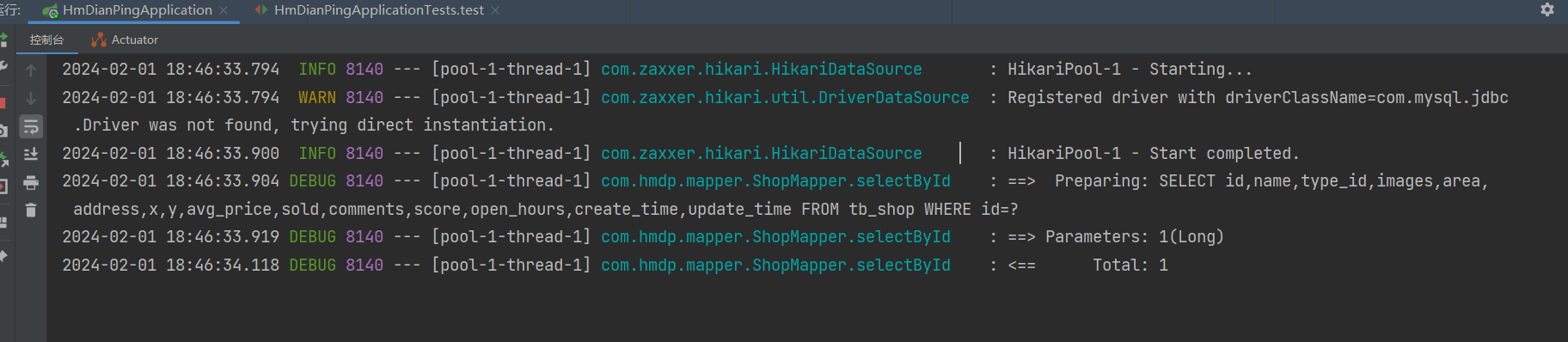
只有一个sql,完美
在查看这里的jmeter,看他的结果树
有些事旧的数据
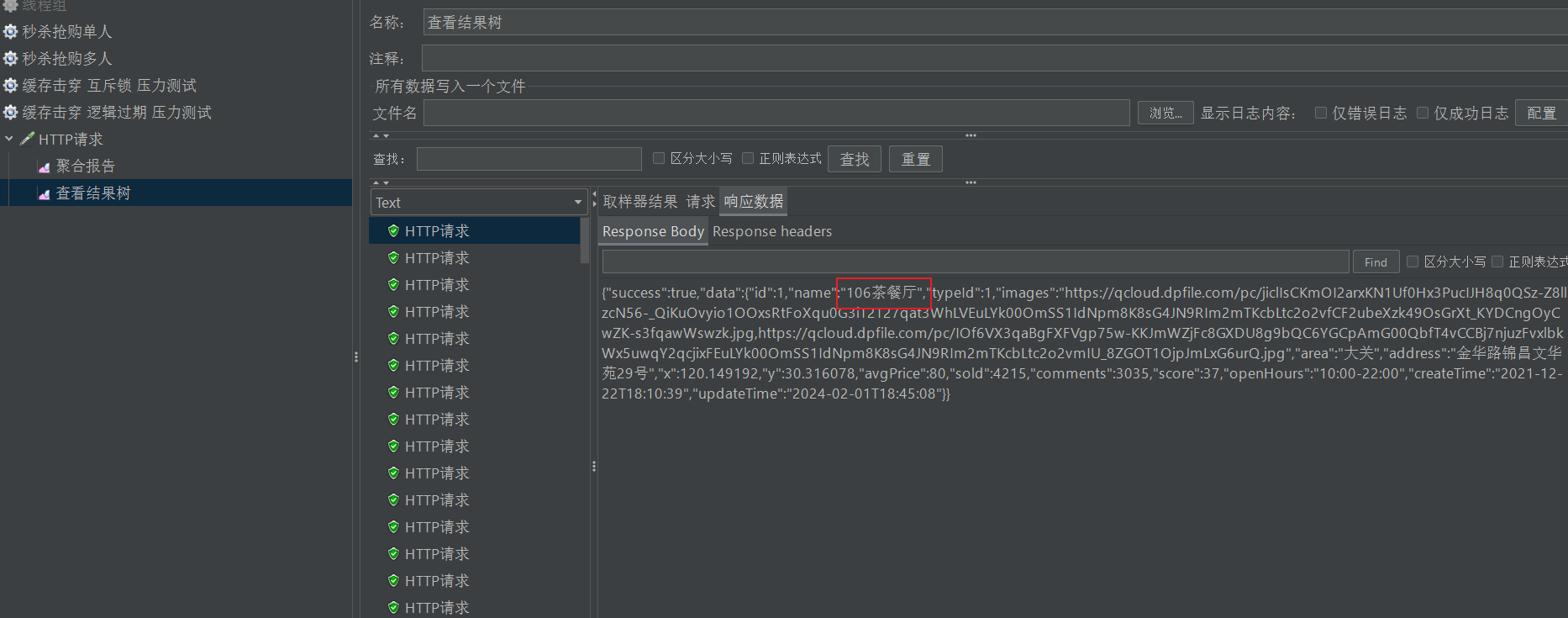
后面已经都是新的数据
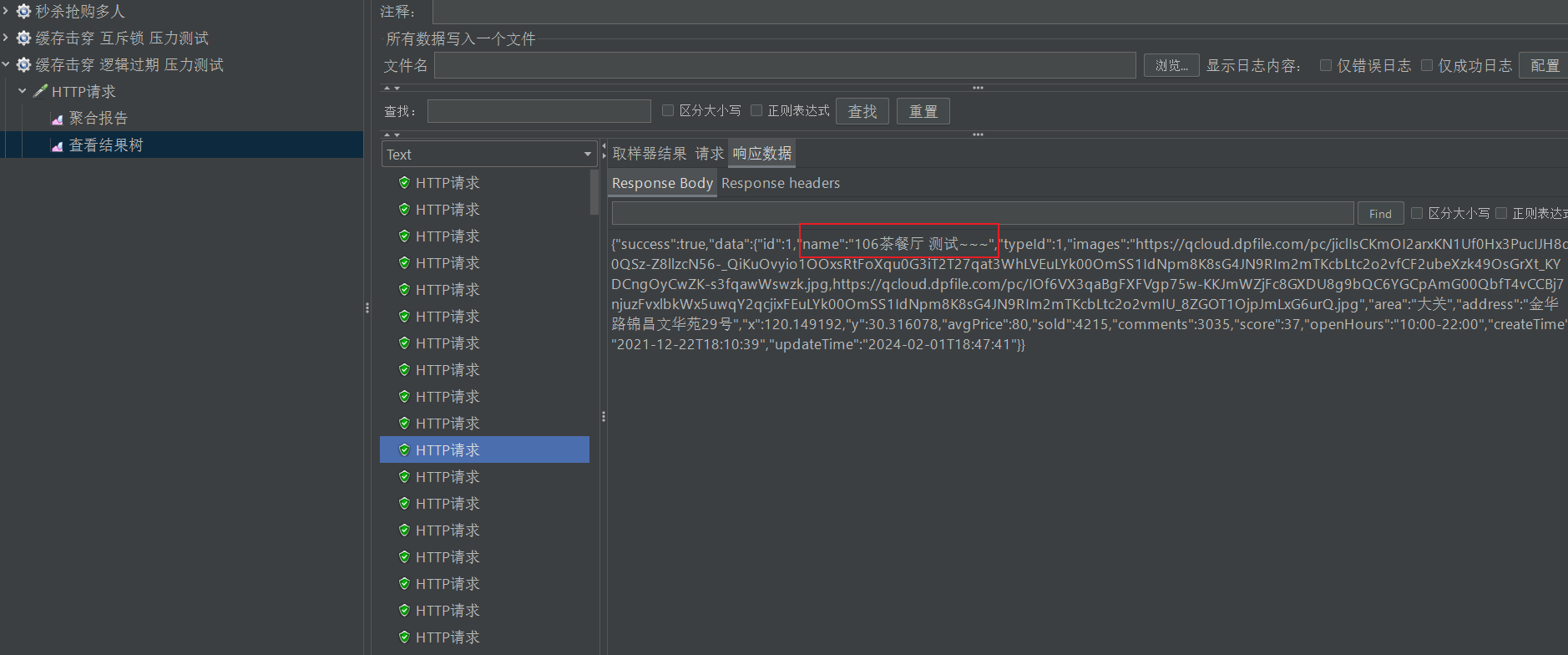
查看redis
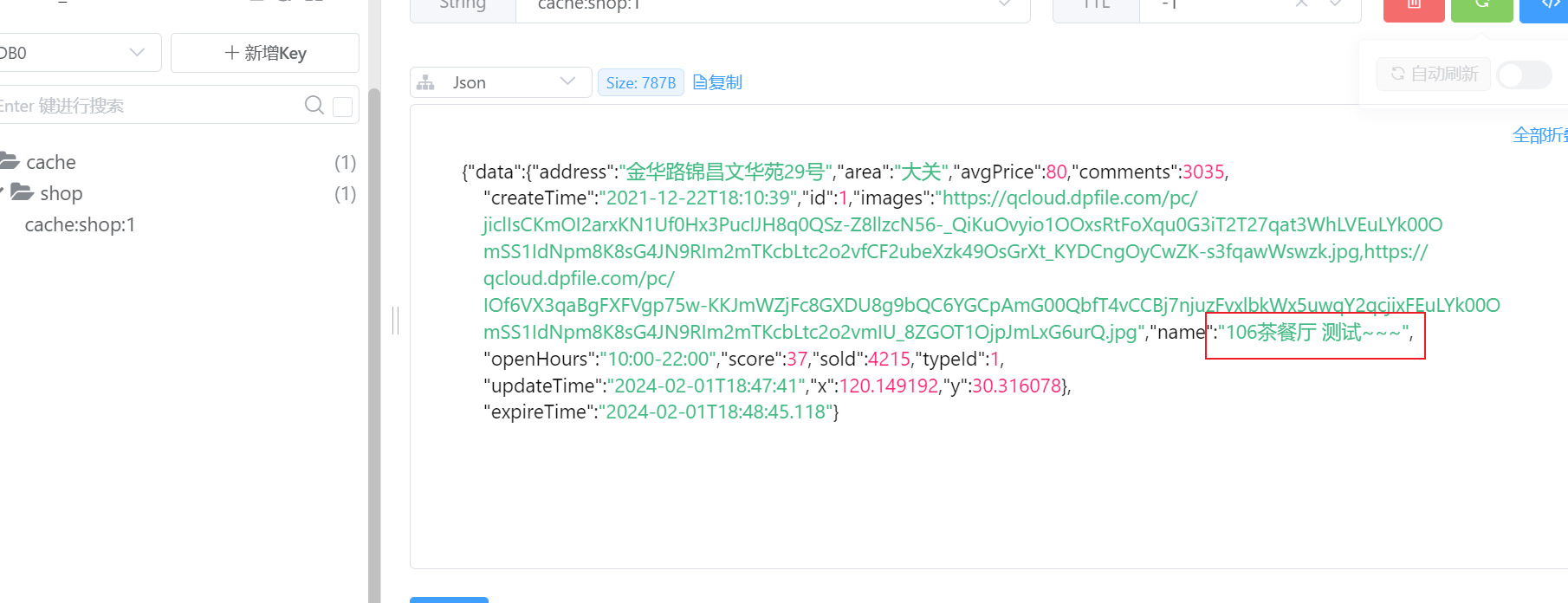
这里也是正确的,所以没有问题!!!
总结
那么整体就ok了,这个逻辑过期也是牺牲了一致性的!