一、awk的介绍:
1.awk的简介:
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具
可以在无交互的模式下实现复杂的文本操作
相较于sed常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理,因为awk相当适合小型的文本数据。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符
2.基本格式:
awk [选项] ‘模式条件{操作}’ 文件1 文件2...
awk -f | -v 脚本文件 文件1 文件.....
3.工作原理:
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中, 并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个"字段"然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符"&&“表示"与”、"“表示"或”、"!“表示"非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
4.awk常见的内置变量:
- FS∶ 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同
- NF∶ 当前处理的行的字段个数。
- NR∶ 当前处理的行的行号(序数)。
- $0∶当前处理的行的整行内容。
- $n∶ 当前处理行的第n个字段(第n列)。
- FILENAME∶ 被处理的文件名。
- RS∶ 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’
- $NF:最后一段
- $(NF-1):倒数第二段
二.打印方法:
-
awk可以将自动将多个空格压缩成一个空格
-
打印字符串需要加双引号
1.基础打印:
打印其中一列:

打印字符串:

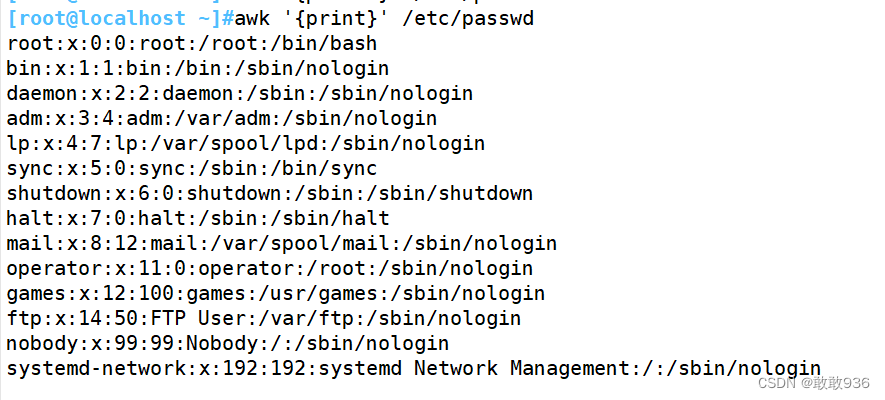
2.打印全部:
[root@localhost ~]#awk '{print}' /etc/passwd
print在不加任何变量和选项的情况下,默认输出所有
注意:
0 和 1 放置 {} 前,能够起到限制答应的作用(默认为“1”)
0是不允许打印读入的内容,1是允许打印的内容

$0代表整行内容,awk是逐行读取处理,配合$0的效果就是打印文本所有内容

3.打印行内容及其行号:
[root@localhost ~]#awk '{print NR}' /etc/passwd

4.打印指定行内容:
[root@localhost ~]#awk 'NR==3{print}' /etc/passwd
[root@localhost ~]#awk 'NR==3,NR==5{print}' /etc/passwd
[root@localhost ~]#awk 'NR>=3&&NR<=5{print}' /etc/passwd

5.奇偶行打印:
5.1打印奇偶数行:
[root@localhost ~]#awk 'NR%2==0{print}' /etc/passwd
#打印偶数行
[root@localhost ~]#awk 'NR%2==1{print}' /etc/passwd
#打印奇数行

5.2奇偶行打印特殊方式--getline:
getline工作过程:
(1)当getline左右无重定向符号(“<”)或者管道符号(“|”)时,awk首先读取的是第一行,而getline获取的是是光标跳转至下一行的内容(也就是第二行)
原因:getline运行之后awk会改变NF,NR,$0,FNR等内部变量,所以此时读取$0的行号不再为1,而是2。
注意:
FNR:awk当前读取的记录数,其变量值小于等于NR,(比如说当读取完第一个文件后,读取第二个文件,FNR是会从0开始进行,而NR不会)。因此读取两个或两个以上的文件,NR==FNR,可以 判断是不是在读取第一个文件。
(2)当getline左右有管道符号或重定向符时,getline则作用定向输入文件,由于文件是刚打开,并没有被awk读入一行,而只是getline读入,所以getline返回的是文件的第一行,而不是跳转至一行输入
打印偶数行:
[root@localhost etc]#seq 10 |awk '{getline;print $0}'
先进行getline跳转至下一行,awk读取跳转后的整行内容,经过逐步跳转读取,形成了只显示偶数行

打印奇数行:
先进行awk打印第一行的内容,结束后按照正常顺序打印,但是getline进行跳转,第二行不打印了,最终呈现出奇数行打印

6.条件判断打印:
正向判断打印:
[root@localhost ~]#awk -F: '$3>=1000{print $3,$1}' /etc/passwd
#先用 -F指定分隔符为":" ,文件以":"分割的第三列为uid,uid大于1000的打印第三列和第一列,也就是uid和用户
判断取反打印:
[root@localhost ~]#awk -F: '!($3<=1000){print $3,$1}' /etc/passwd

还可以直接进行 if 语句判断打印:

7.提取:
7.1根据$n以及NR提取字段
$n,代表提取第几列
提取ip地址:
ifconfig ens33|sed -n '2p'|awk '{print $2}'
ifconfig ens33 |awk 'NR==2{print $2}'
提取ipv6地址:
ifconfig ens33|sed -n '3p'|awk '{print $2}'
ifconfig ens33 |awk 'NR==3{print $2}'
7.2 根据选项-F指定分隔符:
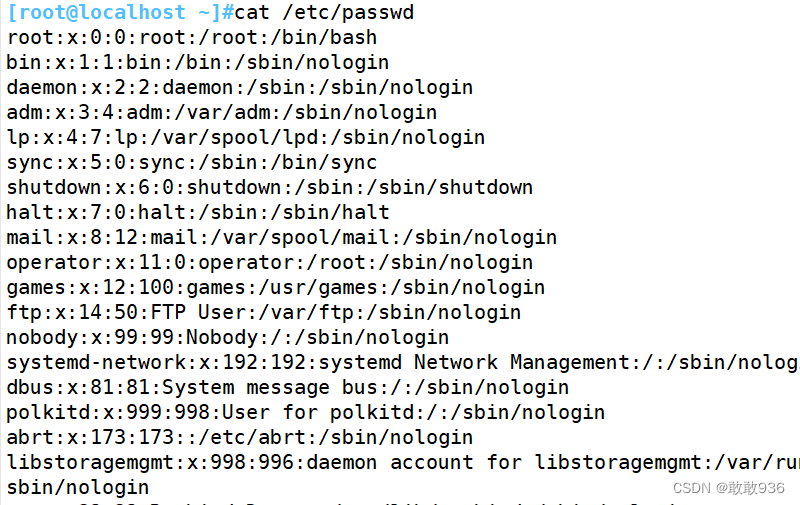
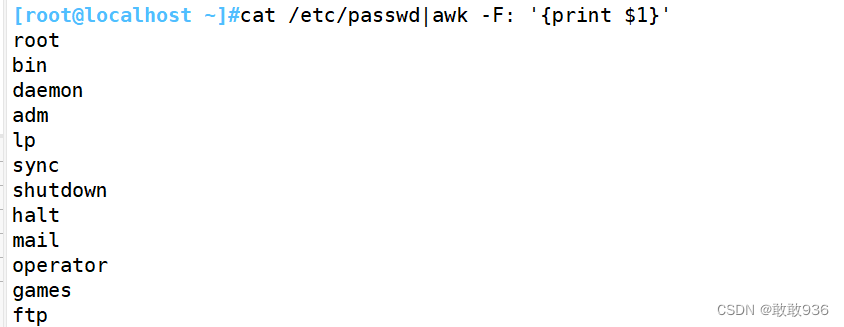
打印/etc/passwd所有用户名:
cat /etc/passwd|awk -F":" '{print $1}'
或
cat /etc/passwd|awk -F: '{print $1}'以冒号为分隔符,提取第一位即可

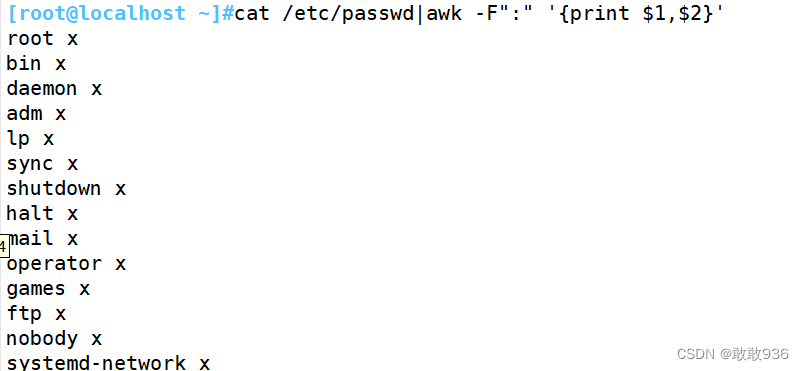
7.3提取多列内容:
打印时逗号可以表示空格,如果使用“:”或者“+”,需要将特殊符号加上双引号当成字符串打印
cat /etc/passwd|awk -F":" '{print $1,$2}'
cat /etc/passwd|awk -F":" '{print $1":"$2}'
cat /etc/passwd|awk -F":" '{print $1"+"$2}'以空格符分隔,逗号就是分隔符
7.4提取磁盘已经使用情况,并去除%:
#使用两条awk命令
df|awk '{print $5}'|awk -F% '{print $1}'
#使用一次awk命令
df|awk -F"[ %]+" '{print $5}'
##也可以使用( |%)代表或者
df|awk -F"( |%)+" '{print $5}'第一次以空格为分隔符提取,第二次用-F%分隔提取

7.5匹配以root开头的行:

7.6匹配以bash结尾的行:

7.7提取df里面数字:

三、awk的三元表达式:
1. java和shell中的三元表达式:
java中:
(条件表达式)?(A表达式或者值):(B表达式或者值)
解释:
条件表达式成立(为真)时,会取冒号前面的值A。 - 条件表达式不成立(为假)时,会取冒号后面的值B。
shell中:
[ 条件表达式 ] && A || B
解释:
条件表达式成立(为真)时,会取||前面的值A。 - 条件表达式不成立(为假)时,会取||后面的值B。
2.awk三元表达式的应用:
格式:awk '(条件表达式)?(A表达式或者值):(B表达式或者值)'
[root@localhost ~]#awk -F: '{max=($3>=$4)?$3:$4;{print max,$0}}' /etc/passwd |sed -n '1,6p'
#比较passwd文件中第三列和第四列的大小
去他们结果较大的值,赋于变量max 并且输出max及其所在行的全部内容
四、awk精准筛选:
筛选方法:
| $n (><==) | 用于对比数值 |
| $n~"字符串" | 代表第n个字段,包含某个字符串的作用 |
| $n!~"字符串" | 代表第n个字段,不好含某个字符串的作用 |
| $n=="字符串" | 代表第n个字段为某个字符串的作用 |
| $n!="字符串" | 代表第n个字段不为某个字符串的作用 |
| $NF | 代表最后一个字段 |
案例:
输出第七个字段包含“bash”所在行的第一个字段和最后一个字段

输出第七个字段不包含“nologin”所在行的第一个字段和最后一个字段

五、内置变量的使用:
- FS∶ 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同
- NF∶ 当前处理的行的字段个数。
- NR∶ 当前处理的行的行号(序数)。
- $0∶当前处理的行的整行内容。
- $n∶ 当前处理行的第n个字段(第n列)。
- FILENAME∶ 被处理的文件名。
- RS∶ 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’
- $NF:最后一段
- $(NF-1):倒数第二段
1.NF-当前处理的行的字段个数:
1.1显示每行有几个字段:

1.2打印出每行最后一个字段:
 1.3 打印出每行倒数第二个字段:
1.3 打印出每行倒数第二个字段:

2.NR:当前处理行的行号:
2.1当前处理行的行号:
#NR写在后面则在后面显示行号
#awk -F: '{print $1,NR}' /etc/passwd
root 1
bin 2
daemon 3
adm 4
lp 5
sync 6
shutdown 7
halt 8

#可以用制表符
awk -F: '{print $1"\t"NR}' /etc/passwd
root 1
bin 2
daemon 3
adm 4
lp 5

#NR写在前面则在前面显示行号
awk -F: '{print NR"\t"$1}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp

2.2 NR==n代表行号等于什么
代表取第二行第一个字段

2.3 NR%2==0取偶数行

2.4 NR%2==1取奇数行:

2.5 NR==1,NR==4取区间行:

2.6 取UID数值范围$n>1000:
#取uid大于1000的行
awk -F: '$3>1000 {print}' /etc/passwd
#取uid大于等于1000的行
awk -F: '$3>=1000 {print}' /etc/passwd
六、awk的分隔符:
1.RS 指定分隔符:
awk 从文件中读取资料时,将根据 RS 的定义把资料切割成许多条记录, 而 awk 一次仅读入一条记录进行处理。内置变量 RS 的预设值是"\n"。
但是也可以在使用 BEGIN 模式在操作前进行行分隔符的改变。
通过begin模式先在awk命令执行前将分隔符改为 : ,在打印其行号和每一行内容

2.指定输出的分隔符:
2.1 FS 输入时的列分隔符:

3.awk结合数组运用:
3.1 awk中定义数组打印:
awk 'BEGIN{a[0]=10;a[1]=20;a[2]=30;print a[0]}'变量i读取数组a的下标,可以形成遍历:

3.2 去重打印数组:
[root@localhost ~]#x=(10 10 10 20 30 20 30 20 40 10 30 10)
[root@localhost ~]#echo ${x[@]}|awk -v RS=' ' '!a[$1]++'
10
20
30
40七、关系表达式:
关系表达式结果为“真”才会被处理
真:结果为非0值,非空字符串
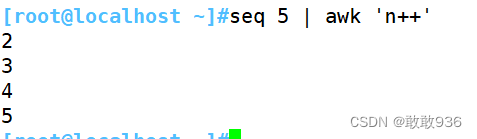
假:结果为空字符串或0值

n=0 第一行为假,不打印
取反:

关系表达式打印奇偶数行:
seq 5 |awk 'i=!i' 奇数行
#第1行 i=0 假=!假 真 打印
#第2行 i=1 真=!真 假 不打印
....
seq 5 |awk -v i=1 'i=!i' 偶数行
seq 5 |awk '!(i=!i)' 偶数行
八、awk脚本:
用awk编写脚本:

九、试题练习:
1. 统计/etc/fstab文件中每个文件系统类型出现的次数:
cat /etc/fstab |awk '/^[^#]/{print}'|awk '{print $3}'|sort |uniq -c 
2.统计/etc/fstab文件中每个单词出现的次数:
grep -Eo "\b[[:alpha:]]+\b" /etc/fstab |sort|uniq -c|sort

3.提取主机名:


提取后再放入文件中:

4.提取任意字符串中的数字:
echo "Yd$C@M05MB%9&Bdh7dq+YVixp3vpw"|grep -E -o "[0-9]+"