文章目录
- 算法介绍
- 实验分析
算法介绍
K最近邻(K-Nearest Neighbors,KNN)是一种常用的监督学习算法,用于分类和回归任务。该算法基于一个简单的思想:如果一个样本在特征空间中的 k k k个最近邻居中的大多数属于某个类别,那么该样本很可能属于这个类别。KNN算法不涉及模型的训练阶段,而是在预测时进行计算。
以下是KNN算法的基本步骤:
-
选择K值: 首先,确定用于决策的邻居数量K。K的选择会影响算法的性能,通常通过交叉验证等方法来确定最优的K值。
-
计算距离: 对于给定的测试样本,计算其与训练集中所有样本的距离。常用的距离度量包括欧几里得距离、曼哈顿距离、闵可夫斯基距离等。
-
找到最近的K个邻居: 根据计算得到的距离,找到距离最近的K个训练样本。
-
投票或取平均: 对于分类任务,采用多数表决的方式,即选择K个邻居中最常见的类别作为测试样本的预测类别。对于回归任务,可以取K个邻居的平均值作为预测结果。
KNN算法的优点包括简单易理解,对于小规模数据集表现良好,而且适用于多类别问题。然而,它的缺点包括计算开销较大(特别是对于大规模数据集)、对数据分布敏感,以及对特征范围差异较为敏感。
下面我们来验证 k k k近邻算法的正确性:
给定测试样本
x
x
x,若其最近邻样本为
z
z
z,则最近邻分类器出错的概率为:
P
(
e
r
r
)
=
1
−
∑
c
∈
Y
P
(
c
∣
x
)
P
(
c
∣
z
)
(1)
P(err)=1-\sum_{c\in \mathcal{Y}}P(c\mid x)P(c\mid z) \tag{1}
P(err)=1−c∈Y∑P(c∣x)P(c∣z)(1)
我们假设样本是独立同分布的,且均匀的,对于任意的测试样本在附近总能找到式(1)中的训练样本
z
z
z。令
c
⋆
=
arg max
c
∈
Y
P
(
c
∣
x
)
c^\star=\text{arg max}_{c\in \mathcal{Y}}P(c\mid x)
c⋆=arg maxc∈YP(c∣x)表示贝叶斯最优分类器的结果,有:
P
(
e
r
r
)
=
1
−
∑
c
∈
Y
P
(
c
∣
x
)
P
(
c
∣
z
)
≃
1
−
∑
c
∈
Y
P
2
(
c
∣
x
)
=
1
−
P
2
(
c
1
∣
x
)
−
P
2
(
c
2
∣
x
)
−
.
.
.
−
P
2
(
c
⋆
∣
x
)
−
.
.
.
−
P
2
(
c
k
∣
x
)
=
1
−
∑
c
∈
Y
,
c
≠
c
⋆
P
2
(
c
∣
x
)
−
P
2
(
c
⋆
∣
x
)
≤
1
−
P
2
(
c
⋆
∣
x
)
≤
2
×
(
1
−
P
(
c
⋆
∣
x
)
)
(2)
\begin{aligned} P(err)&=1-\sum_{c\in \mathcal{Y}}P(c\mid x)P(c\mid z)\\ &\simeq1-\sum_{c\in \mathcal{Y}}P^2(c\mid x)\\ &=1-P^2(c_1\mid x)-P^2(c_2\mid x)-...-P^2(c^\star\mid x)-...-P^2(c_k\mid x) \\ &=1-\sum_{c\in \mathcal{Y},c\ne c^\star}P^2(c\mid x)-P^2(c^\star\mid x)\\ &\leq 1-P^2(c^\star\mid x)\\ &\leq 2\times (1-P(c^\star\mid x)) \end{aligned} \tag{2}
P(err)=1−c∈Y∑P(c∣x)P(c∣z)≃1−c∈Y∑P2(c∣x)=1−P2(c1∣x)−P2(c2∣x)−...−P2(c⋆∣x)−...−P2(ck∣x)=1−c∈Y,c=c⋆∑P2(c∣x)−P2(c⋆∣x)≤1−P2(c⋆∣x)≤2×(1−P(c⋆∣x))(2)
这里, c ⋆ c^\star c⋆ 是我们关心的类别,而 Y \mathcal{Y} Y 是所有可能的类别的集合。在这一步,我们只考虑了 c ⋆ c^\star c⋆ 这一类别的分类情况,因为我们关注的是样本被错误分类的概率。这样,我们就得到了第五行的推导。
在最后一步,我们使用了不等式
1
−
a
b
≤
(
1
−
a
)
+
(
1
−
b
)
1-ab \leq (1-a)+(1-b)
1−ab≤(1−a)+(1−b),其中
a
=
P
(
c
⋆
∣
x
)
a = P(c^\star\mid x)
a=P(c⋆∣x),
b
=
P
(
c
⋆
∣
x
)
b = P(c^\star\mid x)
b=P(c⋆∣x)。这样我们就得到了最终的推导:
P
(
e
r
r
)
≤
2
×
(
1
−
P
(
c
⋆
∣
x
)
)
P(err)\leq2\times (1-P(c^\star\mid x))
P(err)≤2×(1−P(c⋆∣x))
故 k k k近邻分类器泛化错误率不超过贝叶斯最优分类器的错误率的两倍。
实验分析
数据集如下所示:
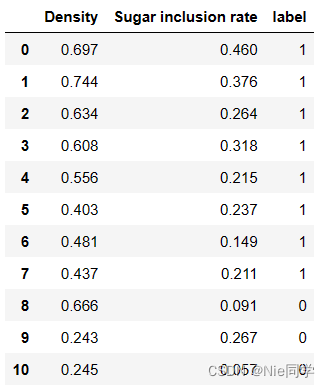
读入数据集:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('data/4.0a.csv')
定义欧式距离:
# 定义欧氏距离计算函数
def euclidean_distance(point1, point2):
return np.sqrt(np.sum((point1 - point2) ** 2))
定义KNN算法:
# 定义KNN算法函数
def knn_predict(train_data, test_point, k):
distances = []
# 计算测试点与每个训练点的距离
for index, row in train_data.iterrows():
train_point = row[['Density', 'Sugar inclusion rate']].values
label = row['label']
distance = euclidean_distance(test_point, train_point)
distances.append((distance, label))
# 根据距离排序,选择前k个最近的点
distances.sort()
neighbors = distances[:k]
# 统计最近点的标签
label_counts = {0: 0, 1: 0}
for _, label in neighbors:
label_counts[label] += 1
# 返回预测的标签
return max(label_counts, key=label_counts.get)
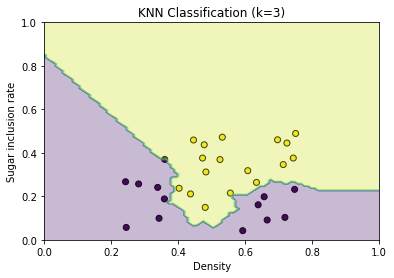
执行KNN算法并绘制结果:
# 设定k值
k_value = 3
# 生成密集的点用于绘制决策边界
x_values, y_values = np.meshgrid(np.linspace(0, 1, 100), np.linspace(0, 1, 100))
grid_points = np.c_[x_values.ravel(), y_values.ravel()]
# 预测每个点的标签
predictions = np.array([knn_predict(data, point, k_value) for point in grid_points])
# 将预测结果转换为与 x_values, y_values 相同的形状
predictions = predictions.reshape(x_values.shape)
# 绘制散点图
plt.scatter(data['Density'], data['Sugar inclusion rate'], c=data['label'], cmap='viridis', edgecolors='k')
plt.title('Original Data Points')
# 绘制决策边界
plt.contourf(x_values, y_values, predictions, alpha=0.3, cmap='viridis')
plt.xlabel('Density')
plt.ylabel('Sugar inclusion rate')
plt.title(f'KNN Classification (k={k_value})')
plt.show()