scrapy-redis源码分析并实现自定义初始请求
- 前言
- 关卡:如何自定义初始请求
- 背景
- 思考
- 简单又粗暴的方式
- 源码分析
- 结束
前言
通过这篇文章架构学习(二):原生scrapy如何接入scrapy-redis,初步入局分布式,我们正式开启scrapy-redis分布式爬虫之旅,接下来我们会遇到许多业务或技术难题,期待大家一路斩将,直达胜利之门。
承接上文,笔者将开始自己的通关之旅~
关卡:如何自定义初始请求
背景
笔者现在处理的采集业务是:所有站点通过遍历列表页的方式去采集数据,一般情况下深度只有2层,所以应该算是广度遍历。
这种情况下只要构造好第一页的请求,那么后续直接替换页码即可,但如何是第一页请求需要增加cookie或者请求头配置呢,这就不能直接使用原生的请求方式了。
思考
首先我们一定要有这个意识:不是只有url才能作为名单,名单的内容与格式是由你决定的。
由于我是在开发通用采集脚本(这个有机会讲讲),所以思考内容比较多。
- 纯粹的GET请求,这种可以使用原生逻辑即可,页码替换只要在
parse替换即可 - 纯粹的POST请求也可以使用原生逻辑实现,因为源码里是可以适配
json格式的名单(下文源码演示) - 存在反爬或者信息校验的请求时是无法使用原生逻辑的
- 原生请求
callback默认是指向parse的,但是我又不想只想它
简单又粗暴的方式
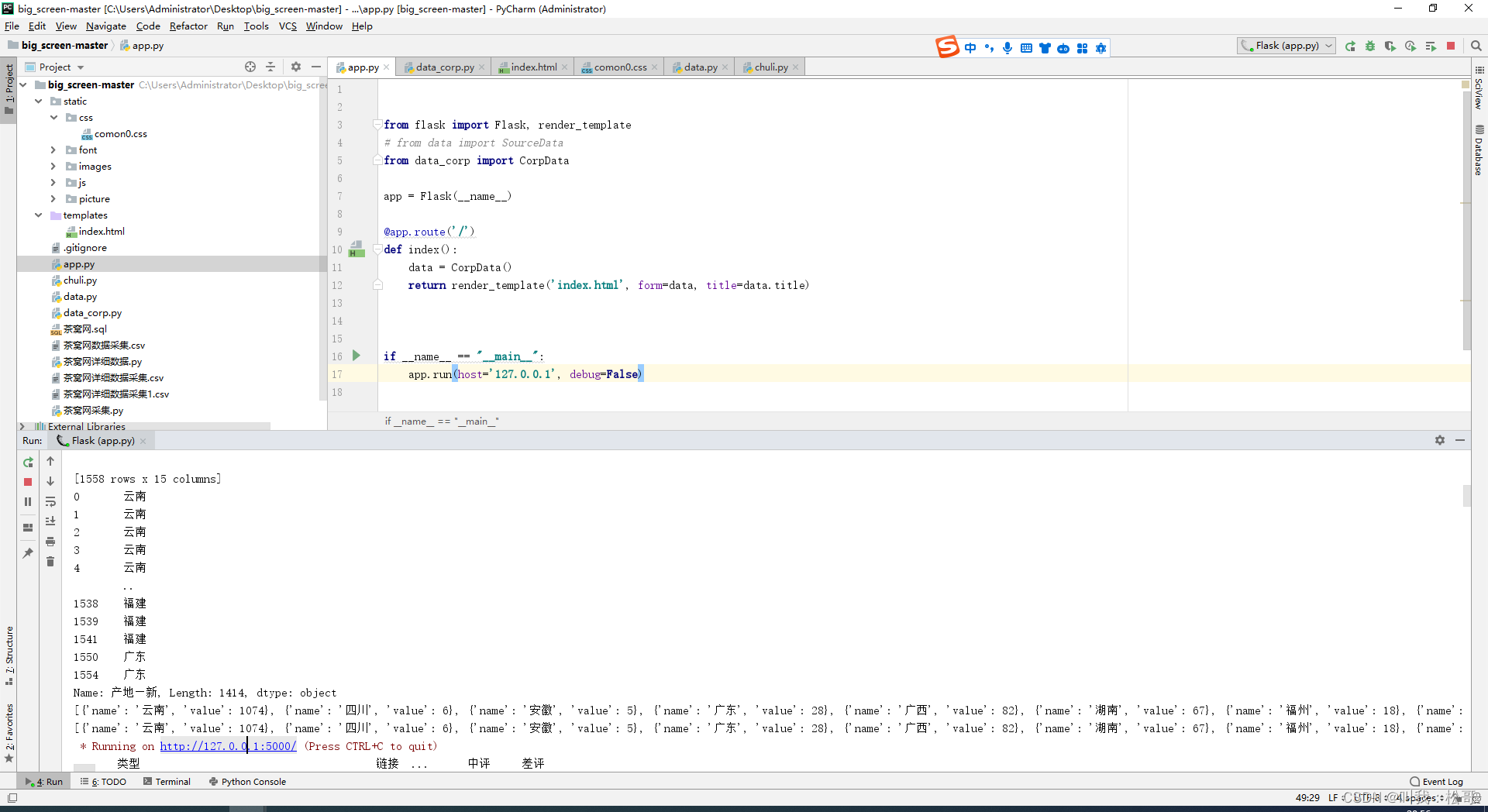
我们知道初始名单入口就是start_requests,那直接重写它就是了,干它,我都可以为所欲为自定义初始请求了。现在的采集基本就是这么实现的,其实无伤大雅,但是如果想开发通用采集脚本就需要更加灵活的开发方式,我们追求的是高效且灵活可控,而不是写死。(下图的BaseSpider类是我自定义的基类,它继承了RedisSpider)
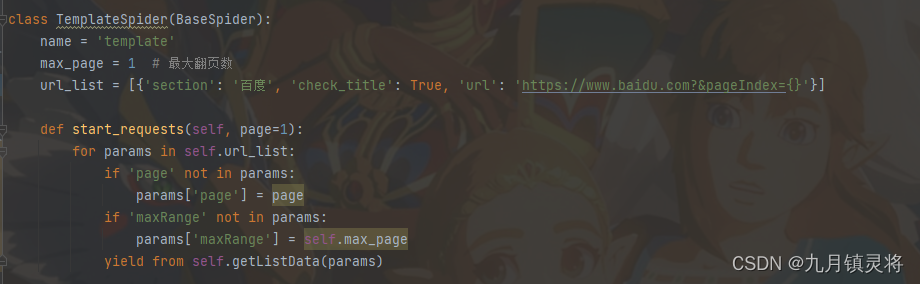
源码分析
直接看RedisSpider类,它同时继承了RedisMixin和Spider,
这里要科普一下,就是python中,当一个类同时继承了两个基类,它可以共用这两个基类的属性和方法,如果两个基类中定义了相同名称的方法或属性,那么Python会根据MRO(Method Resolution Order,方法解析顺序)来决定使用哪一个,MRO是Python确定如何查找和调用方法的一个规则。MRO返回的元组会包含 RedisMixin 和 Spider,并且 RedisMixin 会在 Spider 之前。这意味着当 RedisSpider 继承的方法或属性有冲突时,Python会优先使用 RedisMixin 中的定义。
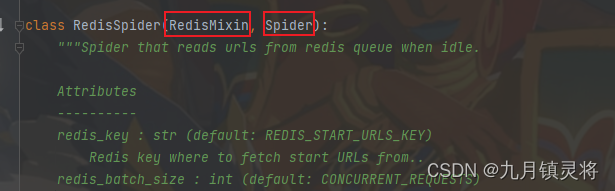
RedisMixin和Spider两个基类是都有start_requests方法的,所以RedisSpider调用的是RedisMixin的start_requests方法
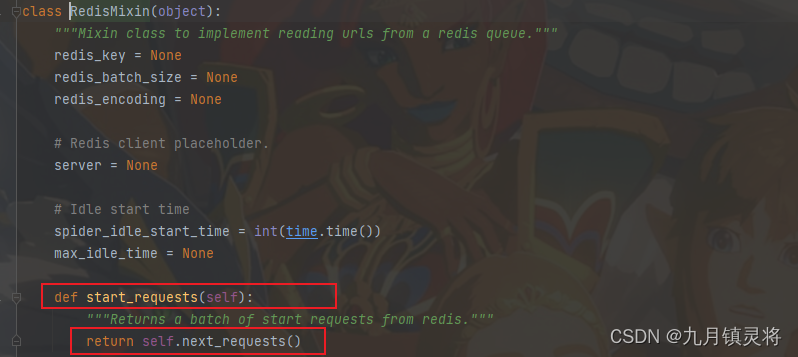
直接跟下去,看看next_requests是啥作用。next_requests的作用是返回要调度的请求,通过下图我们就知道fetch_data是取redis队列数据的(取完就删),既然返回的是请求,那么生成请求的就是make_request_from_data方法了,看这方法的定义就知道我们离目标不远了,继续跟下去~
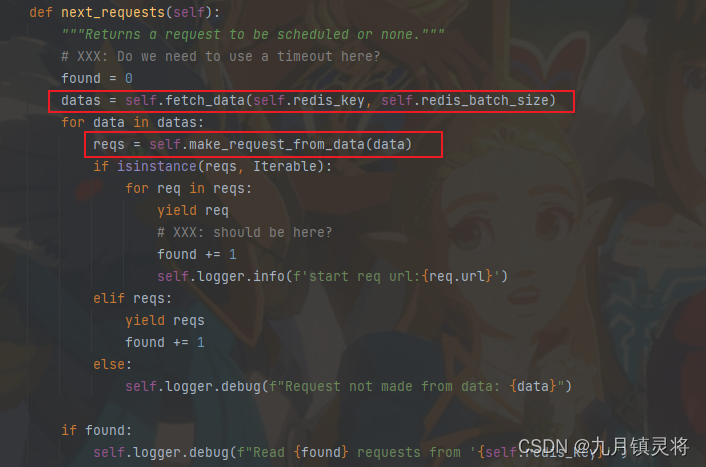
看到这里我们就确定是在make_request_from_data方法中生成的初始请求了。这里大家也就能知道,redis名单是可以存储json格式的了(不过要先转成str),而且源码很粗暴,只要不是json格式,无论是不是url都直接发起GET请求
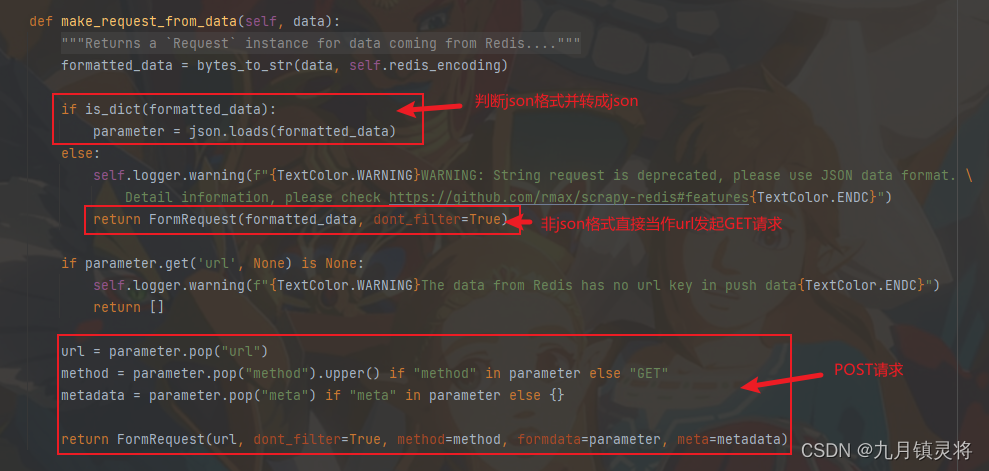
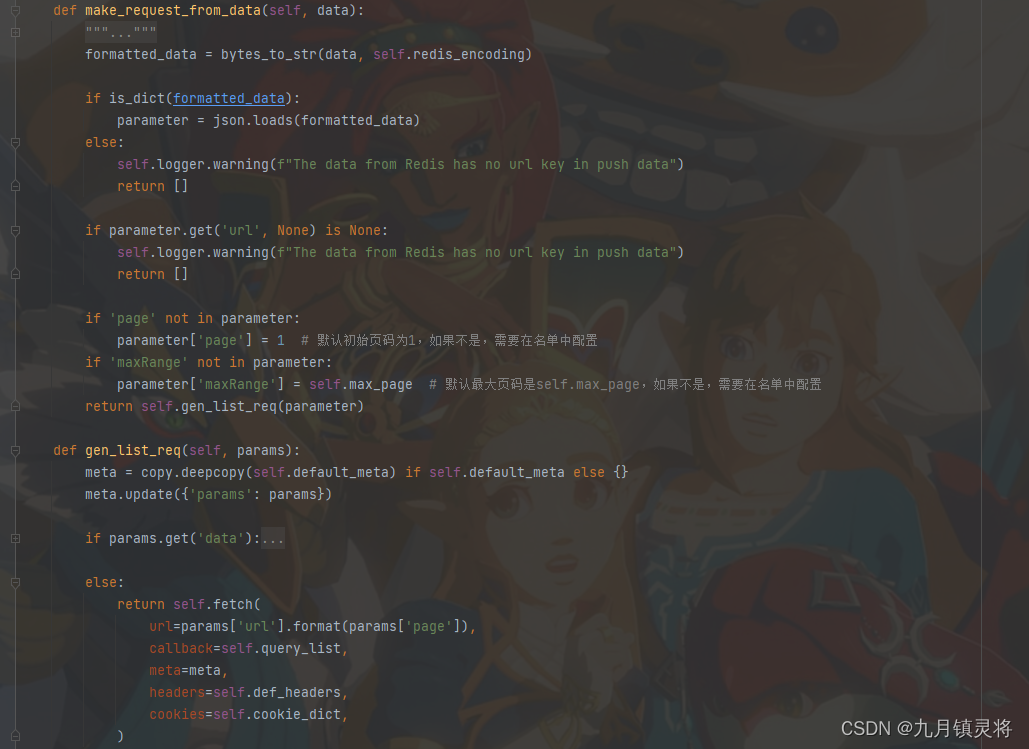
所以我们只需要在自己的脚本或者类中重写make_request_from_data方法即可,只要最后返回的是请求或者空列表即可。
实现方式各异,对我而言,我做了约束,名单必须是json格式。
结束
这关卡算是过了,掌握了源码解析后,如果业务无法满足了,后续只需要在原有基础上继续重构就行。
好了,分享就到这了,有啥错误的地方请指正~