作者:张杰、霍智鑫、行疾
什么是 Ray?
Ray 是一个开源框架,专为构建可扩展的分布式应用程序而设计,旨在通过提供简单直观的 API,简化分布式计算的复杂性,让开发者能够便捷高效地编写并行和分布式 Python 应用程序。
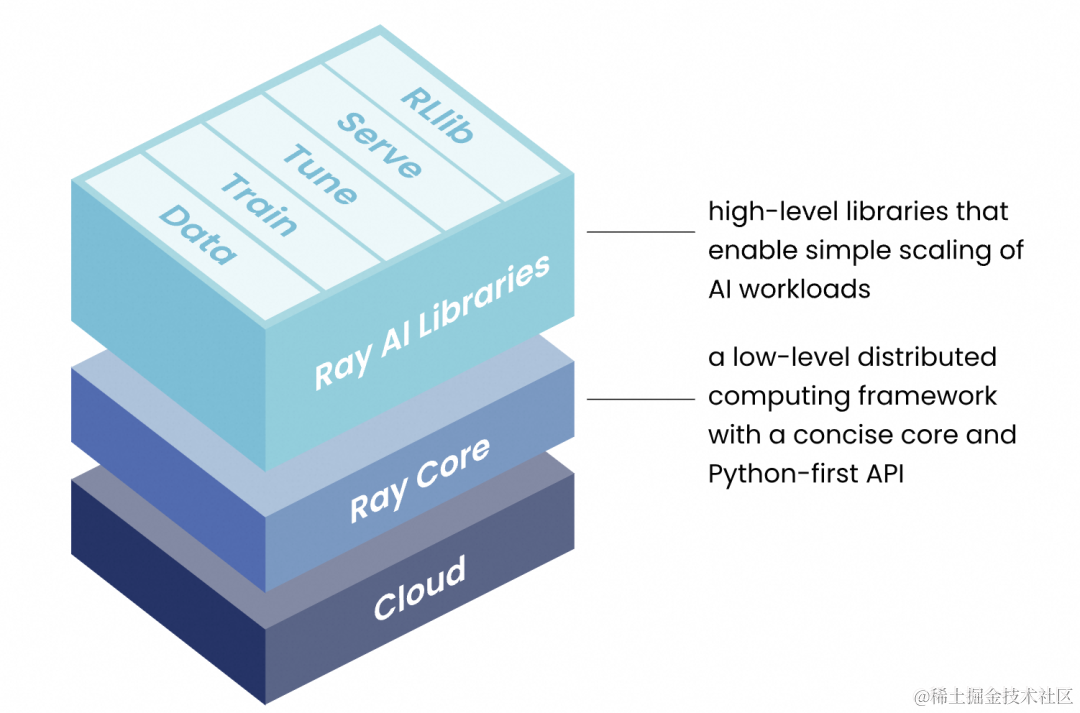
Ray 的统一计算框架由三层组成:
-
Ray AI libraries
一个开源、Python 语言的特定领域库集,为 ML 工程师、数据科学家和研究人员提供了一个可扩展且统一的 ML 应用程序工具包。
-
Ray Core
一个开源的 Python 通用分布式计算库,使机器学习工程师和 Python 开发人员能够扩展 Python 应用程序并加速机器学习工作负载。
-
Ray Cluster
Ray 集群由一个 Head 节点(负责协调和管理整个 Ray 集群,以及运行 Ray 的一些关键的全局服务)和若干个 Worker 节点(实际执行计算任务的节点,可以自动伸缩以适应工作负载的资源需求变化)组成,Worker 节点连接到 Head 节点。Ray 集群可以部署在物理机、虚拟机、Kubernetes 以及各种云环境之上。
图源:https://docs.ray.io/en/latest/ray-overview/index.html
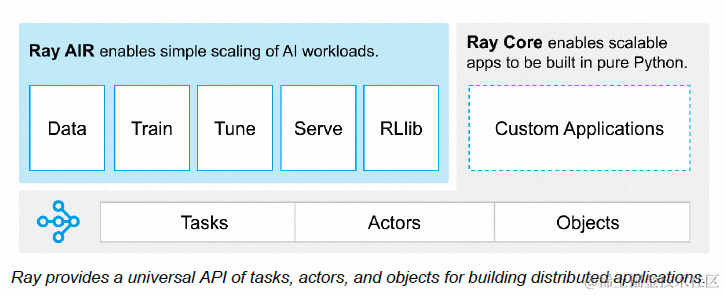
Ray Core 包含以下三个核心概念:
-
Tasks
Ray 支持在独立的 Python 工作线程中异步执行任意函数,这些可异步执行的函数称作“任务(Task)”。开发者能够为每个任务配置所需的 CPU、GPU 及其他自定义资源。Ray 集群调度器会根据这些资源请求在集群中合理调度任务,从而实现高效并行处理。
-
Actors
参与者(Actor)将 Ray API 从函数(即任务)扩展到类。参与者本质上是一个有状态的工作实体(或服务)。每当一个新的参与者被实例化时,将创建一个新的工作线程,并将该参与者调度到该特定的工作线程上,并且可以访问和改变该工作线程的状态。与任务一样,参与者也支持 CPU、GPU 和自定义资源需求。
-
Objects
在 Ray 中,任务和参与者在对象(Objects)上创建和计算。我们将这些对象称为远程对象(remote objects),因为它们可以存储在 Ray 集群中的任何位置,并且我们使用 objects ref 来引用它们。远程对象缓存在 Ray 的分布式共享内存的对象存储中,并且集群中的每个节点都有一个对象存储。在 Ray 集群设置中,一个远程对象可以驻留在一个或多个节点上,与谁持有 objects ref 无关。
Ray Cluster
Ray Cluster 的基本架构如下图所示。一个 Ray 集群由一个 Head 节点和若干个 Worker 节点组成,Worker 节点通过网络连接到 Head 节点,进行协同和通信。
Head 节点主要负责运行 Ray 集群管理相关的控制进程(以蓝色突出显示),例如 Autoscaler、GCS,以及负责运行 Ray 作业的 Driver processes。除此之外,主节点与其他 Worker 节点无异,Ray 可以像任何其他 Worker 节点一样在 Head 节点上调度任务。
Worker 节点则专注于执行 Ray 作业中用户的应用程序代码,不运行任何 Head 节点中的控制和管理进程。它们参与分布式调度,以及 Ray Objects 在集群内存中的存储和分发。

图源:https://docs.ray.io/en/latest/cluster/key-concepts.html
要在生产环境中跨多台机器部署 Ray,首要步骤是部署一个由 Head 节点和 Worker 节点(Ray 节点在 Kubernetes 上运行时实现为 pod)构成的 Ray 集群。该集群支持通过 Ray 自带的 autoscaler 功能实现弹性扩缩。
Ray 集群的创建方式有多种,对于在 Kubernetes 环境下的部署,我们推荐使用 kuberay,它提供了一种便捷的方式来快速搭建 Ray 集群。详情可参考 Ray 官方文档 Getting Started with KubeRay — Ray 2.9.1 [ 1] 。
Ray on Kubernetes
在 Kubernetes(包括阿里云 ACK)上部署 Ray Cluster 是通过 KubeRay Operator 来支持的,它提供了一种 Kubernetes 原生的方式来管理 Ray 集群。KubeRay Operator 的安装包括部署 Operator Deployment 和 RayCluster、RayJob 和 RayService 的 CRD。
在 Kubernetes 上部署 Ray 集群有多方面好处:
弹性伸缩: Kubernetes 能够根据集群工作负载自动伸缩节点数量,与 Ray 的 autoscaler 紧密集成,可以实现 Ray 集群根据工作负载需求动态伸缩,优化资源利用率,轻松管理大规模分布式应用程序。
容错性: Ray 本身就设计有容错机制,在 Kubernetes 上运行时,这一特性得到了增强。如果某个 Ray 节点失败,Kubernetes 会自动处理,替换失败节点,保证集群的稳定性和可用性。
资源管理: 在 Kubernetes 中,可以通过资源请求和限制,精细地控制和管理 Ray 节点所能使用的资源,比如 CPU 和内存。这样可以更有效地利用集群资源,避免资源浪费。
简化部署: Kubernetes 提供了一套统一的部署、管理和监控容器化应用的机制。通过 Kubernetes 部署 Ray 集群,可以简化配置和管理流程,确保在不同环境中(开发、测试、生产)部署的一致性。
服务发现和负载均衡: Kubernetes 能够提供服务发现和负载均衡的功能。这意味着 Ray 节点之间的通信以及客户端到 Ray 集群的连接都可以通过 Kubernetes 自动管理,从而简化网络配置并提高性能。
多租户支持: Kubernetes 支持命名空间,可以实现多用户、多团队在同一个 Kubernetes 集群中同时运行各自的 Ray 集群而不会相互干扰,这在共享资源的环境中尤其有用。
监控和日志: 与 Kubernetes 集成之后,可以利用它的监控和日志系统来跟踪 Ray 集群的状态和性能。例如,可以使用 Prometheus 和 Grafana 来监控集群的性能指标。
兼容性: Kubernetes 是云原生生态系统的核心,与多种云服务提供商和技术栈兼容。因此,利用 Kubernetes 部署 Ray 集群可以轻松地在不同的云平台或者混合云环境之间进行迁移和扩展。
总体而言,将 Ray 部署在 Kubernetes 上能极大地简化分布式应用程序的部署与管理,因此,当下它成为众多需要运行大规模机器学习任务的组织的热门选择。详情可参考 Ray 官方文档 Ray on Kubernetes — Ray 2.9.1 [ 2] 。
Ray on ACK
阿里云容器服务 ACK 致力于帮助企业构建高效和易于管理的云原生环境,提供高性能且可伸缩的容器应用管理能力。通过 KubeRay 结合 ACK 的云原生化部署方式,可以实现在 ACK 集群上快速创建 Ray 集群,不仅便于与阿里云 SLS 日志、Arms Prometheus 监控、Redis 等产品无缝对接,增强日志管理、可观测、高可用等能力,还可以通过 Ray autoscaler 与 ACK autoscaler 弹性功能结合,充分发挥云的弹性能力,为客户按需提供计算资源。
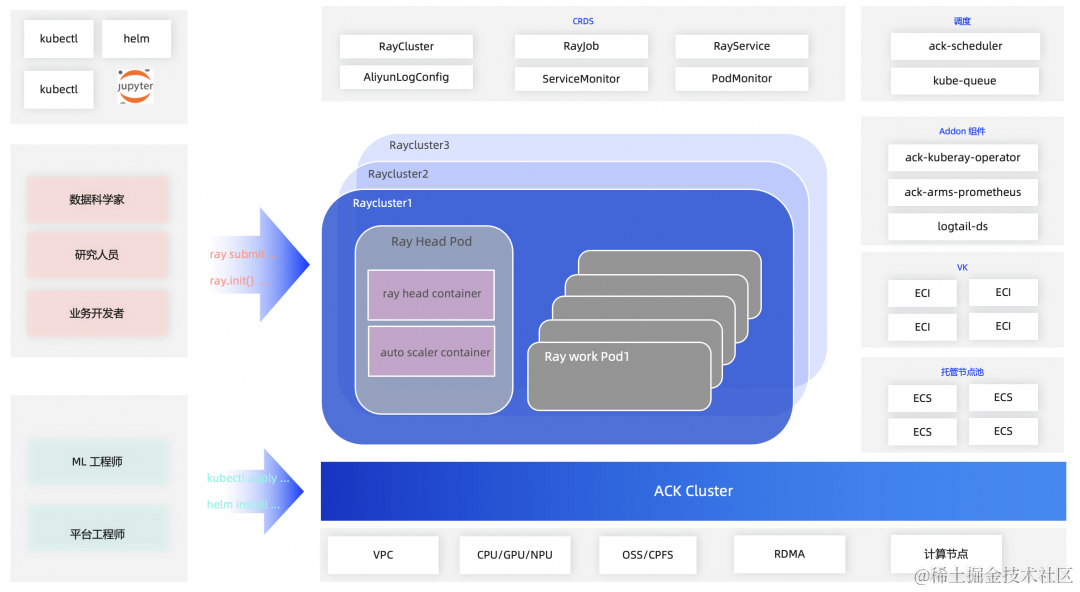
接下来,我们将提供一个详细的教程,指导您在 ACK 集群中部署 ack-kuberay-operator 组件,并迅速创建一个 RayCluster。
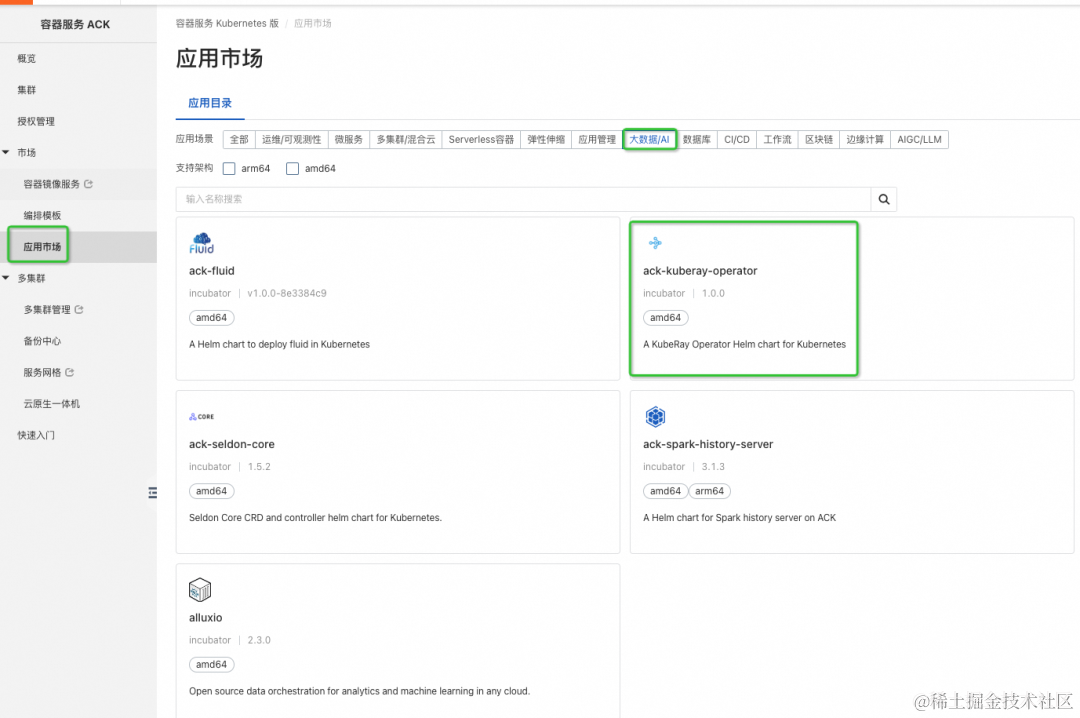
部署 ack-kuberay-operator
阿里云容器服务 ACK 应用市场 [ 3] 里集成了社区的 kuberay 组件,并在社区组件的基础上做了能力增强和安全权限收敛,组件名为:ack-kuberay-operator [ 4] 。
前置条件
- 创建一个 ACK Pro [ 5] 集群, K8s 版本为 1.24 及以上
-
- 开启日志服务
- 开启阿里云可观测监控 Prometheus 版
- 节点配置:1 台 ecs.g6e.xlarge 4vCPU 16GiB (测试环境最低规格建议,生产环境中建议以实际需求为准)
- 本地安装 kubectl [ 6] 、helm [ 7]
-
- 保存 ACK 集群的 kubeconfig 文件到本地 $HOME/.kube/config 文件
- 创建阿里云云数据库 Redis 版 [ 8] (支持 RayCluster 高可用需要,可根据实际需求选择创建)
-
- 与新建的 ACK Pro 集群同 Region、同 VPC
- 添加白名单分组,允许 VPC/Pod CIDR 地址段访问
- 获得 redis 实例的地址 [ 9]
- 获得 redis 实例的密码 [ 10]
部署 ack-kuberay-operator
点击阿里云容器服务 ACK 应用市场 -> 大数据/AI -> ack-kuberay-operator 组件, 点击右上角: 一键部署:
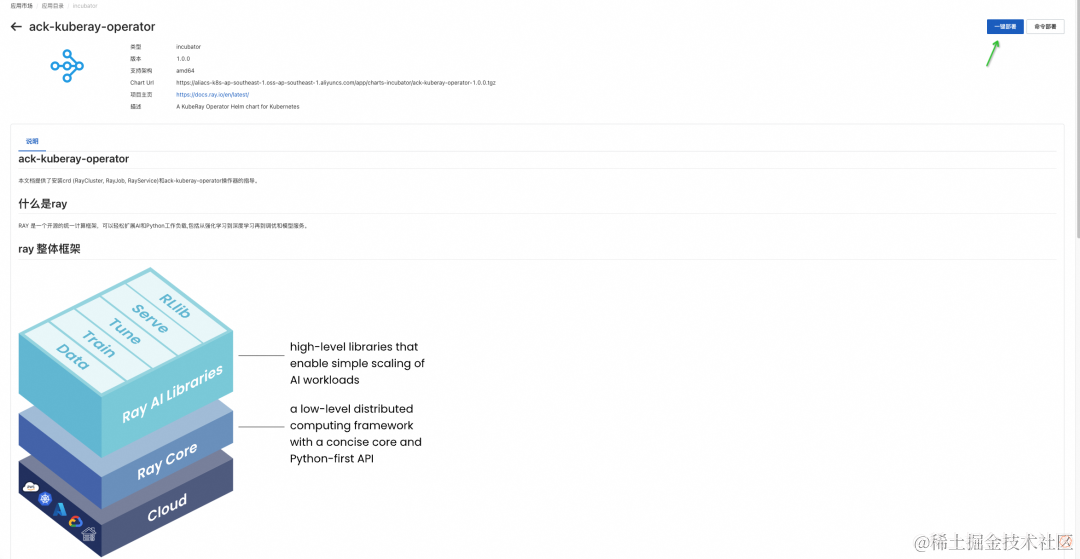
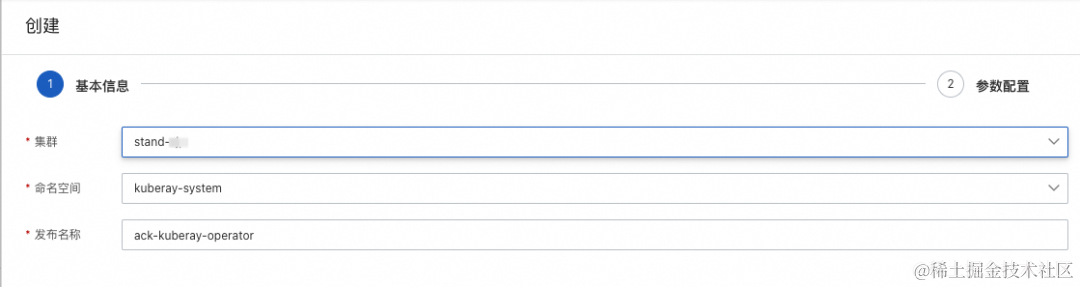
选择对应的 ACK 集群,点击下一步,点击部署:
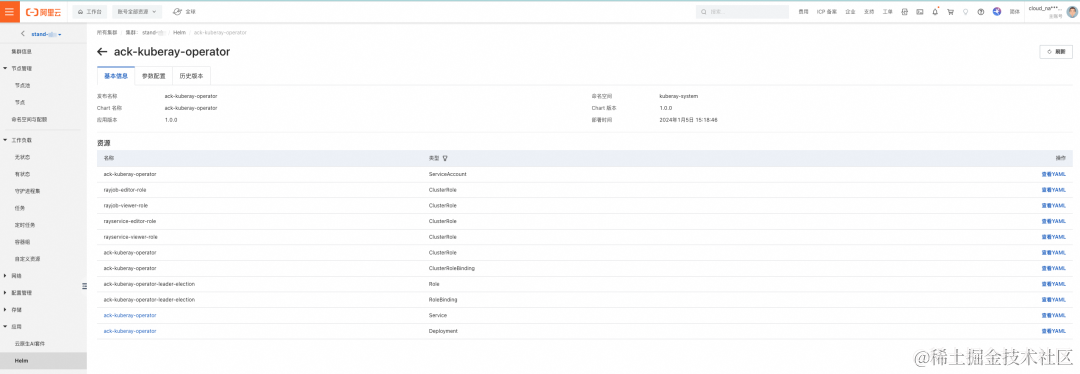
部署成功后,会在对应 ACK 集群的 Helm 页面,展示对应的 ack-kuberay-operator 的 helm 组件信息。
校验 ack-kuberay-operator
查看 kuberay-system 命名空间下的 operator pod 是否 running:
# kubectl get pod -n kuberay-system
NAME READY STATUS RESTARTS AGE
ack-kuberay-operator-dbbf56699-4j9hk 1/1 Running 0 120m
部署 ack-ray-cluster
在阿里云容器服务 ACK 上,我们推荐使用 ack-ray-cluster 组件来部署为您执行具体 Ray 任务的 RayCluster,ack-ray-cluster 增加了额外的 value 配置,便于与阿里云云产品集成(日志,监控,高可用)。
创建 RayCluster
增加 aliyunhub helm repo 源,安装 ack-ray-cluster chart 包。
# helm repo add aliyunhub https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/
# helm repo update aliyunhub
# helm search repo ack-ray-cluster
NAME CHART VERSION APP VERSION DESCRIPTION
aliyunhub/ack-ray-cluster 1.0.0 1.0.0 A ray cluster for Alibaba Cloud
根据默认配置安装的 ack raycluster,会自动开启 kuberay 的 auto-scaler 功能,raycluster 默认使用 ray 社区官方镜像 rayproject/ray:2.7.0。其他配置,请查看ack-ray-cluster chart 包里的 values 配置。
在 raycluster 命名空间,创建 RayCluster,名为 myfirst-ray-cluster。
设置环境变量:
export RAY_CLUSTER_NAME='myfirst-ray-cluster'
export RAY_CLUSTER_NS='raycluster'
helm 安装:
# kubectl create ns ${RAY_CLUSTER_NS}
# helm install ${RAY_CLUSTER_NAME} aliyunhub/ack-ray-cluster -n ${RAY_CLUSTER_NS}
查看 ACK 集群中 Ray Cluster. SVC、POD 资源。
# 查看ray cluster 实例
#kubectl get rayclusters.ray.io -n ${RAY_CLUSTER_NS}
NAME DESIRED WORKERS AVAILABLE WORKERS STATUS AGE
myfirst-ray-cluster 49s
# 查看service 资源
#kubectl get svc -n ${RAY_CLUSTER_NS}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myfirst-ray-cluster-head-svc ClusterIP 192.168.36.189 <none> 10001/TCP,8265/TCP,8080/TCP,6379/TCP,8000/TCP 82s
# 查看raycluster pod 信息
# kubectl get pod -n ${RAY_CLUSTER_NS}
NAME READY STATUS RESTARTS AGE
ray-cluster-01-head-zx88p 2/2 Running 0 27s
ray-cluster-01-worker-workergroup-nt9wv 1/1 Running 0 27s
ack-ray-cluster 组件允许用户在 ACK 集群创建多个 RayCluster,例如在 default 命名空间,创建第二个 RayCluster,名为 mysecond-ray-cluster。
# helm install mysecond-ray-cluster aliyunhub/ack-ray-cluster
RayCluster 集成阿里云日志服务 SLS
若对 RayCluster 有日志持久化的需求,需要在 ACK 集群中创建一个全局的 AliyunLogConfig 资源,使得 ACK 集群中的 logtail 组件收集 RayCluster pod 的日志到 ACK 集群对应的 SLS Project 中。
cat <<EOF | kubectl apply -f -
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
name: rayclusters
namespace: kube-system
spec:
# 设置Logstore名称。如果您所指定的Logstore不存在,日志服务会自动创建。
logstore: rayclusters
# 设置Logtail配置。
logtailConfig:
# 设置采集的数据源类型。采集文本日志时,需设置为file。
inputType: file
# 设置Logtail配置的名称,必须与资源名(metadata.name)相同。
configName: rayclusters
inputDetail:
# 指定通过极简模式采集文本日志。
logType: common_reg_log
# 设置日志文件所在路径。
logPath: /tmp/ray/session_*-*-*_*/logs
# 设置日志文件的名称。支持通配符星号(*)和半角问号(?),例如log_*.log。
filePattern: "*.*"
# 采集容器的文本日志时,需设置dockerFile为true。
dockerFile: true
#设置容器过滤条件。
advanced:
k8s:
IncludeK8sLabel:
ray.io/is-ray-node: "yes"
ExternalK8sLabelTag:
ray.io/cluster: "_raycluster_name_"
ray.io/node-type : "_node_type_"
EOF
🔔 相关参数说明:
logPath: 收集 pod 里 /tmp/ray/session_–/logs 目录下的所有日志。可以自定义。
advanced.k8s.ExternalK8sLabelTag: 收集的日志中增加相关 tag 索引,方便日志查找,默认新增了 _raycluster_name 和 node_type 两个 tag。
AliyunLogConfig 相关参数配置请参考配置说明 [ 11] 。该服务是收费的,具体费用信息参考文档日志服务计费概述 [12 ] 。
在 ACK 集群资源界面选择日志服务 Project 点击进入 SLS Project 详情。
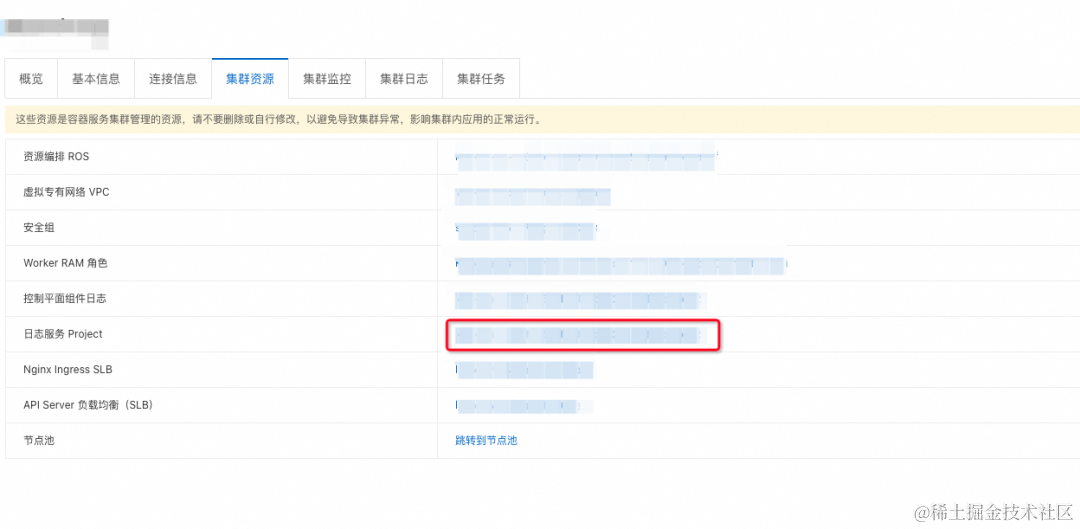
在 Projectr 中找到对应 rayclusters 的 logstore,其中包含着您的 raycluster 中的日志内容:可以根据 tag 查找不同 raycluster 的日志。
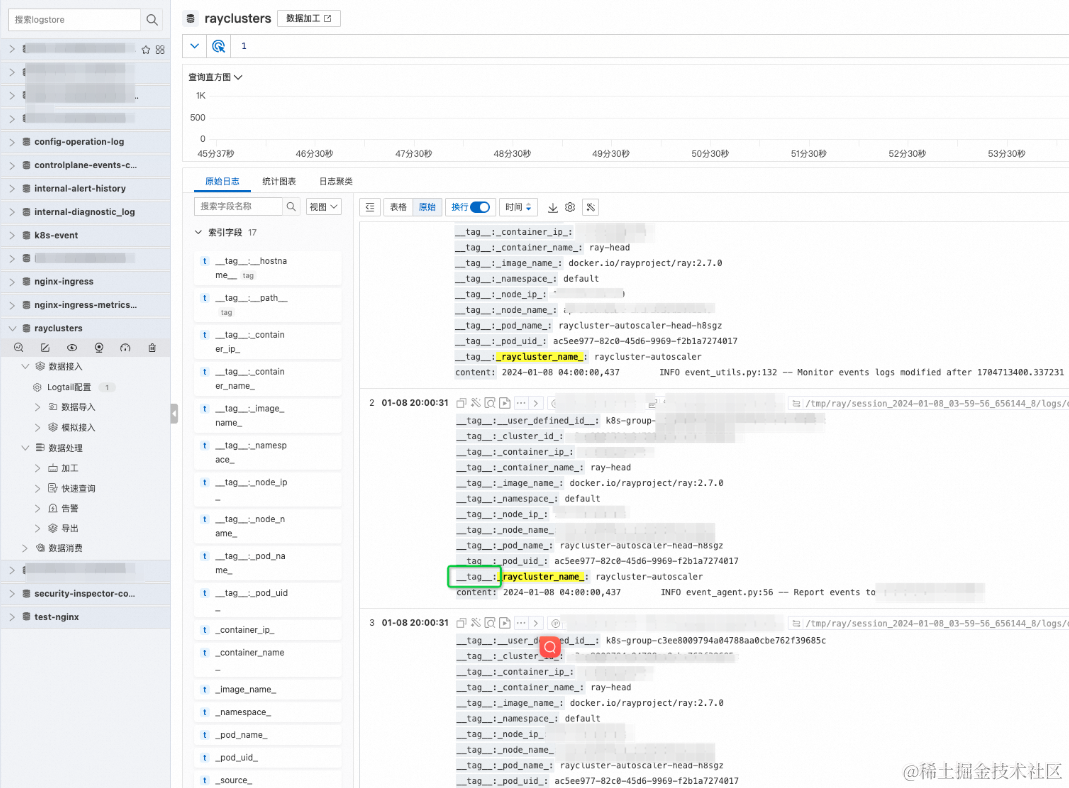
RayCluster 集成阿里云 Prometheus 监控
ack-ray-cluster 集成了阿里云 prometheus [1****3] 监控能力。若需要 raycluster 集群监控能力,则需要在安装时,将 values 里的 armsPrometheus.enable 设置为 true。
🔔 注意:该服务是收费的,具体费用信息参考文档可观测监控 Prometheus 版计费概述[14]。
# helm uninstall ${RAY_CLUSTER_NAME} -n ${RAY_CLUSTER_NS}
# helm install ${RAY_CLUSTER_NAME} aliyunhub/ack-ray-cluster -n ${RAY_CLUSTER_NS} --set armsPrometheus.enable=true
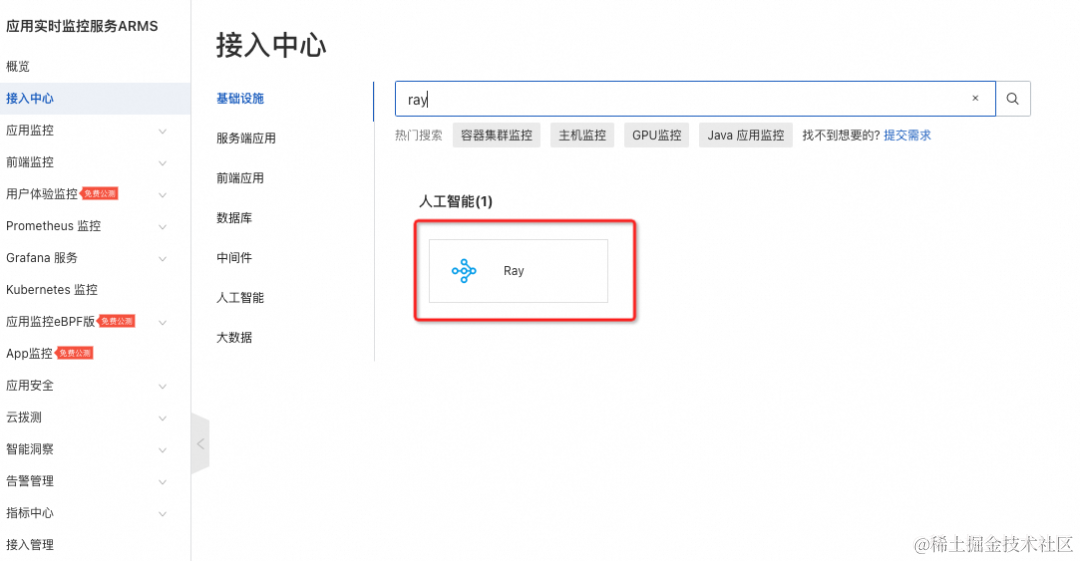
登录 arms 接入中心 [ 15] -> 搜索 ray ->点击 ray:
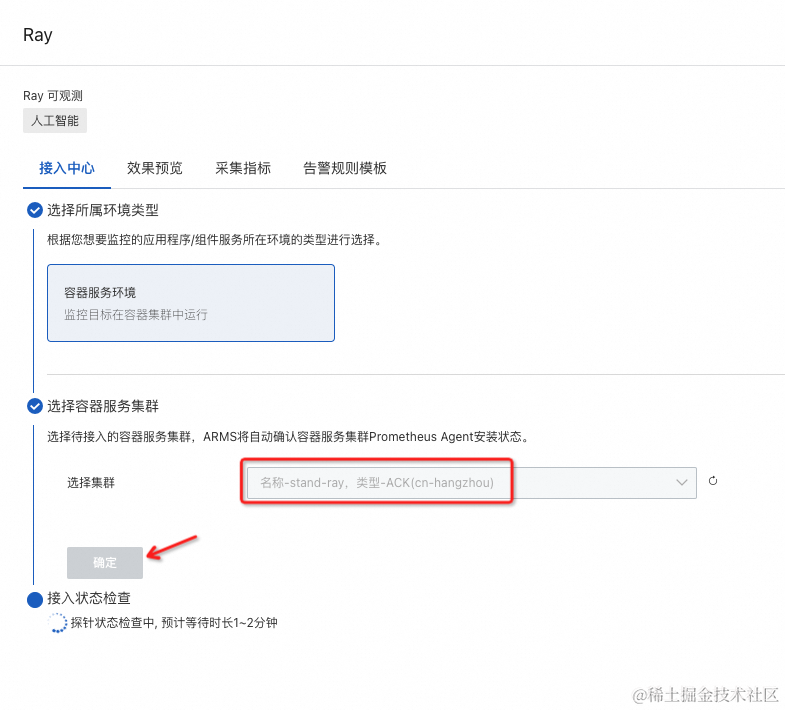
选择上文新建的 ACK 集群,点击确定:
点击接入管理:
点击大盘-> 选择 Ray Cluster:
选择对应 Namespace, RayClusterName, SessionName,若 Ray 集群中有任务在跑,则会有监控数据。
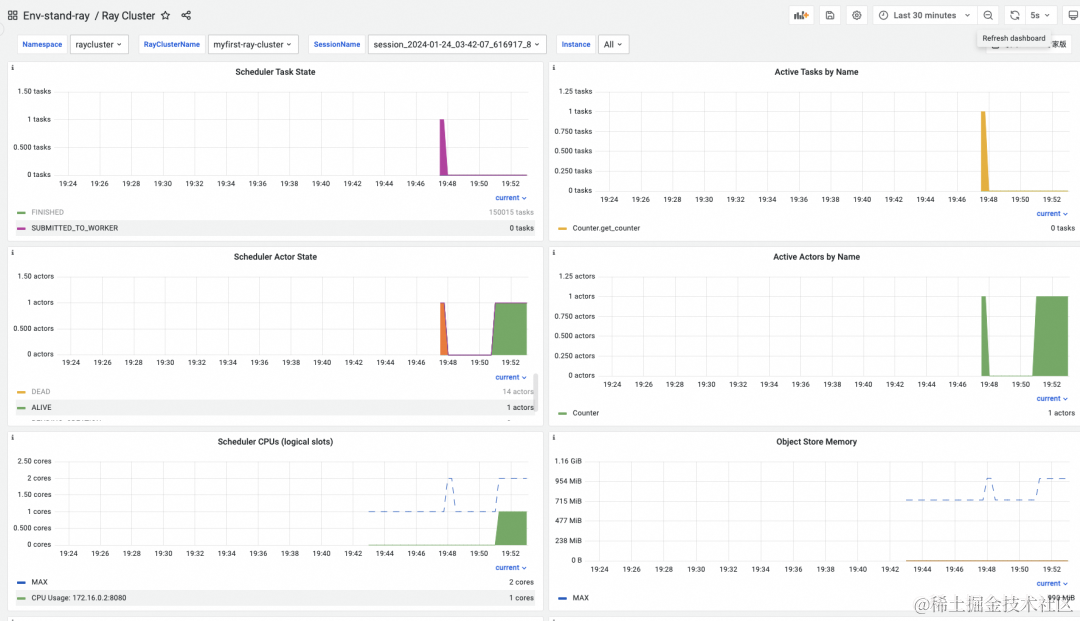
RayCluster 支持 fault toleration
Ray Cluster GCS (Global Control Service) 组件管理 Ray 集群级元数据。默认情况下,GCS 缺乏容错性,因为它将所有数据存储在内存中,故障可能导致整个 Ray 集群失败。为了使 GCS 容错,Ray 要求必须有一个高可用性的 Redis。这样,在 GCS 重启的情况下,它从 Redis 实例中检索所有数据并恢复其常规功能。ack-ray-cluster 支持对阿里云云数据库 Redis 版的集成,提供 Ray Cluster GCS fault toleration 的能力。
GCS fail toleration 介绍:
- kuberay gcs fault toleration config [ 16]
- gcs fault toleration in kuberay [ 17]
手工创建 secret,保存阿里云云数据库 Redis 版实例的 RAY_REDIS_ADDRESS 和REDIS_PASSWORD 信息。
secret 命名规范: ${RAY_CLUSTER_NAME}-raycluster-redis
# export REDIS_PASSWORD='your redis password'
# export RAY_REDIS_ADDRESS='your redis address'
# kubectl create secret generic ${RAY_CLUSTER_NAME}-raycluster-redis -n ${RAY_CLUSTER_NS} --from-literal=address=${RAY_REDIS_ADDRESS} --from-literal=password=${REDIS_PASSWORD}
创建 RayCluster, gcsFaultTolerance.enable 设置为 True,会自动为 RayCluster 实例添加 ray.io/ft-enabled: “true” annotation,用来开启 GCS fault tolerance 能力,并为 RayCluster 实例通过 Env 挂载 secret 的信息。
# helm uninstall ${RAY_CLUSTER_NAME} -n ${RAY_CLUSTER_NS}
# helm install ${RAY_CLUSTER_NAME} aliyunhub/ack-ray-cluster -n ${RAY_CLUSTER_NS} --set armsPrometheus.enable=true --set gcsFaultTolerance.enable=true
提交完之后查看 RayCluster 的情况:
# kubectl get rayclusters.ray.io ${RAY_CLUSTER_NAME} -n ${RAY_CLUSTER_NS}
NAME DESIRED WORKERS AVAILABLE WORKERS STATUS AGE
myfirst-ray-cluster 0 0 1 11m
查看对应的 RayCluster 的 Pod 情况:
# kubectl get pod -n ${RAY_CLUSTER_NS}
NAME READY STATUS RESTARTS AGE
myfirst-ray-cluster-head-vrltd 2/2 Running 0 12m
这里以阿里云云数据库 Redis 实例为例,使用 DMS 访问 Redis 查看数据:
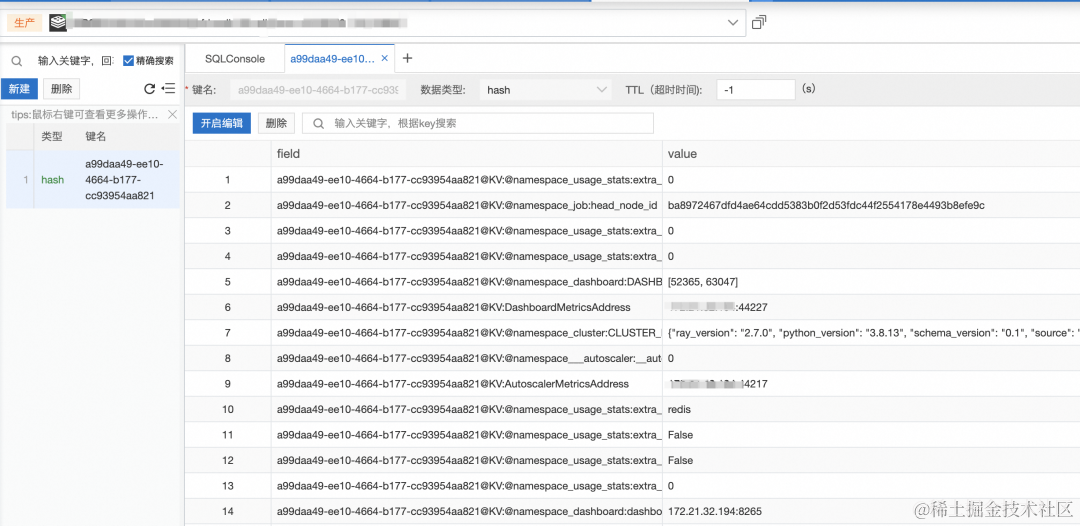
可以看到 RayCluster 的 GCS 中的信息已经被存到了 Redis 中。当卸载这个 RayCluster 时,这个 RayCluster 的 GCS 的信息会在 Redis 中自动进行删除操作。
扩展实践
Ray DashBoard
使用 kubectl port-forward 对 Ray Dashboard 进行本地访问:
# kubectl get svc -n ${RAY_CLUSTER_NS}
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myfirst-ray-cluster-head-svc ClusterIP 192.168.208.188 <none> 10001/TCP,8265/TCP,8080/TCP,6379/TCP,8000/TCP 18m
# kubectl port-forward svc/myfirst-ray-cluster-head-svc --address 0.0.0.0 8265:8265 -n ${RAY_CLUSTER_NS}
Forwarding from 0.0.0.0:8265 -> 8265
本地浏览器访问 http://127.0.0.1:8265/
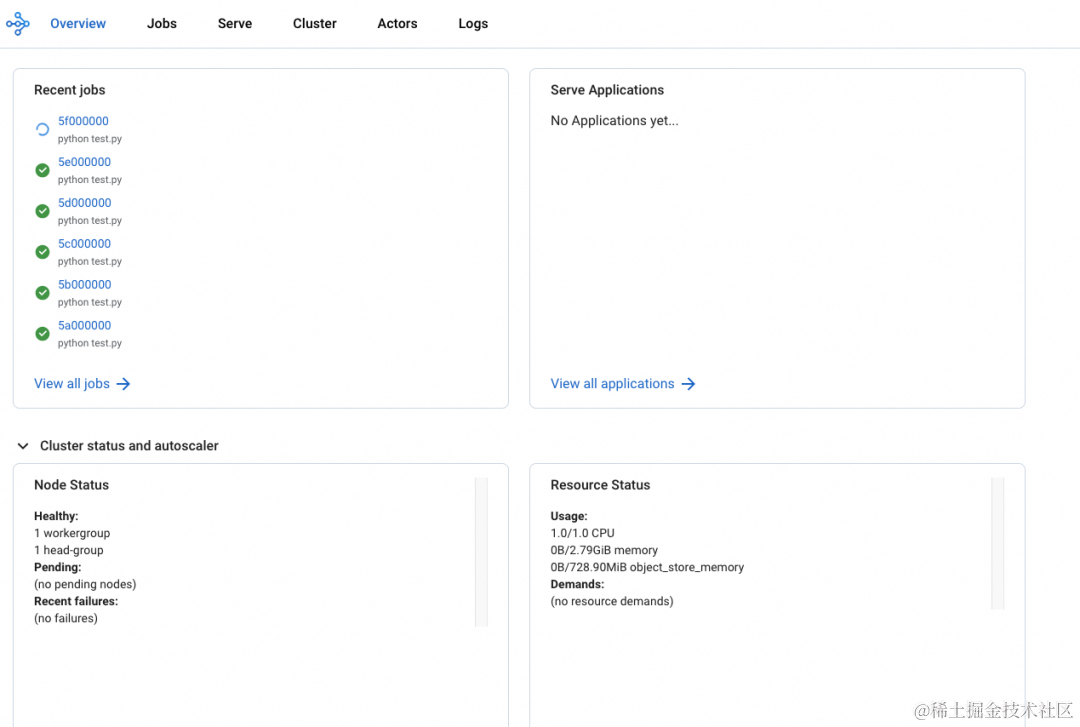
ACK-RayCluster DashBoard 默认禁用了 Metric 的展示,后续会提供 Metic 与阿里云 Prometheus 监控页面的嵌入集成能力。
提交Ray Job
以本地 RayCluster 提交 Ray Job 为例:
# kubectl get pod -n ${RAY_CLUSTER_NS}
NAME READY STATUS RESTARTS AGE
myfirst-ray-cluster-head-v7pbw 2/2 Running 0 39m
myfirst-ray-cluster-worker-workergroup-5dqj8 1/1 Running 0 31m
# kubectl exec -it -n ${RAY_CLUSTER_NS} myfirst-ray-cluster-head-v7pbw -- bash
head pod 里使用 echo 命令保存 my_script.py 文件:
import ray
import os
# 连接本地或者远程ray cluster
ray.init()
@ray.remote(num_cpus=1)
class Counter:
def __init__(self):
self.name = "test_counter"
self.counter = 0
def increment(self):
self.counter += 1
def get_counter(self):
return "{} got {}".format(self.name, self.counter)
counter = Counter.remote()
for _ in range(10000):
counter.increment.remote()
print(ray.get(counter.get_counter.remote()))
运行 my_script.py 脚本,执行分布式任务:
# python my_script.py
2024-01-24 04:25:27,286 INFO worker.py:1329 -- Using address 127.0.0.1:6379 set in the environment variable RAY_ADDRESS
2024-01-24 04:25:27,286 INFO worker.py:1458 -- Connecting to existing Ray cluster at address: 172.16.0.236:6379...
2024-01-24 04:25:27,295 INFO worker.py:1633 -- Connected to Ray cluster. View the dashboard at http://172.16.0.236:8265
test_counter got 0
test_counter got 1
test_counter got 2
test_counter got 3
...
Ray Cluster 内运行 job 作业有多种方式,具体可参照:
- how do you use the ray-client [ 18]
- quick start useing the ray job cli [ 19]
Ray Auto-Scaler 结合 ACK Cluster-Autoscaler 实现弹性伸缩
首先 ACK 集群默认节点池开启弹性伸缩能力 [ 20] 。
# helm uninstall ${RAY_CLUSTER_NAME} -n ${RAY_CLUSTER_NS}
# helm install ${RAY_CLUSTER_NAME} aliyunhub/ack-ray-cluster -n ${RAY_CLUSTER_NS}
查看 RAY 集群中资源的运行情况:
# kubectl get pod -n ${RAY_CLUSTER_NS}
NAME READY STATUS RESTARTS AGE
myfirst-ray-cluster-head-kvvdf 2/2 Running 0 22m
# 登录head 节点,查看集群status 信息
# kubectl -n ${RAY_CLUSTER_NS} exec -it myfirst-ray-cluster-head-kvvdf -- bash
(base) ray@myfirst-ray-cluster-head-kvvdf:~$ ray status
======== Autoscaler status: 2024-01-25 00:00:19.879963 ========
Node status
---------------------------------------------------------------
Healthy:
1 head-group
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Usage:
0B/1.86GiB memory
0B/452.00MiB object_store_memory
Demands:
(no resource demands)
在 raycluster 中运行提交如下 job:
import time
import ray
import socket
ray.init()
@ray.remote(num_cpus=1)
def get_task_hostname():
time.sleep(120)
host = socket.gethostbyname(socket.gethostname())
return host
object_refs = []
for _ in range(15):
object_refs.append(get_task_hostname.remote())
ray.wait(object_refs)
for t in object_refs:
print(ray.get(t))
上述代码启动了 15 个 task,每个 task 需要 1 核 CPU 调度资源。默认创建的 raycluster head pod 的 --num-cpus 为 0,不允许调度 task, work pod 的 cpu 内存默认为 1 核,1G 因此需要自动扩容 15 个 work pod。ACK 集群中整体节点资源不够,Pending 的 pod 会自动触发 ACK 的节点池弹性伸缩能力。
# kubectl get pod -n ${RAY_CLUSTER_NS} -w
NAME READY STATUS RESTARTS AGE
myfirst-ray-cluster-head-kvvdf 2/2 Running 0 47m
myfirst-ray-cluster-worker-workergroup-btgmm 1/1 Running 0 30s
myfirst-ray-cluster-worker-workergroup-c2lmq 0/1 Pending 0 30s
myfirst-ray-cluster-worker-workergroup-gstcc 0/1 Pending 0 30s
myfirst-ray-cluster-worker-workergroup-hfshs 0/1 Pending 0 30s
myfirst-ray-cluster-worker-workergroup-nrfh8 1/1 Running 0 30s
myfirst-ray-cluster-worker-workergroup-pjbdw 0/1 Pending 0 29s
myfirst-ray-cluster-worker-workergroup-qxq7v 0/1 Pending 0 30s
myfirst-ray-cluster-worker-workergroup-sm8mt 1/1 Running 0 30s
myfirst-ray-cluster-worker-workergroup-wr87d 0/1 Pending 0 30s
myfirst-ray-cluster-worker-workergroup-xc4kn 1/1 Running 0 30s
...
# kubectl get node -w
cn-hangzhou.172.16.0.204 Ready <none> 44h v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 NotReady <none> 0s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 NotReady <none> 0s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 NotReady <none> 0s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 NotReady <none> 1s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 NotReady <none> 11s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.16 NotReady <none> 10s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.16 NotReady <none> 14s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 NotReady <none> 31s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 NotReady <none> 60s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.17 Ready <none> 61s v1.24.6-aliyun.1
cn-hangzhou.172.16.0.16 Ready <none> 64s v1.24.6-aliyun.1
...
Ray Auto-Scaler 的 ECI 弹性伸缩实践
首先 ACK 集群要部署 ACK Virtual Node 组件 [ 21] 。
RayCluster 可以结合 ray 的 auto-scaler 能力,自动弹 ECI 节点,提供免运维、强隔离、能快速启动的容器运行环境。
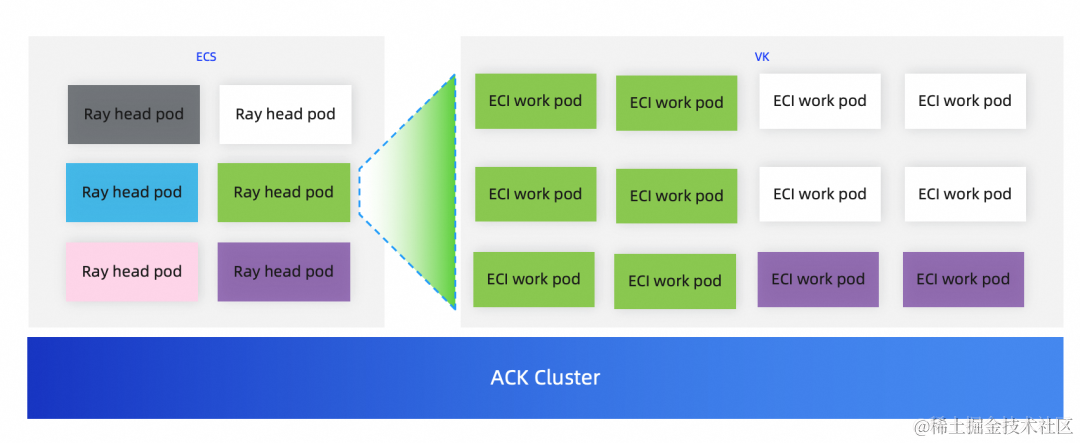
查看 node 节点,新增 virtual-kubelet-cn-hangzhou-kVK 节点。
# kubectl get node
NAME STATUS ROLES AGE VERSION
cn-hangzhou.172.16.0.20 Ready <none> 19h v1.26.3-aliyun.1
cn-hangzhou.172.16.0.236 Ready <none> 82m v1.26.3-aliyun.1
cn-hangzhou.172.16.0.41 Ready <none> 19h v1.26.3-aliyun.1
virtual-kubelet-cn-hangzhou-k Ready agent 16m v1.26.3-aliyun.1
创建 values.yaml 文件:
cat > values.yaml <<EOF
worker:
groupName: workergroup
labels:
alibabacloud.com/eci: "true"
EOF
安装支持 ECI 的 raycluster:
# helm uninstall ${RAY_CLUSTER_NAME} -n ${RAY_CLUSTER_NS}
# helm install ${RAY_CLUSTER_NAME} aliyunhub/ack-ray-cluster -n ${RAY_CLUSTER_NS} -f values.yaml
# kubectl get pod
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myfirst-ray-cluster-head-7fgp4 2/2 Running 0 7m2s 172.16.0.241 cn-hangzhou.172.16.0.240 <none> <none>
向 RayCluster 内提交并运行 python job:
import time
import ray
import socket
ray.init()
@ray.remote(num_cpus=1)
def get_task_hostname():
time.sleep(120)
host = socket.gethostbyname(socket.gethostname())
return host
object_refs = []
for _ in range(2):
object_refs.append(get_task_hostname.remote())
ray.wait(object_refs)
for t in object_refs:
print(ray.get(t))
上述代码启动了 2 个 task,每个 task 需要 1 核 CPU 调度资源。默认创建的 raycluster head pod 的 --num-cpus 为 0,不允许调度 task, work pod 的 cpu 内存默认为 1 核,1G 因此会自动扩容 2 个 eci work pod。
get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myfirst-ray-cluster-head-7fgp4 2/2 Running 0 4m56s 172.16.0.241 cn-hangzhou.172.16.0.240 <none> <none>
myfirst-ray-cluster-worker-workergroup-6s2cl 0/1 Init:0/1 0 4m5s 172.16.0.17 virtual-kubelet-cn-hangzhou-k <none> <none>
myfirst-ray-cluster-worker-workergroup-l9qgb 1/1 Running 0 4m5s 172.16.0.16 virtual-kubelet-cn-hangzhou-k <none>
总结
阿里云容器服务 ACK 提供的 ack-kuberay-operator 和 raycluster 可以实现在 ACK 集群上快速创建 Ray 集群,更加方便与阿里云 SLS 日志、Arms Prometheus 监控、Redis 等产品无缝对接,增强日志管理、可观测、高可用等能力,还可以通过 Ray autoscaler 与 ACK autoscaler 弹性功能结合,充分发挥云的弹性能力,为客户按需提供计算资源。未来 ACK 会进一步提供 Ray 在 ACK 上的增强能力,更好的满足用户在分布式,弹性,AI 方面的需求。
相关链接:
[1] Getting Started with KubeRay — Ray 2.9.1
https://docs.ray.io/en/latest/cluster/kubernetes/getting-started.html
[2] Ray on Kubernetes — Ray 2.9.1
https://docs.ray.io/en/latest/cluster/kubernetes/index.html
[3] 应用市场
https://cs.console.aliyun.com/#/next/app-catalog
[4] ack-kuberay-operator
https://cs.console.aliyun.com/#/next/app-catalog/ack/incubator/ack-kuberay-operator
[5] ACK Pro
https://cs.console.aliyun.com/#/k8s/cluster/list
[6] kubectl
https://kubernetes.io/docs/tasks/tools/
[7] helm
https://helm.sh/docs/intro/install/
[8] 阿里云云数据库 Redis 版
https://www.aliyun.com/product/redis?spm=5176.28508143.J_4VYgf18xNlTAyFFbOuOQe.107.e939154adYavb9&scm=20140722.S_product%40%40%E4%BA%91%E4%BA%A7%E5%93%81%40%4072449._.ID_product%40%40%E4%BA%91%E4%BA%A7%E5%93%81%40%4072449-RL_redis-LOC_menuUNDproduct-OR_ser-V_3-P0_0&v=6ff4a055f2f22f9d118832696bb06df3
[9] 地址
https://help.aliyun.com/zh/redis/user-guide/view-endpoints?spm=a2c4g.11174283.0.0.544d303aA6fL7P
[10] 密码
https://help.aliyun.com/zh/redis/user-guide/change-or-reset-the-password?spm=a2c4g.11186623.0.0.60d14438SOiTpf
[11] 配置说明
https://help.aliyun.com/zh/sls/user-guide/use-crds-to-collect-container-logs-in-daemonset-mode-1?spm=a2c4g.11186623.0.0.fead7fd7ZmC7Q0
[12] 日志服务计费概述
https://help.aliyun.com/zh/sls/product-overview/billing-overview
[13] 阿里云 Prometheus
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/use-alibaba-cloud-prometheus-service-to-monitor-an-ack-cluster?spm=a2c4g.11186623.0.i5#task-2461398
[14] 可观测监控 Prometheus 版计费概述
https://help.aliyun.com/zh/arms/prometheus-monitoring/product-overview/product-billing-new-version1/
[15] arms 接入中心
https://arms.console.aliyun.com/#/intgr/integrations
[16] kuberay gcs fault toleration config
https://docs.ray.io/en/latest/cluster/kubernetes/user-guides/kuberay-gcs-ft.html#kuberay-external-storage-namespace
[17] gcs fault toleration in kuberay
https://docs.ray.io/en/latest/cluster/kubernetes/user-guides/kuberay-gcs-ft.html#kuberay-gcs-ft
[18] how do you use the ray-client
https://docs.ray.io/en/latest/cluster/running-applications/job-submission/ray-client.html#how-do-you-use-the-ray-client
[19] quick start useing the ray job cli
https://docs.ray.io/en/latest/cluster/running-applications/job-submission/quickstart.html
[20] 弹性伸缩能力
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/auto-scaling-of-nodes?spm=a2c4g.11186623.0.i16#task-1893824
[21] 部署 ACK Virtual Node 组件
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/deploy-the-virtual-node-controller-and-use-it-to-create-elastic-container-instance-based-pods?spm=a2c4g.11186623.0.i2#section-nz6-jj2-383
点击此处,了解 ACK 云原生 AI 套件产品详情。