上一篇文章提出了一个用于笔迹识别(鉴别)的三段式模型,同时也提出了一个新数据集HTID_1,本文主要针对模型的最后一部分--笔迹识别,在HTID_1上进行实验.
数据集
实验前先介绍一下HTID_1.
HTID_1是用于笔迹识别的数据集,是基于本文提出的模型制作而成的.将互联网上收集的740人笔迹原始图片输入模型而制作成的笔迹纹理图.每张纹理图由5*5字组成,每字32*32像素,单张纹理图大小为160*160像素.

数据集分为两部分:训练集和测试集.两部分是互斥的,即训练集中的单字笔迹不会出现在测试集中.其中训练集分为740类,每类100张纹理图,总74,000张;测试集中每人随机生成100~200张纹理图,总111,601张.数据集大小为725MB.
实验
一.验证笔迹识别可行性
前文提到了HTID_0,准确率达到了99%,一定程度上证明了图像分类应用于笔迹识别的有效性,但该数据集可能存在数据泄露,所以制作了HTID_1.
本次实验使用通用的图像分类网络,更倾向于轻量化网络,使用了ResNet、MobileNet、SqueezeNet、ShuffleNet.使用了飞桨PaddlePaddle的模型代码及预训练权重.
实验结果:
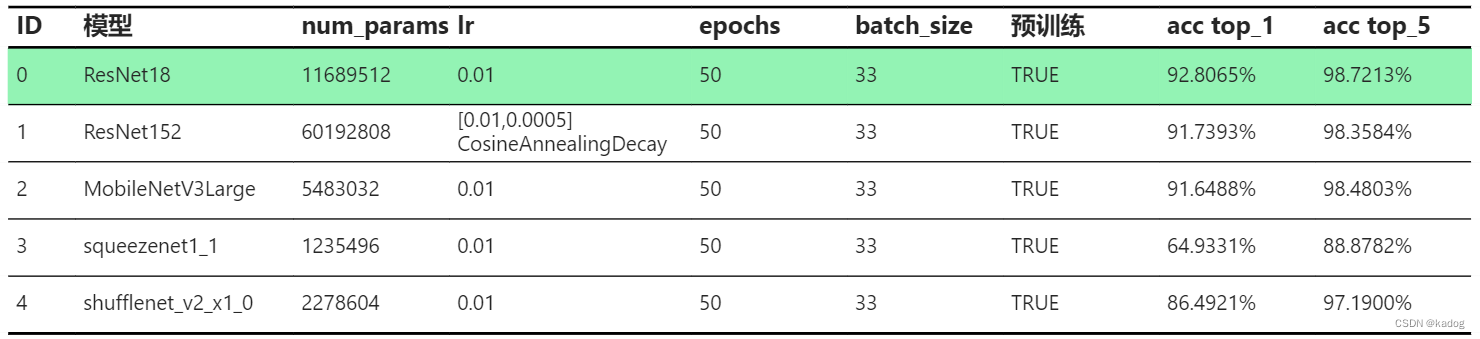
ResNet152因为loss下降的太快了,所有学习率到后面减小一些.
可以看到测试集的top1&5的准确率都挺高的,大部分达到了90%以上,验证了图像分类用于笔迹识别是可行的.
ResNet的参数量比其他模型多了一个数量级,其中ResNet18的准确率最高,但是ResNet152的表现不及18,可能是学习率的问题.
squeezenet是本次实验中参数量最少得,但是准确率也是最低的.
MobileNetV3Large准确率与ResNet152相近,考虑到训练成本,后续的实验将使用MobileNetV3Large
二.数据增强
本次实验主要有两种数据增强:
BW
随机添加黑白噪声.
这种方法需要消耗大量的CPU,需要核心比较多,否则训练很慢.
RE
将单张纹理图内的25个字重新随机排序.
本次实验将以上面实验中的MobileNetV3Large作为基础,在该基础上继续训练,对训练集使用数据增强.增强方式如下:
ID 5: 训练集中每张图片有0.8的概率增加随机黑白噪声,增加的黑白噪声数量为当前图像总像素的10%~30%(随机比例,黑白也是随机的).
ID 6: 训练集的每张图片都应用RE.
ID 7: 先应用和ID5相同的BW,再应用RE.
实验结果如下:

3种方式的准确率都有提高,说明数据增强是有效的.但是BW的提升不明显,top_1只增加了0.24%,而RE的top1增加了1.24%.BW和RE一起使用时准确率也有提高,但更像是BW给RE添加了一些削弱效果.
三.单字位置影响
数据集中的纹理图每个单字的位置都是随机的,按照CNN的平移不变性,即使单字位置换了,输出的结果也相同.本次实验将使用ID 6的模型,对测试集的每张图片进行RE,然后进行推理(只推理不训练).
实验结果:

6_0是为了验证加载权重是否正确.
可以看到测试集的top1基本保持在92.8%附近,top5在98.7%附近.误差小于0.1%,可认为单字位置对预测结果不产生主要影响,影响可以忽略.
四.单字个数
在真实场景中,获取的笔迹检材的字数是不确定的.为了探索这种不确定性对结果的影响,设计了本次实验:更换测试集,纹理图仍保留5*5字,从测试集字库中随机抽取单字,构成单字为1~25的25个测试集,当纹理图内非重复单字不足25字时,使用当前纹理图内的单字进行随机填充.每个人生成25张图片.每个新测试集有18500张纹理图.使用ID 6和ID 0对这25个测试集进行推理.

实验结果:
|
|
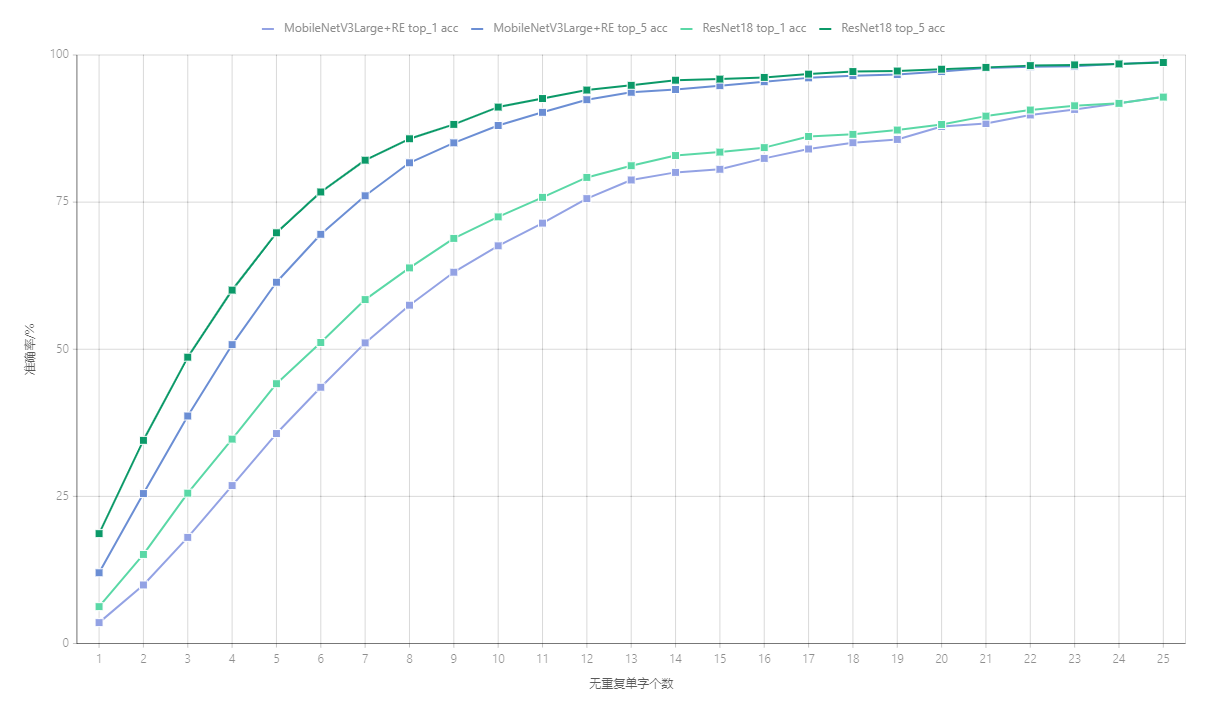
从结果上看ResNet18还是要比MobileNetV3Large强的.两个模型呈现的趋势都是随着无重复单字个数减少准确率减低,接近于log函数.字数越少准确率下降越快.
MobileNetV3Large在14个无重复单字时top1准确率还有80%,top5在11个单字时还有90%.
ResNet18在13个单字时top1为81%,top5在10个单字时还有91%.
所有要保障可用性,单张纹理图内至少需要有10~15个无重复单字.
五.噪声污染
噪声有多种来源,比如墨水溅落、年代久远导致的纸张损坏字迹不清、虫子的尸体粪便等非模型因素,还有就是模型的因素,如对非笔迹像素擦除不完整,擦除时对笔迹造成了损坏,切割单字时对笔迹造成了损坏.这些都影响推理的结果.本次实验考虑一种理想的噪声污染,不考虑单字位置的影响,每张纹理图使用25个无重复单字,对纹理图进行随机黑白噪声填充,填充比例为单图总像素的5%~50%(步长5%),每个比例创建一个新测试集,每个测试集8500张纹理图.

50%的噪声人眼已经无法识别笔迹(眯眼睛或者缩小图片可以看清楚一些),所以再大的噪声比例不进行测试.
使用ID 5 MobileNetV3Large+BW和ID 6 MobileNetV3Large+RE进行推理.
实验结果:
|
|
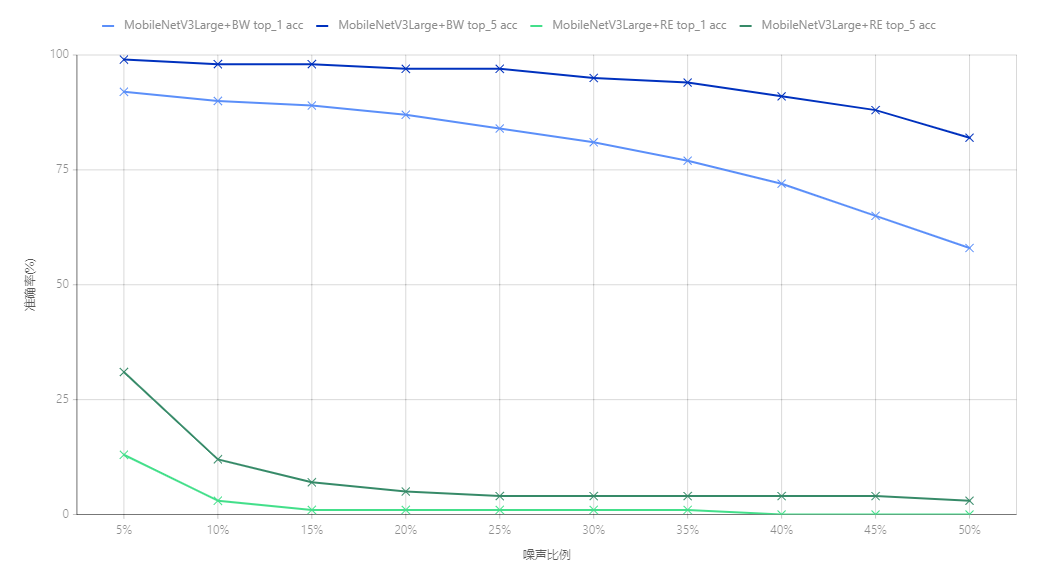
可以清楚地看到两个模型呈现两级分化的情况,未经过BW数据训练的ID 6根本无法承受噪声攻击(即使是5%的噪声).这也就引出了鲁棒性问题了,如果单纯使用训练集训练是无法抵抗噪声污染的,当检材多了一些水渍、墨水时模型将会作废.而在训练时主动加入噪声污染,在损失极小的正常图片准确率时,能大幅提高被污染后的推理准确率.在噪声到达30%时,ID 5依旧有81%的top1准确率,top5为95%.
所以要增加模型的鲁棒性,在不修改模型结构的情况下,要对训练集进行BW数据增强.
六.极限
前面的实验都是在训练参数相同的情况下进行的,本次实验主要目的是探索现有模型在HTID_1上能达到的最好准确率是多少.
这里只使用了一个专门应用于笔迹识别的网络GR-RNN[1],全称为"用于书写者识别的全局上下文残差递归神经网络",他的网络引入了GRU.
同时也使用一些通用的图像分类网络,ConvNeXt[2],Inception-ResNet[3],PNASNet5[4],UniRepLKNet[5].
实验结果:
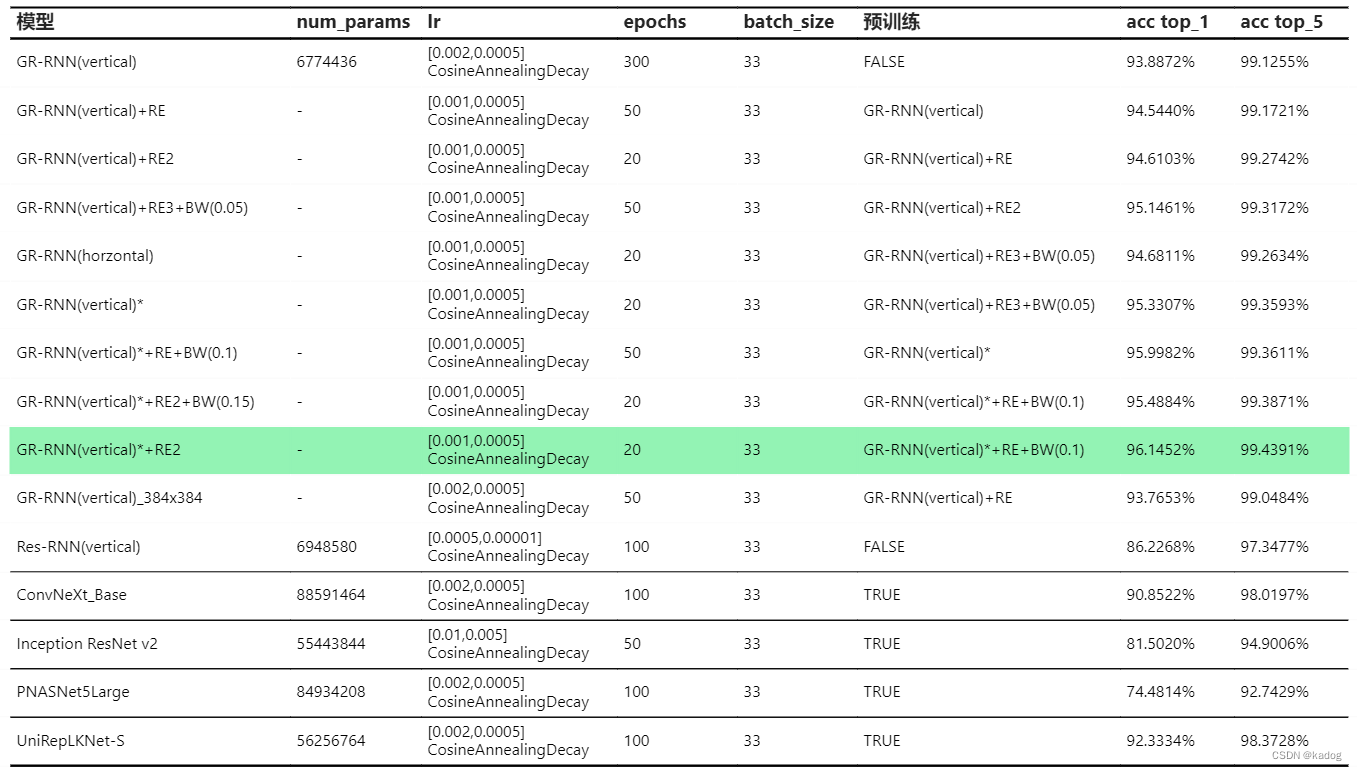
GR-RNN(vertical) top1 起步是93.8872%,后面在图像增强继续训练下达到了96.1452%.相比之下horzontal结果比vertical差一些,差了0.6496%,当前情况下vertical更适合.
GR-RNN(vertical)_384x384是图像放大到384*384像素,结果变差了,猜测是因为以RGB形式加载图片,放大算法添加了一些过渡像素让新笔迹图片变模糊了,原本棱角分明的笔画被圆滑了.

可能用位图效果会好一些.

Res-RNN(vertical)是基于GR-RNN魔改的网络,加了残差块,效果不如GR-RNN(vertical).
剩下几个模型表现都一般,UniRepLKNet-S表现好一些,可能这些模型需要大型数据集进行训练.
测试就进行到这里了,在HTID_1上最好结果是top1 96.1452%,top5 99.4391%
参考文献
[1]S. He and L. Schomaker, “GR-RNN: Global-Context Residual Recurrent Neural Networks for Writer Identification,” arXiv.org, 2021. Available: https://arxiv.org/abs/2104.05036.
[2]Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A ConvNet for the 2020s,” arXiv.org, 2020. Available: https://arxiv.org/abs/2201.03545.
[3]C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi, “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning,” arXiv.org, 2016. Available: https://arxiv.org/abs/1602.07261v2.
[4]C. Liu et al., “Progressive Neural Architecture Search,” arXiv.org, 2017. Available: https://arxiv.org/abs/1712.00559v3.
[5]X. Ding et al., “UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition,” arXiv.org, 2023. Available: https://arxiv.org/abs/2311.15599. [Accessed: Jan. 29, 2024]






![[C#][opencvsharp]winform实现自定义卷积核锐化和USM锐化](https://img-blog.csdnimg.cn/direct/a7dff0c0bf88402c914b51a8509963b6.jpeg)