文章目录
- 7.1 文本数据的基本操作
- 7.1.1 基础知识
- 7.1.2 重点案例:客户反馈分析
- 7.1.3 拓展案例一:产品评论的关键词提取
- 7.1.4 拓展案例二:日志文件中的日期提取
- 7.2 使用正则表达式处理文本
- 7.2.1 基础知识
- 7.2.2 重点案例:日志文件错误类型提取
- 7.2.3 拓展案例一:提取电子邮件地址
- 7.2.4 拓展案例二:从文本中提取日期
- 7.3 类别数据的处理
- 7.3.1 基础知识
- 7.3.2 重点案例:顾客满意度调查分析
- 7.3.3 拓展案例一:产品评价分类
- 7.3.4 拓展案例二:员工信息管理
7.1 文本数据的基本操作
处理文本数据是数据预处理中的一个重要环节,它包括了一系列的操作,如清洗、分割、替换等,旨在从原始文本中提取有用信息或将其转换为更适合分析的格式。
7.1.1 基础知识
- 字符串操作: 包括大小写转换、分割(split)、连接(join)、替换(replace)等。
- 去除无用字符: 如去除空格、标点符号等。
- 提取特定信息: 使用字符串操作或正则表达式来提取文本中的特定信息。
7.1.2 重点案例:客户反馈分析
假设你有一份客户反馈的文本数据,需要进行初步的文本清洗和关键信息提取。
数据准备
# 示例客户反馈文本数据
feedback_data = [
"Great product! I've been using it for a month and very satisfied.",
"The item did not meet my expectations and arrived late.",
"Excellent service, fast shipping.",
"Product was damaged. Terrible experience!"
]
feedback_df = pd.DataFrame(feedback_data, columns=['feedback'])
文本数据处理
# 转换为小写
feedback_df['feedback'] = feedback_df['feedback'].str.lower()
# 去除标点符号
feedback_df['feedback'] = feedback_df['feedback'].str.replace('[^\w\s]', '', regex=True)
# 提取包含特定关键词的反馈
positive_feedback = feedback_df[feedback_df['feedback'].str.contains('great|excellent')]
negative_feedback = feedback_df[feedback_df['feedback'].str.contains('not|damaged|terrible')]
7.1.3 拓展案例一:产品评论的关键词提取
分析一份产品评论数据,提取出每条评论中的关键产品特性词汇。
数据准备
# 示例产品评论数据
product_reviews = [
"The camera quality is outstanding, but the battery life is short.",
"Amazing battery performance, but the images are not very clear."
]
reviews_df = pd.DataFrame(product_reviews, columns=['review'])
关键词提取
# 提取评论中的关键词
keywords = ['camera', 'battery', 'images']
for keyword in keywords:
reviews_df[keyword] = reviews_df['review'].str.contains(keyword).astype(int)
7.1.4 拓展案例二:日志文件中的日期提取
假设你有一份服务器日志文件,需要从每条日志中提取日期信息。
数据准备
# 示例日志数据
log_entries = [
"2023-01-01 12:34:56: User logged in",
"2023-01-02 13:14:16: User logged out",
"2023-01-03 15:04:26: System error occurred"
]
log_df = pd.DataFrame(log_entries, columns=['log'])
日期提取
# 提取日志中的日期
log_df['date'] = log_df['log'].str.extract('(^\d{4}-\d{2}-\d{2})')
通过这些案例,我们展示了如何进行文本数据的基本操作,包括清洗文本、提取关键信息,以及从日志文件中提取日期。这些操作为深入分析文本数据打下了坚实的基础。

7.2 使用正则表达式处理文本
正则表达式是一种强大的文本处理工具,它允许我们进行复杂的搜索、匹配、替换等操作,非常适用于处理那些结构复杂或格式不统一的文本数据。
7.2.1 基础知识
- 正则表达式基本概念: 正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
- 常用符号: 包括特殊字符(如
.、*、+、?、[]、())和转义字符(如\d、\w、\s等)。 - 匹配和搜索: 使用正则表达式进行模式匹配和搜索特定模式的文本。
- 替换: 使用正则表达式替换文本中的特定部分。
7.2.2 重点案例:日志文件错误类型提取
假设你有一份应用程序的日志文件,需要从中提取出所有错误类型。
数据准备
import pandas as pd
# 示例日志数据
log_entries = [
"ERROR: Invalid user input at 2023-01-01 12:34",
"WARNING: System overload at 2023-01-02 13:14",
"ERROR: Disk full at 2023-01-03 15:04"
]
logs_df = pd.DataFrame(log_entries, columns=['log'])
错误类型提取
# 使用正则表达式提取错误类型
logs_df['error_type'] = logs_df['log'].str.extract('(ERROR|WARNING)')
7.2.3 拓展案例一:提取电子邮件地址
处理一份含有用户反馈的文本数据,需要从中提取出所有电子邮件地址。
数据准备
# 示例用户反馈数据
feedbacks = [
"Please contact us at support@example.com",
"You can also reach out to feedback@example.net for more info."
]
feedback_df = pd.DataFrame(feedbacks, columns=['text'])
电子邮件地址提取
# 使用正则表达式提取电子邮件地址
feedback_df['email'] = feedback_df['text'].str.extract('([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)')
7.2.4 拓展案例二:从文本中提取日期
假设你正在处理一份报告文档,需要从文本中提取所有的日期信息。
数据准备
# 示例报告文档数据
reports = [
"The project started on 2023-01-10 and is expected to end by 2023-04-15.",
"Our next meeting will be on 2023-02-20."
]
reports_df = pd.DataFrame(reports, columns=['text'])
日期提取
# 使用正则表达式提取日期
reports_df['date'] = reports_df['text'].str.extract('(\d{4}-\d{2}-\d{2})')
通过这些案例,我们展示了如何使用正则表达式在文本数据处理中进行模式匹配、搜索、和替换操作。无论是提取日志文件中的错误类型、从反馈中提取电子邮件地址,还是从报告文档中提取日期信息,正则表达式都是一个强大而灵活的工具。

7.3 类别数据的处理
类别数据处理是数据预处理中的重要环节,特别是在准备数据以供机器学习模型使用时。类别数据通常指的是可以将其分为不同类别的非数值型数据。
7.3.1 基础知识
- 标签编码(Label Encoding): 将类别转换为一组数字,每个类别对应一个唯一的整数。
- 独热编码(One-Hot Encoding): 创建新的列,每个列对应一个类别,如果数据属于该类别,则列值为1,否则为0。
- Pandas 的
Categorical类型: 用于提高处理类别数据的效率和性能。 - 使用
pd.get_dummies()进行独热编码: 一个简便的方法来转换类别数据为独热编码格式。
7.3.2 重点案例:顾客满意度调查分析
假设你有一份顾客满意度调查数据,其中包含顾客对服务满意度的评价(如“满意”,“不满意”,“中立”)。
数据准备
import pandas as pd
# 示例顾客满意度调查数据
satisfaction_data = {
'customer_id': [1, 2, 3, 4],
'satisfaction': ['满意', '不满意', '满意', '中立']
}
satisfaction_df = pd.DataFrame(satisfaction_data)
类别数据处理
# 将满意度转换为类别类型
satisfaction_df['satisfaction'] = pd.Categorical(satisfaction_df['satisfaction'], categories=['不满意', '中立', '满意'])
# 使用独热编码
satisfaction_encoded = pd.get_dummies(satisfaction_df, columns=['satisfaction'])
7.3.3 拓展案例一:产品评价分类
分析一份产品评价数据,需要将文本评价转换为数值型标签以便进行进一步分析。
数据准备
# 示例产品评价数据
reviews_data = {
'review_id': [101, 102, 103, 104],
'review': ['positive', 'negative', 'positive', 'neutral']
}
reviews_df = pd.DataFrame(reviews_data)
类别数据处理
# 将评价转换为数值型标签
reviews_df['review_label'] = reviews_df['review'].astype('category').cat.codes
7.3.4 拓展案例二:员工信息管理
假设你正在处理一份员工信息表,其中包含员工的部门信息,你需要对部门信息进行独热编码以便进行聚类分析。
数据准备
# 示例员工信息数据
employees_data = {
'employee_id': ['E001', 'E002', 'E003', 'E004'],
'department': ['HR', 'Tech', 'HR', 'Marketing']
}
employees_df = pd.DataFrame(employees_data)
类别数据处理
# 对部门信息进行独热编码
department_encoded = pd.get_dummies(employees_df, columns=['department'])
通过这些案例,我们展示了如何处理类别数据,包括标签编码、独热编码以及利用 Pandas 的 Categorical 类型。这些方法在准备数据进行机器学习模型训练时尤为重要,能够有效地将非数值型数据转换成模型可以理解的格式。
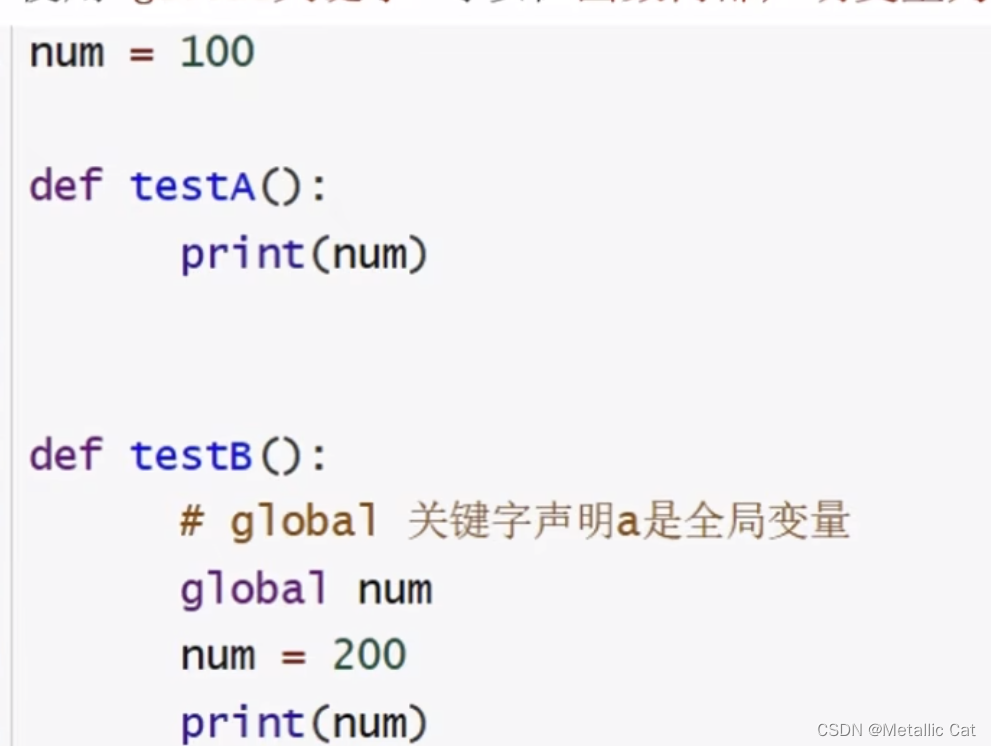



![[NOIP2011 提高组] 聪明的质监员](https://img-blog.csdnimg.cn/direct/d674fd8805504449be7207dd707f96ee.png)