文章目录
- 一、Buffer模块
- 1.为什么需要Buffer缓冲区
- 2.Buffer模块的设计
- 3.Buffer模块的实现
- 4.Buffer缓冲区的其它设计方案
- 二、Socket模块
- 1.Socket模块的设计
- 2.Socket代码实现
- 三、Acceptor模块
- 1.Acceptor模块的设计与实现
- 2.Acceptor模块完整代码实现
- 四、定时器模块
- 1.时间轮的思想
- 2.TimerTask类
- 3.TimerWheel类
- 五、线程池模块
- 1.LoopThread类
- 2.LoopThreadPool类
一、Buffer模块
1.为什么需要Buffer缓冲区
我们实现的TCP网络服务器必须要有发送缓冲区和接收缓冲区,这一点是毋庸置疑的。考虑以下两种情况:
- 如果服务器没有发送缓冲区,那么当服务器想向客户端发送假设100KB的数据时,调用操作系统的write接口进行发送。但是如果操作系统(准确来说是操作系统的缓冲区)只接收了80KB,我们服务器还有20KB的数据没有发送出去,这个时候只能阻塞在write接口处等待最后20KB数据发送出去。如果有了发送缓冲区,我们就能将这20KB的数据再放回发送缓冲区,等什么时候操作系统缓冲区能接收新数据了再进行第二次发送。
- 如果服务器没有接收缓冲区,由于TCP是面向字节流的协议,也就是说它的数据报文是没有明显边界的,那么就可能会出现一次接收的数据不完整或者数据粘包的问题,这时候我们拿到不完整的数据既不能解析,也不能丢弃,只有接收缓冲区,能让我们缓存这些不完整的数据报文,等到下一次对方再发送新数据的时候,我们读取到完整的报文时再交给上层进行业务处理。
这两个简单常见的例子就足以说明,TCP服务器必须要有Buffer缓冲区。
2.Buffer模块的设计
muduo库的作者陈硕老师在《Linux多线程服务端编程:使用muduo C++网络库》书中提到,muduo Buffer的设计考虑了常见的网络编程需求,他试图在易用性和性能之间找一个平衡点,目前这个平衡点更偏向于易用性。所以muduo库的Buffer设计要点如下:
- 对外表现是一块连续的内存空间,这样更方便代码的编写。
- Buffer缓冲区的空间大小是可变的,支持动态扩容,以适应不同大小的消息。
- 虽然服务器需要接收缓冲区和发送缓冲区,但我们不希望分开两个缓冲区来写,而是希望一块内存空间既能读也能写,做到读写配合。
从连续的内存空间、支持动态扩容这两个要点来看,Buffer缓冲区底层的数据结构应该选择vector最合适。并且还需要两个index分别代表读位置和写位置,这样就能满足一块内存空间的读写配合。有个细节的地方需要注意,读位置和写位置的index不应该设置为指针类型或者迭代器类型,最好使用下标来表示,因为vector如果需要扩容将数据拷贝到新空间,会出现迭代器失效的情况,需要我们去处理迭代器失效,从易用性角度考虑,使用下标是最好的。
确定了Buffer的数据结构以后,我们可以很容易地想象出Buffer的结构图如下图所示:
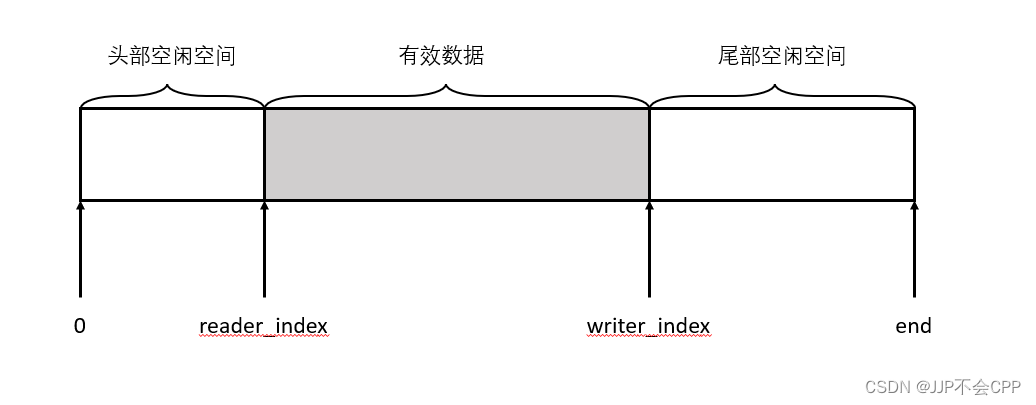
通过起始位置、读位置(reader_index)、写位置(writer_index)、末尾位置,我们可以将Buffer分成三部分:
- 读位置之前的空间,即起始位置和读位置之间的空间,我们称为头部空闲空间;
- 读位置和写位置之间的空间,我们称为有效数据。这部分存放的就是可读数据;
- 写位置之后的空间,即写位置和末尾位置之间的空间,我们称为尾部空闲空间。
划分完成之后,Buffer缓冲区的读写数据方式会变得非常清晰。读位置和写位置之间的空间,就是有效数据区域,也就是可读数据。当我们要从Buffer缓冲区中读取数据时,从读位置(reader_index)开始向后读取指定的字节,读取完以后再将读位置(reader_index)向后移动读取的字节数。写入也是同理,当我们要向Buffer缓冲区中写入数据时,从写位置(writer_index)开始向后写入指定的字节,写入完以后再将写位置(writer_index)向后移动写入的字节数。当读位置(reader_index)和写位置(writer_index)相遇的时候,说明缓冲区已经没有可读数据了。
如果写位置(writer_index)一直写入到末尾位置,尾部空闲空间不够写入怎么办?
Buffer模块是支持动态扩容的,当我们向Buffer缓冲区写入指定字节的数据时,它先会去检查尾部空闲空间能不能容纳这些字节的数据,如果不能,再将头部空闲空间加入进来,判断尾部空闲空间加上头部空闲空间是否能够容纳,如果可以的话,就将可读数据挪动到起始位置,更新读位置(reader_index)和写位置(writer_index)后再写入新数据,例如下列示意图:
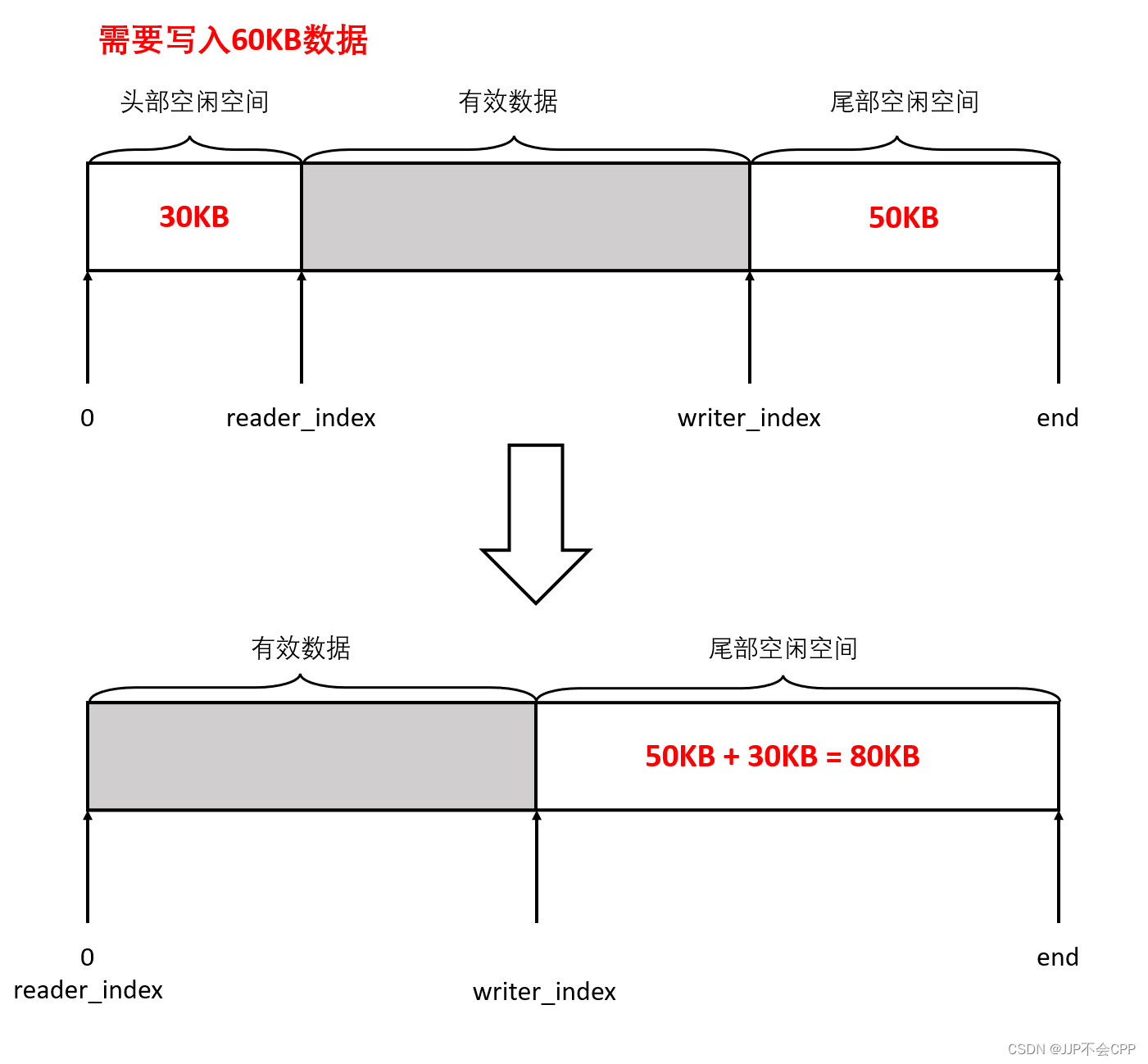
如果尾部空闲空间加上头部空闲空间都不够写入,那就只能从写位置(writer_index)开始向后扩容了。需要注意的是,扩容之后的Buffer并不会缩小空间大小,比如扩容到1000字节的大小,下一次写入比1000字节小的数据也不会重新开辟分配空间。也就是说,muduo库的Buffer缓冲区空间大小是自适应的,比如一开始空间大小是1KB,程序经常收发10KB的数据,那么用了几次之后它的空间大小会自动增长到10KB,然后就保持不变。这样做的好处是:一方面避免浪费内存,即一开始不会开很大的空间,而是不够了再去扩容。另一方面是避免反复分配内存,扩容之后申请了多大的内存空间就保持不变了,只会扩大不会缩小,因为分配内存也是需要时间开销的。
3.Buffer模块的实现
有了上述的设计思路以后,我们实现一个Buffer模块并不是什么难事,这里直接把代码贴出来了。我写这些文章的目的是记录每个模块的设计思路以及细节,学习muduo库设计的高性能高并发版本服务器,所以代码实现并不是最重要的,思路更重要,这些简单代码就不过多介绍浪费篇幅了。
#define BUFFER_DEFAULT_SIZE 1024
class Buffer
{
public:
Buffer()
: _reader_index(0), _writer_index(0), _buffer(BUFFER_DEFAULT_SIZE)
{
}
// 获取当前写入起始地址
char *getWriteStartPosition()
{
// buffer空间的起始地址加上写偏移量
return begin() + _writer_index;
}
// 获取当前读取起始地址
char *getReadStartPosition()
{
return begin() + _reader_index;
}
// 获取缓冲区末尾空间大小--写偏移之后的空闲空间
uint64_t getTailSpaceSize()
{
// 整体空间大小减去写偏移
return _buffer.size() - _writer_index;
}
// 获取缓冲区起始空间大小--读偏移之前的空闲空间
uint64_t getHeadSpaceSize()
{
return _reader_index;
}
// 获取可读数据大小
uint64_t getReadableSize()
{
return _writer_index - _reader_index;
}
// 将读偏移向后移动
void moveReadOffset(uint64_t len)
{
if(len == 0)
{
return;
}
assert(len <= getReadableSize());
_reader_index += len;
}
// 将写偏移向后移动
void moveWriteOffset(uint64_t len)
{
assert(len <= getTailSpaceSize());
_writer_index += len;
}
// 确保可写空间足够(整体空闲空间够了就移动数据,否则就扩容)
void ensureWriteSpace(uint64_t len)
{
// 如果末尾空闲空间大小足够,直接返回
if (len <= getTailSpaceSize())
{
return;
}
// 如果末尾空闲空间不够,则判断加上起始空闲空间大小是否足够,够的话就将数据到起始位置
else if (len <= getHeadSpaceSize() + getTailSpaceSize())
{
uint64_t readAbleSize = getReadableSize();
std::copy(getReadStartPosition(), getReadStartPosition() + readAbleSize, begin());
_reader_index = 0;
_writer_index = readAbleSize;
}
else
{
// 扩容
_buffer.resize(_writer_index + len);
}
}
// 写入数据
void write(const void *data, uint64_t len)
{
// 1.保证有足够空间 2.拷贝数据进行
if(len == 0)
{
return;
}
ensureWriteSpace(len);
const char *chardata = (const char *)data;
std::copy(chardata, chardata + len, getWriteStartPosition());
}
void writeAndPush(const void *data, uint64_t len)
{
write(data, len);
moveWriteOffset(len);
}
void writeFromString(const std::string &data)
{
write(data.c_str(), data.size());
}
void writeStringAndPush(const std::string &data)
{
writeFromString(data);
moveWriteOffset(data.size());
}
void writeFromBuffer(Buffer &data)
{
write(data.getReadStartPosition(), data.getReadableSize());
}
void writeBufferAndPush(Buffer &data)
{
writeFromBuffer(data);
moveWriteOffset(data.getReadableSize());
}
// 读取数据
void read(void *buf, uint64_t len)
{
// 要求要获取的数据大小必须小于可读数据大小
assert(len <= getReadableSize());
std::copy(getReadStartPosition(), getReadStartPosition() + len, (char *)buf);
}
void readAndPop(void *buf, uint64_t len)
{
read(buf, len);
moveReadOffset(len);
}
std::string readAsString(uint64_t len)
{
assert(len <= getReadableSize());
std::string str;
str.resize(len);
read(&str[0], len);
return str;
}
std::string readAsStringAndPop(uint64_t len)
{
assert(len <= getReadableSize());
std::string str = readAsString(len);
moveReadOffset(len);
return str;
}
// 寻找换行字符
char *findCRLF()
{
char *findRes = (char *)memchr(getReadStartPosition(), '\n', getReadableSize());
return findRes;
}
std::string getLine()
{
char *pos = findCRLF();
if (pos == nullptr)
{
return "";
}
return readAsString(pos - getReadStartPosition() + 1);
}
std::string getLineAndPop()
{
std::string str = getLine();
moveReadOffset(str.size());
return str;
}
// 清空缓冲区
void clear()
{
_reader_index = 0;
_writer_index = 0;
}
private:
char *begin()
{
return &(*_buffer.begin());
}
private:
std::vector<char> _buffer; // 使用vector进行内存空间管理
uint64_t _reader_index; // 读偏移
uint64_t _writer_index; // 写偏移
};
4.Buffer缓冲区的其它设计方案
其实在刚开始学习muduo库的Buffer缓冲区时,我很好奇为什么会选择vector这个数据结构作为缓冲区的底层数据结构呢?要知道vector的优势在于连续性,但是插入和删除的时间复杂度都是比较高的,因为vector的插入和删除会涉及到很多数据挪动,时间复杂度往往都是O(N^2)级别的。而muduo库不是高性能的网络版本服务器吗?怎么还会用这种低效的方式呢?我一开始以为会是什么复杂的高深的数据结构来实现,将时间复杂度降到最低,毕竟服务器不就是追求性能和效率吗?
其实这个问题的答案作者在书中已经给我们解答了,还记得文章开始我们介绍过,作者陈硕老师在《Linux多线程服务端编程:使用muduo C++网络库》书中提到:“muduo Buffer的设计考虑了常见的网络编程需求,试图在易用性和性能之间找一个平衡点,目前这个平衡点更偏向于易用性”。所以选择vector作为Buffer的存储结构是因为偏向易用性,为了让代码实现以及muduo库组件的使用都更简单方便。
作者在书中也提供了其它几种设计方案,感兴趣的读者可以去翻阅一下这本书。其中最高效的方案应该是zero copy方案,该方案是实现分段连续的zero copy buffer。这个方案虽然使得服务器性能更好更高效,但代价就是代码实现变得复杂,晦涩难懂。并且由于Buffer缓冲区不是连续的,parse消息会变得比较麻烦。
那么为什么muduo库的Buffer选择偏向易用性而不是偏向高性能呢?
其实我们都可以发现,muduo库的Buffer模块有很多可以优化从而提高效率的地方。那么我们可能会怀疑,muduo库的性能会不会太低了?作者给出的解释是:“可以优化,但不一定值得优化”。
目前最常用的千兆以太网的吞吐量基本都是几百兆每秒,而现在服务器上最常用的DDR2/DDR3内存的带宽至少是4GB/s,比千兆以太网高40倍以上。也就是说,对于Buffer缓冲区中几KB或几十KB大小的数据,在内存中复制几次根本不是问题,因为受千兆以太网延迟和带宽的限制,跟这个程序通信的其他机器上的程序不会察觉到性能差异。
再比如说,如果我们的服务器上层应用需要和数据库打交道,那么性能瓶颈往往出现在数据库的数据交互上,提高服务器本身的这点性能,尤其是Buffer缓冲区模块的这一点点性能提升,对整个程序本身的优化是微不足道的,因为从数据库中读取一次数据往往就抵消了Buffer模块所做的所有低等级优化,这时还不如把精力放在DB调优上。
所以muduo库的Buffer模块可以优化,但优化的意义往往不大,因为这些性能提升往往是微不足道的。如果确实在内存带宽方面遇到问题,或者确实有性能的需要,可以考虑将Buffer模块改写为zero copy方案,甚至可以考虑将程序放到Linux内核中去,而不是在用户态尝试各种优化。因为只有把程序做到操作系统内核才能真正实现zero copy,否则内核态和用户态之间始终有一次内存拷贝。
二、Socket模块
1.Socket模块的设计
Socket模块是封装了socket套接字操作,也就是将Linux的那一套TCP socket套接字操作封装成一个Socket类,这个类比较简单,需要的功能有以下几个:
- 创建套接字,即封装socket创建套接字函数操作。
- 绑定地址信息,即封装bind函数操作。
- 设置开始监听,即封装listen函数操作。
- 设置客户端发起连接请求,即封装connect函数操作。
- 获取新连接,即封装accept函数操作。
- 接收数据,即封装recv函数操作。
- 发送数据,即封装send函数操作。
- 最后提供创建服务器连接接口和创建客户端连接接口。
2.Socket代码实现
#define MAX_LISTEN 1024
class Socket
{
public:
Socket()
: _sockFd(-1)
{
}
Socket(int fd)
: _sockFd(fd)
{
}
~Socket()
{
closeSocket();
}
// 创建套接字
bool createSocket()
{
_sockFd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if (_sockFd < 0)
{
LOG("create socket error");
return false;
}
return true;
}
// 绑定地址信息
bool bindSocket(const std::string &ip, uint16_t port)
{
sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = ip.size() == 0 ? INADDR_ANY : inet_addr(ip.c_str());
socklen_t len = sizeof(sockaddr_in);
int bindRes = bind(_sockFd, (sockaddr *)&addr, len);
if (bindRes < 0)
{
LOG("bind error");
return false;
}
return true;
}
// 开始监听
bool listenSocket(int backlog = MAX_LISTEN)
{
int listenRes = listen(_sockFd, backlog);
if (listenRes < 0)
{
LOG("listen error");
return false;
}
return true;
}
// 向服务器发起连接
// 这个接口是给客户端向服务端发起连接请求的
bool connectSocket(const std::string &ip, uint16_t port)
{
sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(port);
addr.sin_addr.s_addr = inet_addr(ip.c_str());
socklen_t len = sizeof(sockaddr_in);
int connectRes = connect(_sockFd, (sockaddr *)&addr, len);
if (connectRes < 0)
{
LOG("connect error");
return false;
}
return true;
}
// 获取新连接
int acceptConnect()
{
int newFd = accept(_sockFd, nullptr, nullptr);
if (newFd < 0)
{
LOG("accept error");
return -1;
}
return newFd;
}
// 接收数据
ssize_t recvData(void *buf, size_t len, int flag = 0)
{
ssize_t recvRes = recv(_sockFd, buf, len, flag);
if (recvRes <= 0)
{
if (errno == EAGAIN || errno == EINTR)
{
return 0;
}
LOG("recv error");
return -1;
}
return recvRes;
}
ssize_t nonBlockRecv(void *buf, size_t len)
{
return recvData(buf, len, MSG_DONTWAIT);
}
// 发送数据
ssize_t sendData(const void *buf, size_t len, int flag = 0)
{
ssize_t sendRes = send(_sockFd, buf, len, flag);
if (sendRes < 0)
{
if (errno == EAGAIN || errno == EINTR)
{
return 0;
}
LOG("send error");
return -1;
}
return sendRes;
}
ssize_t nonBlockSend(void *buf, size_t len)
{
if (len == 0)
{
return 0;
}
return sendData(buf, len, MSG_DONTWAIT);
}
// 关闭套接字
void closeSocket()
{
if (_sockFd != -1)
{
close(_sockFd);
_sockFd = -1;
}
}
// 创建一个服务端连接
// 这个函数接口是服务端调用的,用来创建一个服务端连接
bool createServer(uint16_t port, const std::string &ip = "", bool blockFlag = false)
{
if (createSocket() == false)
{
return false;
}
if (bindSocket(ip, port) == false)
{
return false;
}
if (listenSocket() == false)
{
return false;
}
if (blockFlag)
{
nonBlock();
}
reuseAddress();
return true;
}
// 创建一个客户端连接
bool createClient(uint16_t port, const std::string &ip)
{
if (createSocket() == false)
{
return false;
}
if (connectSocket(ip, port) == false)
{
return false;
}
return true;
}
// 设置套接字选项---开启地址端口重用
void reuseAddress()
{
int val = 1;
setsockopt(_sockFd, SOL_SOCKET, SO_REUSEADDR, (void *)&val, sizeof(int));
val = 1;
setsockopt(_sockFd, SOL_SOCKET, SO_REUSEPORT, (void *)&val, sizeof(int));
}
// 设置套接字阻塞属性---设置为非阻塞
void nonBlock()
{
int flag = fcntl(_sockFd, F_GETFL, 0);
fcntl(_sockFd, F_SETFL, flag | O_NONBLOCK);
}
int getSocketFd()
{
return _sockFd;
}
private:
// socket创建的套接字
int _sockFd;
};
三、Acceptor模块
1.Acceptor模块的设计与实现
Acceptor模块就是主Reactor获取新连接的模块,它与主Reactor关联,由最顶层的TcpServer模块将它与EventLoop模块关联起来,这个模块比较简单,我们可以通过设计与实现来了解该模块的原理以及功能。首先看一下Acceptor的类内成员变量:
- _socket:该变量用于创建服务器,我们上面已经封装了Socket类,所以可以通过_socket这个变量快速地调用Socket类接口,通过socket套接字操作搭建服务器。
- _eventLoop:该变量就是主Reactor,只负责监控新连接的到来。
- _channel:该变量是主Reactor的事件管理类变量。
- _acceptCallBack:该变量是新连接到来以后执行的回调函数,这个回调函数由外部设置,Acceptor类负责调用。
private:
Socket _socket;// 用于创建监听套接字
EventLoop *_eventLoop;// 用于对监听套接字进行事件监控
Channel _channel;// 用于对监听套接字进行事件管理
AcceptCallBack _acceptCallBack;
接下来是Acceptor类的构造函数,构造函数初始化主Reactor以及创建服务器,同时设置主Reactor可读事件触发的回调函数。
// 不能将启动读事件监控放到构造函数中,必须在设置回调函数之后,再去启动
// 否则有可能造成启动监控后,立即有事件到来了,但是处理的时候回调函数还没设置,所以新连接得不到处理,并且资源泄露
Acceptor(EventLoop *eventLoop, uint16_t port)
:_eventLoop(eventLoop), _socket(createServer(port)), _channel(eventLoop, _socket.getSocketFd())
{
_channel.setReadAbleCallBack(std::bind(&Acceptor::handleRead, this));
}
构造函数里设置的主Reactor可读事件触发回调函数是handleRead函数,这个函数也是Acceptor类内成员函数,该函数首先是调用accept函数操作,获取新连接。因为TCP服务器的套接字操作步骤是,socket创建套接字、bind绑定地址信息、listen设置监听状态,最后accept获取连接。当有连接到来的时候,进程会从accept函数调用处返回,返回以后,handleRead函数再去调用外部设置的新连接到来触发的回调函数,即调用成员变量_acceptCallBack。
// 监听套接字的读事件回调函数---获取新连接,调用_acceptCallBack函数进行新连接处理
void handleRead()
{
int newFd = _socket.acceptConnect();
if(newFd < 0)
{
return;
}
if(_acceptCallBack)
{
_acceptCallBack(newFd);
}
}
事实上这个_acceptCallBack是由TcpServer模块设置的,这一整条链路的逻辑是这样的:Acceptor构造函数初始化_socket时调用createServer函数创建服务器,createServer函数只会执行socket创建套接字、bind绑定地址信息、listen设置监听状态的操作,并不会调用accept获取连接,因为accept函数如果没有连接到来的话是会让线程或进程阻塞的。Acceptor构造函数设置的主Reactor的可读事件回调函数是handleRead,这个handleRead函数只会在可读事件触发时被调用,主Reactor的可读事件只会在新连接到来时触发。所以当有新连接到来时,主Reactor的可读事件触发,调用handleRead函数执行。
我们再来看看handleRead函数内部执行了什么,首先是调用accept函数获取连接,也就是说这种写法不用进程或线程阻塞在accept函数调用处等待连接的到来,而是当连接到来的时候,以可读事件触发的形式调用handleRead函数去执行accept获取连接,这一次获取连接是不需要等待就能获取成功的,所以接下来可以执行外部设置的连接到来回调函数_acceptCallBack。
这样又回到上面说的,这个_acceptCallBack是由TcpServer模块设置的,设置的函数就是newConnection,这个函数后续会介绍,它的功能就是为新连接创建Connection对象去管理。至此,主Reactor如何获取新连接,以及Acceptor的原理和功能我们都清楚了。这个模块涉及了一些回调函数,并且还与其它多个模块关联,如果不仔细梳理,很难彻底弄清楚Acceptor模块到底是做什么的,也很难弄清楚该模块与其它模块的关系。
2.Acceptor模块完整代码实现
介绍完了关键几个代码之后,剩下的函数接口都比较简单,这里就不过多讲解了,贴上代码即可。
using AcceptCallBack = std::function<void(int)>;
class Acceptor
{
public:
// 不能将启动读事件监控放到构造函数中,必须在设置回调函数之后,再去启动
// 否则有可能造成启动监控后,立即有事件到来了,但是处理的时候回调函数还没设置,所以新连接得不到处理,并且资源泄露
Acceptor(EventLoop *eventLoop, uint16_t port)
:_eventLoop(eventLoop), _socket(createServer(port)), _channel(eventLoop, _socket.getSocketFd())
{
_channel.setReadAbleCallBack(std::bind(&Acceptor::handleRead, this));
}
void setAcceptCallBack(const AcceptCallBack &callBack)
{
_acceptCallBack = callBack;
}
void startListen()
{
_channel.startReadAbleEvent();
}
private:
// 监听套接字的读事件回调函数---获取新连接,调用_acceptCallBack函数进行新连接处理
void handleRead()
{
int newFd = _socket.acceptConnect();
if(newFd < 0)
{
return;
}
if(_acceptCallBack)
{
_acceptCallBack(newFd);
}
}
int createServer(uint16_t port)
{
bool ret = _socket.createServer(port);
assert(ret == true);
return _socket.getSocketFd();
}
private:
Socket _socket;// 用于创建监听套接字
EventLoop *_eventLoop;// 用于对监听套接字进行事件监控
Channel _channel;// 用于对监听套接字进行事件管理
AcceptCallBack _acceptCallBack;
};
四、定时器模块
1.时间轮的思想
为了防止一个连接长时间不与服务器进行信息交互,但又霸占着连接资源,所以我们的服务器必须要有定时器模块。因为服务器的资源是有限的,最简单的来说,每个连接就是一个socket,其实本质上是文件描述符,而Linux操作系统中文件描述符是有限资源,如果被大量这种不通信又不断开的连接霸占,那么后面到来的新连接就没办法获取文件描述符了。所以定时器模块可以让网络库的使用者设定一个超时时间,当连接距离上一次通信的时间到当前时刻的时间间隔大于超时时间,服务器会主动断开连接。
实现定时器模块首先需要有计时的功能,muduo库使用的计时器功能是Linux操作系统提供的timerfd,这是以文件描述符方式管理超时提醒的机制。timerfd_fd函数能创建一个系统的计时器,我们设置计时时间,操作系统会给我们返回一个文件描述符,当设置的时间到了,操作系统会向文件里写入数据,数据表示距离上一次读取超时了多少次。有了这个机制,我们可以很好地将计时功能与epoll多路转接联系起来使用。我们可以将文件描述符放在epoll模型中监控可读事件,当可读事件触发时,说明操作系统向该文件写入数据了,也就是说明时间到了,这时候再由epoll_wait函数返回可读事件,经由上层用户去处理超时连接。这里就不介绍timerfd是具体使用了,只需要知道是用来做什么的就可以,不了解如何使用的可以去学习一下接口。
但是如果只使用timerfd显然无法满足我们的需求,试想一下,仅仅使用timerfd来计时的话,最好的方式就是全局定义一个计时器,然后每个连接记录一个距离上次通信的时间,检查超时销毁连接的操作就变成了需要遍历所有的连接,如果超时了再将其销毁。这样的做法针对服务器中大量连接的情况是不实际的。所以需要思考的就是如何高效地组织这些定时器,能够快速地找出当前时刻已经超时的连接。muduo的做法是使用set数据结构,也就是底层使用的红黑树,把每个连接按到期时间先后排序,操作的时间复杂度是O(logN)。但除此之外,作者在书中还介绍了时间轮的方案,虽然作者没有实现在muduo库源码上,但通过作者描述的思路,我更感兴趣这一种实现方案,下面我将详细介绍时间轮方案的实现。
其实我翻阅了一些书籍以及搜索了网上的一些文章,定时器的实现方案还是有许多的,比如按到期时间先后排序的队列、以到期时间建立最小堆、红黑树、时间轮。这些都是比较常见的实现方案,对比了一下其实会发现,时间轮方案比其它都更优越。
我在项目中实现的时间轮是多级时间轮,不过我的多级时间轮只有两级,因为多了没必要,秒级时间轮和分钟级时间轮就已经能大致满足需求了,毕竟一个连接多长时间未通信销毁其实没有固定值,一般也是根据场景来确定。几秒钟几十秒就关闭连接太短了,几个小时才关闭连接似乎又太长了,所以分钟级别是比较合适的。
秒级时间轮和分钟级时间轮其实是一样的数据结构,它们都是有一个vector数组,这个数组有60个元素,分别代表60秒和60分钟。vector数组每一个元素下面还跟着一个数组,这个数组就是超时任务对象。具体的运作逻辑是,秒针每秒向后移动一格,然后将当前指向的所有超时任务销毁,这就是时间轮的基本思想。由于秒针是每秒向后移动一格,然后秒针走到哪里,就执行哪里的超时任务,所以一维的vector数组应该被我们设计成循环队列,这一点也不难理解,因为限制了长度是60,循环队列才能让秒针一直在转,就像时钟一样,不停地转圈圈。
举个例子更好地说明一下,假设初始状态,秒针和分针都指向0下标处,此时有一个5秒之后的超时任务,所以在秒针当前位置向后加5的位置,插入这个超时任务。由于秒针是每秒向前走一格的,走到5位置处刚好是5秒,也就意味着改任务的时间到了,可以执行超时处理了。
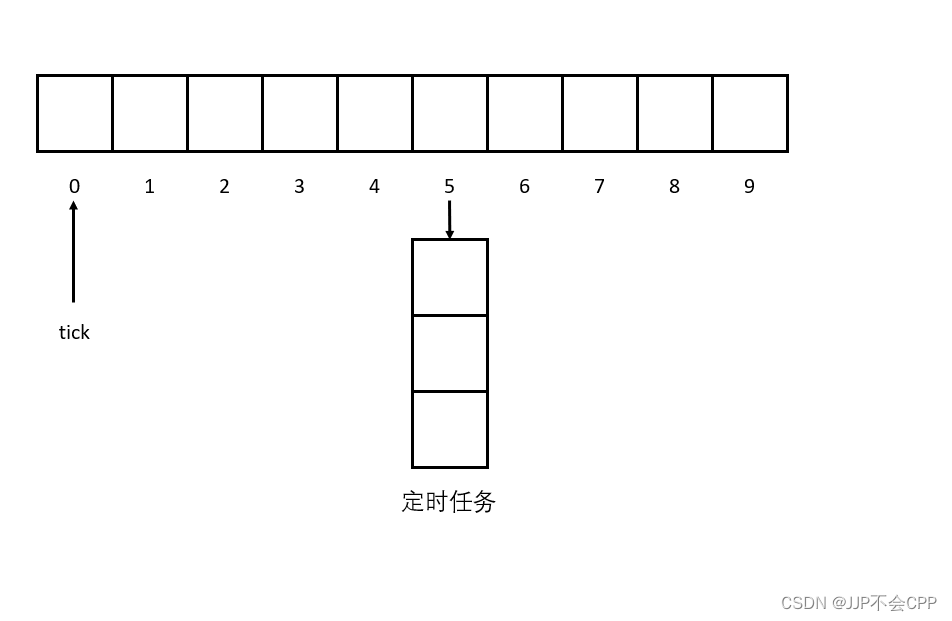
上图虽然只有秒级时间轮,但加入分钟级时间轮也很好理解,这其实和现实生活中的时钟是一样的道理,秒级时间轮的指针走了60格以后,分钟级时间轮的指针才能向前走1格,就好比现实中秒针走一圈,分针才向前走一格。这就是时间轮的思想,理解起来应该不困难,接下来介绍时间轮定时器模块的具体设计与实现。
2.TimerTask类
首先我们需要有一个超时任务类,因为时间轮管理的是一个个的超时任务对象,它只负责如何高效地管理这些对象,具体如何执行超时以后的操作,还是通过超时任务对象来确定的。所以TimerTask类就是设置超时任务类。它可以设置超时的时间是多少,以及超时以后该如何处理。超时以后如何处理是上层决定的事情,定时器模块需要的只是一个回调函数,超时以后调用该回调函数即可。
除此之外,我们不希望时间轮的指针走到超时位置时,还要一个一个TimerTask对象去执行超时对应的回调函数,我们希望这些TimerTask对象自己调用这些回调。所以我们采用RAII的思想,让TimerTask类在构造函数里完成这些超时时间、超时回调函数的设置,在析构函数里调用超时回调函数。这样就只需要在时间轮里释放TimerTask对象即可,它会在析构函数里自动调用超时回调函数,非常方便。
TimerTask的代码不难实现,这里就直接给出了,具体是看TimerTask对象如何在时间轮里被使用。
/// @brief 定时器任务类,这个类实例化出来的对象,在生命周期内就是一个定时任务,当生命周期结束的时候就代表超时了,就会执行超时的任务
/// 这里其实使用了RAII的思想
class TimerTask
{
public:
// 构造函数,需要告诉我定时器任务对象的id是什么,超时时间是什么,以及超时以后处理的任务是什么
TimerTask(uint64_t id, uint32_t timeout, const TaskFunc &task)
: _id(id),
_timeout(timeout),
_task(task),
_cancelFlag(false)
{
}
// 析构函数,在析构的时候执行超时任务
~TimerTask()
{
// 如果上层用户没有取消超时任务,就执行超时任务
if (_cancelFlag == false)
{
_task();
}
// 调用release回调函数
_release();
}
void setRelease(const ReleaseFunc &release)
{
_release = release;
}
uint32_t getTimeOut()
{
return _timeout;
}
void cancel()
{
_cancelFlag = true;
}
private:
uint64_t _id; // 定时器任务对象的ID
uint32_t _timeout; // 定时任务的超时时间
bool _cancelFlag; // false表示没有被取消,true表示被取消
TaskFunc _task; // 定时器对象要执行的定时任务
ReleaseFunc _release; // 用于删除TimerWheel中保存的定时器对象信息
};
3.TimerWheel类
TimerWheel类就是我们要实现的时间轮,首先看一下TimerWheel类成员变量的设计:
private:
int _second_tick; // 当前的秒针,走到哪里释放哪里,就相当于执行哪里的任务
int _minute_tick; // 当前的分针
int _capacity; // 时间轮表盘最大数量,其实就是最大延迟时间
// 这是个二维数组,其实就是一个桶结构,一维的每一个元素代表每1s的时间,
// 每秒下面挂的就是这一时刻的定时器任务对象的shared_ptr
std::vector<std::vector<TaskSharedPtr>> _second_wheel; // 秒级时间轮
std::vector<std::vector<TaskSharedPtr>> _minute_wheel; // 分钟级时间轮
// _timers是用来保存定时器任务对象的weak_ptr的,key值是定时器任务对象的ID值,用来索引对应的定时器任务对象
// value值是保存定时器任务对象的weak_ptr
// 这里用weak_ptr的原因是不会使shared_ptr的引用计数增加
// 如果使用shared_ptr的话,在插入到_timers中或者从_timers中获取对象的时候都会拷贝shared_ptr对象,使得引用计数增加,这样是不合理的
std::unordered_map<uint64_t, TaskWeakPtr> _timers;
EventLoop *_eventLoop;
int _timerfd; // 定时器描述符
// 定时器任务对象的时间管理对象指针
std::unique_ptr<Channel> _timerChannel;
成员变量中首先需要的是两个时间轮,分别是秒级时间轮和分钟级时间轮,以及两个时间轮的指针,分别代表秒针和分针。还需要一个_timers哈希表用来保存所有的定时任务TimerTask对象,这也很有必要,因为我们需要将TimerTask对象管理起来,以后需要对其进行查找,使用哈希表效率比较高。
重点的是,我们这里时间轮管理的定时任务TimerTask对象,并不是使用原生的对象指针,而是使用智能指针,我认为这是设计的一个巧妙之处,这里用智能指针主要有以下场景的考虑:
- 当我们需要刷新定时任务的时间时,比如说在2s的时候一个新连接到来了,服务器为这个连接建立了一个定时任务,5s之后如果不通信的话就销毁连接,也就是应该在第7s销毁连接,那么这个定时任务就应该添加在秒级时间轮下标为7的位置。但如果当秒针走到3s处,这个连接有一次新的通信,我们就应该刷新定时任务的销毁时间,就不应该是第7s销毁了,因为最近一次通信是第3s,按照5s之后不活跃销毁的规则,真正销毁的时间应该是第8s。这时如果不使用智能指针,而是使用原生的对象指针是会出问题的,因为第7s和第8s处都有这个定时任务,指针会被释放两次,这是会出错误的。所以使用shared_ptr智能指针,在这个地方非常有必要,我们可以在第8s新插入这个定时任务对象的shared_ptr,即使秒针走到第7s释放了原来的shared_ptr,由于引用计数不为0,所以不会真正释放对象,等到第8s的时候才会真正释放,这就是使用shared_ptr智能指针的原因。
接下来再介绍多层级的时间轮是如何实现的:首先定时任务TimerTask对象会设置timeout超时时间,如果这个超时时间大于或等于60,说明超时时间在一分钟以上,那就需要使用分钟级时间轮和秒级时间轮了。否则的话秒级时间轮就够用了。如果要用分钟级时间轮,假设超时时间timeout为110s,即1min50s,那么就在分针级时间轮的第1格插入这个TimerTask对象。当秒针走过了60格以后,分针就会向前走1格,此时并不释放分针级时间轮第一个的这个TimerTask对象,而是将该定时任务对象转移到秒级时间轮对应的格子中,比如这个110s的TimerTask对象,就应该转移到秒级时间轮的第50格。当下一次秒针再走到第50格的时候,前后就一共走了60+50=110s,就可以释放这个TimerTask对象了。也就是说,分钟级时间轮不处理定时任务,只将定时任务转移到秒级时间轮,只有秒级时间轮才会处理超时任务。
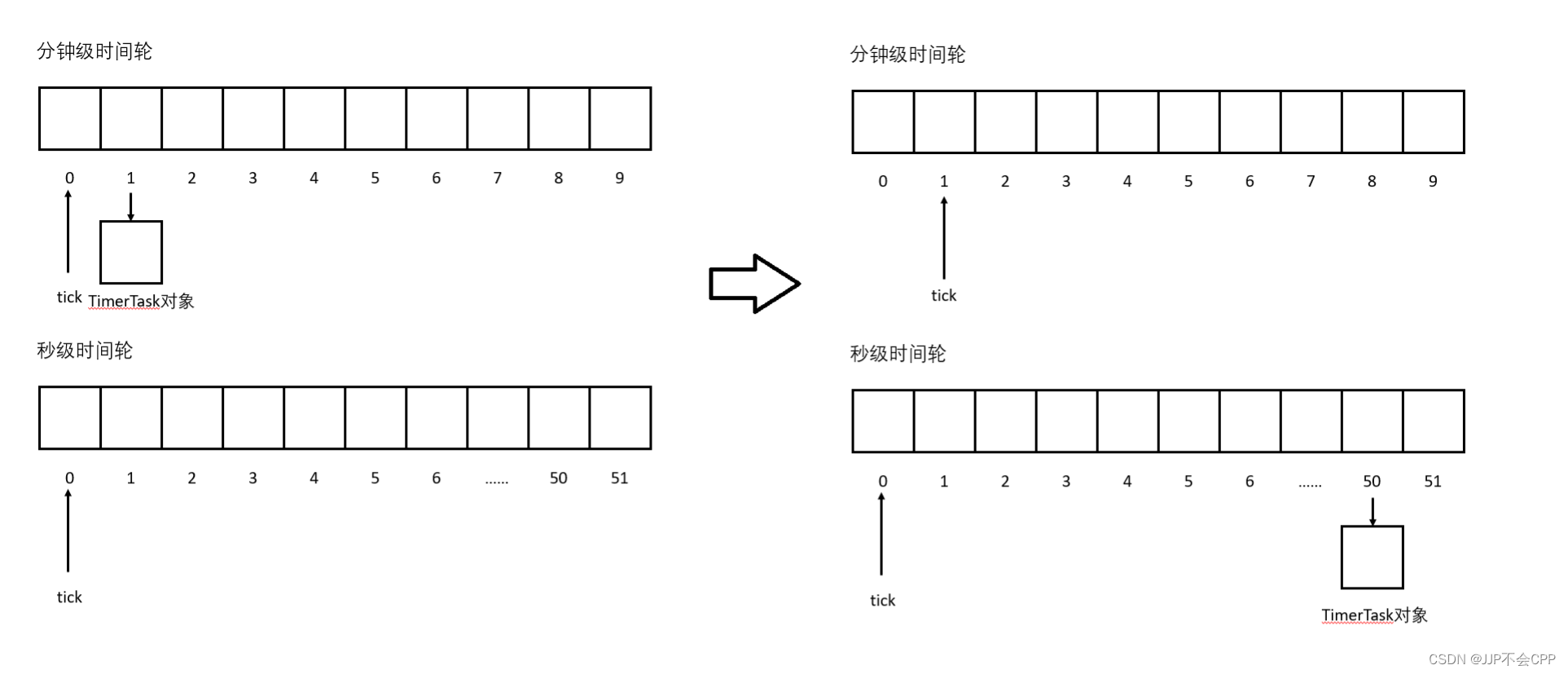
接下来我们可以介绍addTimer、refreshTimer和runTimerTask三个函数接口了。
addTimer:
首先是addTimer函数接口,这个接口是添加一个定时任务TimerTask对象到时间轮中,由于我们有秒级时间轮和分钟级时间轮,所以需要对TimerTask对象的超时时间timeout进行判断,如果timeout大于或等于60,即超过一分钟以上,那就需要将这个TimerTask对象放在分钟级时间轮上。否则的话,就放在秒级时间轮上。该函数的具体实现如下:
// 添加定时任务到EventLoop中
void addTimerToEventLoop(uint64_t id, uint32_t timeout, const TaskFunc &task)
{
// 首先new一个定时器任务对象出来,交给shared_ptr管理
TaskSharedPtr ptr(new TimerTask(id, timeout, task));
// 设置定时器任务对象的release回调函数,设置为removeTimer函数
// 这个release函数是用来清理TimerWheel中保存的定时器任务对象信息的
ptr->setRelease(std::bind(&TimerWheel::removeTimer, this, id));
// 设置完以后计算超时时间,如果timeout>60,说明要用到分钟轮
if (timeout >= 60)
{
int minute_timeout = timeout / 60;
int minute_pos = (_minute_tick + minute_timeout) % _capacity;
_minute_wheel[minute_pos].push_back(ptr);
}
else
{
int second_pos = (_second_tick + timeout) % _capacity;
_second_wheel[second_pos].push_back(ptr);
}
// 构造一个weak_ptr到_timers中,保存定时器任务对象的信息
_timers[id] = TaskWeakPtr(ptr);
}
refreshTimer:
refreshTimer是刷新定时任务的函数接口,也就是上面提到的使用智能指针在这种场景下的好处。实现这个接口也不难,只需要在当前指针加上timeout的位置处,插入一个管理TimerTask对象的shared_ptr智能指针,就可以实现刷新操作。
// 刷新或者延迟定时任务
bool refreshTimerInEventLoop(uint64_t id)
{
// 通过保存的定时器对象的weak_ptr构造一个shared_ptr出来,添加到时间轮中
// 首先通过定时器任务ID到_timers中查找对应的定时器任务对象的weak_ptr
auto iter = _timers.find(id);
if (iter == _timers.end())
{
return false;
}
// 找到了以后,将对应的weak_ptr转换成shared_ptr
TaskSharedPtr ptr = iter->second.lock();
// 获取这个定时器任务对象的timeout超时时间
int timeout = ptr->getTimeOut();
if (timeout >= 60)
{
int minute_timeout = timeout / 60;
int minute_pos = (_minute_tick + minute_timeout) % _capacity;
_minute_wheel[minute_pos].push_back(ptr);
}
else
{
int second_pos = (_second_tick + timeout) % _capacity;
_second_wheel[second_pos].push_back(ptr);
}
return true;
}
runTimerTask:
runTimerTask函数接口其实就是让秒针每秒向前走一格,如果秒针已经走了一圈了,就让分针向前走一格。因此,这个函数必须每秒钟被调用一次,具体如何保证每秒钟被调用一次我们下面再介绍,这里先介绍该函数接口的实现。其实实现也是非常简单,就是每次调用都让秒针向后移动一格,然后释放秒级时间轮秒针位置的所有TimerTask对象,这样就会执行这个TimerTask对象的析构函数从而去执行超时处理。如果秒针走了一圈了,那就让分针向前走一格,然后将分钟级时间轮中分针指向位置的TimerTask对象转移到秒级时间轮的对应位置。分钟级时间轮不处理超时任务,只将超时任务转移给秒级时间轮去处理。
void runTimerTask()
{
// 首先判断秒针是否已经走满一圈,是的话就让分针进一格
if (_second_tick + 1 >= 60)
{
_minute_tick = (_minute_tick + 1) % _capacity;
for(int i = 0; i < _minute_wheel[_minute_tick].size(); i++)
{
int timeout = _minute_wheel[_minute_tick][i]->getTimeOut();
// 分钟级时间轮的时间到了,将定时任务转移到秒级时间轮对应的位置
_second_wheel[timeout % 60].push_back(_minute_wheel[_minute_tick][i]);
}
_minute_wheel[_minute_tick].clear();
}
// 每一秒更新一次_tick的位置,相当于每一秒时钟向后走一步
_second_tick = (_second_tick + 1) % _capacity;
// 更新完以后,就销毁该时刻下对应的所有定时器任务
_second_wheel[_second_tick].clear();
}
到这里,我们就基本上实现了时间轮的所有核心操作,但是现在的时间轮只有操作和管理定时任务TimerTask对象的功能,定时器模块还需要计时功能,没有计时功能怎么知道有没有超时呢?所以接下来我们需要实现定时器模块的计时功能。
我们之前也提过,muduo库的计时功能是通过Linux提供的timerfd机制实现的,操作系统会为我们创建一个文件,超时了就向文件中写入数据。所以我们可以将该文件的文件描述符用epoll监控起来,一旦可读事件触发,说明文件中有数据到来,也就是说提醒我们时间到了。所以首先需要创建一个timerfd,并且我们需要将超时时间设置为1s,因为我们希望操作系统每秒提醒我们调用一次runTimerTask函数,这样就能让时间轮的秒针每秒向前移动一格。createTimerFd函数实现如下:
static int createTimerFd()
{
// 使用timerfd_create函数会创建一个定时器的文件描述符
// 这个文件描述符是操作系统帮我们管理的,一旦超时,操作系统就会向文件里写入数据
// 每次读取出来的数据表示距离上一次读取超时了多少次
int timerfd = timerfd_create(CLOCK_MONOTONIC, 0);
if (timerfd < 0)
{
LOG("timerfd_create error");
abort();
}
// 这里将超时时间设置为1s,每1s后超时一次
struct itimerspec itime;
itime.it_value.tv_sec = 1;
itime.it_value.tv_nsec = 0; // 第一次超时时间为1s后
itime.it_interval.tv_sec = 1;
itime.it_interval.tv_nsec = 0; // 第一次超时后,每次超时的时间间隔
timerfd_settime(timerfd, 0, &itime, nullptr);
return timerfd;
}
我们在TimerWhell时间轮类的构造函数处就应该调用createTimerFd去创建timerfd,并且将该文件描述符交给epoll去监控,设置可读事件触发的回调函数为timeout,这个函数接下来我们会实现,然后启动epoll的可读事件监控,这样就能监控timerfd文件描述符了,由于我们设置的timerfd超时时间是1s,所以操作系统每1s都会向文件描述符写入数据,epoll每1s都会监控到可读事件,然后调用timeout函数。构造函数的实现如下:
// 构造函数,需要传递进入eventLoop对象
// 因为定时器任务也是需要被reactor管理的
// 添加定时器任务、刷新定时器任务、取消定时器任务
// 这些都会作为事件让eventLoop对象管理,eventLoop对象再交给Poller对象去监控这些事件
// 监控事件发生以后,再让Channel对象去处理
TimerWheel(EventLoop *eventLoop)
: _capacity(60), _second_tick(0), _minute_tick(0), _second_wheel(_capacity), _minute_wheel(_capacity),
_eventLoop(eventLoop), _timerfd(createTimerFd()),
_timerChannel(new Channel(_eventLoop, _timerfd))
{
// _timerChannel是定时器任务事件管理的对象,用来管理定时器任务的事件
// 这里设置_timerChannel的可读事件,设置为timeOut,一旦可读事件就绪,就会调用timeout
_timerChannel->setReadAbleCallBack(std::bind(&TimerWheel::timeOut, this));
// 开始可读事件的监控
_timerChannel->startReadAbleEvent();
}
接下来是timeout函数,这个函数是被绑定在timerfd文件描述符的可读事件下的,timerfd的可读事件触发就会被调用,所以这个函数每秒钟会被调用一次。所以我们要利用它每秒钟被调用一次的特点,通过该函数去调用runTimerTask函数,让秒针每秒向后走一格,这样整个定时器模块的逻辑就打通了。
// 这个函数已经被绑定在_timerChannel对象中,也就是说被作为可读事件监控起来了
// 一旦可读事件触发,就会调用这个函数
// 那什么时候会触发呢?当这个事件关联的文件描述符也就是_timerfd有数据到来的时候
// 因为_timerfd是操作系统为我们创建的一个定时器文件,是操作系统在帮我们管理
// 并且我们设置了每1s超时一次,所以操作系统每1s都会提醒我们一次
// 也就是说每1s操作系统都会向_timerfd中写入数据,那么每1s可读事件都会就绪,就会调用timeout函数
// 调用以后就会去读取_timerfd里的内容,并且执行runTimerTask函数去处理超时任务
// 这里就是定时器的精髓,很好地利用操作系统的timerfd机制,将文件描述符交给epoll去监控管理
// 一旦超时了操作系统会通知,非常牛逼
void timeOut()
{
// 先调用readTimerFd函数去读取timerfd里的数据
// times表示距离上一次读取超时了多少次
int times = readTimerFd();
// 循环执行runTimerTask
// 超时了多少次就执行多少次,runTimerTask函数是将指时钟向后移动1s,然后执行对应时刻的所有超时任务
for (int i = 0; i < times; i++)
{
runTimerTask();
}
}
至此,TimerWhell时间轮类的实现基本差不多了,剩下的接口比较简单,就不过多介绍了,这里可以直接给完整的代码:
using TaskWeakPtr = std::weak_ptr<TimerTask>;
using TaskSharedPtr = std::shared_ptr<TimerTask>;
/// @brief 时间轮类,用来管理定时任务对象的类,实现超时处理的方式是时间轮
class TimerWheel
{
public:
// 构造函数,需要传递进入eventLoop对象
// 因为定时器任务也是需要被reactor管理的
// 添加定时器任务、刷新定时器任务、取消定时器任务
// 这些都会作为事件让eventLoop对象管理,eventLoop对象再交给Poller对象去监控这些事件
// 监控事件发生以后,再让Channel对象去处理
TimerWheel(EventLoop *eventLoop)
: _capacity(60), _second_tick(0), _minute_tick(0), _second_wheel(_capacity), _minute_wheel(_capacity),
_eventLoop(eventLoop), _timerfd(createTimerFd()),
_timerChannel(new Channel(_eventLoop, _timerfd))
{
// _timerChannel是定时器任务事件管理的对象,用来管理定时器任务的事件
// 这里设置_timerChannel的可读事件,设置为timeOut,一旦可读事件就绪,就会调用timeout
_timerChannel->setReadAbleCallBack(std::bind(&TimerWheel::timeOut, this));
// 开始可读事件的监控
_timerChannel->startReadAbleEvent();
}
~TimerWheel()
{
}
// 把所有对定时任务的操作都放在一个线程中完成,所以放在EventLoop线程中比较合适
// 因为定时器中有个_timers成员,定时器信息的操作有可能在多线程中进行,因此需要考虑线程安全问题
// 但是又不想加锁,因为加锁耗费资源,所以把所有定时操作放在一个线程中进行
// 这里和EventLoop模块、线程池模块的设计解决了这种线程不安全的问题
// 因为设计的时候一个EventLoop对象就会被分配一个线程,并且EventLoop对象内部会绑定这个线程的ID
// 这些函数将来都会作为任务通过EventLoop对象的runInLoop函数添加到任务队列
// 在这里就会判断当前执行的线程是不是EventLoop对象对应的线程
// 如果是的话就直接执行任务,如果不是的话就加入任务队列,等到下一次被EventLoop对象对应的线程调用
// 这样就能保证这些addTimer类似的函数能够只被一个线程调用,不会被其它线程调用
// 所以临界资源_timers是安全的,就不会有线程安全了
void addTimer(uint64_t id, uint32_t timeout, const TaskFunc &task);
void refreshTimer(uint64_t id);
void cancelTimer(uint64_t id);
// 存在线程安全问题,所以只能在EventLoop线程调用,不能被其它线程调用
bool hasTimer(uint64_t id);
private:
// 刷新或者延迟定时任务
bool refreshTimerInEventLoop(uint64_t id)
{
// 通过保存的定时器对象的weak_ptr构造一个shared_ptr出来,添加到时间轮中
// 首先通过定时器任务ID到_timers中查找对应的定时器任务对象的weak_ptr
auto iter = _timers.find(id);
if (iter == _timers.end())
{
return false;
}
// 找到了以后,将对应的weak_ptr转换成shared_ptr
TaskSharedPtr ptr = iter->second.lock();
// 获取这个定时器任务对象的timeout超时时间
int timeout = ptr->getTimeOut();
if (timeout >= 60)
{
int minute_timeout = timeout / 60;
int minute_pos = (_minute_tick + minute_timeout) % _capacity;
_minute_wheel[minute_pos].push_back(ptr);
}
else
{
int second_pos = (_second_tick + timeout) % _capacity;
_second_wheel[second_pos].push_back(ptr);
}
return true;
}
// 添加定时任务到EventLoop中
void addTimerToEventLoop(uint64_t id, uint32_t timeout, const TaskFunc &task)
{
// 首先new一个定时器任务对象出来,交给shared_ptr管理
TaskSharedPtr ptr(new TimerTask(id, timeout, task));
// 设置定时器任务对象的release回调函数,设置为removeTimer函数
// 这个release函数是用来清理TimerWheel中保存的定时器任务对象信息的
ptr->setRelease(std::bind(&TimerWheel::removeTimer, this, id));
// 设置完以后计算超时时间,如果timeout>60,说明要用到分钟轮
if (timeout >= 60)
{
int minute_timeout = timeout / 60;
int minute_pos = (_minute_tick + minute_timeout) % _capacity;
_minute_wheel[minute_pos].push_back(ptr);
}
else
{
int second_pos = (_second_tick + timeout) % _capacity;
_second_wheel[second_pos].push_back(ptr);
}
// 构造一个weak_ptr到_timers中,保存定时器任务对象的信息
_timers[id] = TaskWeakPtr(ptr);
}
// 执行定时任务
// 这个函数应该每秒钟被执行一次,相当于秒针向后走了一步
// 这个函数会被timeout函数调用,timeout函数会在超时的时候被调用
// 而TimerFd我们设置的是1s钟超时,所以这里的逻辑就是,每隔1s,操作系统会向timerfd中写入数据代表时间到了
// 然后epoll监控到timerfd文件描述符的可读事件触发,就调用对应的可读事件回调函数,也就是timeout函数
// timeout函数再调用runTimerTask函数,这样就能保证一秒钟执行这个函数一次
void runTimerTask()
{
// 首先判断秒针是否已经走满一圈,是的话就让分针进一格
if (_second_tick + 1 >= 60)
{
_minute_tick = (_minute_tick + 1) % _capacity;
for(int i = 0; i < _minute_wheel[_minute_tick].size(); i++)
{
int timeout = _minute_wheel[_minute_tick][i]->getTimeOut();
// 分钟级时间轮的时间到了,将定时任务转移到秒级时间轮对应的位置
_second_wheel[timeout % 60].push_back(_minute_wheel[_minute_tick][i]);
}
_minute_wheel[_minute_tick].clear();
}
// 每一秒更新一次_tick的位置,相当于每一秒时钟向后走一步
_second_tick = (_second_tick + 1) % _capacity;
// 更新完以后,就销毁该时刻下对应的所有定时器任务
_second_wheel[_second_tick].clear();
}
// 删除保存的定时器任务对象的信息,也就是在_timers中的内容
void removeTimer(uint64_t id)
{
auto iter = _timers.find(id);
if (iter != _timers.end())
{
_timers.erase(iter);
}
}
// 取消定时器任务
void cancelTimerInEventLoop(uint64_t id)
{
// 首先看该定时器任务是否在_timers中
// 如果不在的话,说明没有这个定时器任务,直接返回
auto iter = _timers.find(id);
if (iter == _timers.end())
{
return;
}
// 找到了以后构造shared_ptr指针对象,然后去执行定时器任务对象的cancel函数
// 这个函数就是将取消标志位设置为true,这样在定时器任务对象析构的时候,就不会去执行定时器对象要处理的任务
// 只会执行release回调函数,也就是删除在_timers中保存的定时器对象的信息
TaskSharedPtr ptr = iter->second.lock();
if (ptr)
{
ptr->cancel();
}
}
// 创建Timerfd
static int createTimerFd()
{
// 使用timerfd_create函数会创建一个定时器的文件描述符
// 这个文件描述符是操作系统帮我们管理的,一旦超时,操作系统就会向文件里写入数据
// 每次读取出来的数据表示距离上一次读取超时了多少次
int timerfd = timerfd_create(CLOCK_MONOTONIC, 0);
if (timerfd < 0)
{
LOG("timerfd_create error");
abort();
}
// 这里将超时时间设置为1s,每1s后超时一次
struct itimerspec itime;
itime.it_value.tv_sec = 1;
itime.it_value.tv_nsec = 0; // 第一次超时时间为1s后
itime.it_interval.tv_sec = 1;
itime.it_interval.tv_nsec = 0; // 第一次超时后,每次超时的时间间隔
timerfd_settime(timerfd, 0, &itime, nullptr);
return timerfd;
}
// 读取timerfd里的数据
int readTimerFd()
{
// 这个times就是读取出来的内容,表示距离上一次读取超时了多少次
uint64_t times;
int readRes = read(_timerfd, ×, 8);
if (readRes < 0)
{
LOG("read error");
abort();
}
return times;
}
// 这个函数已经被绑定在_timerChannel对象中,也就是说被作为可读事件监控起来了
// 一旦可读事件触发,就会调用这个函数
// 那什么时候会触发呢?当这个事件关联的文件描述符也就是_timerfd有数据到来的时候
// 因为_timerfd是操作系统为我们创建的一个定时器文件,是操作系统在帮我们管理
// 并且我们设置了每1s超时一次,所以操作系统每1s都会提醒我们一次
// 也就是说每1s操作系统都会向_timerfd中写入数据,那么每1s可读事件都会就绪,就会调用timeout函数
// 调用以后就会去读取_timerfd里的内容,并且执行runTimerTask函数去处理超时任务
// 这里就是定时器的精髓,很好地利用操作系统的timerfd机制,将文件描述符交给epoll去监控管理
// 一旦超时了操作系统会通知,做到了异步的事件驱动机制,非常牛逼
void timeOut()
{
// 先调用readTimerFd函数去读取timerfd里的数据
// times表示距离上一次读取超时了多少次
int times = readTimerFd();
// 循环执行runTimerTask
// 超时了多少次就执行多少次,runTimerTask函数是将指时钟向后移动1s,然后执行对应时刻的所有超时任务
for (int i = 0; i < times; i++)
{
runTimerTask();
}
}
private:
int _second_tick; // 当前的秒针,走到哪里释放哪里,就相当于执行哪里的任务
int _minute_tick; // 当前的分针
int _capacity; // 时间轮表盘最大数量,其实就是最大延迟时间
// 这是个二维数组,其实就是一个桶结构,一维的每一个元素代表每1s的时间,
// 每秒下面挂的就是这一时刻的定时器任务对象的shared_ptr
std::vector<std::vector<TaskSharedPtr>> _second_wheel; // 秒级时间轮
std::vector<std::vector<TaskSharedPtr>> _minute_wheel; // 分钟级时间轮
// _timers是用来保存定时器任务对象的weak_ptr的,key值是定时器任务对象的ID值,用来索引对应的定时器任务对象
// value值是保存定时器任务对象的weak_ptr
// 这里用weak_ptr的原因是不会使shared_ptr的引用计数增加
// 如果使用shared_ptr的话,在插入到_timers中或者从_timers中获取对象的时候都会拷贝shared_ptr对象,使得引用计数增加,这样是不合理的
std::unordered_map<uint64_t, TaskWeakPtr> _timers;
EventLoop *_eventLoop;
int _timerfd; // 定时器描述符
// 定时器任务对象的时间管理对象指针
std::unique_ptr<Channel> _timerChannel;
};
五、线程池模块
由于我们实现的是多线程模型,所以必须要实现一个线程池,我们要实现one loop one thread服务器,主Reactor运行在主线程上,只负责接收获取连接,从属Reactor运行在子线程上,负责处理连接的IO事件,所以我们可能会创建多个线程来运行从属Reactor,就需要线程池来管理这些线程。
1.LoopThread类
LoopThread类实现的是单个线程的逻辑,我们希望创建单个线程对象,即LoopThread对象时,也意味着创建一个从属Reactor。也就是说,一个子线程与一个从属Reactor绑定在一起。我们绑定线程的执行函数为threadEntry。在threadEntry这个函数内部,我们创建从属Reactor,然后让该从属Reactor启动监控,这个启动监控其实是一个while(true)死循环,也就是它会一直启动。threadEntry函数的实现如下:
// 实例化EventLoop对象,唤醒_cond上有可能阻塞的线程,并且开始运行EventLoop模块的功能
void threadEntry()
{
// 这个函数是每次被线程执行的函数
// 每次执行都会新建一个EventLoop对象,创建好之后调用start启动
EventLoop loop;
{
std::unique_lock<std::mutex> lock(_mutex);
_eventLoop = &loop;
_cond.notify_all();
}
loop.start();
// 出了这个函数EventLoop会自动销毁
// 但实际上start是一个死循环,除非关闭连接或者连接出错了
// 就会去调用连接关闭回调函数和错误处理回调函数来关闭连接,这样才会退出
// 所以也就是说这个创建的loop是贯穿一个连接整个生命周期的
// 只有连接结束了这个loop才会被销毁
}
这样单个线程的任务就完成了,LoopThread类的完整代码实现如下:
class LoopThread
{
public:
// 创建线程,设定线程入口函数
// 这里创建线程的时候将线程_thread初始化函数设置为threadEntry函数
// 也就是说创建的这个线程每次会去执行threadEntry函数
LoopThread()
:_eventLoop(nullptr), _thread(std::thread(&LoopThread::threadEntry, this))
{}
// 返回当前线程关联的EventLoop对象指针
EventLoop *getEventLoop()
{
EventLoop *loop = nullptr;
{
// 这里必须加锁等待条件变量_eventLoop不为空成立才能返回_eventLoop
// 因为刚创建线程可能还没有执行threadEntry函数,就来获取_eventLoop的话,获取到的是空值
// 必须等threadEntry创建了_eventLoop对象才能返回
std::unique_lock<std::mutex> lock(_mutex);
_cond.wait(lock, [&](){
return _eventLoop != nullptr;
});
loop = _eventLoop;
}
return loop;
}
private:
// 实例化EventLoop对象,唤醒_cond上有可能阻塞的线程,并且开始运行EventLoop模块的功能
void threadEntry()
{
// 这个函数是每次被线程执行的函数
// 每次执行都会新建一个EventLoop对象,创建好之后调用start启动
EventLoop loop;
{
std::unique_lock<std::mutex> lock(_mutex);
_eventLoop = &loop;
_cond.notify_all();
}
loop.start();
// 出了这个函数EventLoop会自动销毁
// 但实际上start是一个死循环,除非关闭连接或者连接出错了
// 就会去调用连接关闭回调函数和错误处理回调函数来关闭连接,这样才会退出
// 所以也就是说这个创建的loop是贯穿一个连接整个生命周期的
// 只有连接结束了这个loop才会被销毁
}
private:
// 互斥锁和条件变量用于实现EventLoop获取的同步关系,避免线程创建了,但是EventLoop还没有实例化,就去获取EventLoop,就会获取到nullptr
std::mutex _mutex; // 互斥锁
std::condition_variable _cond; // 条件变量
EventLoop *_eventLoop; // EventLoop指针变量,这个对象需要在线程内实例化
std::thread _thread; // EventLoop对应的线程
};
2.LoopThreadPool类
LoopThreadPool类是线程池类,外界通过线程池的nextEventLoop函数接口获取子线程,实际上就是获取从属Reactor。这里的逻辑是,当主Reactor监控到一个新连接到来的时候,就从线程池的nextEventLoop函数中获取一个从属Reactor,让该从属Reactor监控新连接的IO事件。线程池的完整代码如下:
class LoopThreadPool
{
public:
// 构造函数,需要用baseLoop来初始化,也就是需要用主reactor来初始化
LoopThreadPool(EventLoop *baseLoop)
:_threadCount(0), _nextLoopIndex(0), _baseLoop(baseLoop)
{}
// 设置线程数量
void setThreadCount(int count)
{
_threadCount = count;
}
// 创建所有的从属线程
void create()
{
if(_threadCount > 0)
{
_threads.resize(_threadCount);
_eventLoops.resize(_threadCount);
for(int i = 0; i < _threadCount; i++)
{
_threads[i] = new LoopThread;
_eventLoops[i] = _threads[i]->getEventLoop();
}
}
}
// 从线程池中获取eventLoop
// 这个函数接口是给TcpServer调用的,当一个新连接到来的时候,就会创建一个新的Connection对象
// 这个Connection对象需要从线程池中拿到一个EventLoop来关联
// 关联起来后,往后这个Connection对象的所有操作都放在这个EventLoop对象中
EventLoop *nextEventLoop()
{
// 如果线程池的线程数量为0,就返回主eventLoop
if(_threadCount == 0)
{
return _baseLoop;
}
_nextLoopIndex = (_nextLoopIndex + 1) % _threadCount;
return _eventLoops[_nextLoopIndex];
}
private:
int _threadCount; // 从属线程的数量
int _nextLoopIndex;
EventLoop *_baseLoop; // 主EventLoop,运行在主线程,从属线程数量为0,则所有操作都在_baseLoop中进行
std::vector<LoopThread *> _threads; // 保存所有的LoopThread对象
std::vector<EventLoop *> _eventLoops; // 从属线程数量大于0则从_eventLoop中进行线程EventLoop分配
};